
01. 데이터 분석 기초
1. 목표
- 파이썬을 활용한 데이터 분석 입문
- 공공 데이터를 활용해 데이터 분석 실습
(이전 MySQL에서 이미 한 경험이 있다.) - NumPy, Pandas, Matplotlib과 같은 데이터 분석 라이브러리 기초 사용법에 대한 이해
2. Data Science 영역
1) Data Analysis or Analyst (⇒ 송길영 바이브 부사장, 마인드 마이너)
- 데이터에서 인사이트를 뽑아내는 역할
- 통계지식이 필요 + 도메인(메인) + 데이터 + 분석스킬 ⇒ 나도 데이터 분석가네? ⇒ 연봉 2배씩.
- EX)
- PM으로써의 DS or 데이터 분석가
- 성과 측정 지표 정의
- MECE 기법 (분석 방법론)
- 결제 전환율 개선
- 데이터 로그 설계
- AB 테스트
- 마케터로써의 DS or 데이터 분석가
참고: Data Scientist & Analyst 에게 무엇이든 물어보세요! | 뱅크샐러드 (banksalad.com)
- PM으로써의 DS or 데이터 분석가
- 리포트 작성
2) Data Engineering → 개발에 자신이 있는 분들
- 데이터를 수집 및 저장하는 역할 (빅데이터 시스템 구축)
- 기존에 백엔드 엔지니어 분들이 Hadoop에 대한 이해를 바탕으로 커리어 전환
3) Data Visualization
- 말 그대로 데이터 시각화하는 작업.
- 기존에 프론트엔드 엔지니어 분들이 많이 포진해계심.
- 대시보드
- 대표적인 예: 자동차 계기판 (현재의 자동차 및 주행 상황에 대한 정보를 한눈에 전달)
3. 대표적인 데이터 분석 Package
-
대화형 파이썬 툴
: Jupyter - Colab -
통계 및 수학적 계산을 도와주는 라이브러리
: NumPy -
데이터 핸들링 (엑셀 다루기) - 데이터 정제(전처리) (⇒ Garbage in, Garbage out)
: Pandas / SQL / 테블로
-
엑셀로 데이터 분석 할 수 있는데 왜 파이썬을 배워야 합니까?
(1) 빅데이터 핸들링
⇒ 데이터가 100만행이면 엑셀이 열릴까요? / 컬럼도 갯수가 최소 10개 20개 갑니다.
⇒ 데이터 갯수가 차원이 달진다. / 반복문 ⇒ 10만개씩 10번 반복하면 되지 않을까요?(2) 자동화
⇒ 파이썬으로 한번 코드로 작성을 해놓으면 → 계속 사용 가능. 반복하지 않아도 됨.
-
데이터 시각화 ⇒ (1) 설득 (2) 데이터의 숨어있는 패턴 발견
: Matplotlib ⇒ Seaborn ⇒ Plotly -
머신러닝 / 딥러닝 → 미래를 예측하기 위해서 활용 & 패턴 찾기
⇒ 어떤 결과를 분석(연구)해서 결과를 내놓았다고 해봅시다.
⇒ 그 다음 사람들의 반응은 뭘까요? ⇒ 잘봤습니다. 그래서 앞으로는 어떻게 되나요? (예측)- Scikit-learn
- Tensorflow
- Keras
1) Jupyter
- 웹 브라우저 기반에서 파이썬 코드를 작성하고 실행하게 도와주는 툴 ⇒ colab
2) NumPy
- Numarray와 Numeric이라는 기존 파이썬 패키지를 계승해서 나온 수학 및 과학 연산을 위한 파이썬 패키지
- 선형대수, 행렬 또는 다차원 배열을 쉽게 처리할 수 있도록 도와주는 패키지
- 수학적인 연산처리에도 자주 활용됨.
3) Pandas
- panda는 panel data와 analysis 줄여서 표현
- 데이터 조작 및 분석을 위한 파이썬 패키지. (원래는 금융 데이터 분석을 위해 만들어짐)
- 레이 달리오 <원칙>
- 테이블 형태의 데이터를 다루는 DataFrame 자료형을 제공
- SQL과 같은 데이터 조회, 분석, 삭제, 수정등의 작업이 가능
4) Matplotlib
- 데이터 시각화를 도와주는 툴로써 그래프와 차트 등을 그릴 수 있게 도와준다.
5) Seaborn
- Matplotlib 패키지에서 지원하지 않는 시각화 작업 가능
- facebook 개발자 6만명(전세계) 페이스북 코리아도 포함되겠죠. 저 숫자에.… 20~30% → 1만명
- 사람이 늘어날수록 백엔드가 기하급수적으로 많이 필요해요.
