네트워크 (1)
컴퓨터 네트워크란?
컴퓨터 네트워크는 통신 및 데이터 교환을 허용하는 연결된 장치의 시스템이며 인터넷과 WWW는 현대 컴퓨터 네트워크의 핵심 구성 요소입니다.
현대 컴퓨터 네트워크에서 데이터를 어떻게 전달할까?
회선교환방식
회선교환 방식은 회선 독점을 통한 통신방식이라고 볼 수 있습니다.
회선교환 방식의 가장 큰 특징은 전용선 할당에 있습니다.
송수신을 연결하는 전용선을 설정하고 전송을 하는게 핵심입니다.
패킷교환방식
패킷교환은 회선교환과 다르게 전용선의 개념이 없습니다.
패킷교환은 전송하려는 데이터를 패킷이라는 단위로 나눠 네트워크망으로 뿌려주게 됩니다.
따라서 특정한 데이터가 100개의 패킷으로 분해되어 전송된다면, 100개의 패킷들은 라우터에의해 서로다른 경로로 전송될 수 있고, 최종적으로 목적지에 100개의 패킷이 전달되면 패킷의 순서를 통해 다시 원래의 데이터로 합쳐지는 방식입니다.
라우터와 스위치
스위치
목적지로 출발한 데이터를 중간에 적합한 경로로 스위칭해주는 역할을 하는것이 스위치이고 스위치는 데이터링크 계층에 속한다. 스위치는 데이터링크 계층에 속해 있으므로 MAC주소 기반으로 동작한다.
라우터
라우터 또한 목적지로 가는 적합한 경로를 찾아주는 라우팅 기능을 한다. 라우터는 IP주소를 기반으로 작동하여 네트워크 계층에 속해있다.
둘의 차이점
- 가장 대표적인 차이는 계층의 차이이다. 라우터는 네트워크계층에서 IP주소를 기반으로 동작하며 스위치는 MAC주소를 기반으로 데이터링크 계층에서 동작한다.
- 스위치는 브로드캐스트 도메인을 구분할 수 없는 반면 라우터는 브로드캐스트 도메인을 구분하여 서로 다른 네트워크 대역을 구분한다.
- 스위치는 불명확한 목적지를 가진 데이터를 처리할 때 모든 포트로 데이터를 퍼뜨리는 브로드캐스트를 하지만 라우터는 해당 데이터를 버린다.
- 스위치는 관리자의 설정이 필요 없지만 라우터는 관리자의 설정으로 라우팅 테이블 생성과 통신을 해야한다.
프로토콜이 뭔가요? 프로토콜 스택에 대해서 설명해주세요.
컴퓨터 네트워크에서의 프로토콜은 서로 다른 기종의 컴퓨터끼리 통신하기 위해서 미리 정해놓은 통신 규약 및 통신 약속입니다.
참고공부내용
https://velog.io/@mingle-mongle/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9C
OSI 7 Layer
OSI 7 계층은 네트워크에서 통신이 일어나는 과정을 7단계로 나눈 것을 말한다.
참고 공부 내용
https://shlee0882.tistory.com/110
TCP/IP
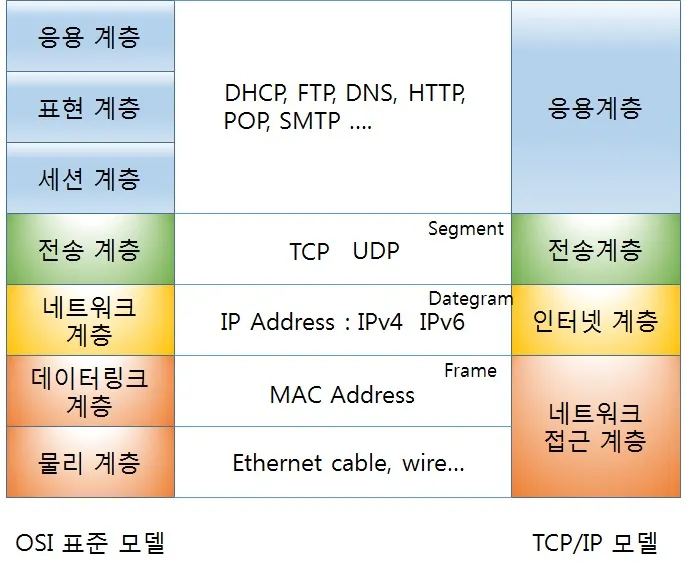
현재 수많은 프로그램들이 인터넷으로 통신하는 데 있어 가장 기반이 되는 프로토콜. 실제 대다수 프로그램은 TCP와 IP로 통신(정확히는 '네트워킹')하고 있다.
