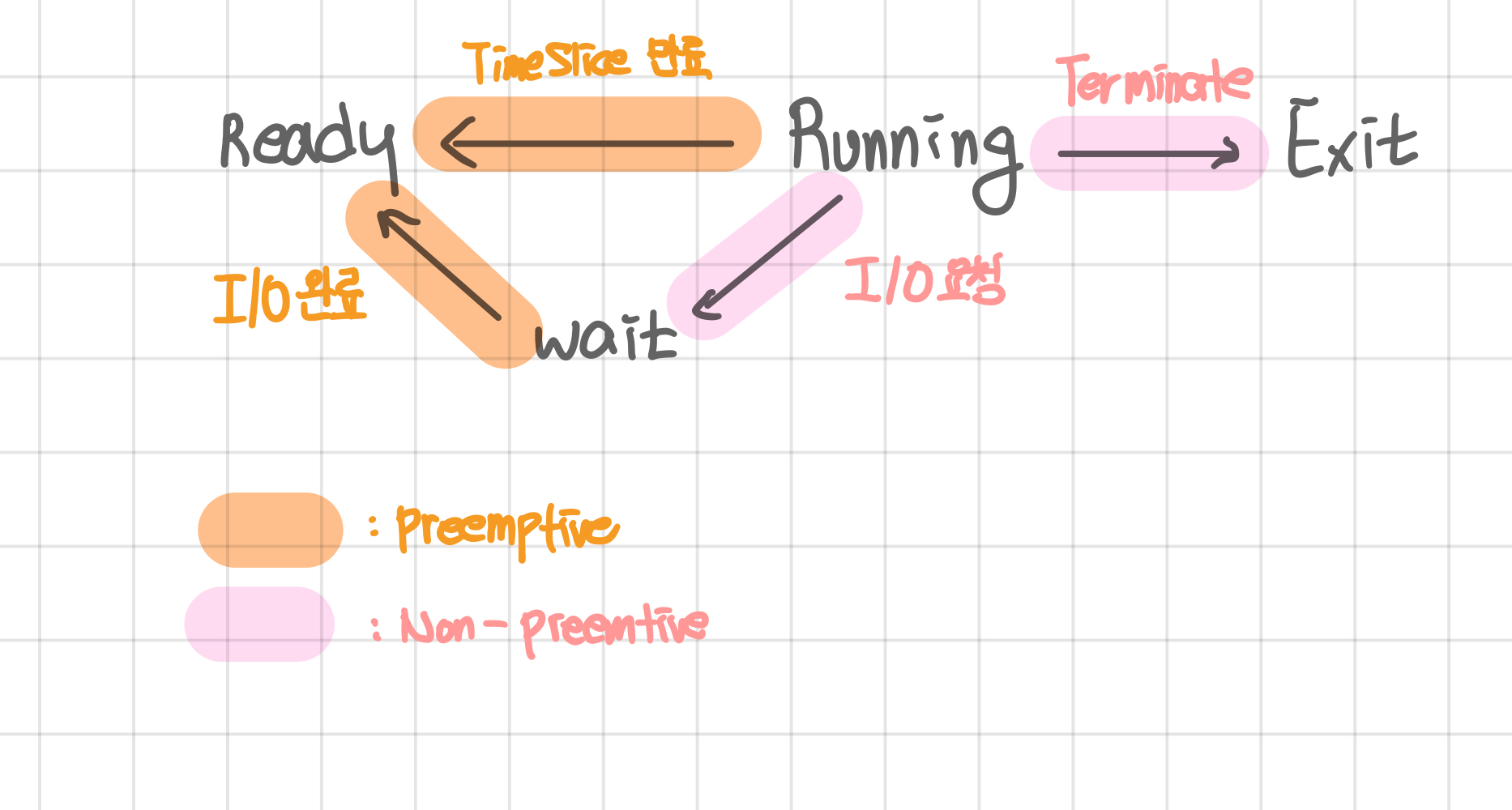
Cpu scheduler: ready queue에 있는 프로세스를 선택
Scheduling Criteria
context switching 시간은 고려하지 않는다
CPU Utilization
: CPU를 사용하는 시간
Throughput
: 단위시간당 실행된 프로세스 개수
Turnaround time
: 개별 프로세스가 작업하는데 걸리는 시간
평균 반환 시간(프로세스 시작부터 종료까지 걸린 시간)
Waiting time
: 프로세스가 ready queue에서 기다리는 시간
Response time
: 요청시점부터 할당될 때 까지의 시간
Scheduling Algorithm
스케줄링 목적: (utilization & Throughput ↑) && time ↓
First-Come, First-Served (FCFS)
ready queue에 도착한 순서대로
가장 적게 걸리는 프로세스가 먼저 오는게 waiting time이 가장 적게 걸림
Fairness ↑
Convey effect : short process가 뒤에 오면 하염없이 기다려야함
Shortest-Job-First (SJF)
CPU 버스트 시간이 가장 짧은거 부터
최소 평균 Waiting time
한계: 다음 CPU 요청의 길이를 아는 데 어려움이 있음
SJF는 비선점형, SJF의 선점형 버전이 SRTF
Shortest-Remaining-Time-First
도착한 프로세스 버스트 타임과 실행중인 프로세스의 남아 있는 시간 비교
Round Robin
Time sharing system을 위해 설계
목표: 모든 프로세스가 공평하게 CPU를 사용할 기회를 갖도록 함
Time quantum, q
시간할당량
각 프로세스는 q라는 cpu 사용 시간을 할당받음
- 프로세스가 할당된 시간 q를 모두 사용하면 아직 실행이 끝나지 않았더라도 중단(선점)
- 선점된 프로세스는 레디 큐에 맨뒤로 이동하여 다음 차례를 기다림
- OS는 레디큐 맨앞 프로세스에게 cpu를 할당하고 이 과정을 반복
Fairness ↑
예측 가능한 대기 시간
어떤 프로세스도 (n-1)q 시간 단위 이상을 기다리지 않는다. 특정 프로세스가 무한정 기다리는 기아 상태(Starvation)가 발생하지 않음을 보장
성능의존성:
-
q가 매우 크면: 대부분의 프로세스가 시간 할당량 내에 실행을 마치므로, 먼저 온 프로세스가 먼저 끝나는 선입선출(FIFO) 방식과 유사