- 투자 받는 회사들 보세요. → 전부다 백엔드 뽑습니다. 트레픽 핸들링.
4. 데이터 분석이란?
- 위와 같은 툴들 또는 파이썬을 잘 알아야 한다?
- 분석툴을 잘 다루면 데이터 분석을 잘 할 수 있을까?
→ x
파이썬 잘하고, 툴 잘 다루면 분석에 도움을 받을 수 있으나, 그것이 데이터 분석의 본질은 아니다.
그래서 BI(Business Inteligence)-Samsung이 만든 BrighticsAI 툴들을 마주하면 드는 생각이 “이걸 어디서부터 어떻게 접근해야 하는 거지?”하는 생각이 들거다.
→ 본질이 비어서 그런 것.
- 본질 : 데이터(석유)를 통해 얻고자 하는 것이 무엇인가?
- 분석의 목적에 맞게 툴을 배워야 할 것이다.
- 마케팅 분석이 목적인가?
- 로그 데이터 분석이 목적인가?
- 분석의 목적에 맞게 툴을 배워야 할 것이다.
5. 데이터 분석 과정
1) 데이터 분석 설계
- 방향성 기획 (⇒데이터를 통해 얻고자 하는 것이 무엇인가?)
- 방법론 검토
- 문제 정의
- 데이터 분석을 통해 무엇을 알고 싶은지, 도출하고자 하는 결론은 무엇인지?
- 가설 설정
- H사 프로젝트
- 보험 영업팀이 고객데이터 100만을 갖고 있어요. 근데 도대체 누구한테 전화를 해야해?
- 금융 자산 금액, 최종 학위, 나이, 차량 운용 여부, 기존 보험 금액, 동네, 자가여부 (컬럼이 수백개) → 보험을 가입할 확률이 높은 고객에게 먼저 전화를 한다.
- 보험 영업팀이 고객데이터 100만을 갖고 있어요. 근데 도대체 누구한테 전화를 해야해?
- H사 프로젝트
2) 데이터 준비
⇒ SQL, Crawaling, 개발자에게 요청, 공공데이터 API
- 데이터 불러오기
- 형태 파악하기
3) 데이터 가공 (70~80%)
⇒ 파이썬 / SQL
- 추출 및 정제
garbage in garbage out
: 요리 재료(데이터)를 샀으니 바로 요리를 하는 것이 아니라 → 요리 재료를 손질해야겠죠?
- 파생 변수(컬럼) 생성
- column1, column2, column3, column4 ⇒ (column1+column2)/2
- 구별 외국인 수 / 구별 인구수
⇒ 해당 구의 외국인 비율
⇒ 인사이트를 얻을 수 있는 컬럼을 생성하셔야 합니다.
- 데이터 구조에 대한 전처리
- 매출 데이터와 상품 데이터를 어떻게 결합할 것인지
- 데이터 내용에 대한 전처리
- 일별 데이터, 월별 또는 연간 데이터로 변환
- 분석에 도움이될만한 새로운 컬럼을 생성
4) 데이터 분석
- 통계 분석
- 데이터의 패턴을 찾아본다. ⇒ 설득을 위해서.
- 그래프 및 시각화
- 어떤 형태로 시각화 했을 때 내가 원하는 방향으로 상대방을 잘 설득할 수 있을지? 에 대한 고민.
5) 결론 도출
⇒ storytelling, 포인트: 설득 / 납득
- 분석 결과 해석
- 분석 결과 정리
02. 수학적 연산을 위한 Numpy
1. Numpy 특징
- Numarray와 Numeric이라는 기존 파이썬 패키지를 계승해서 나온 수학 및 과학 연산을 위한 파이썬 패키지
- 선형대수, 행렬 또는 다차원 배열을 쉽게 처리할 수 있도록 도와주는 패키지
- 수학적인 연산처리에도 자주 활용됨.
- 다차원 배열 객체(ndarray)를 통해 벡터 및 행렬을 사용하는 선형 대수 계산에 주로 사용
- 순수 파이썬에 비해 속도가 빠름.
