
User mode vs Kernel mode
Register
Memory
User Stack
File Descriptor
시스템 콜(System Call)이란?
캐시
Atomic Operation
RAX Register
32bit OS vs 64bit OS
인터럽트(Interrupt)
Segmentation Fault
User mode vs Kernel mode
어떻게 구분되는가?
가상 메모리 주소로 구분됨.
• 일반적으로 커널은 상위 가상 주소 영역 (예: 0xC0000000~), 유저 프로그램은 하위 가상 주소 영역 (예: 0x08048000~) 사용.
• CPU의 권한 레벨(Ring 0 vs Ring 3) 로도 구분됨.
• User Mode: 제한된 명령만 사용 가능 (Ring 3)
• Kernel Mode: 하드웨어 직접 제어 가능 (Ring 0)
⸻
언제 유저 ↔ 커널 모드 전환?
User → Kernel : 시스템 콜, 예외(Exception), 인터럽트
Kernel → User : 시스템 콜 리턴, 인터럽트 핸들러 종료 후 스케줄링
⸻
read() 호출 상황 흐름 (수정 제안 포함)
- Thread T1에서 read() 호출
• read()는 시스템 콜 → 커널 모드 진입
• 커널에서 T1의 I/O 요청을 처리할 준비
• SSD에서 데이터를 아직 받지 못함 → T1은 BLOCKED (wait)
➡ 커널은 T1의 상태를 저장하고, 다른 스레드(T2)를 실행하도록 스케줄링
-
T2 실행 중 SSD 인터럽트 발생
• SSD에서 데이터 준비 완료 → interrupt handler 실행 (커널 모드)
• T1의 상태를 READY로 바꿈
• 하지만 지금은 T2가 실행 중이라 여전히 T2 running -
Timer Interrupt (시분할 타이머)
• 주기적으로 발생해 선점 스케줄링 수행
• T2의 context 저장 → READY로 전환
• READY 상태였던 T1을 선택하여 실행
• T1 다시 running 상태 → 커널 read() 마무리 → 유저 모드 복귀
⸻
Register
레지스터(Register)는 CPU 내부에 있는 초고속 임시 기억장치로,
모든 연산이 이곳을 중심으로 이루어짐.
특징
• 초고속: CPU 내부에 존재하므로 가장 빠른 접근 속도를 가짐
• 연산 중심: 모든 산술/논리 연산은 반드시 레지스터를 통해서 수행됨
• 작은 용량: 극소수의 비트만 저장할 수 있으나, 속도는 RAM보다 수십~수백 배 빠름
⸻
레지스터의 역할 in OS (예: PintOS)
-
인터럽트 처리
• 인터럽트 발생 시, 현재 레지스터 값을 struct intr_frame 에 저장
• 인터럽트 처리 후, 이 값을 복원하여 정확한 지점에서 실행 재개 -
문맥 전환 (Context Switch)
• 스레드 A → B 전환 시:
A의 레지스터 값들(rsp, rbp, rip, rdi, …)을 저장
B의 레지스터 값들을 복원하여 실행 흐름 전환
⸻
• Register는 CPU 연산의 중심이며, 가장 빠른 기억장치다.
• 모든 연산은 레지스터를 거쳐야 하며, OS에서는 문맥 전환과 인터럽트 처리 시 반드시 저장/복원이 수행된다.