-
q가 매우 작으면: 문맥 교환(Context Switch)이 너무 자주 발생하여, 실제 프로세스 실행 시간보다 문맥 교환에 드는 오버헤드가 커져 시스템 전체 성능이 저하
응답 시간 vs. 반환 시간:
평균 Turnaround Time은 SJF 알고리즘보다 긴 경우가 많다.
하지만 사용자가 요청에 대한 반응을 빠르게 느끼는 Response Time은 우수함(모든 프로세스가 짧은 시간 내에 한 번씩은 실행되기 때문)
예제: RR 스케줄링 (시간 할당량 q = 4)
프로세스 1 (P1): 실행 시간 24
프로세스 2 (P2): 실행 시간 3
프로세스 3 (P3): 실행 시간 3
(모든 프로세스는 시간 0에 도착했다고 가정합니다.)
| P1 | P2 | P3 | P1 | P1 | P1 | P1 | P1 |
0 4 7 10 14 18 22 26 30시간 할당량(Time Quantum)과 문맥 교환 시간(Context Switch Time)
라운드 로빈의 성능을 결정하는 가장 중요한 요소는 시간 할당량 q의 크기. q는 문맥 교환 시간보다 훨씬 커야 함
문맥 교환: 하나의 프로세스에서 다른 프로세스로 CPU 제어를 넘겨주는 과정. 이때 이전 프로세스의 상태를 저장하고 새 프로세스의 상태를 불러오는 데 시간이 소요됨 (보통 10µs 미만)
시간 할당량: 프로세스가 실행되는 시간. (보통 10-100ms, 즉 10,000-100,000µs)
만약 시간 할당량이 문맥 교환 시간과 비슷할 정도로 작다면, CPU는 실제 작업보다 프로세스 전환에 더 많은 시간을 쓰게 되어 비효율적
turnaround time은 시간 할당량 q의 크기에 따라 크게 달라집니다.
q가 너무 클 경우:
알고리즘이 FIFO처럼 동작
만약 실행 시간이 매우 긴 프로세스가 먼저 CPU를 점유하면, 뒤따르는 짧은 프로세스들은 매우 오랜 시간 기다려야 함
이로 인해 짧은 프로세스들의 반환 시간이 급격히 늘어나 평균 반환 시간이 길어집니다.
q가 너무 작을 경우:
문맥 교환이 너무 자주 발생합니다.
문맥 교환에 소요되는 오버헤드가 전체 실행 시간을 증가시킵니다.
예를 들어, 실행 시간이 10인 프로세스를 q=1로 실행하면 9번의 불필요한 문맥 교환이 발생하여 총 실행 시간이 늘어납니다.
결과적으로 모든 프로세스의 완료 시간이 늦춰져 평균 반환 시간이 길어집니다.

라운드 로빈은 어디갓나여?