
Chapter 23. 구조체와 사용자 정의 자료형 2
이번 Chapter에서는 구조체 기반의 프로그램 개발에 필요한 내용을 추가로 알아보고, 구조체 이외의 사용자 정의 자료형에 대해서도 알아볼 것이다.
23-1 "구조체의 정의와 typedef 선언"
구조체 변수를 선언할 때에는 무조건 struct 선언을 추가해야 한다. 이게 꽤나 귀찮은 일인데 구조체를 정의한 후에 typedef 선언을 할 수도 있을까?
typedef 선언
먼저 typedef 선언이 무엇인지 보자.
typedef 선언은 기존에 존재하는 자료형의 이름에 새 이름을 부여하는 것을 목적으로 하는 선언이다.
예를 들어 다음과 같이 typedef 선언을 하게 되면
typedef int INT; // int의 또 다른 이름 INT를 부여이로 인해 컴파일러에게 "자료형의 이름 int에 INT라는 이름을 추가로 붙여줍니다."라는 의미를 전달하게 된다.
따라서 위의 선언 이후로는 다음의 형태로 int형 변수를 선언할 수 있다. (int를 사용하는 것과 동일해짐)
INT num;
INT * ptr;다양한 형태의 typedef 선언을 보여주는 다음 예제를 살펴보자.
#include <stdio.h>
typedef int INT;
typedef int * PTR_INT;
typedef unsigned int UINT;
typedef unsigned int * PTR_UINT;
typedef unsigned char UCHAR;
typedef unsigned char * PTR_UCHAR;
int main()
{
INT num1 = 120; // int num1 = 120;
PTR_INT pnum1 = &num1; // int * pnum1 = &num1;
UINT num2 = 190; // unsigned int num2 = 190;
PTR_UINT pnum2 = &num2; // unsigned int * pnum2 = &num2;
UCHAR ch = 'Z'; // unsigned char ch = 'Z';
PTR_UCHAR pch = &ch; // unsigned char * pch = &ch;
printf("%d, %u, %c \n", *pnum1, *pnum2, *pch);
return 0;
}
> 출력
120, 190, Ztypedef 선언에 있어서 새로운 이름의 부여는 가장 마지막에 등장하는 단어를 중심으로 이뤄진다.
따라서 위에서 typedef 선언을 통해서 새롭게 부여된 이름과 그 대상이 되는 자료형은 다음과 같다.

typedef 선언을 통해서 복잡한 유형의 자료형 선언을 매우 간결히 처리할 수 있게 되었다.
그래서 대부분의 프로그램 개발에 있어서 적지 않은 typedef 선언이 항상 포함된다.
그리고 typedef로 정의되는 자료형의 이름은 대부분 대문자로 시작하는 것이 관례다. 그래야 기본 자료형의 이름과 typedef로 새로이 정의한 자료형의 이름을 구분할 수 있기 때문이다.
구조체의 정의와 typedef 선언
그래서 구조체의 선언에 있어서 struct 선언을 생략할 수 있는 방법은 어떤것일까?
예를 들어
struct point
{
int xpos, ypos;
};라는 point라는 구조체가 정의되었다.
pos라는 이름의 구조체 변수를 선언하기 위해서는
struct point pos;라고 하게 된다.
하지만, 여기서 typedef 선언을 아래와 같이 한다면
typedef struct point Point;다음과 같은 형태로 struct 선언을 생략한채 구조체 변수를 선언할 수 있다.
Point pos;따라서 보통 구조체 정의의 뒤를 이어 typedef 선언이 등장하게 된다. 앞으로의 struct 선언을 생략을 위해 말이다!
따라서 이걸 한 곳에 묶어서 표현하면 다음과 같다.
typedef struct point
{
int xpos, ypos;
} Point;struct point에 들어갈 구조체 멤버를 바로 적어둠으로써 한번에 선언할 수 있다.
Chapter 22에서 한 예제를 가지고 typedef 선언을 추가해본 것이 아래 예제와 같다.
