
01. Fast API란?
1. Fast API
- 특징
- 고성능
: Starlette과 Pydantic을 사용하여 높은 성능을 제공한다.- Starlette은 비동기 프로그래밍을 지원하는 가벼운 웹 프레임워크로, FastAPI의 비동기 처리 기능을 통해 높은 성능을 제공한다.
- Pydantic은 데이터 검증 및 설정 관리에 사용되는 라이브러리로, 강력한 타입 힌트와 함께 데이터 처리의 정확성과 성능을 향상시킨다.
- 이 두 컴포넌트의 결합은 FastAPI가 데이터 처리와 HTTP 요청 처리에서 뛰어난 성능을 낼 수 있게 돕는다.
- 표준 기반
: OpenAPI (이전에 Swagger로 알려짐) 및 JSON 스키마를 기반으로 한다.
- 고성능
이름에서 알 수 있듯이 API를 빠르게 만들 수 있도록 집중한 프레임워크다. 또한 FastAPI 자체에는 ORM(Object-Relational Mapping) 기능이 포함되어 있지 않다. 하지만, FastAPI는 SQLAlchemy와 같은 외부 라이브러리를 통해 ORM 기능을 사용할 수 있도록 설계되었다.
SQLAlchemy는 Python에서 매우 강력하고 유연한 ORM 라이브러리로, 다양한 데이터베이스와의 상호작용을 쉽게 만들어줍니다. 한 번 익히면 다양한 프로젝트와 상황에서 재사용할 수 있기 때문에 매우 가치 있는 라이브러리라고 할 수 있다. FastAPI와 SQLAlchemy를 함께 사용함으로써, 개발자들은 FastAPI의 빠른 성능과 편리한 API 개발 기능과 더불어, 데이터베이스 작업을 위한 강력한 ORM 기능을 활용할 수 있게 된다.
2. Fast API 개발자
FastAPI의 개발자인 Sebastián Ramírez는 Typer라는 별도의 라이브러리를 만들어 CLI 애플리케이션을 쉽게 생성할 수 있도록 했다. Typer는 Python의 타입 힌트를 기반으로 하여, FastAPI와 유사한 방식으로 CLI 애플리케이션을 개발할 수 있게 해주며, 사용자 친화적인 CLI를 빠르게 구축할 수 있다. 그래서 FastAPI 문서나 웹사이트에서 Typer를 소개하고 있다. FastAPI와 Typer 모두 사용자가 빠르고 쉽게 API 및 CLI 애플리케이션을 개발할 수 있도록 설계된 도구다.
FastAPI 자체로는 CLI(Command Line Interface, 명령줄 인터페이스) 애플리케이션을 직접 생성하지 않는다. CLI는 사용자가 텍스트 기반의 명령을 통해 컴퓨터와 상호 작용할 수 있게 해주는 인터페이스다.
- Fast API 사용하는 기업
: 9 Companies that Use FastAPI - PLANEKS - Uber, Netflix, Micro soft ...
3. Fast API와 Flask 차이점
1) 설계 및 성능
- FastAPI
: FastAPI는 비동기 프로그래밍을 지원하여 더 빠른 성능을 제공한다. 이는 특히 동시성이 높은 애플리케이션에서 유리하다. FastAPI는 내부적으로 Starlette (비동기 웹 프레임워크)와 Pydantic (데이터 검증 및 설정 관리 라이브러리)를 사용한다.
- Flask
: Flask는 동기 프로그래밍 모델을 사용하며, 웹서버 게이트웨이 인터페이스(WSGI)를 기반으로 한다. 이 때문에 FastAPI보다는 일반적으로 성능이 낮다. Flask는 간단하고 가볍다. 확장 가능한 구조를 가지고 있어 필요에 따라 추가 기능을 플러그인 형태로 쉽게 추가할 수 있다.
2) 데이터 검증 및 직렬화
- FastAPI
: Python의 타입 힌트와 Pydantic을 사용하여 데이터 검증과 직렬화를 자동화한다. 이로 인해 개발자는 타입 안전성을 보장하고 버그를 줄일 수 있다.
- Flask
: 데이터 검증과 직렬화는 Flask에서 기본적으로 제공되지 않는다. Flask에서 이러한 기능을 구현하려면 마샬링 라이브러리나 다른 확장 기능을 사용해야 한다.
3) 자동 문서 생성
-
FastAPI
: OpenAPI 표준을 기반으로 자동 API 문서를 생성한다. 이는 API 개발 및 테스트를 쉽게 해주며, Swagger UI와 ReDoc을 통해 문서를 제공한다. -
Flask
: Flask 자체에는 자동 문서 생성 기능이 없다. 이를 위해서는 Swagger와 같은 별도의 확장 도구를 사용해야 한다.
4) 비동기 프로그래밍 지원
- FastAPI
: FastAPI는 Python의 async와 await를 사용한 비동기 프로그래밍을 기본적으로 지원한다. 이는 특히 I/O 바운드 작업에 유리하다.
- Flask
: 기본적으로 Flask는 비동기 프로그래밍을 지원하지 않는다. Flask에서 비동기를 사용하려면 추가적인 작업과 확장이 필요하다.
5) 사용 케이스 및 학습 곡선
- FastAPI
: FastAPI는 성능이 중요하고, 타입 안전성 및 자동 문서화가 필요한 복잡한 애플리케이션에 적합하다. 타입 힌트와 비동기 코드에 익숙하지 않은 경우 학습 곡선이 조금 높을 수 있다.
- Flask
: Flask는 간단하고 가벼운 애플리케이션 또는 프로토타입 개발에 적합하다. 입문자에게 친숙하며, 확장성과 유연성으로 인해 다양한 프로젝트에 적용할 수 있다.
[결론]
FastAPI와 Flask는 각각의 사용 사례와 필요에 따라 선택할 수 있는 강력한 프레임워크다. FastAPI는 현대적인 기능과 빠른 성능을 제공하는 반면, Flask는 간결함과 확장 가능한 구조로 널리 사용된다. 프로젝트의 요구 사항과 개발자의 선호도에 따라 적합한 프레임워크를 선택하는 것이 중요하다.
