안녕하세요
블로그를 옮기기 전에 포스팅했던, Redis에 관한 포스팅을 다시 작성해볼까 합니다.
In-memory database
Redis는 대표적인 in-memory database 중에 하나입니다.
따라서 Redis를 이해하려면 먼저 In-memory database가 무엇인지 이해해야 합니다.
보통 database 하면 떠오르는 MySql(RDBMS) 나 MongoDB(NoSql) 등은 모두 disk에 data를 기록하고 disk로 부터 data를 불러와서 사용하게 됩니다..
반면에 In-memory database 방식은 disk가 아닌 Main-memory에 data를 저장하고 불러와 사용합니다.
MySql 이나 Maria DB도 In-memory도 In-memory database로 사용할 수 있는 옵션이 제공된다고는 합니다.
그러면 in-memory database의 장단점에 대해 알아볼까요?
1. In-memory 방식의 장점
In-memory database 방식은 data를 읽고 쓰는 속도가 disk base 방식보다 훨씬 빠릅니다.
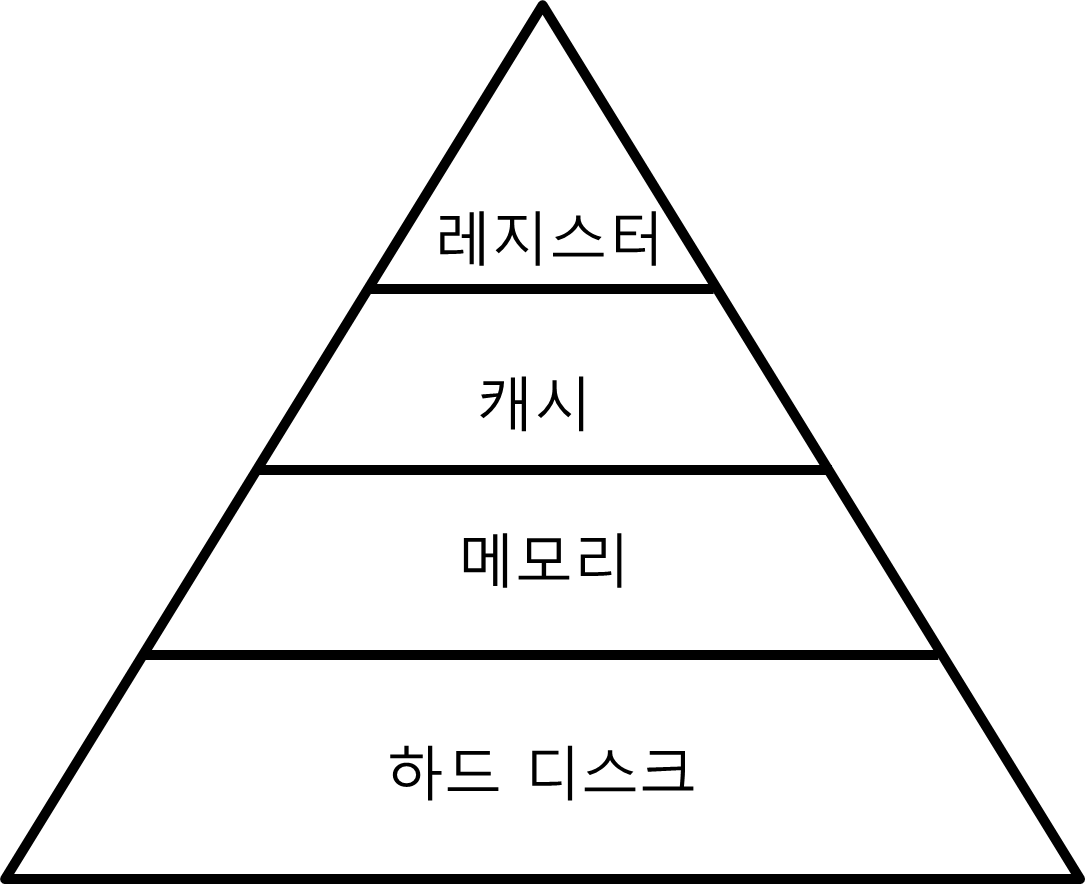
위 사진은 Memory 계층구조를 나타낸 사진입니다.