#include <stdio.h>
struct point
{
int xpos;
int ypos;
};
typedef struct point Point;
typedef struct person
{
char name[20];
int age;
char phoneNum[20];
} Person;
int main()
{
Point pos = {10, 20};
Person man = {"이승기", 21, "010-1212-3434"};
printf("Point position: (%d, %d)\n", pos.xpos, pos.ypos);
printf("Person's information: name - %s, age - %d, phone number - %s \n", man.name, man.age, man.phoneNum);
return 0;
}
> 출력
Point position: (10, 20)
Person's information: name - 이승기, age - 21, phone number - 010-1212-3434typedef 선언이 추가되었다고 struct 선언을 통한 구조체 변수 선언이 불가능한건 아니다! typedef 선언으로 다른 이름으로도 구조체 변수 선언이 가능해진 것 뿐이다!
구조체의 이름 생략
사실 typedef 선언과 동시에 구조체 선언이 이루어지게 되면 구조체 자체의 이름을 생략할 수 있다. 예를 들면 위 예시에서 선언한 구조체 Person의 경우 아래와 같이도 선언할 수 있다.
typedef struct
{
char name[20];
int age;
char phoneNum[20];
} Person;이렇게 되면 struct person man;의 형식으로는 구조체 변수를 선언할 수 없게 된다. 하지만 typedef 선언으로 간단하게 만들었는데 굳이 struct 선언을 이용해서 선언할 필요가 있을까? ㅎㅎ
23-2 "함수로의 구조체 변수 전달과 반환"
구조체 변수를 함수의 인자로 전달하거나 함수 내에서 return문을 통해서 구조체 변수를 반환하는 경우 발생하는 모든 현상은
int형 변수를 인자로 전달하거나 int형 변수를 반환하는 경우 발생하는 현상과 동일하다.
함수의 인자로 전달되고 return문에 의해 반환되는 구조체 변수
다음 코드를 실행하게 되면, 인자로 전달되는 변수의 값은 매개변수에 복사 된다.
void SimpleFunc(int num){....}
int main()
{
int age = 24;
SimpleFunc(age);
....
}마찬가지로 함수의 인자로 구조체 변수가 전달될 수 있으며, 이러한 인자를 전달받을 수 있도록 구조체 변수가 매개변수의 선언으로 올 수 있다.
전달되는 구조체 변수의 값은 매개변수에 통째로 복사된다.
이 현상을 확인하기 위해 다음 예제를 살펴보자.
#include <stdio.h>
typedef struct point
{
int xpos, ypos;
} Point;
void ShowPosition(Point pos)
{
printf("[%d, %d]\n", pos.xpos, pos.ypos);
}
Point GetCurrentPosition()
{
Point cen;
printf("Input current pos: ");
scanf("%d %d", &cen.xpos, &cen.ypos);
return cen;
}
int main()
{
Point curPos = GetCurrentPosition();
ShowPosition(curPos);
return 0;
}
> 출력
Input current pos: 2 4
[2, 4]구조체의 멤버로 배열이 선언되어도 위 예제에서 보인 것과 동일한 형태의 복사가 진행된다. 값의 반환과정에서도 구조체의 멤버로 선언된 배열이 통째로 복사된다.
이를 확인할 수 있는 예제를 다음에서 살펴보자.
#include <stdio.h>
typedef struct person
{
char name[20];
int age;
char phoneNum[20];
} Person;
void ShowPersonInfo(Person man)
{
printf("이름: %s \n", man.name);
printf("나이: %d \n", man.age);
printf("전화번호: %s \n", man.phoneNum);
}
Person ReadPersonInfo(void)
{
Person man;
printf("이름? ");
scanf("%s", man.name);
printf("나이? ");
scanf("%d", &man.age);
printf("전화번호? ");
scanf("%s", man.phoneNum);
return man;
}
int main()
{
Person man = ReadPersonInfo();
ShowPersonInfo(man);
return 0;
}
> 출력
이름? KMJ
나이? 30
전화번호? 010-3535-4646
이름: KMJ
나이: 30
전화번호: 010-3535-4646예제 하나를 더 보자. 이번에는 구조체 변수를 대상으로 Call-by-reference의 예를 보여준다.
#include <stdio.h>
typedef struct point
{
int xpos, ypos;
} Point;
void OrgSymTrans(Point * ptr)
{
ptr->xpos = (ptr->xpos) * -1;
ptr->ypos = -ptr->ypos; // 위와 동일
}
void ShowPosition(Point pos)
{
printf("[%d, %d] \n", pos.xpos, pos.ypos);
}
int main()
{
Point pos = {7, -5};
OrgSymTrans(&pos);
ShowPosition(pos);
OrgSymTrans(&pos);
ShowPosition(pos);
return 0;
}
> 출력
[-7, 5]
[7, -5]구조체의 포인터 변수도 매개변수로 선언이 되어서 Call-by-reference 형태의 함수호출을 구성할 수 있다.