2. 설치 및 import 방법
# Colab에서 설치
%pip install numpy
# 라이브러리 import
import numpy as np- 구글의 코랩
: 코랩 실행 시 Ctrl(Command) + Enter 를 동시에 누르면 실행 - VSC ⇒ ipynb 확장자 (jupyter 노트북)
3. Numpy 배열의 종류와 axis 축
-
nD array: N차원(Dimension) 배열(Array) 객체
- 1D array: 1차원 배열 (Vector) ⇒ axis=0, 열
- 2D array: 2차원 배열 (Matrix) ⇒ axis=1, 행
- 3D array: 3차원 배열 (Tensor) ⇒ axis=2, 채널
np.arange(5) # array([0, 1, 2, 3, 4]) np.zeros((3,2), dtype='int32') # array([[0, 0], [0, 0], [0, 0]], dtype=int32) np.zeros((3,2), dtype='int64') # array([[0, 0], [0, 0], [0, 0]]) np.ones((3,2), dtype='int32') # array([[1, 1], [1, 1], [1, 1]], dtype=int32) np.ones((3,2), dtype='int64') # array([[1, 1], [1, 1], [1, 1]]) -
nD array 생성
- arange
- zeros : ‘0’으로 채워진 행렬을 생성
- ones : ‘1’ 로 채워진 행렬을 생성
-
reshape - 차원과 크기 변경
a = np.arange(6).reshape((3, 2)) a array([[0, 1], [2, 3], [4, 5]]) -
행렬 내적(=행렬 곱) 계산 (np.dot)
1행1열 ⇒ 1*5 + 2*7 = 19
1행2열 ⇒ 1*6 + 2*8 = 22
2행1열 ⇒ 3*5 + 4*7 = 43
2행1열 ⇒ 3*6 + 4*8 = 50
---
1 2 5 6 19 22
* =
3 4 7 8 43 504. Numpy 예제
Q1. 2차원 배열에서 행렬의 각 행 평균을 계산하는 코드를 작성하세요.
# np.mean() == 평균 계산
arr = np.array([[1,2,3], [4,5,6], [7,8,9]])
arr.shape
# (3, 3)
np.mean((arr), axis=1, dtype="int64")
-> array([2, 5, 8])
=> 각 행의 평균은 2, 5, 8Q2. 1차원 배열에서 짝수 인덱스의 값을 출력하는 코드를 작성하세요.
arr = np.array([1,2,3,4,5,6])
even_indexes = np.arange(0, arr.size, 2)
print(arr[even_indexes])
=> [1 3 5]
------------------------------------------------
arr[even_indexes]
=> array([1, 3, 5])인덱스는 0부터 시작하기때문에 1, 3, 5 가 맞습니다.
Q3. 2차원 배열의 주 대각선 상에 있는 원소들을 출력하는 코드를 작성하세요.
# diag()
arr = np.array([[1,2,3], [4,5,6], [7,8,9]])
arr.shape
# (3, 3)
np.diag(arr)
=> array([1, 5, 9])- 주대각선 이란?
: 삼각행렬
Q4. 2차원 배열에서 각 열의 표준편차를 계산하는 코드를 작성하세요.
# std()
arr = np.array([[1,2,3], [4,5,6], [7,8,9]])
np.std(arr)
# 2.581988897471611
print(arr)
=> [[1 2 3]
[4 5 6]
[7 8 9]]
np.std(arr, axis=0)
=> array([2.44948974, 2.44948974, 2.44948974])Q5. 1차원 배열에서 중앙값(median)을 계산하는 코드를 작성하세요.
# median()
arr = np.array([1,2,3,4,5])
np.median(arr)
=> 3.0Q6. 1차원 배열에서 원소의 값이 5 이상인 것들만 출력하는 코드를 작성하세요.
# Boolean Indexing
arr = np.array([1,4,6,3,9,2,7,8])
arr >= 5 # 5보다 크거나 같으면 True | 5보다 작으면 False
=> array([False, False, True, False, True, False, True, True])
arr[arr >= 5] # 5보다 크거나 같은 값만 출력
=> array([6, 9, 7, 8])Q7. 1차원 배열에서 원소의 값이 3 또는 5인 것들의 인덱스를 출력하는 코드를 작성하세요.
# where()
arr = np.array([1,3,5,2,4,6,3,5,7])
np.where((arr == 3) | (arr == 5))
=> (array([1, 2, 6, 7]),) # 3또는 5인 인덱스는 1,2,6,7번에 위치
# and == &
# or == |5. Numpy 실제 사용 사례 (gaussian_process)
머신러닝에서 많이 사용하는 알고리즘이 있다.
03. 데이터 분석의 핵심 Pandas
1. Pandas 특징
- panda는 panel data analysis 줄여서 표현
- 데이터 조작 및 분석을 위한 파이썬 패키지. (원래는 금융 데이터 분석을 위해 만들어짐)
- 레이달리오의 <원칙>
- 테이블 형태의 데이터를 다루는 DataFrame(=Excel, CSV) 자료형을 제공
- SQL과 같은 데이터 조회, 분석, 삭제, 수정등의 작업이 가능
- Numpy 기반에서 개발
- 대용량의 데이터를 다룰 때 엑셀보다 속도가 훨씬 빠름.