⸻
Meomory
흔히 RAM(Random Access Memory) 을 의미
프로그램 실행 중 코드, 변수, 함수 등 모든 실행 데이터를 담는 공간
CPU는 메모리에서 데이터를 가져와 레지스터에 올려야 연산 가능
⸻
Text: 실행 코드가 저장된 영역
Data: 전역 변수, static 변수 저장 영역
Heap: malloc() 등으로 동적 할당되는 공간
Stack: 함수 호출, 지역 변수, 리턴 주소 저장 (LIFO 구조)
Stack은 함수 호출 시 늘어나고, 함수 종료 시 줄어드는 후입선출 구조
⸻
PintOS에서의 메모리 활용
- Kernel Stack
• 각 스레드(struct thread)마다 4KB 고정 크기의 커널 스택 보유
• 함수 호출 시 레지스터, 리턴 주소, 지역 변수 등이 여기에 저장됨
• 스택 오버플로우 감지: thread.magic 값(0xcd6abf4b)으로 검출
→ 오버플로우 시 magic 값이 깨지고 ASSERT(is_thread(t))로 감지
⸻
-
Page Allocator
• 메모리를 4KB 페이지 단위로 관리 (x86 표준)
• palloc_get_page(): 페이지 할당
• palloc_free_page(): 페이지 반납• Free Page Pool: 사용 가능한 페이지 목록
• Kernel/User Pool: 커널과 유저 메모리 분리
• Swap Disk: 메모리 부족 시 디스크에 임시 저장
⸻
- Virtual Memory (P2 ~ P3)
• 모든 프로세스가 자신만의 가상 주소 공간을 갖도록 제공
• 주요 개념:
Virtual Address : 프로세스가 보는 논리 주소 (0x8048000 등)
Physical Address : 실제 RAM의 물리 주소 (0x0012F000 등)
Page Table : 가상 주소 ↔ 물리 주소 매핑
Page Fault : 매핑 없는 가상 주소 접근 시 발생
Lazy Loading : 접근 시점에만 데이터를 로딩
Memory Mapping (mmap) : 파일 내용을 메모리에 직접 매핑
Stack Growth : 접근 시 자동으로 스택 확장
page_fault() : 페이지 폴트 발생 시 데이터를 적절히 채우는 핵심 함수
RAM도 빠르지만, 캐시 미스(Cache Miss) 발생 시 성능 저하가 크다
⸻
💾 변수와 메모리의 관계
int x = 5;
• x는 메모리 어딘가에 저장됨
• &x는 변수의 메모리 주소
• CPU는 이 주소를 통해 메모리에서 값을 가져와 연산 수행→ this is why pointer is important in C
⸻
User Stack
프로세스가 User Mode에서 실행될 때 사용하는 스택 메모리 영역
함수 호출, 지역 변수 저장, 리턴 주소 추적 등을 담당하며, 프로그램의 흐름 제어와 관련된 중요한 역할을 합니다.
⸻
특징
위치: 사용자 주소 공간의 가장 높은 주소부터 아래 방향으로 성장
용도: 함수 호출 시 스택 프레임 저장 (매개변수, 지역 변수, return address 등)
구조: 후입선출 (LIFO: Last-In-First-Out)
관리 주체: 커널이 프로세스 생성 시 유저 스택 공간을 할당
스택 포인터: rsp (x86_64) 또는 esp (x86)- 현재 스택 위치를 가리킴
⸻
함수 호출 시의 스택 변화
int main() {
foo();
}
void foo() {
int a = 10;
}
함수 호출 시:
+--------------------+ ← 높은 주소
| return address | ← main()이 foo() 호출 후 돌아올 주소
| saved registers |
| local variable a |
+--------------------+ ← 낮은 주소 (rsp 위치)
⸻
PintOS와 User Stack
• Project 2~3에서 사용자 프로그램을 로드할 때, 프로세스의 user stack을 페이지 단위로 할당
• 유저 프로그램의 인자 전달 (argv/argc), 스택 성장 (stack growth) 등을 구현할 때 사용됨
• page fault가 스택 영역에 발생하면 → page_fault() 핸들러에서 스택 자동 확장이 일어날 수 있음
⸻
Stack Overflow
• 너무 많은 함수 호출 또는 큰 지역 변수 → 스택이 허용 범위를 넘으면 Stack Overflow 발생
• 일반적으로 OS는 가드 페이지 또는 최대 스택 크기 제한을 통해 보호
⸻
File Descriptor
운영체제에서 프로세스가 파일, 키보드, 화면, 소켓 같은 입출력 자원에 접근할 때 사용하는 정수형 식별자.
