1. z-score?
Z-점수(Z-score)는 통계학에서 사용되는 개념으로, 어떤 데이터 포인트가 그 데이터 집합의 평균으로부터 얼마나 떨어져 있는지를 나타냅니다. Z-점수는 다음과 같은 공식으로 계산됩니다:

X는 특정 데이터 포인트, 평균은 데이터 집합의 평균값, 표준편차는 데이터 집합의 표준편차입니다.
Z-점수의 의미는 다음과 같습니다:
- Z-점수가 0이면, 해당 데이터 포인트는 평균과 같습니다.
- Z-점수가 양수이면, 해당 데이터 포인트는 평균보다 큽니다.
- 예를 들어, Z-점수가 1이면, 해당 데이터 포인트는 평균보다 1 표준편차만큼 더 큽니다. - Z-점수가 음수이면, 해당 데이터 포인트는 평균보다 작습니다.
- 예를 들어, Z-점수가 -2이면, 해당 데이터 포인트는 평균보다 2 표준편차만큼 더 작습니다.
간단히 말해, Z-점수는 데이터 포인트가 평균에 비해 얼마나 "표준적"이거나 "비표준적"인지를 알려줍니다. 이를 통해 데이터 포인트가 전체 데이터 집합에서 얼마나 특이한지를 판단할 수 있습니다.
2. z-score와 정규화의 차이?
Z-점수(Z-score)를 계산하는 과정과 데이터 정규화(normalization)는 비슷한 메커니즘이지만, 목적과 활용 상황이 다릅니다.
2.1 Z-점수 (Z-score)
- 목적: 데이터 포인트가 전체 데이터 집합에서 얼마나 표준적이거나 비표준적인지를 알려주기 위함입니다.
- 공식:
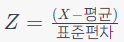
- 활용 상황: 통계적 추론, 이상치 탐지, 데이터 포인트의 상대적 위치 파악 등
2.2 데이터 정규화 (Normalization)
- 목적: 다양한 범위의 값을 가진 여러 특성을 비슷한 범위로 맞춰주기 위해 사용합니다. 이렇게 하면 머신러닝 알고리즘이 더 잘 동작하기도 합니다.
- 공식: 정규화의 일종인 Min-Max scaling을 예로 들면,

- 활용 상황: 머신러닝 모델 학습, 다양한 특성 값의 범위를 통일해야 할 때
2.3 차이점:
- 범위: Z-점수는 보통 -3에서 +3 사이의 값이 되지만, 이는 필수적인 것은 아닙니다. 데이터 정규화의 경우, 예를 들어 Min-Max scaling을 사용하면 값은 0과 1 사이로 변환됩니다.
- 데이터 분포: Z-점수는 원래 데이터가 정규분포를 따를 때 더 유용합니다. 데이터 정규화는 분포에 관계없이 적용됩니다.
- 통계 정보: Z-점수는 평균과 표준편차를 사용합니다. 정규화는 최소값과 최대값을 사용할 수 있습니다.
두 방법 모두 데이터를 변환하는 방법이지만, 그 목적과 활용 상황에 따라 적절한 방법을 선택해야 합니다.
3. z-score와 표준화의 차이?
Z-점수(Z-score)와 표준화(Standardization)는 종종 혼용되기도 하지만, 그들이 지칭하는 범위가 약간 다릅니다.
3.1 Z-점수 (Z-score):
- 개별 데이터 포인트: Z-점수는 특정 데이터 포인트가 그 데이터 집합의 평균으로부터 얼마나 떨어져 있는지를 측정합니다.
- 공식:
- 목적: 데이터 포인트의 상대적 위치나 이상치 여부를 판단하기 위해 사용됩니다.
3.2 표준화 (Standardization):
- 전체 데이터 집합: 표준화는 데이터 집합의 모든 값을 변환하여 평균이 0이고 표준편차가 1이 되도록 만듭니다. 실제로 표준화 과정에서 각 데이터 포인트를 해당 데이터 집합의 Z-점수로 변환합니다.
- 공식: 데이터 집합의 모든 값을
 식을 사용해 변환합니다.
식을 사용해 변환합니다. - 목적: 머신러닝 알고리즘에 입력되는 특성들의 스케일을 통일시키거나, 통계적 분석을 용이하게 하기 위해 사용됩니다.
3.3 차이점:
- 범위: Z-점수는 특정 데이터 포인트에 대한 것이며, 표준화는 데이터 집합 전체에 적용됩니다.
- 목적: Z-점수는 상대적 위치나 이상치 판별 등에 중점을 둡니다. 표준화는 주로 데이터 전처리에서 스케일 조정을 목적으로 합니다.
- 활용 상황: Z-점수는 통계적 분석이나 이상치 탐지 등에 사용되며, 표준화는 머신러닝 모델의 입력 데이터를 준비할 때나 여러 변수의 스케일을 맞출 필요가 있을 때 사용됩니다.
간단히 말하면, Z-점수는 개별 데이터 포인트에 대한 측정이고, 표준화는 전체 데이터 집합을 변환하는 과정 중 하나입니다. 표준화를 할 때, 실제로 하는 것은 각 데이터 포인트를 해당 데이터 집합의 Z-점수로 변환하는 것입니다.
4. 파이썬 코드로 z-score 구현해보기
4.1 개별 데이터 포인트의 Z-점수 구하기
import numpy as np
# 데이터 샘플
data = np.array([23, 45, 56, 12, 9, 38, 56, 48, 20, 8])
# 데이터 샘플의 평균과 표준편차 계산
mean = np.mean(data)
std_dev = np.std(data)
# 특정 데이터 포인트 (예: 45)
data_point = 45
# Z-점수 계산
z_score = (data_point - mean) / std_dev
print(f"Z-score of {data_point}: {z_score}")4.2 전체 데이터 샘플의 Z-점수 구하기
import numpy as np
# 데이터 샘플
data = np.array([23, 45, 56, 12, 9, 38, 56, 48, 20, 8])
# 데이터 샘플의 평균과 표준편차 계산
mean = np.mean(data)
std_dev = np.std(data)
# 전체 데이터의 Z-점수 계산
z_scores = (data - mean) / std_dev
print(f"Z-scores of the data: {z_scores}")
대한민국 4차 산업의 역군을 꿈꾸며.
https://bothbest.amebaownd.com/
https://bambooflooring.shopinfo.jp/
https://bamboochopsticks.storeinfo.jp/
https://bothbest.seesaa.net/
https://bothbest.mystrikingly.com
https://zybuluo.com/bothbest/note/2624938
https://bothbest.amebaownd.com/posts/57445395
https://bamboochopsticks.storeinfo.jp/posts/57445422
https://bambooflooring.shopinfo.jp/posts/57445427
https://bothbest.seesaa.net/article/518162762.html
https://bambooflooring.notion.site/bothbest-26f41b6b363980b0865fd008cf78ea7a
https://connect.usama.dev/blogs/37095/How-to-Choose-Bamboo-Decking-That-Lasts-15-Years
https://bothbest.mystrikingly.com/blog/choosing-bamboo-flooring-that-withstands-kids-and-pets
https://bambooflooring.notion.site/From-Forest-to-Floor-A-Step-by-Step-Guide-to-Bamboo-Flooring-Manufacturing-27141b6b363980f6bc45ea303bea1f0d