어떤 프로그램이 data를 불러올 때 disk base 방식은 hard disk에서 읽어 와야하므로 memory <-> hard disk 간 병목 현상을 비롯해 여러 속도에 영향을 미치는 환경이 발생하게 됩니다.
반면 memory에서 읽어오는 In-memory 방식은 이러한 현상이 발생하지 않으므로 속도가 빠른 것이죠.
2. In-memory 방식의 단점
반면 Memory에 data를 저장하기 때문에 data가 휘발성입니다.
이 말은 즉, 서버 전원이 갑자기 꺼져버리면 in-memory에 저장되어 있던 data들이 즉시 삭제되어 버린다는 뜻이죠.
이는 data가 저장되고 유지되어야 하는 상황에서는 치명적입니다.
또한 memory의 크기가 넉넉하지 않기에 많은 data를 저장할 수 없습니다.
따라서 많은 data 저장공간을 필요로 한다면 disk base 방식을 사용하는 것이 유리하죠.
그럼 Redis는?
Redis는 앞서 설명한 In-memory database입니다.
따라서 기본적으로 매우 빠른 속도를 가지고 있죠.(평균 작업속도가 평균 1ms 보다 작은걸로 알려져 있습니다.)
또한 Redis는 기본적으로 NoSql 방식이기에 table 구조를 가지고 있지 않고 Key-Value 타입으로 data를 관리합니다.
Redis의 특징은 다음과 같습니다.
- 영속성을 지원하는 인메모리 데이터 저장소 입니다.
- 읽기 성능 증대를 위한 서버 측 복제를 지원합니다.
- 쓰기 성능 증대를 위한 클라이언트 측 샤딩(Sharding) 지원합니다.
- 다양한 서비스에서 사용되며 검증된 기술입니다.
- 문자열, 리스트, 해시, 셋, 정렬된 셋과 같은 다양한 데이터형을 지원합니다. 메모리 저장소임에도 불구하고 많은 데이터형을 지원하므로 다양한 기능을 사용할 수 있습니다.
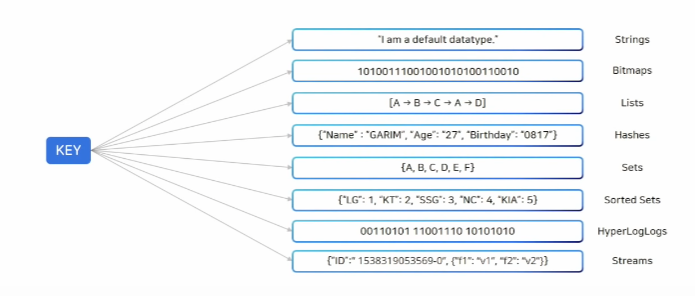
위 사진은 Redis가 지원하는 다양한 data 타입들 입니다.
Redis를 이용한 Caching 전략
이런 Redis를 사용하는 가장 흔한 방법은 cache 처럼 사용하는 방법입니다.
Redis를 이용해 caching 하는 방법에는 다양한 전략들이 있죠.
1. Look-Aside(읽기 전략)
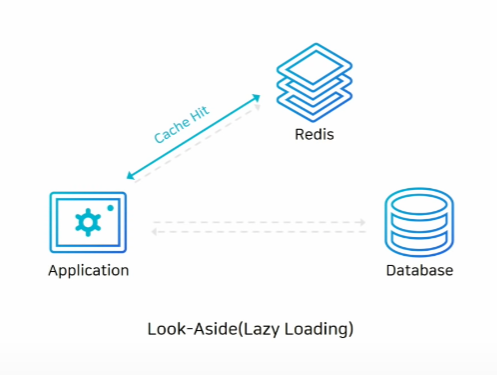
이 전략은 Application에서 data가 필요할 때 먼저 Redis를 확인합니다.
Redis에서 필요한 data를 찾으면 cache hit가 발생하고 그 data를 사용합니다.