운영체제는 이런 자원을 숫자(FD) 로 추상화해 관리
✅ 기본 FD 번호
| 번호 | 이름 | 설명 |
|---|---|---|
| 0 | stdin | 표준 입력 (키보드) |
| 1 | stdout | 표준 출력 (화면) |
| 2 | stderr | 표준 에러 출력 |
✅ FD 테이블 예시
[ 프로세스 A의 FD 테이블 ]
┌─────┬──────────────┐
│ 0 │ /dev/tty0 │ (stdin)
│ 1 │ /dev/tty0 │ (stdout)
│ 2 │ /dev/tty0 │ (stderr)
│ 3 │ file.txt │
└─────┴──────────────┘🔁 dup2(oldfd, newfd)
oldfd가 가리키는 자원을newfd에 복제하는 시스템 호출
동작 방식
newfd가 열려 있으면close(newfd)newfd가oldfd와 같은 파일을 가리키게 함
결과
초기 상태:
FD Table
┌─────┬────────────┐
│ 1 │ stdout │
│ 3 │ file.txt │
└─────┴────────────┘
→ dup2(3, 1) 실행
결과 상태:
FD Table
┌─────┬────────────┐
│ 1 │ file.txt │ ← 3번과 동일 자원
│ 3 │ file.txt │
└─────┴────────────┘사용 예제
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd = open("output.txt", O_WRONLY | O_CREAT, 0644);
dup2(fd, 1); // stdout(1)을 output.txt로 리디렉션
write(1, "hello\n", 6); // → output.txt에 기록됨
}fork()와 dup2()
dup2()는 단독으로도 사용할 수 있지만, fork()와 함께 자식 프로세스의 입출력을 리디렉션할 때 자주 사용됩니다.
✅ 예: 쉘 명령 ls | grep txt 의 내부
int pipefd[2];
pipe(pipefd);
if (fork() == 0) {
// 자식: ls
dup2(pipefd[1], 1); // stdout → pipe write
close(pipefd[0]); // read 닫기
execlp("ls", "ls", NULL);
} else {
// 부모: grep
dup2(pipefd[0], 0); // stdin → pipe read
close(pipefd[1]); // write 닫기
execlp("grep", "grep", "txt", NULL);
}정리
- 파일 디스크립터(FD)는 프로세스가 자원에 접근할 수 있게 해주는 번호표
dup2(oldfd, newfd)는 입출력을 복제하거나 리디렉션할 때 사용fork()이후 자식 프로세스의 입출력을 제어하려면 거의 항상dup2()가 함께 쓰임- 쉘 구현, 로그 기록, 파이프 연결 등에 필수적인 개념
// 핵심 요약 예시
dup2(fd, 1); // stdout을 fd로 바꿈 → printf가 화면이 아닌 fd로 출력됨시스템 콜(System Call)이란?
유저 프로그램이 커널(운영체제)에 기능을 요청할 때 사용하는 인터페이스