OSI 7 Layer 또는 TCP/IP 처럼 프로토콜들을 계층화하면 어떤 장점이 있을까요?
통신이 일어나는 과정을 단계별로 파악할 수 있다.
흐름을 한눈에 알아보기 쉽고, 사람들이 이해하기 쉽고, 7단계 중 특정한 곳에 이상이 생기면 다른 단계의 장비 및 소프트웨어를 건들이지 않고도 이상이 생긴 단계만 고칠 수 있다.
사용해봤던 프로토콜
HTTP
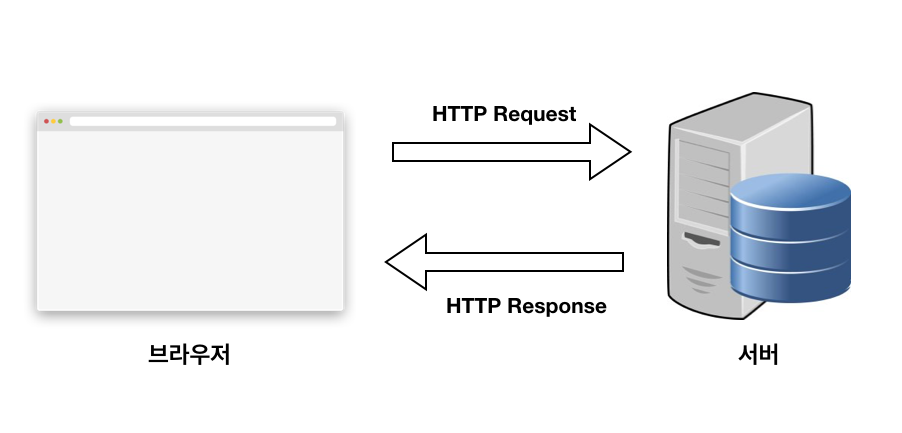
출처 : https://joshua1988.github.io/web-development/http-part1/
HTTP 프로토콜이란?
클라이언트와 서버 간 통신을 위한 통신 규칙 세트 또는 프로토콜입니다. 사용자가 웹 사이트를 방문하면 사용자 브라우저가 웹 서버에 HTTP 요청을 전송하고 웹 서버는 HTTP 응답으로 응답합니다.
HTTP의 요청/응답 모델
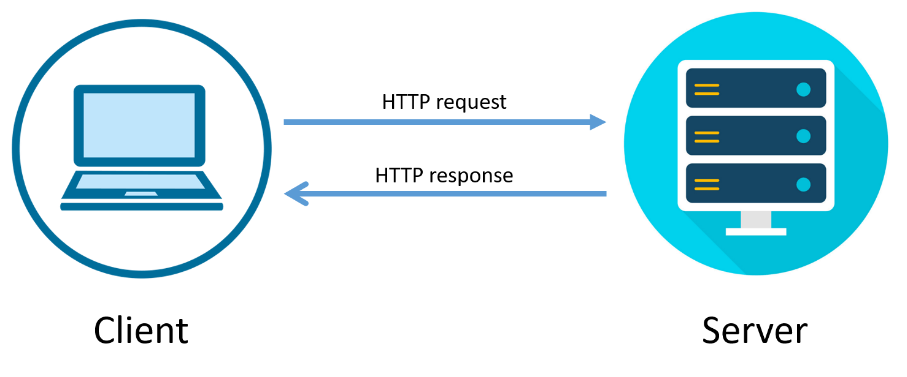
HTTP는 서버/클라이언트 모델을 따르는데 클라이언트에서 요청(Request)를 보내면 서버는 요청을 처리해서 응답(response)를 합니다.
- 요청 : GET/POST/PUT/PATCH/DELETE
- 응답: 상태코드 상태메세지
200 : 성공
300 : 리디렉션
400 : 실패(클라이언트)
500 : 실패(서버)
HTTP 메서드중 GET과 POST의 차이점
GET 은 클라이언트에서 서버로 어떠한 리소스로부터 정보를 요청하기 위해 사용되는 메서드이다.
POST는 클라이언트에서 서버로 리소스를 생성하거나 업데이트하기 위해 데이터를 보낼 때 사용 되는 메서드다.