2. Pandas 설치 및 import 방법
# Colab에서 설치
%pip install pandas
# 라이브러리 import
import pandas as pd3. Pandas 함수
# DF (Data Frame) = Excel : 2개 이상의 Series 데이터
data = {
"country": ["kor", "usa", "china", "japan"],
"rank": [1,2,3,4],
"grade": ["A", "B", "C", "D"]
}
df = pd.DataFrame(data) # csv to json, json to csv, xlsx
df-
출력
index country rank grade 0 kor 1 A 1 usa 2 B 2 china 3 C 3 japan 4 D
1) 파일 로드 및 저장
- read_csv, read_excel, readl_html, to_csv, to_excel
2) 데이터 확인
- df.shape, df.info, df.columns, df.dtypes, df.head, df.tail
# 데이터 설랙션 → 데이터를 불러오는 방법
# 1) df.컬럼, df['컬럼']
print(df.country)
print(df.grade)
df[['country','rank']]
> 출력
0 kor
1 usa
2 china
3 japan
Name: country, dtype: object
0 A
1 B
2 C
3 D
Name: grade, dtype: object| index | country | rank |
|---|---|---|
| 0 | kor | 1 |
| 1 | usa | 2 |
| 2 | china | 3 |
| 3 | japan | 4 |
# 2) df. loc[인덱스값, 컬럼명]
print(df.loc[1])
print(df.loc[:])
print(df.loc[:, 'grade'])
df.loc[:,['grade', 'country']]
# 행 순서가 내가 적은 컬럼 순서대로 출력됨.
> 출력
country usa
rank 2
grade B
Name: 1, dtype: object
country rank grade
0 kor 1 A
1 usa 2 B
2 china 3 C
3 japan 4 D
0 A
1 B
2 C
3 D
Name: grade, dtype: object| index | grade | country |
|---|---|---|
| 0 | A | kor |
| 1 | B | usa |
| 2 | C | china |
| 3 | D | japan |
-
조건문도 가능하다.
print(df['rank'] > 2) # boolen indexing 형태로 출력 df[df['rank'] > 2] # df.loc[df['rank'] > 2] 와 동일 df.loc[df['rank'] > 2, ['grade', 'country']] # df[df['rank'] > 2][['grade', 'country']] 와 동일 > 출력 0 False 1 False 2 True 3 True Name: rank, dtype: boolindex country rank grade 2 china 3 C 3 japan 4 D index grade country 2 C china 3 D japan
# df.iloc[ ] → location 기반으로 항상 숫자값을 필요로 한다.3) 값 정렬
- sort_index() → index 순서대로 정렬
- sort_values(by=”컬럼 값”) → by에 주어진 값대로 정렬
ascending=False: 내림차순 정렬
df['new_rank'] = [10, 100, 30]
df.sort_values(by='new_rank')- 출력
| index | country | grade | rank | new_rank |
|---|---|---|---|---|
| 0 | kor | A | 1 | 10 |
| 2 | china | C | 3 | 30 |
| 1 | usa | B | 2 | 100 |
4) null 데이터(NaN) 처리
- isnull() => 데이터의 null 여부
- fillna() => null 데이터를 채워주세요.
- dropna() => null 데이터를 지워주세요.
# null 데이터(NaN) 처리
# 데이터 값 변경
import numpy as np
df.loc[1, 'grade'] = np.nan
df.isnull().sum() # null 데이터 갯수
df.isnull() # boolen indexing
> 출력
country 0
grade 1
rank 0
new_rank 0
dtype: int64| index | country | grade | rank | new_rank |
|---|---|---|---|---|
| 0 | false | false | false | false |
| 1 | false | true | false | false |
| 2 | false | false | false | false |
5) 특정 column / row 삭제
- df.drop([’column_name’], axis=1)
- df.drop[’row’]
- inplace 특성을 사용해서 완전히 삭제 가능. (
inplace = True) - 또는, 기존의 데이터에 덮어씌우기로 완전히 삭제 가능.