• 유저 모드에서는 하드웨어나 중요한 시스템 자원에 직접 접근 불가
• 시스템 콜을 통해 간접적으로 접근 → ex. 파일 열기, 읽기, 쓰기 등
⸻
동작 과정
- 유저 프로그램 실행 중
- 특정 작업 필요 → 시스템 콜 호출 (read(), write() 등)
- 커널 모드로 전환
- 커널이 요청된 작업 수행
- 결과를 유저 모드로 반환하고 복귀
⸻
시스템 콜의 주요 종류
프로세스 관리 fork(), exec(), exit()
파일 입출력 open(), read(), write(), close()
디바이스 제어 ioctl() 등
정보 조회 getpid(), sleep() 등
프로세스 간 통신(IPC) pipe(), mmap(), shmget() 등
⸻
PintOS에서의 활용
• syscall.c에서 시스템 콜 인터페이스 구현
• read(), write(), exit(), exec() 등 다양한 콜 처리
• int 0x30 인터럽트를 사용해 커널 모드로 진입
⸻
캐시
캐시가 필요한 이유
• CPU는 매우 빠르며, 메모리는 상대적으로 느림
→ 속도 차이: 수십~수백 배 (ex. CPU 1ns vs Memory 100~200ns)
• 이로 인해 CPU가 데이터를 기다리는 병목(Bottleneck) 발생
→ 해결책: Cache (자주 쓰는 데이터를 미리 저장)
⸻
캐시 계층 구조
| 계층 | 위치 | 용량 | 속도 | 특징 |
|---|---|---|---|---|
| L1 | CPU 코어 내부 | 수십 KB | 가장 빠름 | 명령어/데이터 캐시 분리 |
| L2 | CPU 코어 내부 | 수백 KB | 빠름 | 통합 캐시 |
| L3 | CPU 전체 공유 | 수 MB | 느림 | 모든 코어가 공유 |
⸻
Locality of Reference (지역성의 법칙)
Temporal (시간적) : 최근에 사용한 데이터 → 또 쓸 확률 높음 루프 변수, 조건 카운터
Spatial (공간적) : 가까운 주소의 데이터 → 함께 쓸 확률 높음 배열 접근, 스택 프레임
➡ 캐시는 사용한 데이터뿐 아니라, 주변 데이터까지 미리 불러옴 (prefetching)
⸻
캐시 작동 흐름
- CPU가 주소 A를 요청
- 캐시에 A가 있으면 → Cache Hit (1~3 cycle)
- 없으면 → Cache Miss → 메모리에서 A를 불러와 캐시에 저장 (수백 cycle 소모)
- 캐시 공간이 부족하면 기존 데이터를 eviction(교체)
⸻
Cache Miss의 종류
Cold Miss: 처음 접근한 데이터
Capacity Miss: 캐시 크기 부족
Conflict Miss: 캐시 슬롯 충돌 (배열 stride 등)
⸻
CPU에서의 캐시 사용
- I-Cache: 명령어 캐시
- D-Cache: 데이터 캐시
- TLB (Translation Lookaside Buffer): 가상 주소 → 물리 주소 변환 결과를 저장하는 캐시
→ 가상 메모리 성능 최적화에 핵심
⸻
PintOS와 캐시의 연관성
- 성능 실험 해석
• 데이터 접근 패턴에 따라 캐시 효율 차이 발생
• B-Tree는 캐시 효율을 고려한 구조 - 컨텍스트 스위칭
• 스레드 전환 시 캐시 데이터 무효화 → 캐시 미스 증가 - TLB와 페이지 테이블