POST는 전송할 데이터를 HTTP 메시지 body 부분에 담아서 서버로 보낸다.
GET은 서버의 리소스에서 데이터를 요청할 때, POST는 서버의 리소스를 새로 생성하거나 업데이트할 때 사용한다.
DB로 따지면 GET은 SELECT 에 가깝고, POST는 Create 에 가깝다고 보면 된다.
HTTP 메서드중 PUT과 PATCH의 차이점
리소스를 업데이트 한다는 점에서는 같은 역할을 하는 메소드처럼 보이지만 두개의 요청에는 약간의 차이가 있다.
PUT : 리소스의 모든 것을 업데이트 한다.
PATCH : 리소스의 일부를 업데이트 한다.
HTTP 상태 코드
1로 시작하는 경우 = Informational responses
: 요청을 받았으며 프로세스를 계속함
2로 시작하는 경우 = Success
: 요청을 성공적으로 받았으며 인식했고 수용했음
3로 시작하는 경우 = Redirection
: 클라이언트의 요청에 대해 적절한 위치를 제공하거나 대안의 응답을 제공
4로 시작하는 경우 = Client Error
: 클라이언트의 잘못된 요청
5로 시작하는 경우 = Server Error
: 정상적인 클라이언트의 요청에 대해 서버의 문제로 인해 응답할 수 없음
201 created
200 ok
404 not found : 해당 오류는 서버 자체는 존재하지만 서버에서 요청한 것을 찾을 수 없을 때
HTTP 헤더
HTTP 헤더는 클라이언트와 서버가 요청 또는 응답으로 부가적인 정보를 전송할 수 있도록 해줍니다.
- General header : 요청과 응답 모두에 적용되지만 바디에서 최종적으로 전송되는 데이터와는 관련이 없는 헤더.
- Request header : 페치될 리소스나 클라이언트 자체에 대한 자세한 정보를 포함하는 헤더. == 내가 보내는 메세지의 헤더
- Response header : 위치 또는 서버 자체에 대한 정보(이름, 버전 등)와 같이 응답에 대한 부가적인 정보를 갖는 헤더. == 내가 받은 메세지의 헤더
- Entity header: 컨텐츠 길이나 MIME 타입과 같이 엔티티 바디에 대한 자세한 정보를 포함하는 헤더.
HTTP의 무상태성(Stateless)
HTTP는 서버가 클라이언트의 상태를 보존하지 않는 무상태 프로토콜
장점 : 서버 확장성 높음. 무한한 서버 증설 가능 (스케일 아웃)
단점: 클라이언트가 추가 데이터를 전송해야 함 (서버에 저장되어 있지 않으므로)
-> 단순한 서비스 소개 화면 같은 경우엔 무상태로 설계할 수 있지만, 로그인 등 유저의 상태를 유지해야 하는 서비스라면 브라우저 쿠키, 서버 세션, 토큰 등을 이용해 상태를 유지해야 한다.
- 클라이언트가 요청할 때 필요한 데이터를 다 담아서 보내기 때문에 같은 기능을 하는 아무 서버나 호출해도 된다.
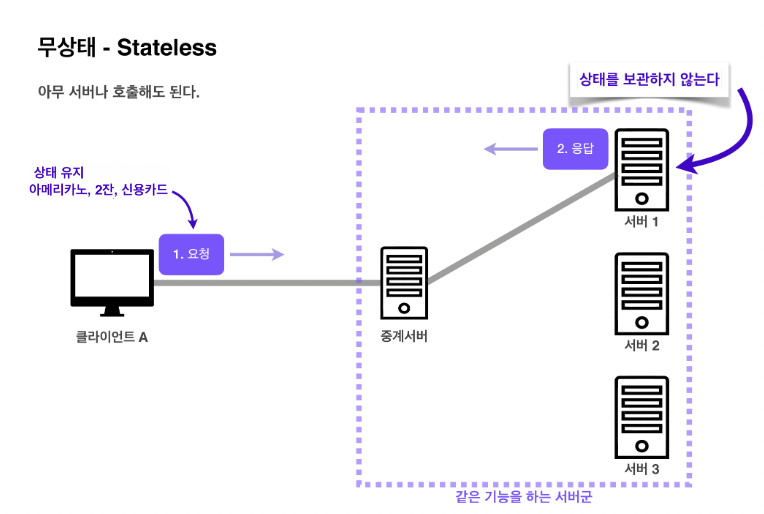
- 서버에 장애가 생겨도 다른 서버에서 응답을 전달하기 때문에 클라이언트는 다시 요청할 필요가 없다.