그러나 Redis에 해당 data가 없으면 cache miss가 발생하고 database, 즉 disk에서 data를 찾아 Redis로 넣어주게 되죠.
이러한 cache miss가 자주 발생하면 오히려 성능 저하를 발생시키므로 초기에 Redis에 data가 많이 없으면 cache warming이라는 작업을 해주는 것이 좋습니다.
Cache warming은 database의 data를 Redis로 넣어주는 작업으로 과도한 cache miss를 예방해주어 성능 저하를 방지할 수 있죠.
2. Write-Around(쓰기 전략)
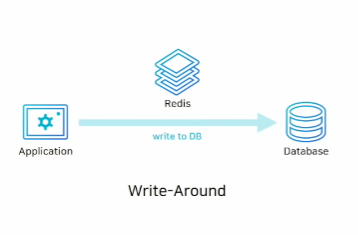
이 방식은 data를 저장할 때 database, 즉 disk에만 쓰고 데이터를 읽을 때 cache miss가 발생한 경우에만 database에서 Redis로 data를 넣어줍니다.
따라서 Redis의 data와 database의 data가 다른 경우가 발생할 수 있습니다.
3. Write-Though(쓰기 전략)
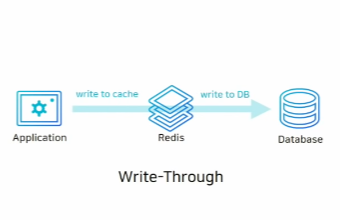
이 방식은 data를 저장할 때 Redis에도 저장하고 database에도 저장하는 방식입니다.
Redis와 database는 항상 같은, 최신의 data를 저장하고 있지만 data를 두 번 저장하므로 상대적으로 느릴 수 있죠.
또한 저장한 data가 항상 재사용 되는 것은 아니기에 리소스 낭비가 발생할 수 있습니다.
Reids의 데이터를 지키려면?
앞서 In-memory 방식은 휘발성 이어서 서버가 종료되면 data가 모두 날아간다는 단점이 있다고 했습니다.
Redis에는 이러한 불상사를 막기위해 데이터를 disk로 백업해주는 기능이 있습니다.
대표적인 방식들인 AOF 방식과 RDB 방식을 알아보겠습니다.
1. AOF 방식
Append Only File의 약자로 Redis의 모든 write/update 연산 자체를 파일에 기록하는 형식입니다.
AOF 방식은 저장할 내용이 많기에 파일이 커지고 주기적으로 압축하여 저장하는 과정이 필요하고 Redis 프로토콜 형태로 저장됩니다.
모든 연산을 기록하므로 장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우 사용하면 좋습니다.
APPENDFSYNC 옵션이 everysec 인 경후 최대 1초 사이의 데이터 유실이 가능할 수 있습니다.
2. RDB 방식
Snapshot 방식이라고도 하며 저장 당시 memory의 data를 그대로 사진찍듯이 찍어 파일로 저장하고 바이너리 파일 형태로 저장됩니다.
RDB는 백업이 필요하지만 어느 정도의 데이터 손실이 발생해도 괜찮은 경우 사용하면 좋습니다.
만약 SAVE 900 2 이라고 옵션을 설정하면 900초 동안 2개 이상의 키가 변경되었을 때 RDB 파일을 재작성 하라는 의미 이므로 900초 동안 1개의 키만 변경되면 RDB 파일은 재작성 되지 않게 되죠.
3. AOF + RDB

위 사진과 같은 방법으로 AOF, RDB 방법을 수행할 수 있다.
만약 제일 강력한 내구성이 필요한 경우 RDB와 AOF를 동시에 사용하라고 Redis 공식 문서에 나와있습니다.
두 가지 방식을 동시에 사용할 수 있다는 것이죠.
다양한 역할을 할 수 있는 Redis
Redis는 database로도 사용할 수 있지만 메시지 큐 등의 역할도 수행할 수 있습니다.
그리고 Redis로 구성할 수 있는 아키텍처도 여러개가 있는데요, 내용이 많아 자세히 설명해주시는 유튜브 영상 링크를 남기겠습니다.
https://www.youtube.com/watch?v=92NizoBL4uA
참고
