모의면접3 DB
랜덤 I/O와 순차 I/O에 대해서 설명해주세요.
https://velog.io/@ddangle/%EC%88%9C%EC%B0%A8Sequential-IO%EC%99%80-%EB%9E%9C%EB%8D%A4Random-IO
우선, 랜덤 I/O(Random I/O, direct accss)는 하드 디스크 드라이브의 플래터(원판)을 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더(disk arm)를 이동시킨 다음 데이터를 읽는 것을 의미합니다. 그리고 순차 I/O(Sequential I/O) 또한 이 과정은 같습니다.
인덱스에 대해서 설명해주세요.
https://mangkyu.tistory.com/96
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 만약 우리가 책에서 원하는 내용을 찾는다고 하면, 책의 모든 페이지를 찾아 보는것은 오랜 시간이 걸린다. 그렇기 때문에 책의 저자들은 책의 맨 앞 또는 맨 뒤에 색인을 추가하는데, 데이터베이스의 index는 책의 색인과 같다.
데이터베이스에서도 테이블의 모든 데이터를 검색하면 시간이 오래 걸리기 때문에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 돕고 있다.
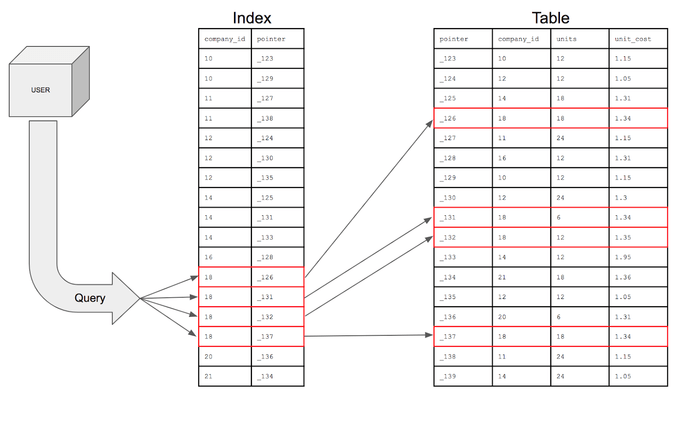
인덱스를 사용해본 경험에 대해서 설명해주세요.
아직 없습니다.
인덱스의 동작 방식에 대해서 설명해주세요.
https://brunch.co.kr/@skeks463/25
어떤 기준으로 인덱스를 설정해야할까요?
- 카디널리티 (Cardinality)
- 선택도 (Selectivity)
- 조회 활용도
- 수정 빈도
인덱스가 잘 동작하고 있는지 어떻게 확인할 수 있을까요?
테이블에 인덱스를 많이 설정하면 좋을까요?
'위의 (1) 어떤 컬럼에 인덱스를 설정해야 할까?'를 보았다면 인덱스를 많이 설정하면 안되는 이유를 어렴풋하게 이해할 수도 있습니다.
① 인덱스 설정 시, 데이터베이스에 할당된 메모리를 사용하여 테이블 형태로 저장되게 됩니다.
(즉, 인덱스가 많아지면 데이터베이스의 메모리를 많이 잡아먹게 됩니다.)
② 인덱스로 지정된 컬럼의 값이 바뀌게 되면 인덱스 테이블이 갱신되어야 하므로 느려질 수 있습니다.
위와 같은 이유로 인덱스를 계속해서 만드는 것이 하나의 쿼리문을 빠르게 만들 수는 있지만, 전체적인 데이터베이스의 성능 부하를 초래합니다.
쿼리 실행 계획에 대해서 설명해주세요. 실행 계획을 확인해본적이 있나요?
https://jeong-pro.tistory.com/243
커버링 인덱스(covering index)에 대해서 설명해주세요.
https://velog.io/@boo105/%EC%BB%A4%EB%B2%84%EB%A7%81-%EC%9D%B8%EB%8D%B1%EC%8A%A4
커버링 인덱스란, 쿼리를 충족시키는데 필요한 모든 데이터를 갖고 있는 인덱스를 말합니다.
다중 컬럼 인덱스(Multi-column index)에 대해서 설명해주세요.
https://code-factory.tistory.com/24
인덱스에서 사용되는 B-Tree와 B+Tree에 대해서 설명해주세요.
https://code-lab1.tistory.com/217
보통 B 트리라고 하면 B- 트리를 의미한다. B 트리는 트리 자료구조의 일종으로 이진트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조이다.
인덱스에서 사용되는 HashTable에 대해서 설명해주세요.
https://mangkyu.tistory.com/102
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다. 해시 테이블은 각각의 Key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색하게 된다. 여기서 실제 값이 저장되는 장소를 버킷 또는 슬롯이라고 한다.
클러스터드 인덱스와 논클러스터드 인덱스의 차이는 무엇일까요?
-
클러스터
테이블당 1개씩만 허용된다.
물리적으로 행을 재배열한다.
PK설정 시 그 칼럼은 자동으로 클러스터드 인덱스가 만들어진다.
인덱스 자체의 리프 페이지가 곧 데이터이다. 즉 테이블 자체가 인덱스이다. (따로 인덱스 페이지를 만들지 않는다.)
데이터 입력, 수정, 삭제 시 항상 정렬 상태를 유지한다.
비 클러스형 인덱스보다 검색 속도는 더 빠르다. 하지만 데이터의 입력. 수정, 삭제는 느리다.
30% 이내에서 사용해야 좋은 선택도를 가진다. -
넌클러스터
테이블당 약 240개의 인덱스를 만들 수 있다.
인덱스 페이지는 로그파일에 저장된다.
레코드의 원본은 정렬되지 않고, 인덱스 페이지만 정렬된다.
인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 포인터(RID)이기 때문에 클러스터형보다 검색 속도는 더 느리지만 데이터의 입력, 수정, 삭제는 더 빠르다.
인덱스를 생성할 때 데이터 페이지는 그냥 둔 상태에서 별도의 인덱스 페이지를 따로 만들기 때문에 용량을 더 차지한다
3% 이내에서 사용해야 좋은 선택도를 가진다.
인덱스 스캔 방식에 대해서 설명해주세요.
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=gglee0127&logNo=221336088285
Index Range Scan, Index Full Scan, Index Unique Scan, Index Skip Scan 등이 있다.
인덱스 사용시 주의해야할 점에 대해서 알려주세요.
https://bcp0109.tistory.com/365
. 인덱스 사용 시 주의사항
다중 인덱스를 사용할 때 범위 조건은 인덱스를 타지만 이후 컬럼들은 인덱스를 타지 않음 범위 조건으로 사용할 때 주의
인덱스로 지정한 컬럼은 그대로 사용해야 함 WHERE age * 10 > 20 처럼 조회조건에 있는 컬럼을 변경하면 안됨
GROUP BY 사용시 인덱스가 걸리는 조건에 대해 설명해주세요.
https://jojoldu.tistory.com/476
GROUP BY 절에 명시된 컬럼이 인덱스 컬럼의 순서와 같아야 한다.
인덱스 컬럼 중 뒤에 있는 컬럼이 GROUP BY 절에 명시되지 않아도 인덱스는 사용할 수 있다.