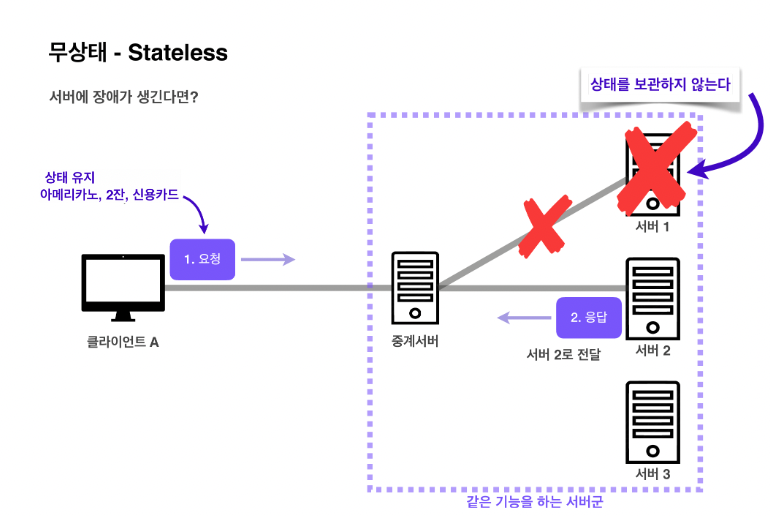
- 응답 서버를 쉽게 바꿀 수 있기 때문에 무한한 서버 증설이 가능하다.
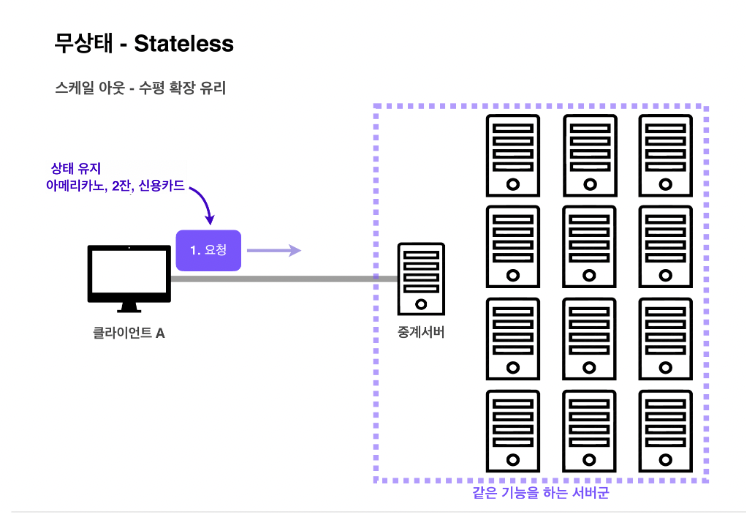
이미지 출처: https://velog.io/@pikadev1771/HTTP-pdptvkgo
HTTP Keep-Alive
HTTP 프로토콜의 Keep-Alive 기능은 클라이언트와 서버 간 요청 및 응답 과정을 효율적으로 유지하기 위해 사용됩니다. keep-alive를 활성화하면 하나의 TCP 연결을 여러 번 재사용하며 응답과 요청을 수행할 수 있습니다.
HTTP 프로토콜에서 클라이언트와 서버 간 여러 요청을 단일 TCP 연결을 재사용하는 방식으로 처리하는 기능을 말합니다. HTTP/1.1 프로토콜부터 도입됐습니다. 이 기능을 활성화하면 여러 HTTP 요청 및 응답 과정에서 발생하는 네트워크 오버헤드를 줄일 수 있습니다.
keep-alive를 사용하는 경우 HTTP 요청 헤더에 Connection: Keep-Alive라는 값을 포함시킵니다.
장점
keep-alive가 없으면 클라이언트와 서버는 각 요청과 응답에 대해 매번 새로운 TCP 연결을 생성하고 닫아야 합니다. 이 방식은 네트워크 리소스가 비효율적으로 사용됩니다. 반면 keep-alive를 사용하면 단일 TCP 연결에서 여러 요청과 응답이 이루어지기 때문에 네트워크 지연 시간이 줄어들고 웹 사이트 성능이 좋아집니다.
