가상 메모리가 실제로 동작하는 방식
TL;DR
Demand Paging은 프로그램의 모든 페이지를 미리 메모리에 올리지 않고, 실제로 필요해질 때만 로드하는 방식이다.
이로 인해 발생하는 Page Fault는 디스크 I/O를 동반하므로 비용이 매우 크며, 이를 최소화하기 위해 Page Replacement 알고리즘, Swap Space, Copy-On-Write 같은 기법이 사용된다.
Paging은 외부 단편화를 해결했지만, 새로운 문제가 생겼다.
- 모든 페이지를 메모리에 올리면 메모리가 부족해짐
- 실제로는 실행 중 사용되지 않는 코드/데이터가 매우 많음
이 관찰에서 출발한 개념이 Demand Paging이다.
Demand Paging의 핵심 개념
Demand Paging이란
프로세스의 페이지를 미리 적재하지 않고,
해당 페이지가 참조되는 순간에만 메모리로 가져오는 방식이다.
- 메모리에 없는 페이지 접근 → Page Fault
- OS가 개입하여 페이지를 로드
- 프로그램은 중단되었다가 다시 이어서 실행됨
핵심 개념
Demand Paging은 가상 메모리가 실제로 가능해지는 전제 조건이다.
Demand Paging 동작 흐름
페이지 폴트가 발생했을 때의 전체 흐름은 다음과 같다.
[CPU 논리 주소 접근]
↓
[Page Table 검사]
↓ (Invalid)
[Page Fault 발생]
↓
[디스크에서 페이지 위치 탐색]
↓
[Free Frame 확보]
├─ 있으면 사용
└─ 없으면 Page Replacement
↓
[디스크 → 메모리 로드]
↓
[Page Table 갱신 (Valid = 1)]
↓
[Instruction Restart]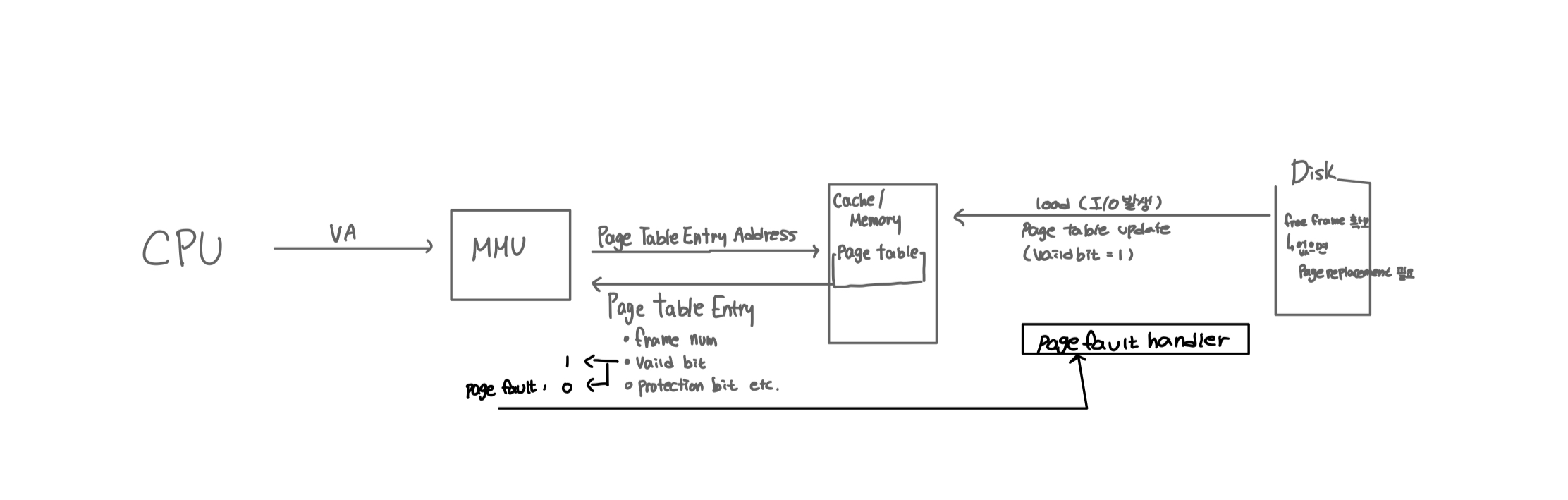
Page Fault의 비용이 치명적인 이유
메모리와 디스크의 속도 차이는 압도적이다.
- 메모리 접근: 수백 ns
- 디스크 접근: 수 ms
즉, 페이지 폴트 한 번은
수천 번의 메모리 접근 비용과 맞먹는다.
그래서 Demand Paging 시스템의 목표는
Page Fault Rate를 극단적으로 낮추는 것
Effective Access Time (EAT)
Demand Paging의 성능은 EAT로 표현된다.