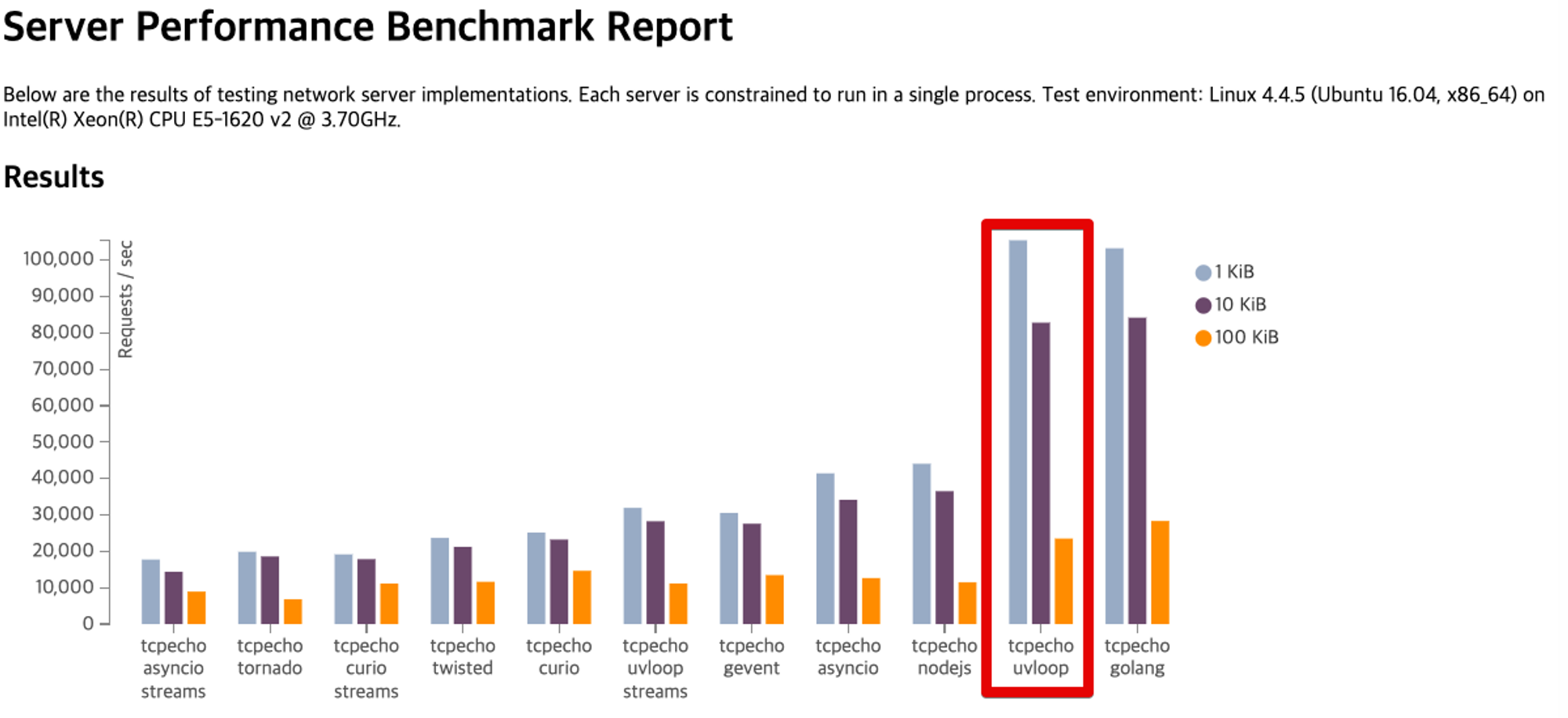
4. Fast API 사용 이유
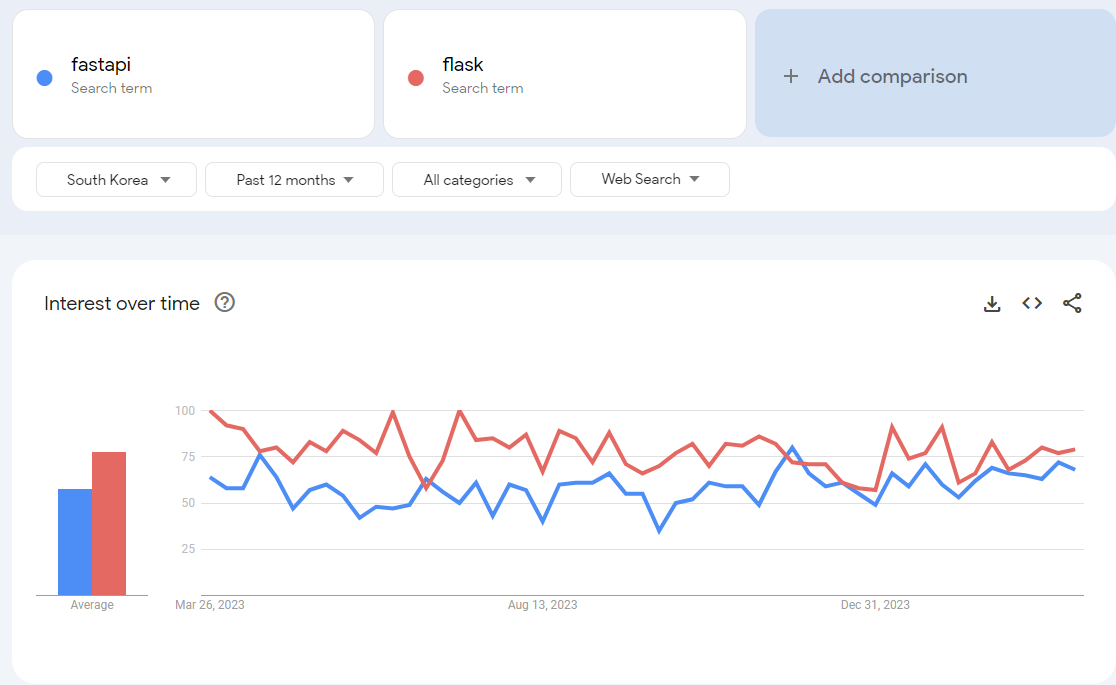
1) FastAPI vs Flask
2) Dev Trend
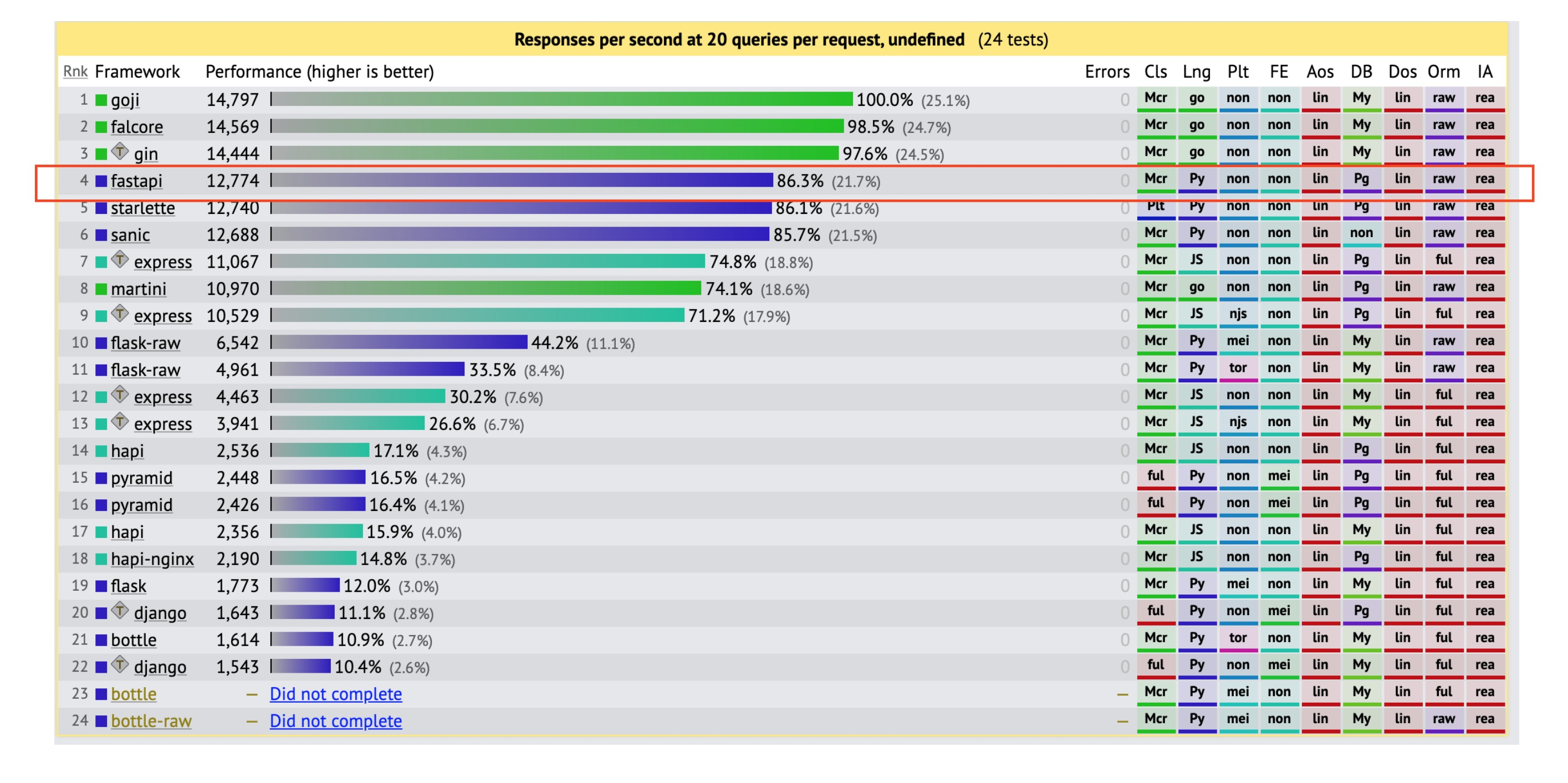
3) Goli(고랭)와 비빌 수 있는 빠른 속도
02. Fast API Project setting
[Project Setting]
0) 새로운 dir 생성 및 가상 환경 설정
먼저 새로운 Python 프로젝트를 위한 디렉토리를 생성하고 가상 환경을 설정한다.
> mkdir fast_api
> cd fast_api1) 가상환경 구성
>(MAC) virtualenv .venv
>(Window) python -m venv .venv실행
>(MAC) source .venv/bin/activate
>(Window) cd .venv\Scripts\activate2) 필요한 패키지 설치
FastAPI와 Uvicorn(ASGI 서버)를 설치한다.
> pip install fastapi
> pip install 'uvicorn[standard]'3) 기본 애플리케이션 작성
main.py 파일을 생성하고 다음 코드를 작성한다.
-
fast_api/main.py
from fastapi import FastAPI app = FastAPI() @app.get("/") def read_root(): return {"Hello": "World"} @app.get("/items/{item_id}") def read_item(item_id: int, q: str = None): return {"item_id": item_id, "q": q}
4) 서버 실행
생성한 애플리케이션을 실행하기 위해 다음 명령어를 사용한다.