• TLB는 주소 변환 캐시
• TLB miss → 페이지 테이블 접근 → page fault 발생 가능
• TLB는 캐시 개념의 연장선
⸻
atomic operation
Atomic Operations(원자 연산)은 다중 스레딩 환경에서 데이터의 일관성과 안전성을 보장하기 위한 중요한 개념
해당 연산은 도중에 끼어들 수 없으며, 완전히 끝날 때까지 다른 스레드나 프로세스가 중간 상태를 볼 수 없다
두 스레드가 같은 변수 counter를 증가시키려 할 때, 원자적이지 않으면 둘 다 같은 값을 읽고, 각각 증가 후 다시 저장해 결국 한 번만 증가된 결과가 나올 수 있다.
하지만 원자 연산을 사용하면 읽기-수정-쓰기 전체 과정이 하나의 동작처럼 수행되어 이런 문제가 발생하지 않는다.
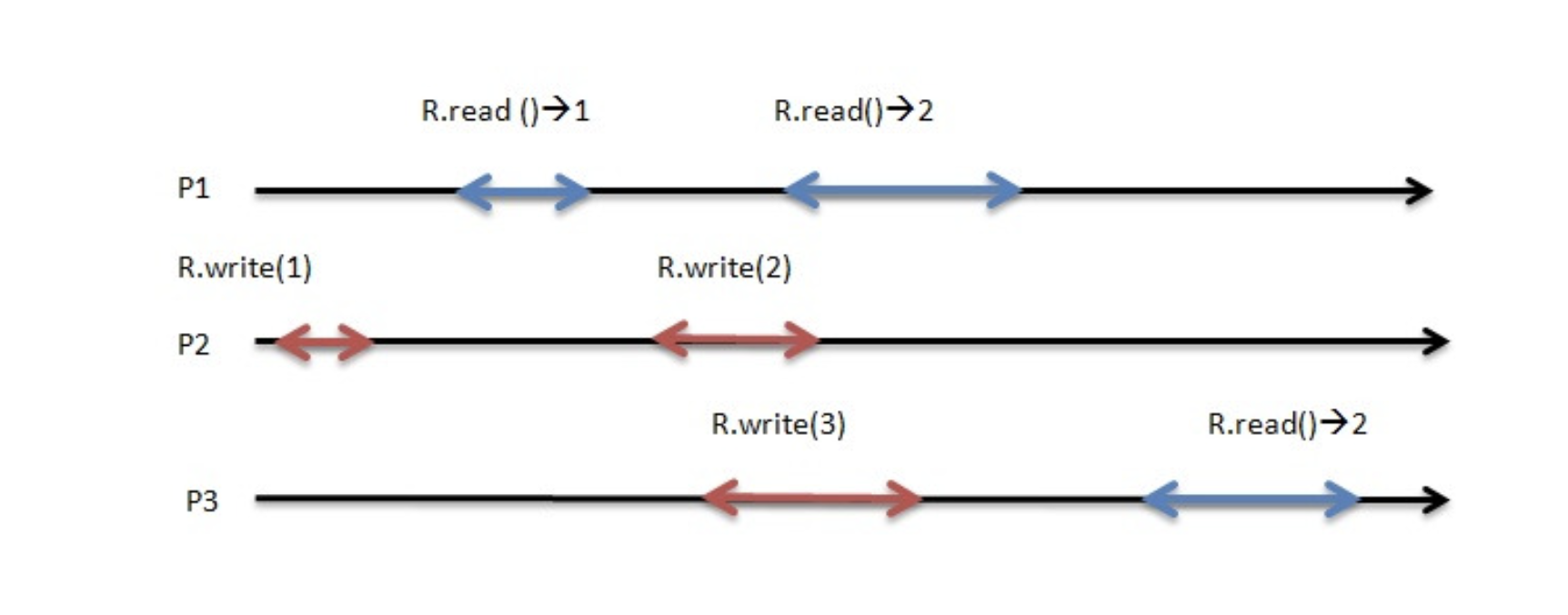
- 경쟁 조건(Race Condition) 방지
- 데이터 무결성 보장
- 락(mutex)보다 빠르고 효율적인 경우도 많음 (단순 변수 연산 등)
대표적인 원자 연산 종류
- Atomic Read/Write: 변수 값 읽기/쓰기
- Atomic Increment/Decrement: 변수 증가/감소
- Compare-and-Swap (CAS): 기대한 값일 경우에만 값을 바꾸는 연산 → 다른 스레드가 값 변경했는지 검사 가능
🔧 예시 (C++ 코드):
#include <atomic>
std::atomic<int> counter(0);
counter.fetch_add(1); // counter를 원자적으로 +1락(Mutex)과의 차이점
| 구분 | 원자 연산 | 락(Mutex 등) |
|---|---|---|
| 목적 | 단일 변수 보호 | 복잡한 자원/코드 보호 |
| 성능 | 매우 빠름 | 느릴 수 있음 (컨텍스트 스위칭 발생) |
| 위험 요소 | 적음 | 데드락, 우선순위 역전 등 발생 가능 |
- 단순한 변수 연산에는 원자 연산이 더 적절
- 여러 자원 동시에 다룰 때는 락이 필요함
요약
- 원자 연산은 하나의 연산이 끼어들 수 없이 완료됨을 보장
- 멀티스레드에서 데이터 충돌 방지와 정합성 유지에 필수
- 락보다 빠르고 가볍지만, 복잡한 상황에는 부족할 수 있음
rax register
데이터 전달 통로, 레지스터는 연산장치가아니다
Return Accumulator for X86-64
-
함수 반환값 저장
x86-64 호출 규약에 따르면, 함수의 반환값은 RAX 레지스터를 통해 전달됩니다. 예를 들어, C 언어에서 return 42;와 같은 명령은 어셈블리 코드에서 mov rax, 42로 변환됩니다.
-
산술 및 논리 연산의 누산기 역할
RAX는 전통적으로 누산기(accumulator)로 사용되며, 덧셈, 곱셈 등 연산의 결과를 저장하는 데 활용됩니다. 예를 들어, add rax, rbx는 RAX와 RBX의 값을 더한 결과를 RAX에 저장합니다.
-
임시 저장소로 활용
함수 호출 시 RAX는 “caller-save” 레지스터로 간주되어, 호출된 함수가 해당 값을 덮어쓸 수 있습니다. 따라서 함수 호출 전에 RAX의 값을 보존하려면 스택에 저장해야 합니다.