EAT = (1 - p) × Memory Time
+ p × Page Fault Service Time- p: Page Fault Rate
- Page Fault Service Time ≈ 디스크 I/O 시간
p = 0.001 (0.1%)일 때도 EAT가 40배 이상 느려짐
➡ 페이지 폴트율은 0.01% 이하가 되어야 시스템 성능 유지 가능.
Swap Space의 역할
Swap Space: 디스크 공간 중 일부를 메모리 확장 공간처럼 사용하는 영역
- 파일 시스템과 분리된 전용 페이지 저장 공간
- 페이지 입출력에 최적화된 구조
- Page Replacement 시 페이지를 내보낼 장소
특히 중요한 점은 다음이다.
- 코드 영역(Text)은 Read-only
- 수정되지 않았다면 Dirty Page가 아님
- 이런 페이지는 swap-out 없이 그냥 버려도 됨
👉 Dirty Bit 관리가 성능에 직접적인 영향을 미친다.
Page Replacement 발생
↓
이 페이지가 Dirty인가?
↓
┌───────────────┐
│ Dirty Page │ → Swap Space에 저장(write-back) 후 제거
└───────────────┘
┌───────────────┐
│ Clean Page │ → 그냥 버림 (no I/O)
└───────────────┘
Page의 상태
├─ RAM에 있음 → Frame에 매핑
├─ 디스크에 있음 → Swap Space
└─ 그냥 버려짐 → Clean Page (코드 영역 등)Copy-On-Write (COW)
fork() 시 부모 프로세스의 페이지를 즉시 복사하지 않음
→ 부모와 자식이 같은 물리 메모리를 공유함(Read-Only)
동작
-
부모·자식 모두 같은 페이지 공유 (Write 불가 = Read-only)
-
둘 중 하나가 해당 페이지에 Write 요청
-
그 순간 페이지를 복사(copy)
→ 이후 독립적으로 사용
장점
fork 시 전체 주소 공간을 복사하는 비용 절약
메모리 사용량 감소
프로세스 생성 속도 대폭 향상
Page Replacement가 필요할 때
Page Fault 발생 시:
- Free Frame이 있다 → 바로 적재
- Free Frame이 없다 → Victim Page 선택
이때 선택 기준이 Page Replacement Algorithm이다.
-
교체할 페이지(Victim Page) 선정
-
해당 페이지가 Dirty이면 → 디스크에 저장(write-back)
-
Dirty 아니면 → 그냥 버림
-
새로운 페이지를 메모리로 로드
-
Page Table 업데이트
Dirty Bit
■ 의미
페이지가 메모리에 올라온 후 수정되었는지 여부 표시
Dirty Page:
교체 시 반드시 디스크에 다시 기록해야 함 (비용 ↑)
Clean Page:
교체해도 디스크에 기록할 필요 없음 (비용 ↓)
Page Replacement Algorithms
FIFO (First-In First-Out)
- 가장 먼저 들어온 페이지 제거
- 단순하지만 성능 나쁨
Belady’s Anomaly
프레임 수를 늘렸는데
오히려 페이지 폴트가 증가하는 현상.
Optimal Algorithm (OPT)
- 미래에 가장 늦게 쓰일 페이지 제거
- 이론적으로 최적
- 현실에서는 구현 불가
👉 비교 기준(하한선)으로만 사용
LRU (Least Recently Used)
- 가장 오랫동안 사용되지 않은 페이지 제거
- 실제 프로그램 특성과 잘 맞음
LRU가 강력한 이유는 하나다.
Locality(지역성)
프로그램의 메모리 접근에는 패턴이 있다.
시간 지역성
최근에 사용한 데이터는 곧 다시 사용됨
공간 지역성
접근한 주소 근처를 곧 접근함
LRU는 이 특성을 가장 잘 활용한다.
핵심 개념 요약
- Demand Paging: 필요할 때만 페이지 로드
- Page Fault: 정상 동작이지만 비용 매우 큼
- Swap Space: 페이지 교체 성능의 핵심 요소
- Copy-On-Write: fork 성능 최적화의 핵심
- FIFO: Belady’s anomaly 발생
- OPT: 이론적 최적
- LRU: 지역성 기반의 실용적 최적 해법
헷갈리기 쉬운 부분
Paging vs Demand Paging
- Paging: 메모리 관리 구조
- Demand Paging: 언제 로드할 것인가에 대한 정책
Dirty Page vs Clean Page
- Dirty: 반드시 디스크에 기록
- Clean: 그냥 버려도 됨
정리
- 가상 메모리는 Demand Paging 없이는 성립하지 않는다
- Page Fault는 반드시 관리해야 할 비용이다
- Page Replacement와 Locality 이해가 성능을 좌우한다
Demand Paging은 필요한 페이지를 그때그때 메모리에 올리는 방식이며, Page Fault를 최소화하는 것이 핵심 목표다. 실제 OS는 정확한 LRU 대신 Clock 기반 근사 알고리즘을 사용하고, Thrashing을 방지하기 위해 Working Set과 PFF를 함께 고려한다. 커널 메모리는 Buddy System과 Slab Allocator로 별도 관리된다.