> uvicorn main:app --reload+) 추가 서버 실행 방법
-
프로그래밍 방식으로 직접 실행하기
FastAPI 애플리케이션을 프로그램 내부에서 직접 실행하는 가장 일반적인 방법import uvicorn if __name__ == "__main__": uvicorn.run("main:app", port=8000, log_level="info")위 코드를 main.py에 추가해준 뒤 아래 명령어 실행
> python main.py만약, 위 내용이 파일 내에 없다면 터미널에서 아래 명령어 실행
> uvicorn main:app --port 8000 --log-level info -
Config와 Server 인스턴스 사용하기
더 많은 구성 옵션과 서버 수명 주기 제어가 필요할 때 사용import uvicorn if __name__ == "__main__": config = uvicorn.Config("main:app", port=8000, log_level="info") server = uvicorn.Server(config) server.run() -
Gunicorn과 함께 사용하기
프로덕션 환경에서는 Gunicorn을 사용하는 것이 권장된다. Gunicorn은 프로세스 관리 및 부하 분산 기능을 제공한다.gunicorn example:app -w 4 -k uvicorn.workers.UvicornWorker
5) 결과 확인
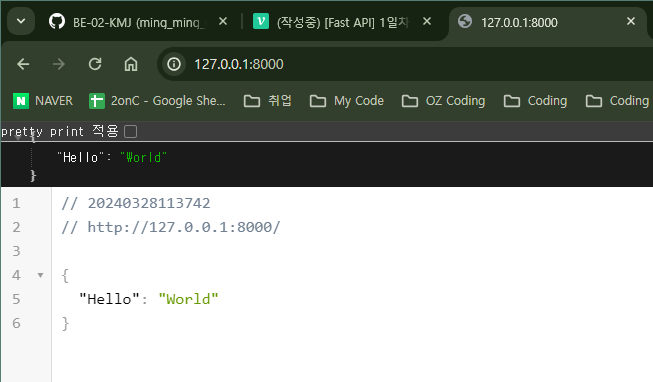
브라우저를 열고 http://127.0.0.1:8000로 이동한다. "Hello: World"라는 JSON 응답을 볼 수 있다.
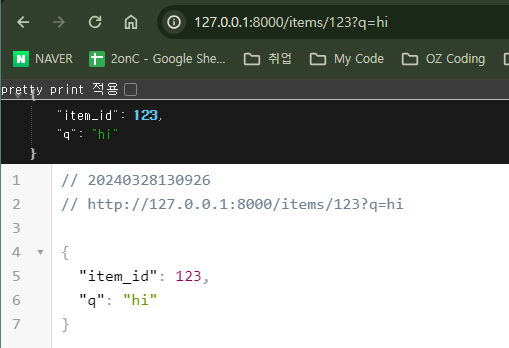
http://127.0.0.1:8000/items/123?q=hi로 이동하면 "item_id": 123,"q": "hi"라는 JSON 응답을 볼 수 있다.
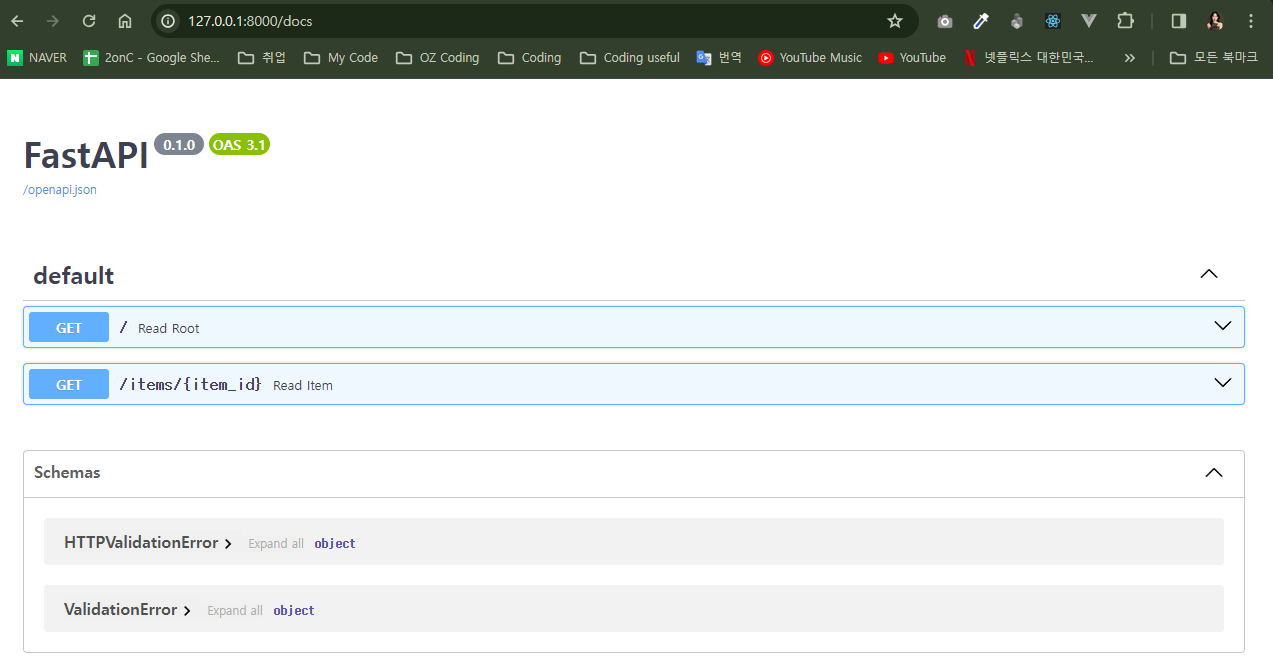
또한 FastAPI는 자동으로 API 문서를 생성한다. http://127.0.0.1:8000/docs 또는 http://127.0.0.1:8000/redoc으로 이동하여 API 문서를 볼 수 있다.
6) 마무리
이렇게 함으로써 기본적인 FastAPI 프로젝트를 설정하고 실행할 수 있다. FastAPI는 매우 유연하고 확장 가능하므로, 추가 기능과 복잡한 API 경로를 쉽게 추가할 수 있다. FastAPI 공식 문서(FastAPI Documentation)를 참조하여 더 많은 정보를 얻을 수 있다.
(+) Swagger UI vs ReDoc
1) Swagger UI (/docs)
Swagger UI는 FastAPI와 함께 가장 일반적으로 사용되는 자동 생성 문서다. 사용자 친화적인 인터페이스를 제공하며, API의 각 경로와 가능한 요청 및 응답을 시각적으로 표시한다. 실시간으로 API를 테스트하고 상호 작용할 수 있는 기능을 제공한다. 예를 들어, API 엔드포인트에 대한 요청을 직접 보내고 응답을 받아볼 수 있다. 각 API 엔드포인트에 대한 파라미터, 요청 본문, 응답 스키마 등의 세부 사항을 볼 수 있다.
2) ReDoc (/redoc)
ReDoc은 좀 더 간결하고 정돈된 인터페이스를 제공하는 다른 형태의 문서화 도구다. Swagger UI보다 더 간단하고 읽기 쉬운 레이아웃을 제공한다. 대규모 API에 적합하며, 복잡한 스키마를 가진 API를 좀 더 쉽게 탐색하고 이해할 수 있도록 도와준다. 실시간 API 테스트 기능은 제공하지 않는다. 대신, 문서화에 더 초점을 맞추고 있다.
3) 활용 용도
-
개발 및 테스트
Swagger UI (/docs)는 API 개발 및 테스트 과정에서 매우 유용하다. 개발자는 API의 각 부분을 실시간으로 테스트하고 결과를 즉시 확인할 수 있다. -
문서화 및 프레젠테이션
ReDoc (/redoc)은 API의 최종 사용자나 스테이크홀더들에게 API를 소개하거나 문서화하는 데 더 적합하다. 그것은 깔끔하고 직관적인 인터페이스로 API의 구조와 기능을 명확하게 전달한다.
결론적으로, Swagger UI와 ReDoc은 각기 다른 목적과 상황에 맞게 활용될 수 있으며, FastAPI에서 두 문서화 도구를 모두 제공하는 것은 개발자가 다양한 요구 사항과 선호도에 맞게 선택할 수 있게 한다.
03. Fast API APIRouter
APIRouter는 FastAPI에서 제공하는 클래스로, 애플리케이션의 라우트(route)를 그룹화하고 모듈화하는 데 사용된다. APIRouter를 사용하면 여러 파일로 나누어진 라우트를 조직적으로 관리할 수 있으며, 이는 애플리케이션의 유지보수성과 확장성을 향상시킨다.