구조체 변수를 대상으로 가능한 연산
구조체 변수를 대상으로는 매우 제한된 형태의 연산만 허용된다.
허용되는 가장 대표적인 연산은 대입연산이며, 그 이외로 주소 값 반환을 목적으로 하는 &연산이나 구조체 변수의 크기를 반환하는 sizeof정도의 연산만 허용된다.
다음 예제를 통해 구조체 변수를 대상으로 하는 연산을 확인해보자.
#include <stdio.h>
typedef struct point
{
int xpos, ypos;
} Point;
int main()
{
Point p1 = {1, 2};
Point p2;
p2 = p1; // 각 멤버 간 복사 진행
printf("크기: %d \n", sizeof(p1));
printf("p1: [%d, %d] \n", p1.xpos, p1.ypos);
printf("크기: %d \n", sizeof(p2));
printf("p2: [%d, %d] \n", p2.xpos, p2.ypos);
return 0;
}
> 출력
크기: 8
p1: [1, 2]
크기: 8
p2: [1, 2]위 예제를 통해서 구조체 변수간 대입연산의 결과로 멤버 대 멤버의 복사가 이루어짐을 확인할 수 있다.
구조체 변수 대상의 덧셈과 뺄셈연산은 구조체 안에 배열이 존재할 수도, 포인터 변수가 존재할 수도 있기 때문에 정형화하기 어렵다.
그럼 어떻게 하면 구조체 변수를 대상으로 덧셈, 뺄셈을 할 수 있을까?
다음 예제에서 보듯 함수를 정의해야 하며, 함수의 정의를 통해서 덧셈이나 뺄셈의 결과를 프로그래머가 직접 정의해야한다.
#include <stdio.h>
typedef struct point
{
int xpos, ypos;
} Point;
Point AddPoint(Point p1, Point p2)
{
Point p = {p1.xpos+p2.xpos, p1.ypos+p2.ypos};
return p;
}
Point MinPoint(Point p1, Point p2)
{
Point p = {p1.xpos-p2.xpos, p1.ypos-p2.ypos};
return p;
}
int main()
{
Point p1 = {5, 6};
Point p2 = {2, 9};
Point result;
result = AddPoint(p1, p2);
printf("구조체 변수 덧셈: [%d, %d]\n", result.xpos, result.ypos);
result = MinPoint(p1, p2);
printf("구조체 변수 뺄셈: [%d, %d]\n", result.xpos, result.ypos);
return 0;
}
> 출력
구조체 변수 덧셈: [7, 15]
구조체 변수 뺄셈: [3, -3]23-3 "구조체의 유용함에 대한 논의와 중첩 구조체"
구조체를 정의하는 이유
구조체를 정의하는 이유는 다음과 같다.
"구조체를 통해서 연관 있는 데이터를 하나로 묶을 수 있는 자료형을 정의하면, 데이터의 표현 및 관리가 용이해지고, 그만큼 합리적인 코드를 작성할 수 있게 된다."
언뜻 보면 단순히 편의를 위한 것으로 들리겠지만, 구조체의 정의는 프로그램 구현에 있어서 절대적인 위치를 차지한다.
관려해서 다음 예제를 한번 보자.
#include <stdio.h>
typedef struct student
{
char name[20]; // 학생 이름
char stdnum[20]; // 학생 학번
char school[20]; // 학교 이름
char major[20]; // 선택 전공
int year; // 학년
} Student;
void ShowStudentInfo(Student * sptr)
{
printf("학생 이름: %s \n", sptr->name);
printf("학생 학번: %s \n", sptr->stdnum);
printf("학교 이름: %s \n", sptr->school);
printf("선택 전공: %s \n", sptr->major);
printf("학년: %d \n", sptr->year);
}
int main()
{
Student arr[7];
int i;
for(i=0; i<7; i++)
{
printf("<학생 %d>\n", i+1);
printf("이름: ");
scanf("%s", arr[i].name);
printf("학번: ");
scanf("%s", arr[i].stdnum);
printf("학교: ");
scanf("%s", arr[i].school);
printf("선택 전공: ");
scanf("%s", arr[i].major);
printf("학년: ");
scanf("%d", &arr[i].year);
}
printf("\n<모든 학생 정보>\n");
for(i=0; i<7; i++)
ShowStudentInfo(&arr[i]);
return 0;
}그리 어려운 예제는 아니다.