- inplace 특성을 사용해서 완전히 삭제 가능. (
# 삭제 (drop)
# 1) 행 데이터 삭제 방법
df.drop([3], inplace=True)
# 2) 컬럼을 삭제
df = df.drop('rank', axis=1)
df['rank'] = [1,2,3]- 출력
| index | country | grade | rank |
|---|---|---|---|
| 0 | kor | A | 1 |
| 1 | usa | B | 2 |
| 2 | china | C | 3 |
6) 특정 column 이름 변경
- df.rename(columns={’A’:’B’})
7) DataFrame 2개 합치기
- pd.concat([df1, df2])
8) 중복 관리
- 중복확인: df.duplicated
- 중복제거: df.drop_duplicates
4. Pandas 구성

- Series: 1개의 컬럼 값으로 구성된 1차원 데이터 셋
- DataFrame: 컬럼과 행으로 구성된 2차원 데이터 셋
- Index: Series와 DataFrame의 고유한 키 값(unique ID)
# Series
data = ['a', 'b', 'c', 'd', 'e']
type(data)
se = pd.Series(data)
type(se)
print(se)
print(se.index)
print(se.values)
print("\n")
# slicing
se[0:3]
# Series 이름, index 이름 생성
se.name = "alphabet"
se.index.name = 'index'
print(se)
> 출력
0 a
1 b
2 c
3 d
4 e
dtype: object
RangeIndex(start=0, stop=5, step=1)
['a' 'b' 'c' 'd' 'e']
index
0 a
1 b
2 c
3 d
4 e
Name: alphabet, dtype: object5. 기술 통계 (descriptive statistics)
# 기술 통계
df.info()
df.describe()
> 출력
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 3 non-null object
1 grade 3 non-null object
2 rank 3 non-null int64
dtypes: int64(1), object(2)
memory usage: 200.0+ bytes| index | rank |
|---|---|
| count | 3.0 |
| mean | 2.0 |
| std | 1.0 |
| min | 1.0 |
| 25% | 1.5 |
| 50% | 2.0 |
| 75% | 2.5 |
| max | 3.0 |
기술통계는 변수의 평균(M)과 표준편차(SD) 그리고 최댓값(MAX)과 최솟값(MIN)을 보고자 할 때 사용하는 분석이다.
-
주로 논문에서 많이 볼 수 있습니다.
-
이 기술통계를 엑셀에서 다루는게 쉽지가 않은반면, pandas는 자동으로 계산해준다.
-
- count: null 을 제외한 데이터 개수
- min, max: 최솟값, 최댓값
- sum: 합
- cumprod: 누적합
- mean: 평균값 (전체 데이터 합의 평균)
- median: 중앙값 (전체 데이터 범위 중의 중간값, 2/4 분위수와 같다.)
- quantile: 분위수 (1/4, 2/4, 3/4)
- var: 표본분산
- std: 표준편차 (데이터가 얼마나 흩어져있는지 체크)
- describe: 요약통계량
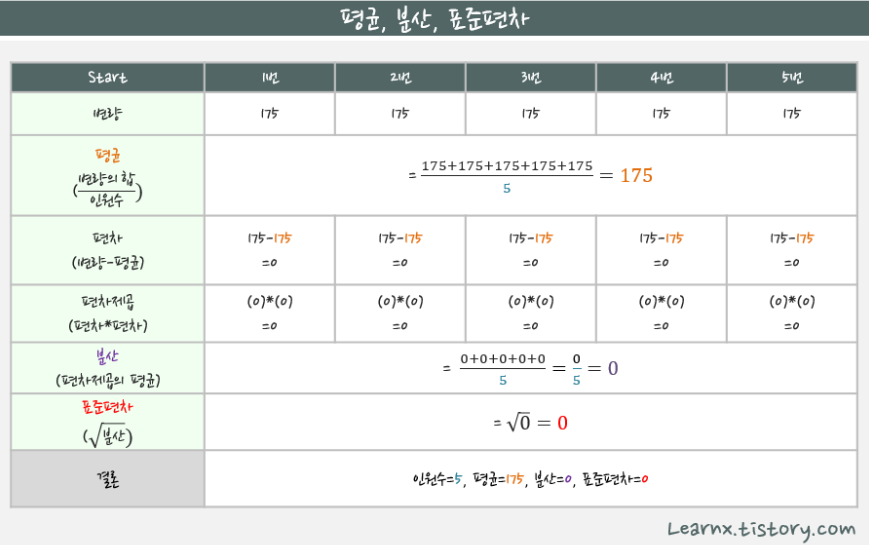
- 평균(mean, average): 주어진 수의 합을 측정개수로 나눈 값으로, 대표값 중 하나
- 분산(Variance): 변량들이 퍼져있는 정도, 분산이 크면 들죽날죽 불안정하다는 의미
- 표준편차(standard deviation): 분산은 수치가 너무 커서, 제곱근으로 적당하게 줄인 값

표준편차가 크면, 수치들이 전반적으로 들죽날죽 컸다 작았다 제멋대로구나,
표준편차가 작으면, 수치들이 고만고만 하구나, 하고 이해하시면 됩니다.