1. APIRouter의 주요 기능
-
라우트 그룹화
관련된 라우트를 하나의APIRouter인스턴스에 그룹화하여 관리할 수 있다. 예를 들어, 사용자 관련 라우트, 주문 관련 라우트 등을 각각 다른APIRouter인스턴스에 정의할 수 있다. -
모듈화
각APIRouter인스턴스를 별도의 Python 파일(모듈)에 위치시켜, 코드의 모듈화를 촉진한다. 이를 통해 각 기능별로 코드를 분리하고, 팀에서 협업하기 쉬워진다. -
미들웨어 및 의존성 주입
APIRouter인스턴스에 미들웨어나 의존성을 추가하여 해당 라우터에서 사용되는 모든 라우트에 적용할 수 있다. -
경로 작업 추가
HTTP 메소드별(예: GET, POST, PUT, DELETE)로 라우트를 쉽게 추가할 수 있다.
2. APIRouter 사용 가능한 옵션
APIRouter 클래스를 초기화할 때 사용할 수 있는 몇 가지 주요 옵션들이 있다.
-
prefix
: 라우트 URL에 공통 접두어를 추가한다.
예를 들어,prefix="/items"로 설정하면, 이 라우터의 모든 라우트 경로는/items으로 시작하게 된다. -
tags
: 라우터에 태그를 추가하여 API 문서에서 관련 라우트를 그룹화할 수 있다. 예를 들어,tags=["items"]는 이 라우터의 모든 라우트를 "items" 태그로 그룹화한다. -
dependencies
: 공통 의존성을 정의하여 라우터의 모든 라우트에 적용한다. 예를 들어, 모든 라우트에 동일한 데이터베이스 세션 의존성을 추가할 수 있다. -
responses
: 라우터의 모든 라우트에 공통된 응답을 정의할 수 있다. 이를 통해 특정 HTTP 상태 코드에 대한 공통 응답을 설정할 수 있다. -
default_response_class
: 라우터의 모든 라우트에 대한 기본 응답 클래스를 설정할 수 있다.
+) route 연습
model를 생성하기 전에 연습하는 것으로 각 파일마다 router를 만들어서 return 해줬다.
-
Fast_api/items.py (new file)
from fastapi import APIRouter router = APIRouter() # items_router로 지정해도 된다. @router.get( # items_router라고 지정시 여기도 router -> items_router로 변경 필요. "/api/v1/items/{item_id}", status_code=200, tags=["item", "payment"], summary="Bring a certificate item", description="Item model에서 item_id 값을 가지고 특정 아이템 조회", ) def get_item(item_id: int): return {"items": item_id}-
@router.get("/items/{item_id}")
:/items/{item_id}경로에 대한 GET 요청을 처리한다.
여기서{item_id}는 경로 매개변수 -
status_code=200
: 이 라우트는 성공적으로 처리되었을 때 HTTP 200 상태 코드를 반환 -
tags=["items"]
: 이 라우트는 "items" 태그.
이 태그는 API 문서에서 이 라우트를 분류하는 데 사용 -
summary와description
: 이 라우트에 대한 요약과 자세한 설명을 제공한다.
이 정보는 API 문서에 표시
-
-
Fast_api/users.py (new file)
from fastapi import APIRouter router = APIRouter( prefix="/api/v1/users", tags=["users"], responses={ 200: {"msg": "Success to get data"}, 400: {"msg": "404 Not Found"}, }, ) @router.get("/{user_id}") def get_user(user_id: int): return {"data": user_id}
위에서 각자 만들 table을 main에 route 등록을 해준다.
-
Fast_api/main.py
import uvicorn from fastapi import FastAPI from items import router as items_router # as는 추후 다른 model에서의 router와 비교하기 위해. from users import router as users_router # router 이름을 users_router라고 이미 정의해줬다면 as를 쓸 필요가 없다. app = FastAPI() app.include_router(items_router) app.include_router(users_router) @app.get("/") def read_root(): return {"Hello": "World"} @app.get("/items/{item_id}") def read_item(item_id: int, q: str = None): return {"item_id": item_id, "q": q} # http://127.0.0.1:8000/items/123?q=hi if __name__ == "__main__": uvicorn.run("main:app", port=8000, log_level="info")
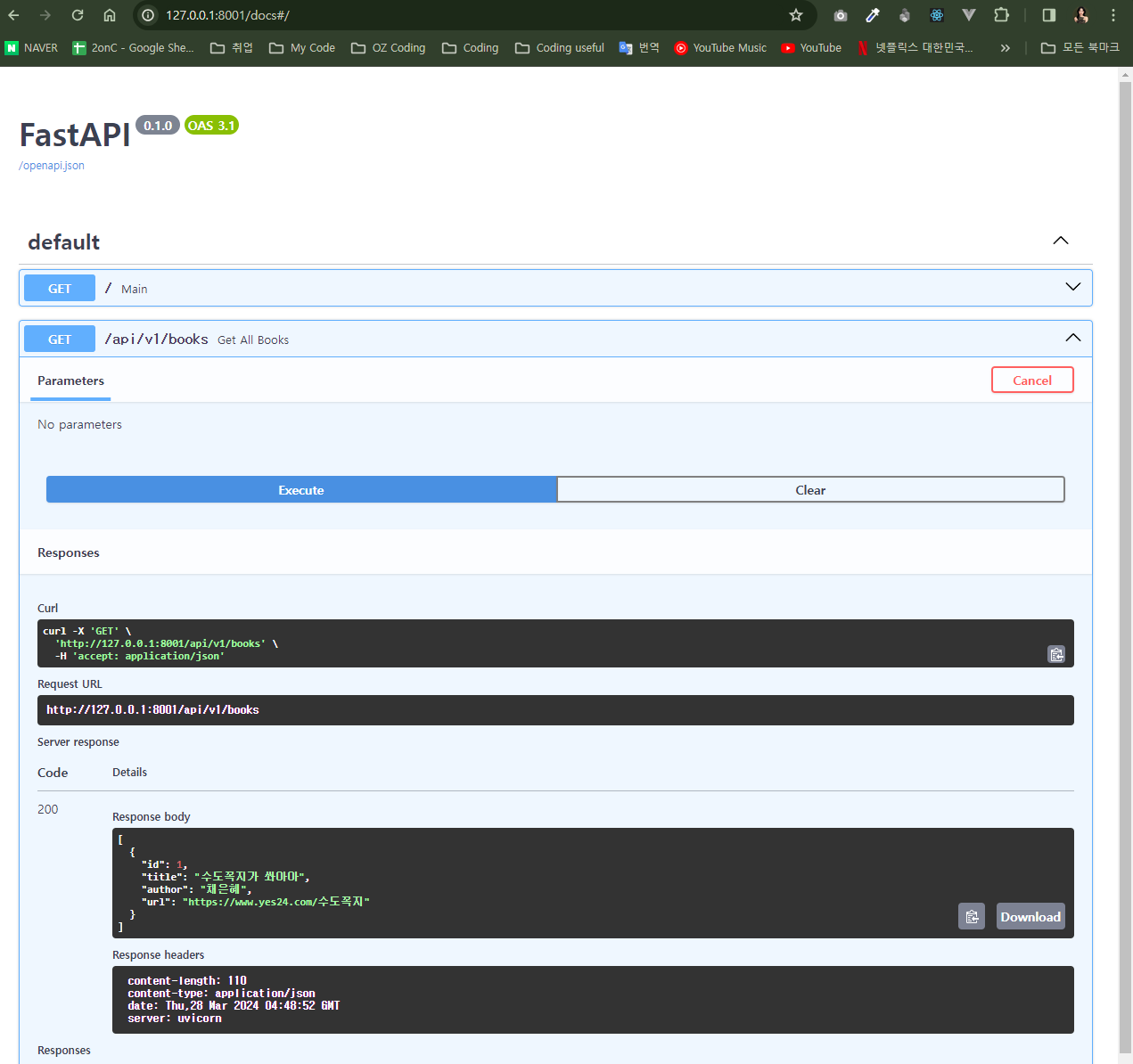
그리고 임의의 local memory DB를 만들어준다.
그 books 데이터만 불러오도록 코드를 작성해본다.
-
Fast_api/books.py
from fastapi import APIRouter, FastAPI BOOKS = [{"id": 1, "title": "수도꼭지가 쏴아아", "author": "채은혜", "url": "https://www.yes24.com/수도꼭지"}] app = FastAPI() router = APIRouter() @router.get("/", status_code=200) def main(): return {"Message": "Welcome to the Book World~!"} # Template Code # 전체 책 데이터 조회 @router.get("/api/v1/books", status_code=200) def get_all_books() -> list: return BOOKS app.include_router(router) # books data만 따로 부르기. if __name__ == "__main__": import uvicorn uvicorn.run("books:app", port=8001, reload=True)
book 데이터를 가지고 CRUD 하는 REST API를 작성해보면 아래와 같이 추가할 수 있다.