RAX는 64비트 레지스터이며, 그 하위 부분은 다음과 같이 접근할 수 있습니다:
- EAX: 하위 32비트
- AX: 하위 16비트=
- AL: 하위 8비트
- AH: 상위 8비트 (16비트 중)
mov rax, 10 ; RAX에 10을 저장
add rax, 5 ; RAX에 5를 더함 (결과: 15)32 bit OS vs 64 bit OS
비트
• 비트 수 = CPU 레지스터 크기
• 32비트: 한 번에 32비트 데이터 처리
• 64비트: 한 번에 64비트 데이터 처리
→ 처리 속도와 데이터 용량에 큰 차이
비유:
32비트는 책장 하나, 64비트는 도서관 전체
⸻
주요 차이점 요약
| 항목 | 32비트 | 64비트 |
|---|---|---|
| 주소 크기 | 4바이트 | 8바이트 |
| 최대 메모리 | 약 4GB | 이론상 18EB (엑사바이트) |
| 레지스터 이름 | eax, esp, ebp 등 | rax, rsp, rbp, r8~r15 등 |
| 함수 인자 전달 | 스택(stack) 사용 | 레지스터 사용 |
| 시스템 콜 방식 | int 0x80 (인터럽트 기반) | syscall (전용 명령어, 빠름) |
| ELF 형식 | ELF32 | ELF64 |
⸻
함수 호출 방식의 차이
• 32비트: 인자를 스택에 push → 느림
push arg2
push arg1
call function
• 64비트: 인자를 레지스터에 저장 → 빠름
mov rdi, arg1
mov rsi, arg2
call function
⸻
시스템 콜 차이
| 항목 | 32비트 | 64비트 |
|---|---|---|
| 방식 | int 0x80 | syscall |
| 속도 | 느림 | 빠름 |
| 보안성 | 낮음 | 높음 |
PintOS와의 연결
PintOS 커널: 32비트 기반, x86 아키텍처
QEMU 에뮬레이터 :32비트 CPU를 가상 실행
호스트 리눅스 환경 :64비트 (x86_64) 운영체제
GDB 디버깅 환경: 64비트 → 레지스터 이름 등 혼동 주의
시스템 콜 처리 in PintOS
• int 0x30 인터럽트 → 커널 진입
• struct intr_frame 에 레지스터 저장
• f->eax에 syscall 번호, 결과도 여기에 저장
인터럽트(Interrupt)
- CPU가 실행 중인 작업을 잠시 멈추고, 더 중요한 작업(이벤트)을 처리하도록 만드는 신호
- 하드웨어나 소프트웨어가 발생시킬 수 있음
왜 필요한가?
- CPU가 모든 장치를 계속 감시하는 건 비효율적
- → 이벤트가 있을 때만 알려주는 비동기 처리 방식
인터럽트 종류
- 하드웨어 인터럽트
- 외부 장치가 발생 (예: 키보드 입력, 타이머, 디스크 완료 등)
- 소프트웨어 인터럽트
- 프로그램이 명시적으로 발생 (예: 시스템 콜
int 0x80)
- 프로그램이 명시적으로 발생 (예: 시스템 콜
작동 흐름
- 인터럽트 발생
- 현재 작업 저장 (문맥 저장)
- 해당 인터럽트에 맞는 핸들러 실행
- 원래 작업으로 복귀
PintOS에서는?
- 인터럽트 번호에 따라 핸들러 등록 (ex:
int 0x30→ 시스템 콜) struct intr_frame에 레지스터 저장/복원- 컨텍스트 스위치, 시스템 콜, 타이머 등 모두 인터럽트 기반
✅ 요약 한 줄
→ 인터럽트는 "지금 중요한 일이 생겼어요!"라고 CPU에게 알리는 시스템
Segmentation Fault
- 잘못된 메모리 접근이 발생할 때 운영체제가 프로그램을 강제 종료시키는 오류
- 예: 허용되지 않은 메모리 주소에 접근하거나, 없는 주소에 쓰기 시도
주요 원인 예시
-
NULL 포인터 역참조
int p = NULL;
p = 10; // ❌ 세그폴트 발생 -
배열 범위 초과 접근
int arr[5];
arr[10] = 1; // ❌ 잘못된 메모리 접근 -
해제된 메모리 사용
int p = malloc(4);
free(p);
p = 20; // ❌ 이미 반납된 메모리 사용 -
읽기 전용 문자열에 쓰기
char *str = "hello";
str[0] = 'H'; // ❌ 문자열 리터럴은 읽기 전용
해결 방법
- 포인터 NULL 확인
- 배열 인덱스 유효성 검사
- malloc/free 짝 맞추기
- GDB, valgrind 등을 사용한 디버깅
세그멘테이션 폴트는 '접근하면 안 되는 메모리'를 건드렸을 때 발생하는 오류