-
정리
- 표준편차가 작다 -> 그래프는 뾰족하다 -> 데이터가 고르지않다.
- 표준편차가 크다 -> 데이터의 편차가 크지 않고 평균에 모여있다 -> 데이터가 고르다.
6. One Sheet
Pandas의 목적은 One Sheet를 해결하는 것이다.
7. 연습 문제
아래 영화 데이터를 가지고 연습 문제를 진행해보려고 한다.
-
영화 데이터
import pandas as pd json_data = { "columns": ["Movie", "Release Year", "Audience", "Rating"], "index": [0, 1, 2, 3, 4, 5, 6, 7], "data": [ ["Avengers", 2012, 1500, 8.8], ["Interstellar", 2014, 1100, 9.1], ["Frozen", 2013, 1020, 8.5], ["About Time", 2013, 950, 8.7], ["The Dark Knight", 2008, 1300, 9.0], ["Inception", 2010, 1200, 8.8], ["La La Land", 2016, 800, 8.6], ["Toy Story", 2010, 980, 8.5] ] } # JSON 데이터를 DataFrame으로 변환 df = pd.DataFrame(json_data['data'], columns=json_data['columns']) df
1) 전체 데이터 중에서 ''Moive 정보만 출력하시오.
df.Movie
df["Movie"]2) 전체 데이터 중에서 'Movie','Rating' 정보를 출력하시오.
df[["Movie", "Rating"]]3) 2013년 이후에 개봉한 영화 데이터 중에서 'Movie','Rating' 정보를 출력하시오.
# df[df["Release Year"] > 2013]
# df[df["Release Year"] > 2013][["Movie", "Rating"]]
df.loc[df["Release Year"] > 2013]4) 주어진 계산식을 참고하여 'Recommend' Column을 추가하시오.
# Recommend = (Audience * Rating) // 100
df["Recommend"] = (df["Audience"] * df["Rating"]) //1005) 전체 데이터를 'Release Year' 기준 내림차순으로 출력하시오.
df.sort_values(by="Recommend", ascending=False)
df.sort_values(by="Recommend", ascending=False).head(5) # 상위 다섯개8. 추가 연습 문제
1) 데이터프레임에서 특정 열(컬럼) 삭제하기
df.drop('column_name', axis=1, inplace=True)2) 데이터프레임에서 결측치(누락값) 있는 행 제거하기
df.dropna(inplace=True)3) 데이터프레임에서 중복된 행 제거하기
df.drop_duplicates(inplace=True)4) 데이터프레임에서 특정 조건에 맞는 행 선택하기
df[df['column_name'] == 'value']5) 데이터프레임에서 특정 열의 값에 따라 그룹화하기
grouped_df = df.groupby('column_name')6) 그룹화한 데이터프레임에서 특정 통계값 계산하기(예: 평균)
grouped_df.mean()7) 데이터프레임에서 특정 열의 값에 따라 정렬하기
df.sort_values('column_name', inplace=True)- inplace 까지 하여 변경사항 저장까지 완료.
8) 데이터프레임에서 특정 열의 값에 따라 내림차순으로 정렬하기
df.sort_values('column_name', inplace=True, ascending=False)9) 데이터프레임에서 특정 열의 값들에 대해 빈도수 구하기
df['column_name'].value_counts()10) 데이터프레임에서 특정 문자열이 포함된 행 선택하기
df['column_name'].value_counts()11) 데이터프레임에서 특정 문자열로 시작하는 행 선택하기
df[df['column_name'].str.startswith('text')]12) 데이터프레임에서 특정 문자열로 끝나는 행 선택하기
df[df['column_name'].str.endswith('text')]13) 데이터프레임에서 특정 문자열을 다른 문자열로 대체하기
df['column_name'] = df['column_name'].str.replace('old_text', 'new_text')14) 데이터프레임에서 특정 열에 대해 원-핫 인코딩하기
pd.get_dummies(df['column_name'])15) 데이터프레임에서 특정 열에 대해 히스토그램 그리기
df['column_name'].hist()16) 데이터프레임에서 특정 열에 대해 박스 플롯 그리기
df.boxplot(column='column_name')17) 데이터프레임에서 특정 열에 대해 산점도 그리기
df.plot.scatter(x='column1', y='column2')04. 시각화를 돕는 Matplotlib, Seaborn, Plotly
1. 시각화가 필요한 이유
- 많은 양의 데이터를 한눈에 볼 수 있다.