-
Fast_api/books.py
# 전체 책 데이터 조회 @router.get("/api/v1/books", status_code=200) def get_all_books() -> list: return BOOKS # 여기서 부터 추가. # 특정 책 데이터 조회 @router.get("/api/v1/books/{book_id}", status_code=200) def get_book(book_id: int): # for book in BOOKS: # if book["id"] == book_id: # book # break # 위 코드를 아래 코드 한 줄로 표현. book = next((book for book in BOOKS if book["id"] == book_id), None) # next는 data 하나를 찾고 나서 break if book: return book return {"error": f"book not found, ID: {book_id}"} # 책 생성 @router.post("/api/v1/books") def create_book(book: dict): BOOKS.append(book) return book # 특정 책 수정 @router.put("/api/v1/books/{book_id}") def update_book(book_id: int, book_update: dict): # 수정할 book data 가져오기 book = next((book for book in BOOKS if book["id"] == book_id), None) for key, value in book_update.items(): if key in book: book[key] = value return book # 특정 책 삭제 @router.delete("/api/v1/books/{book_id}") def delete_book(book_id: int): global BOOKS # for item in BOOKS: # if item['id'] != book_id: # item # 위 코드를 아래 코드 한 줄로 표현. BOOKS = [item for item in BOOKS if item["id"] != book_id] return {"Message": f"Book {book_id} deleted successfully"}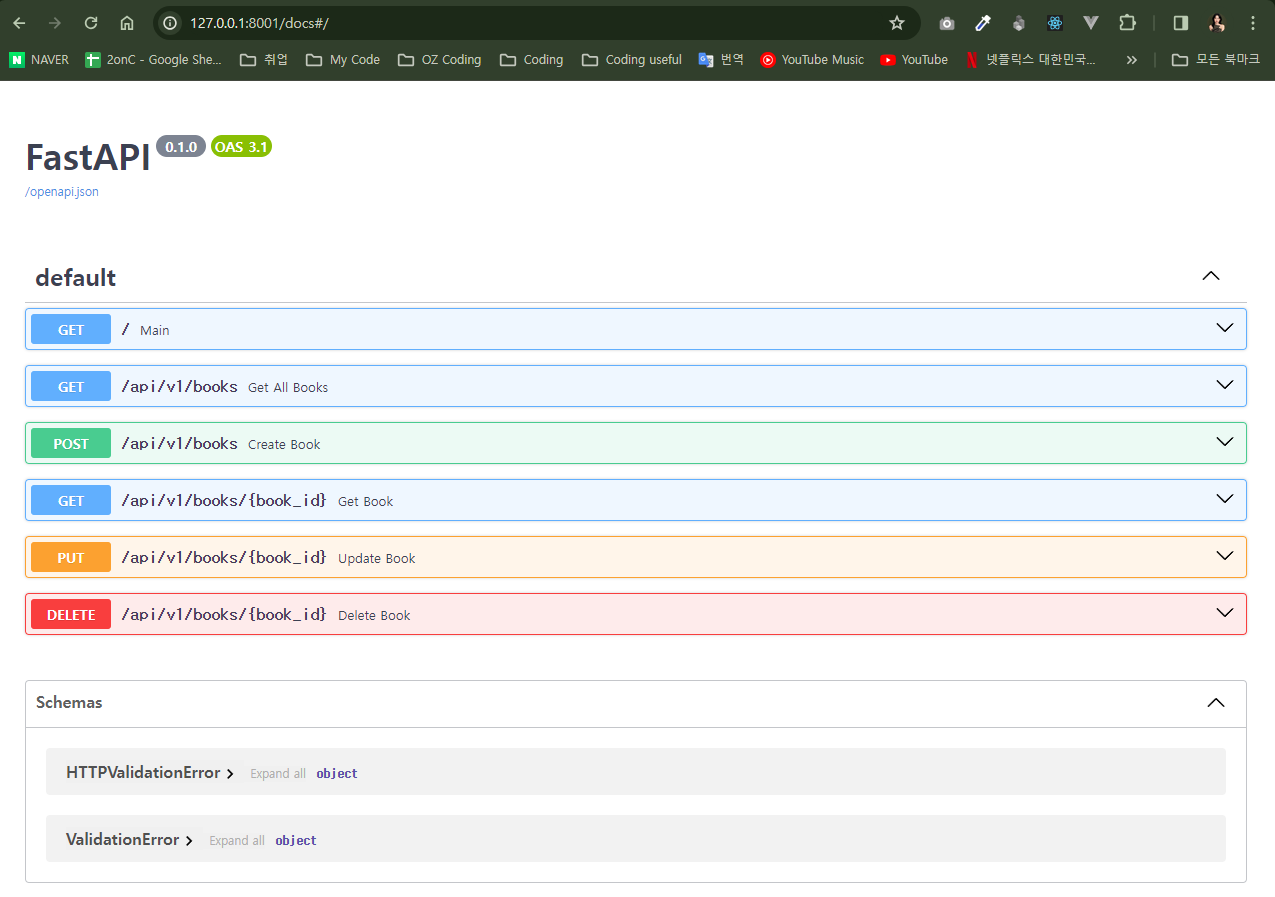
- 실습 짤
- 실습 짤
이 내용들을 각각의 table 별로 정의하는 방법을 아래와 같이 정리했다.
3. models.py: 데이터 모델 정의
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str = None
price: float
tax: float = None4. dependencies.py: 의존성 함수 정의
from fastapi import Depends, HTTPException
def verify_token(token: str = Depends()):
if token != "secret-token":
raise HTTPException(status_code=400, detail="Invalid token")
return token5. items.py: 아이템 관련 라우트 모듈
from fastapi import APIRouter
router = APIRouter()
@router.get("/items/{item_id}",
response_model=Item,
status_code=200,
tags=["items"],
summary="특정 아이템 가져오기",
description="아이템 ID를 사용하여 특정 아이템의 세부 정보를 가져옵니다.",
response_description="아이템 세부 정보 반환",
dependencies=[Depends(verify_token)])
async def read_item(item_id: int):
# 임의의 아이템 반환 예시
return {
"name": "Foo",
"description": "A very nice Item",
"price": 35.4,
"tax": 3.2
}-
response_model=Item
: 이 라우트의 응답은Item모델을 따른다.
이는 응답 데이터가Item클래스의 형식을 갖추어야 함을 의미 -
response_description
: 이 라우트의 응답에 대한 설명 -
dependencies=[Depends(verify_token)]
: 이 라우트에는verify_token함수에 의존성이 설정되어 있다. 이 의존성은 라우트가 실행되기 전에 검증된다.
6. users.py: 사용자 관련 라우트 모듈
from fastapi import APIRouter
router = APIRouter(
prefix="/items",
tags=["items"],
dependencies=[...], # 여기에 의존성을 추가할 수 있습니다
responses={404: {"description": "Not found"}},
)
@router.get("/users")
def get_users():
return {"message": "사용자 목록"}7. main.py (메인 애플리케이션 파일)
from fastapi import FastAPI
from users import router as user_router
from items import router as item_router
app = FastAPI()
app.include_router(user_router)
app.include_router(item_router)이렇게 구조화하면 애플리케이션이 커질수록 각 기능별로 코드를 분리하여 관리하기 쉬워지고, 각 모듈이 독립적으로 작동하여 유지보수가 용이해진다.
04. Fast API Pydantic
Pydantic은 FastAPI에서 데이터 검증 및 설정 관리를 위해 널리 사용된다. Pydantic의 모델을 사용하여 클라이언트로부터 받은 데이터의 형식을 검증하고, API 응답으로 데이터를 구조화하여 반환할 수 있다.
아래의 예제에서는 간단한 도서 정보 관리 API를 구현한다. 이 API에서는 도서를 추가하고, 특정 도서 정보를 조회하는 기능을 포함한다.
- Pydantic 모델 정의
Book모델은 도서 정보를 나타낸다.CreateBook모델은 새로운 도서를 추가할 때 사용할 입력 데이터 형식을 정의한다.
- FastAPI 라우팅
- 도서 추가:
/books/엔드포인트로POST요청을 보내 도서를 추가한다. - 도서 조회:
/books/{book_id}엔드포인트로GET요청을 보내 특정 도서 정보를 조회한다.