예시
keep-alive의 상황을 비유하자면, 전화 통화하는 상황을 떠올릴 수 있습니다. 한 고객이 고객센터에 전화를 걸어 제품에 대해 궁금한 정보를 하나씩 묻는다고 해봅시다. 이때 하나의 질문을 할 때마다 대답을 듣고 전화가 끊어진다고 생각해 보세요. 전화를 걸고 다시 물어보는 과정이 반복된다면 매우 피곤할 것입니다. 한번 연결된 전화를 통해 모든 궁금증을 해결할 수 있는 편이 훨씬 효율적입니다.
HTTP 파이프라이닝
HTTP 파이프라이닝은 응답을 기다리지 않고 단일 TCP 연결을 통해 여러 HTTP 요청을 보내는 기술입니다. 이를 통해 더 빠른 데이터 전송이 가능하고 클라이언트와 서버 간의 왕복 시간으로 인한 대기 시간이 줄어듭니다.
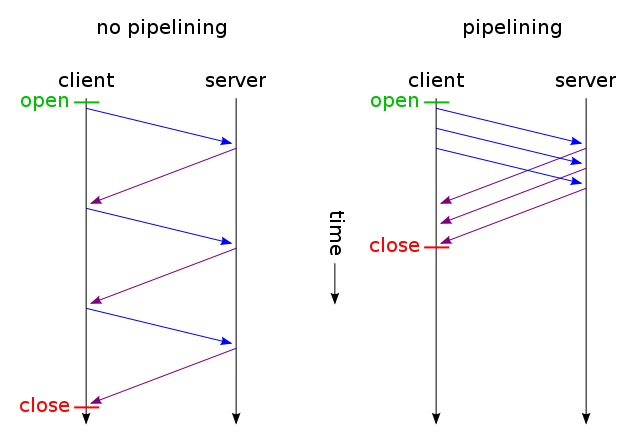
이미지출처: https://seonghui.github.io/TIL/docs/http/keep-alive-and-pipelining.html
최초의 요청이 완료되기 전에 다음 요청을 보내는 기술이다. 다음 요청까,지의 대기 시간을 없앰으로써, 네트워크 가동율을 높이고 성능을 향상시킨다. Keep-Alive 이용을 전제로 하며, 서버는 요청이 들어온 순서대로 응답을 반환한다.
HTTP/1.1, HTTP/2, HTTP/3 각각의 특징
HTTP/1.1
연결(Connection) 하나 당 하나의 요청을 처리하도록 설계되어 있습니다.(요청과 응답이 순차적으로 처리)
이런 설계 방식으로 다수의 리소스(image, css, script)를 처리하기 위해선 요청할 리소스 개수에 비례해서 Latency가 길어지게 됩니다.(동시전송, 속도, 성능문제)
HTTP/2
HTTP1.1의 성능에 초점을 맞추어 수정한 버전입니다. latency, 네트워크, 서버 리소스 사용량 등과 같은 성능 위조로 개선했습니다.
HTTP/3
가장 큰 특징은 TCP가 아닌 UDP를 사용한다는 것이다.
정확히 말하면 HTTP3는 QUIC라는 프로토콜 위에서 돌아가는 HTTP인데, QUIC는 Quick UDP Internet Connection의 약자로 UDP를 사용하는 프로토콜이다.
출처
- https://velog.io/@jihoon97/%EC%8A%A4%EC%9C%84%EC%B9%98-%EB%9D%BC%EC%9A%B0%ED%84%B0%EC%9D%98-%EC%B0%A8%EC%9D%B4
- https://shlee0882.tistory.com/110
- https://namu.wiki/w/TCP/IP
- https://velog.io/@fejigu/HTTP%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EC%9A%94%EC%B2%AD%EA%B3%BC-%EC%9D%91%EB%8B%B5
- https://blog.naver.com/lw_10page/221640822337
- https://velog.io/@pikadev1771/HTTP-pdptvkgo
- https://change-words.tistory.com/entry/HTTP-Keep-Alive
- https://wiki.yowu.dev/ko/Knowledge-base/Network/http-pipelining-how-to-improve-web-performance-with-multiple-requests
- https://jjam89.tistory.com/148
- https://velog.io/@kcwthing1210/HTTP-1.1-vs-HTTP-2.0-vs-HTTP-3.0

좋은 정보 얻어갑니다, 감사합니다.