Page Table 핵심 비트
- Valid bit
→ 페이지가 메모리에 있는지 여부 - Reference bit (R)
→ 최근 접근 여부 - Dirty bit
→ 수정 여부 (디스크 write-back 필요성 판단)
LRU의 현실적인 한계 (⭐)
① Counter-based LRU
- 각 페이지 접근 시 timestamp 저장
- 가장 오래된 페이지를 victim으로 선택
문제점:
- 모든 페이지에 시간 정보 저장
- victim 탐색 비용 큼
→ 현실적으로 비효율
② Stack-based LRU (이중 연결 리스트)
- 접근 시 페이지를 리스트 맨 앞으로 이동
- 맨 뒤가 LRU
문제점:
- 매 접근마다 리스트 갱신
- 페이지 수가 많을수록 오버헤드 증가
➡ 정확한 LRU는 OS 전체에 적용하기엔 너무 비싸다.
LRU Approximation (근사 알고리즘)
Reference Bit 기반
- R=1 → 최근 접근됨
- R=0 → 오래 안 쓰임 → 우선 교체
Second-Chance (Clock) Algorithm ⭐
[Page A][Page B][Page C][Page D]
↑
Clock Hand동작:
- R=1 → R=0으로 초기화 후 넘어감
- R=0 → 즉시 교체
직관:
- 한 바퀴 도는 동안 다시 안 쓰인 페이지는 버려도 됨
Enhanced Clock (R + Dirty)
| R | Dirty | 의미 |
|---|---|---|
| 0 | 0 | ⭐최적의 교체 대상 |
| 0 | 1 | write-back 필요 |
| 1 | 0 | 최근 접근 |
| 1 | 1 | 최악의 교체 대상 |
OS는 (0,0)부터 우선 탐색한다.
Thrashing (스레싱) ⭐
Thrashing이란
페이지 교체가 너무 빈번해 CPU가 실제 작업을 거의 못 하는 상태다.
증상:
- CPU utilization 급감
- 시스템이 멈춘 것처럼 보임
원인:
- 프로세스가 필요로 하는 페이지 집합보다 적은 프레임을 할당받음
Working Set Model
프로세스는 일정 시간 동안 집중적으로 사용하는 페이지 집합을 가진다.
이를 Working Set이라 한다.
- Δ(Delta): 관찰 시간 윈도우
- WS(t): 시간 t에서의 Working Set
Σ WS(processes) > 총 프레임 수
→ Thrashing 발생대응:
- 일부 프로세스 swap out
- 프레임 재할당
Page Fault Frequency (PFF)
Working Set 계산이 복잡하므로 Page Fault Rate로 간접 제어한다.
- Fault ↑ → 프레임 추가
- Fault ↓ → 프레임 회수
Global vs Local Replacement
| 구분 | Local | Global |
|---|---|---|
| 교체 범위 | 자기 프레임 | 전체 프레임 |
| 간섭 | 없음 | 있음 |
| 효율 | 낮음 | 높음 |
| 위험 | 안정적 | Thrashing 위험 |
Global 정책은 WS/PFF와 함께 사용해야 안전하다.
Kernel Memory Allocation
유저 메모리와 달리 커널은 연속 메모리를 요구한다.
Buddy System
- 2의 거듭제곱 단위 분할
- 외부 단편화 감소
Slab Allocator (Linux 기본)
- 커널 객체를 미리 캐싱
- 빠른 alloc/free
- 내부 단편화 감소
예: task_struct, file descriptor
핵심 개념 요약
- Demand Paging 흐름
- Page Fault는 디스크 I/O
- 정확한 LRU는 비현실적
- Clock Algorithm 동작 원리
- Thrashing = Working Set 부족
- WS + PFF + Global 정책 연계
- 커널은 Buddy + Slab 사용
헷갈리기 쉬운 개념 정리
- LRU vs Clock
→ Clock은 LRU의 근사 - Dirty bit 의미
→ 교체 시 디스크 쓰기 여부 - Thrashing ≠ Deadlock
→ 자원 교착이 아니라 메모리 부족 문제
마무리
- 가상 메모리의 핵심은 Page Fault 최소화
- 실제 OS는 근사 알고리즘 + 동적 제어
- Thrashing은 메모리 정책 실패의 신호