[정리]
- 모델 정의
: Pydantic 모델을 정의하는 파일. 이는 데이터 검증과 직렬화에 사용 - 종속성
: 필요한 경우 추가적인 종속성(예: 데이터베이스 연결)을 관리 - API 라우터
: FastAPI 라우터를 정의하는 파일. 이곳에서 실제 API 경로와 관련된 로직을 구현 - 메인 애플리케이션
: FastAPI 애플리케이션 인스턴스를 생성하고 라우터를 포함하는 파일.
0. 새로운 실습 setting
위에서 했던 main.py, items.py, users.py, books.py는 01.basic이란 폴더를 만들어 넣어준다.
아래 코드들은 해당 파일을 새로 만들어 작성해준다.
1. models.py: Pydantic 모델 정의
-
교재
from pydantic import BaseModel from typing import Optional from uuid import UUID class Book(BaseModel): id: UUID title: str author: str description: Optional[str] = None class CreateBook(BaseModel): title: str author: str description: Optional[str] = None class BookSearch(BaseModel): results: Sequence[Book] -
실습
from typing import List, Optional from pydantic import BaseModel class Book(BaseModel): id: int title: str author: str description: Optional[str] = None # 따로 Create Book class 생성 필요 (data validation) # docs에 데이터 그대로 넣어진다. class CreateBook(BaseModel): title: str author: str description: Optional[str] = None class SearchBook(BaseModel): results: Optional[Book] class SearchBookList(BaseModel): results: List[Book]
2. routers.py: API 라우터
-
교재
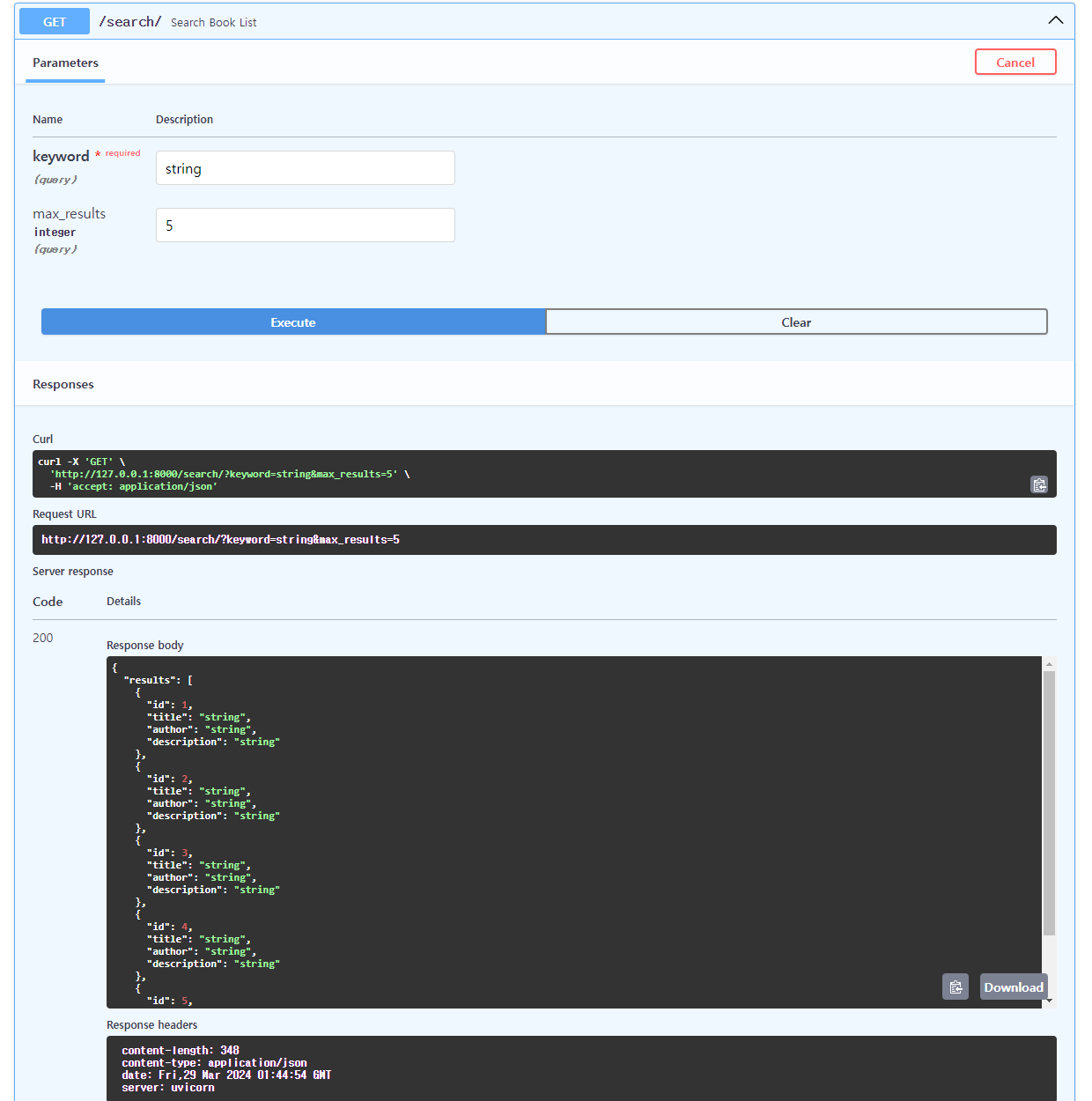
from fastapi import APIRouter, HTTPException from typing import List, Optional from .models import Book, CreateBook, BookSearchResults from uuid import uuid4 router = APIRouter() books: List[Book] = [] @router.post("/books/", response_model=Book, status_code=201) def create_book(book_data: CreateBook) -> Book: book = Book(id=uuid4(), **book_data.dict()) books.append(book) return book @router.get("/books/{book_id}", response_model=Book) def fetch_book(book_id: UUID) -> Book: book = next((b for b in books if b.id == book_id), None) if not book: raise HTTPException(status_code=404, detail="Book not found") return book @router.get("/search/", response_model=BookSearchResults) def search_books( *, keyword: Optional[str] = None, max_results: int = 10 ) -> BookSearchResults: result = [book for book in books if keyword.lower() in book.title.lower()] if keyword else books return BookSearchResults(results=result[:max_results]) -
실습 (books.py)
from typing import List, Optional from fastapi import APIRouter from models import Book, CreateBook, SearchBookList route = APIRouter() books: List[Book] = [] @route.post("/") def create_book(book: CreateBook) -> Book: book = Book(id=len(books) + 1, **book.model_dump()) books.append(book) return book @route.get("/search/") # 1개의 책만 조회 # def search_book() -> SearchBook: # pass # 여러개 책 조회 def search_book_list(keyword: Optional[str], max_results: int = 10) -> SearchBookList: # 이 코드를 # for book in books: # if keyword in book.title: # book # 이렇게 한 줄로 표시 search_result = [book for book in books if keyword in book.title] if keyword else books return SearchBookList(results=search_result[:max_results])
3. main.py: 메인 애플리케이션
- 교재
from fastapi import FastAPI
from .routers import router
app = FastAPI()
app.include_router(router)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)-
실습
from fastapi import FastAPI from books import route as books_route app = FastAPI() app.include_router(books_route) if __name__ == "__main__": import uvicorn uvicorn.run("main:app", reload=True)
이렇게 분리하여 코드를 관리하면 각 부분이 명확하게 구분되어 프로젝트의 확장성과 유지보수성이 향상된다.
데이터베이스 연결, 사용자 인증 등 추가 기능을 쉽게 통합할 수 있다.