- 인사이트를 뽑아낼 수 있다.
- 테블로
- 숫자로만 볼 때 보이지 않던 것들이 시각화를 통해 드러나는 경우가 많다.
- 주식 차트도 데이터를 시각화 한 것. (시가, 종가, 현재가, 거래량 등)
- 타인을 설득할 때의 도구가 된다.
- 결국 데이터를 뽑아내는 것 또한 타인의 설득하기 위한 스토리 텔링의 전초가 될 수 있다.
- 데이터 기반의 의사결정에 도움을 준다.
- 미국 정부의 예산 → 영역이 클 수록 많은 투자 이루어질 예정
- 데이터 시각화에는 정답은 없다.
2. Matplotlib 특징
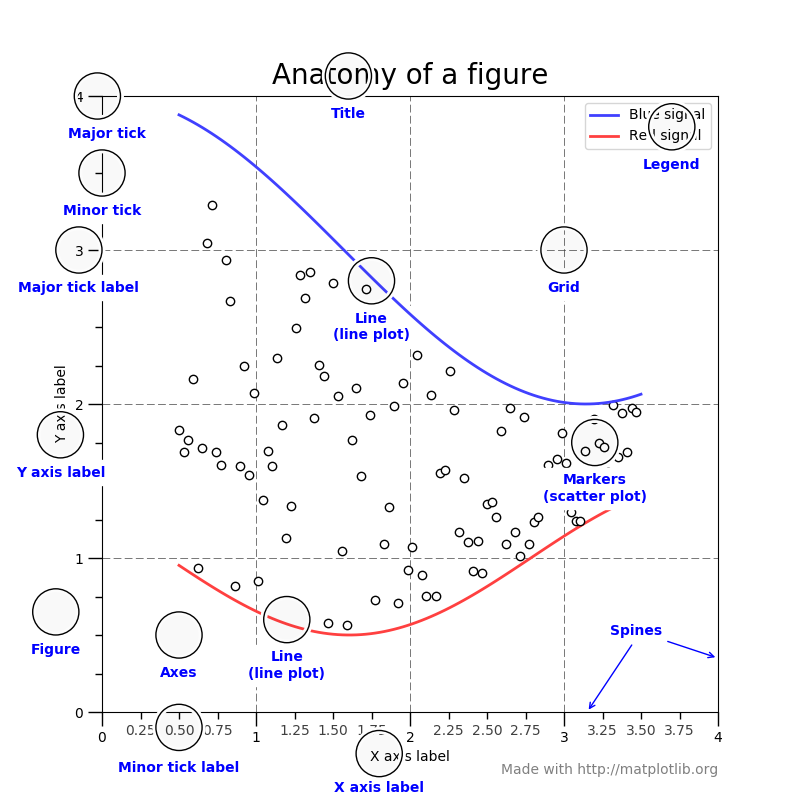
- title
- x label, y label
- legend
- Matplotlib 공식 사이트
-
실습 예제
# Matplotlib 설치 %pip install matplotlib # 라이브러리 import import matplotlib.pyplot as plt plt.plot([1,2,3,4]) # y값 1,2,3,4 로 증가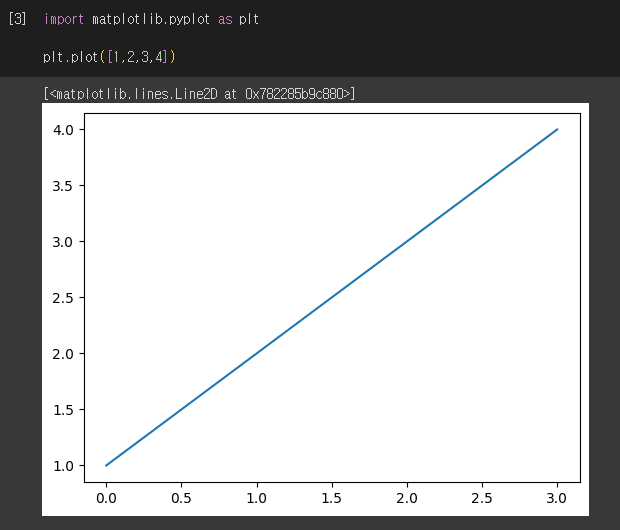
import numpy as np x = np.arange(0,12,1) y = np.sin(x) y2 = np.cos(x) plt.plot(x,y, label="sin", marker="o") plt.plot(x,y2, label="cos", marker="x") plt.legend() # plt.legend(loc=(1,1)) # 범례의 위치 지정 plt.title("sin graph") # 그래프의 제목 plt.xlabel("Time") # 그래프의 x라벨 plt.ylabel("Amplitude") # 그래프의 y라벨 plt.grid() # 그래프 내 그리드(격자) 생성 # limit 값 plt.xlim(0, np.pi) plt.ylim(-1, 1)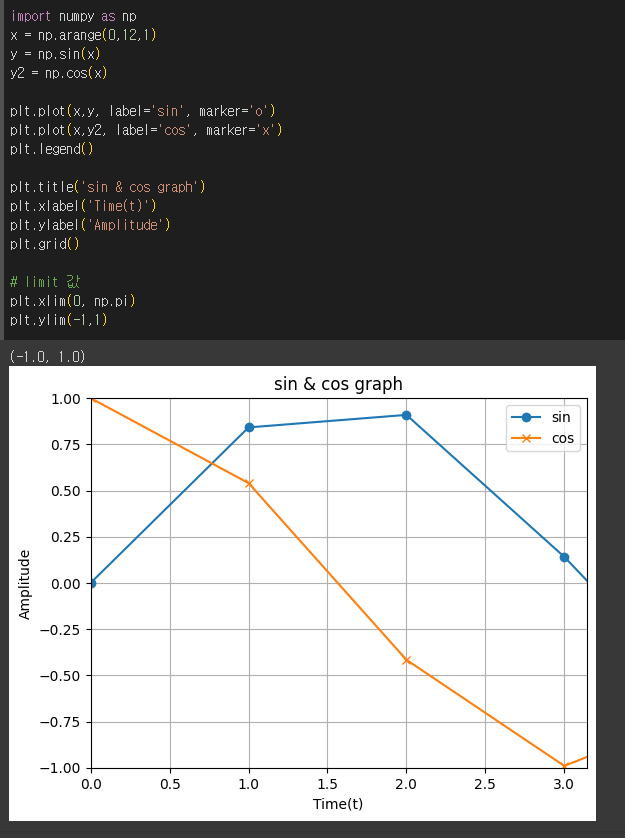
-
# 위의 사이트에서 가져 온 코드 species = ('Adelie', 'Chinstrap', 'Gentoo') sex_counts = { 'Male': np.array([73, 34, 61]), 'Female': np.array([73, 34, 58]), } width = 0.6 # the width of the bars: can also be len(x) sequence fig, ax = plt.subplots() bottom = np.zeros(3) for sex, sex_count in sex_counts.items(): p = ax.bar(species, sex_count, width, label=sex, bottom=bottom) bottom += sex_count ax.bar_label(p, label_type='center') ax.set_title('Number of penguins by sex') ax.legend() plt.show()
-
3. Seaborn
- matplotlib보다 고급화된 시각화 가능
- matplotlib에서 통계용 차트가 추가됨.
4. 연습 문제
-
한글 폰트 적용 코드
!sudo apt-get install -y fonts-nanum !sudo fc-cache -fv !rm ~/.cache/matplotlib -rf import matplotlib.pyplot as plt import numpy as np plt.rc('font', family='NanumBarunGothic')- 위 코드 실행 후 런타임 → 런타임 재시작 필요.
1) 영화 데이터를 활용하여 x 축은 Movie y축은 Rating인 막대(bar) 그래프를 만드시오.
2) 앞에서 만든 막대 그래프에 제시된 세부 사항을 적용하시오.
- 제목: Movie Night Top5
- x축: label: Movie (90도 회전)
- y축: label: Rating
3) 개봉 연도별 평점 변화 추이를 선 그래프(plot)로 그리시오.
(1) 개봉 연도별 평점
(2) x축에는 연도 데이터가 들어가야 하고, y축에는 평점 데이터가 들어가면 되겠네요.
4) 앞에서 만든 그래프에 제시된 세부 사항을 적용하시오.
- marker: 'o'
- x축 눈금: 5년 단위 (2005, 2010, 2015, 2020)
- y축 범위: 최소 7, 최대 10
5) 평점이 9점 이상인 영화의 비율을 확인할 수 있는 원 그래프(파이차트)를 제시된 세부 사항을 적용하여 그리시오.
- label: 9점 이상 / 9점 미만
- 퍼센트: 소수점 첫 번째 자리까지 표시
- 범례: 그래프 우측에 표시
[5일차 후기]
data 변경된 부분을 반영하고 싶다면 inplace 필수!!!
생각보다 데이터를 수치화 시키고 시각화 시키는게 재밌었다~
[참고 자료]
- [오즈스쿨 스타트업 웹 개발 초격차캠프 백엔드 Django 강의]