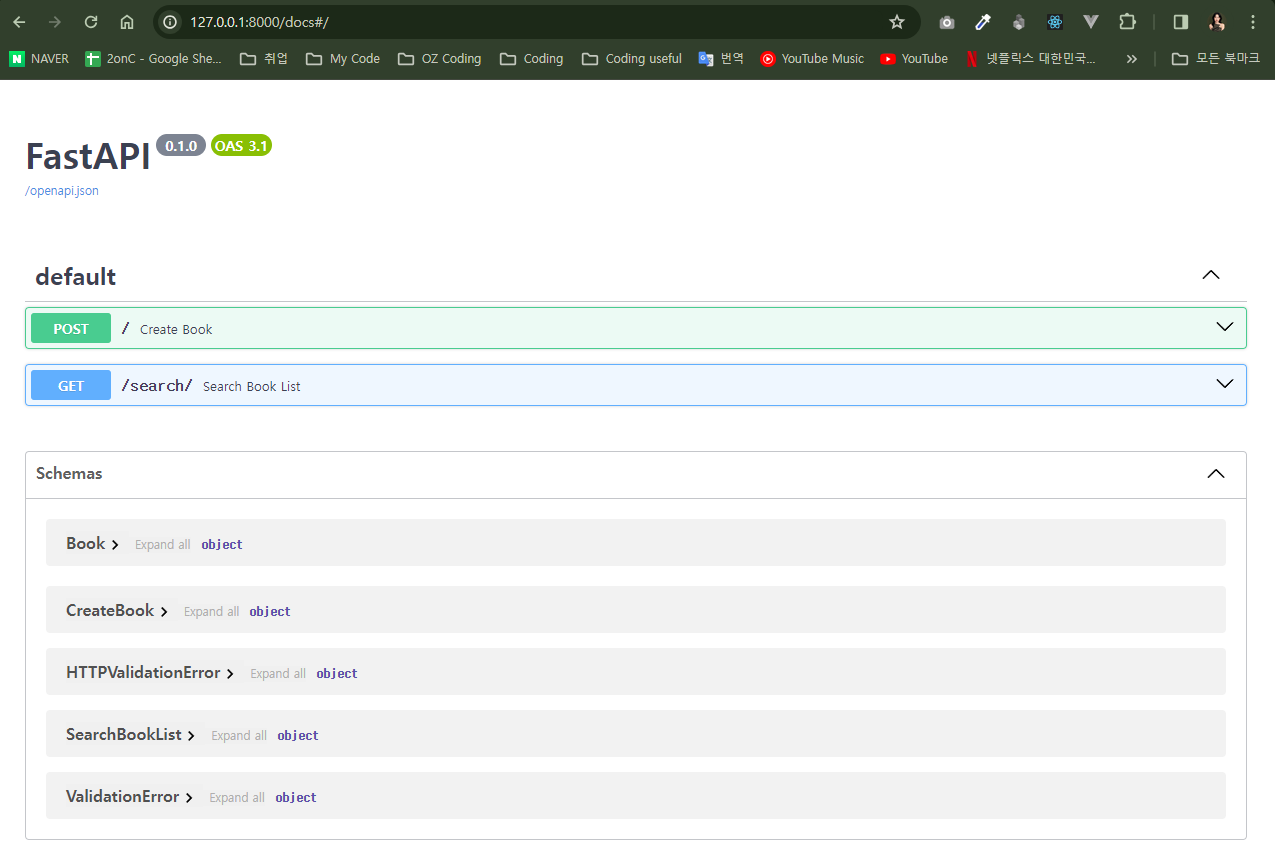
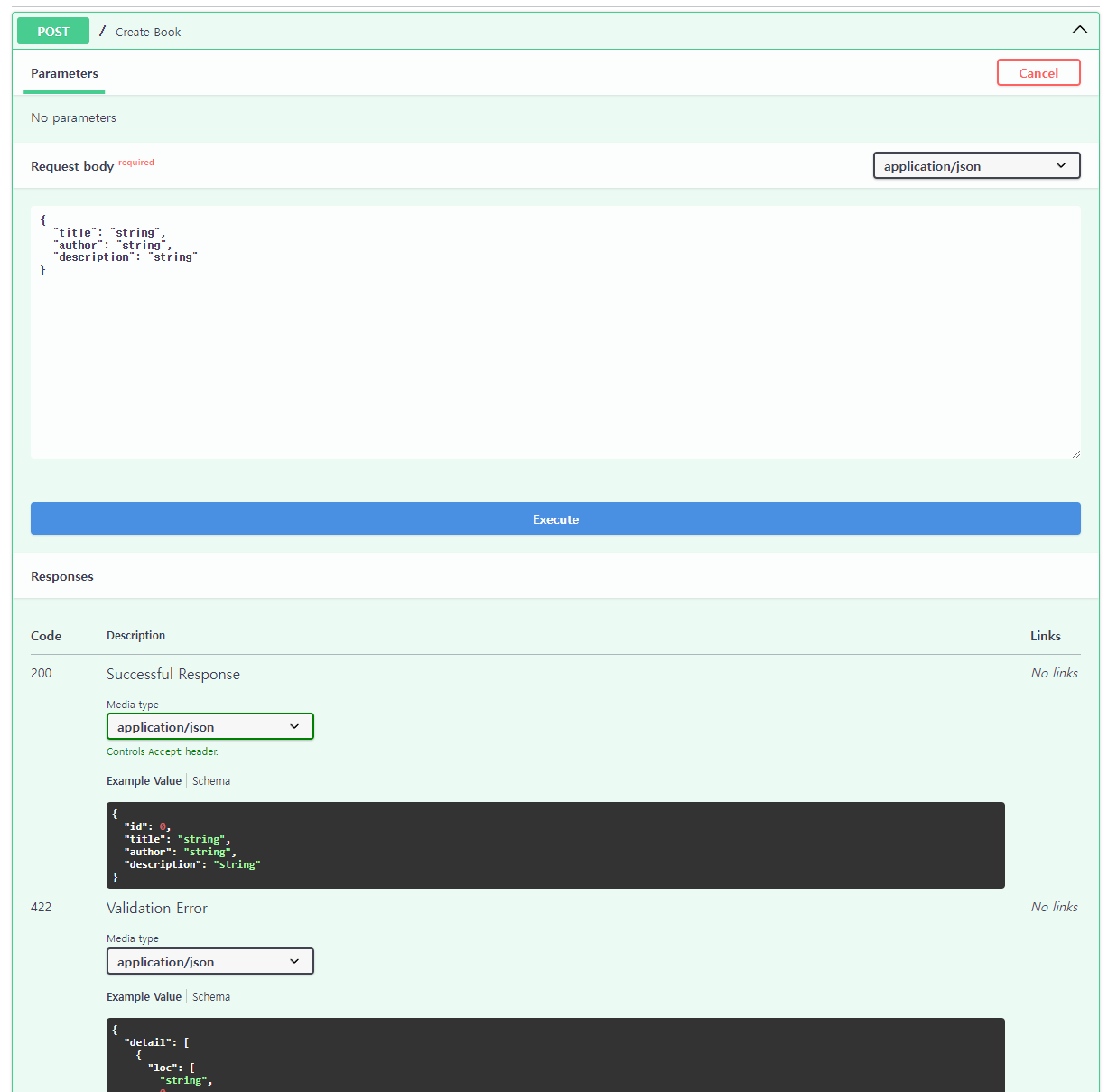
4. Jinja Template 적용
FastAPI에 Jinja2 템플릿을 적용하기 위해서는 몇 가지 단계를 거쳐야한다. 우선, Jinja2Templates 클래스를 사용하여 템플릿 디렉토리를 설정한다. 그런 다음, FastAPI 라우터에 템플릿을 렌더링하는 엔드포인트를 추가한다. 아래 예제는 기존의 책 관리 코드에 템플릿 렌더링을 추가한 것이다.
-
템플릿 디렉토리 설정
:templates폴더에 HTML 템플릿 파일을 저장한다. 예를 들어,index.html이라는 파일을 만들고, 그 안에 책 목록을 렌더링하는 HTML 코드를 작성한다. -
FastAPI 애플리케이션에 템플릿 렌더링 추가
:Jinja2Templates를 사용하여 템플릿 디렉토리를 지정하고, 라우터에 HTML 페이지를 렌더링하는 경로를 추가한다.
먼저, templates/index.html 파일을 생성한다.
<!DOCTYPE html>
<html>
<head>
<title>Books</title>
</head>
<body>
<h1>Books</h1>
<ul>
{% for book in books %}
<li>{{ book.title }} by {{ book.author }}</li>
{% endfor %}
</ul>
</body>
</html>그런 다음, main.py 파일을 업데이트 한다.
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
from .routers import router
app = FastAPI()
app.include_router(router)
# 템플릿을 위한 디렉토리 설정
templates = Jinja2Templates(directory="templates")
@app.get("/books/", response_class=HTMLResponse)
async def read_books(request: Request):
return templates.TemplateResponse("index.html", {"request": request, "books": books})이 코드는 /books/ 경로에 접근할 때, 저장된 책 목록을 HTML 형식으로 렌더링한다. Jinja2 템플릿 엔진은 templates/index.html 파일을 사용하여 동적으로 HTML 페이지를 생성한다.
위의 예제에서 books는 앞서 routers.py에서 정의한 책 목록이다. FastAPI가 이 목록을 템플릿 엔진으로 전달하고, Jinja2는 이를 활용해 HTML 페이지에 동적으로 데이터를 삽입한다.
05. Fast API Async & Sync
before test
-
main.py
from fastapi import FastAPI from routes import router app = FastAPI() app.include_router(router) -
routes.py
from fastapi import APIRouter import asyncio import time router = APIRouter()
1. Blocking I/O in an Async Function (비동기 함수에서의 차단 I/O)
@router.get("/slow-async-ping")
async def slow_async_ping():
time.sleep(10) # 차단 I/O: 메인 이벤트 루프를 10초 동안 차단
pong = service.get_pong() # 차단 I/O: DB에서 pong을 가져옴
return {"pong": pong}이 함수는 async로 선언되어 있지만 내부에서 차단 I/O 작업(time.sleep 및 service.get_pong)을 수행한다. 이로 인해 이벤트 루프가 다른 작업을 수행할 수 없게 되고, 이 함수가 처리되는 동안 서버는 다른 요청을 처리할 수 없다.
2. Blocking I/O in a Sync Function (동기 함수에서의 차단 I/O)
@router.get("/efficient-sync-ping")
def efficient_sync_ping():
time.sleep(10) # 차단 I/O, 하지만 다른 스레드에서 실행
pong = service.get_pong() # 차단 I/O, 다른 스레드에서 실행
return {"pong": pong}이 함수는 일반 동기 함수로, 차단 I/O 작업을 수행한다. Fast API는 이를 자동으로 별도의 스레드에서 실행하여, 메인 이벤트 루프를 차단하지 않고 다른 작업을 계속 처리할 수 있게 한다.
- 동기(sync) 라우트의 사용
- 동기 라우트는
def로 정의되며, 차단 I/O 작업을 수행할 때 사용될 수 있다. - FastAPI는 동기 라우트를 자동으로 별도의 스레드 풀에서 실행하여, 메인 이벤트 루프를 차단하지 않고 다른 요청을 계속 처리할 수 있도록 한다.
- 동기 라우트는 CPU 바운드 작업(복잡한 계산, 데이터 처리 등)에 적합하지 않다. 이 경우, 별도의 프로세스에서 작업을 실행하는 것이 더 나을 수 있다.
- 동기 라우트는
3. Non-blocking I/O in an Async Function (비동기 함수에서의 비차단 I/O)
@router.get("/fast-async-ping")
async def fast_async_ping():
await asyncio.sleep(10) # 비차단 I/O
pong = await service.async_get_pong() # 비차단 I/O DB 호출
return {"pong": pong}이 함수는 비차단 I/O 작업을 사용합니다. asyncio.sleep과 service.async_get_pong는 비동기로 실행되며, 이벤트 루프가 다른 작업을 계속 처리할 수 있게 해줍니다.
- 비동기(async) 라우트의 사용
- FastAPI는 기본적으로 비동기 프레임워크로, Python의
asyncio라이브러리를 사용하여 비동기 작업을 쉽게 관리할 수 있게 해준다. - 비동기 라우트는
async def로 정의되며,await를 사용하여 비동기 함수를 호출한다. - 이 방식은 I/O 바운드 작업(네트워크 요청, 디스크 읽기/쓰기 등)에 효율적이다. 이 작업들은 서버가 결과를 기다리는 동안 다른 요청을 처리할 수 있게 해준다.
- 비동기 라우트에서 차단(blocking) I/O 작업을 수행하면, 전체 이벤트 루프가 차단되어 성능이 저하된다.
- FastAPI는 기본적으로 비동기 프레임워크로, Python의
4. Additional Example: CPU-bound Operation in Async Function (비동기 함수에서의 CPU 집약적 작업)
- 피보나치 수열
-
정의
- 첫 번째와 두 번째 항이 각각 0과 1
- 세 번째 항부터는 바로 앞의 두 항을 더한 값
즉, 피보나치 수열은 0, 1, 1, 2, 3, 5, 8, 13, 21, ...과 같이 이어진다.
-
여기서 주어진 파이썬 함수는 재귀적 방법으로 피보나치 수열을 계산한다. 함수는 매개변수로 숫자 n을 받아서 n번째 피보나치 수를 반환한다.
만약 n이 1 이하인 경우에는 n 자체를 반환한다. 왜냐하면 0번째와 1번째 피보나치 수는 각각 0과 1이기 때문이다.
그 외의 경우에는 fibonacci(n-1)과 fibonacci(n-2)를 더한 값을 반환한다. 이는 피보나치 수열의 성질을 따르는 재귀적인 방법이다.
이 함수를 호출하면 n번째 피보나치 수를 구할 수 있다. 하지만 이 함수는 재귀적으로 자신을 호출하기 때문에 중복 계산이 발생할 수 있고, n이 커질수록 계산 시간이 길어진다. 이런 문제를 해결하기 위해서는 아래 코드와 같이 동적 계획법 등의 방법을 사용할 수 있다.
@router.get("/cpu-bound-async")
async def cpu_bound_async():
result = await some_cpu_intensive_task() # CPU 집약적 작업
return {"result": result}
def some_cpu_intensive_task():
# 예시: 피보나치 수열의 35번째 항을 계산하는 함수
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
# 피보나치 수열의 35번째 항 계산
result = fibonacci(35)
return result이 함수에서 some_cpu_intensive_task는 CPU 집약적 작업을 나타낸다. 비동기 함수에서 이러한 작업을 수행하는 것은 권장되지 않는다. CPU 집약적 작업은 이벤트 루프를 차단할 수 있으며, 이는 FastAPI의 성능에 부정적인 영향을 미친다. 이러한 작업은 별도의 프로세스에서 실행하는 것이 좋다.
CPU 바운드(CPU-bound) 작업이란 주로 CPU의 계산 능력에 의존하는 작업을 말한다. 이러한 작업은 CPU의 계산 속도에 따라 그 성능이 결정되며, 예로는 복잡한 수학적 계산, 데이터 압축, 이미지 또는 비디오 처리, 머신 러닝 모델의 학습 등이 있다.
위 문장에서의 핵심은, 비동기 프로그래밍은 주로 I/O 바운드 작업에 적합하다는 것이다. I/O 바운드 작업은 데이터를 읽거나 쓰는데 대부분의 시간을 소모하는 작업으로, 예를 들면 웹 페이지에서 데이터를 다운로드하거나 데이터베이스에 접근하는 것과 같은 작업들이 여기에 속한다. 이러한 작업들은 실제 CPU가 계산을 수행하는 시간보다 대기 시간이 더 길기 때문에, 비동기 프로그래밍을 통해 CPU가 다른 작업을 수행할 수 있도록 하여 전체적인 프로그램의 효율을 높일 수 있다.
반면에, CPU 바운드 작업은 CPU의 계산 능력이 주요한 성능 요소이므로, 비동기 프로그래밍을 사용해도 큰 효율 향상을 기대하기 어렵다. CPU가 계속해서 계산 작업에 몰두해야 하기 때문에, 다른 작업으로의 전환으로 인한 이득이 거의 없거나 오히려 오버헤드가 발생할 수 있다. 따라서, CPU 바운드 작업을 처리할 때는 멀티프로세싱과 같은 다른 접근 방식을 사용하는 것이 좋다. 멀티프로세싱은 여러 CPU 코어를 동시에 활용하여 여러 작업을 병렬로 처리할 수 있게 해준다.
5. Multi Processing
from concurrent.futures import ProcessPoolExecutor
import asyncio
# 비동기 라우트 내에서 멀티프로세싱을 사용하는 함수
@router.get("/cpu-intensive-task")
async def run_cpu_intensive_task():
with ProcessPoolExecutor() as executor:
# 비동기적으로 프로세스 실행 및 결과 대기
result = await asyncio.get_event_loop().run_in_executor(executor, cpu_bound_operation)
return {"result": result}이 코드는 /cpu-intensive-task 경로에 GET 요청을 보낼 때마다 cpu_bound_operation 함수를 별도의 프로세스에서 실행한다. ProcessPoolExecutor는 Python의 표준 라이브러리로, 여러 프로세스에서 병렬 실행을 가능하게 한다. 이 경우, CPU 집약적인 피보나치 수열 계산이 메인 이벤트 루프를 차단하지 않도록 별도의 프로세스에서 실행된다.
async/await를 사용하더라도, CPU 집약적 작업은 메인 스레드의 이벤트 루프를 차단할 수 있다. 비동기 프로그래밍은 I/O 바운드 작업에 적합하며, 이벤트 루프가 I/O 작업이 완료될 때까지 기다리는 동안 다른 작업을 처리할 수 있게 해준다. 그러나 CPU 바운드 작업은 계속해서 CPU 리소스를 사용하기 때문에, 이벤트 루프가 다른 비동기 작업을 수행할 기회를 얻지 못한다. 따라서, 이러한 종류의 작업은 멀티프로세싱과 같은 다른 접근 방법을 통해 처리하는 것이 좋다.
[1일차 후기]
확실히 django보다 API를 만드는데 미리 작업해야할게 적고 반환되는 데이터 형에 대해서도 언급을 해주기 때문에 가시적으로 좋다.
[참고 자료]
-
[오즈스쿨 스타트업 웹 개발 초격차캠프 백엔드 Fast API 실시간 강의]