하지만 다수의 학생정보를 입력 받아서 저장하고 저장된 내용을 출력하기 위해서 구조체를 정의하지 않고 작성하려고 하면...
하나의 배열에 모든 데이터를 저장할 수 없게 된다. 다수의 배열이 필요하게 되고 출력할 데이터의 종류만큼 매개변수가 선언되어야 한다.
구조체의 정의가 필요한 상황에서 구조체를 정의하지 않으면 어떻게 되는지 잘 보여준다.
중첩된 구조체의 정의와 변수의 선언
배열이나 포인터 변수가 구조체의 멤버로 선언될 수 있듯이, 구조체 변수도 구조체의 멤버로 선언될 수 있다.
구조체 안에 구조체 변수가 멤버로 존재하는 경우를 가리켜 구조체의 중첩이라 한다.
다음 예제에서 정의된 구조체의 의미를 이해해보자.
#include <stdio.h>
typedef struct point
{
int xpos, ypos;
} Point;
typedef struct circle
{
Point center;
double radius;
} Circle;
void ShowCircleInfo(Circle *cptr)
{
printf("Circle center: [%d, %d] \n", (cptr->center).xpos, (cptr->center).ypos);
printf("Circle radius: %g \n\n", cptr->radius);
}
int main()
{
Circle c1 = {{1, 2}, 3.5};
Circle c2 = {{2, 4}, 3.9};
ShowCircleInfo(&c1);
ShowCircleInfo(&c2);
return 0;
}
> 출력
Circle center: [1, 2]
Circle radius: 3.5
Circle center: [2, 4]
Circle radius: 3.9참고로 구조체 변수를 초기화하는 경우에도 배열의 초기화와 마찬가지로 초기화하지 않은 일부 멤버에 대해서는 0으로 자동 초기화가 진행된다.
23-4 "공용체(Union Type)의 정의와 의미"
구조체는 struct라는 키워드를 사용해서 정의하는 반면, 공용체는 union이라는 키워드를 사용해서 정의한다.
구조체 vs. 공용체
공용체는 구조체와 비교하면 쉽게 이해할 수 있다.
동일한 구성의 멤버를 이용해서 구조체와 공용체를 각각 정의해보겠다.
typedef struct sbox // 구조체 sbox 정의
{
int mem1;
int mem2;
double mem3;
} SBox;
typedef union ubox // 공용체 ubox 정의
{
int mem1;
int mem2;
double mem3;
} UBox;위 두 가지 선언은 어떤 키워드를 썼는지에 차이가 있고 나머지는 동일하다.
하지만, 각각의 변수가 메모리 공간에 할당되는 방식과 접근의 결과에는 많은 차이가 있다.
위 구조체와 공용체를 대상으로 각각 다음 연산을 하면 다른 결과를 얻는다.
printf("%d \n", sizeof(SBox)); // 16 출력
printf("%d \n", sizeof(UBox)); // 8 출력16은 모든 멤버의 크기를 합한 결과고, 8은 멤버 중 가장 크기가 큰 double 크기만 계산된 결과이다.
구조체와 공용체의 특성을 이해할 수 있는 예제를 하나 살펴보자.
#include <stdio.h>
typedef struct sbox
{
int mem1;
int mem2;
double mem3;
} SBox;
typedef union ubox
{
int mem1;
int mem2;
double mem3;
} UBox;
int main()
{
SBox sbx;
UBox ubx;
printf("%p %p %p \n", &sbx.mem1, &sbx.mem2, &sbx.mem3);
printf("%p %p %p \n", &ubx.mem1, &ubx.mem2, &ubx.mem3);
printf("%d %d \n", sizeof(SBox), sizeof(UBox));
return 0;
}
> 출력
0061FF10 0061FF14 0061FF18
0061FF08 0061FF08 0061FF08
16 8실행결과에서 가장 눈여겨 봐야할 부분은 UBox형 변수를 구성하는 멤버 mem1, mem2, mem3의 주소값이 동일하다는 것이다.
공용체는 다음 그림과 같은 할당특성을 가지고 있다.
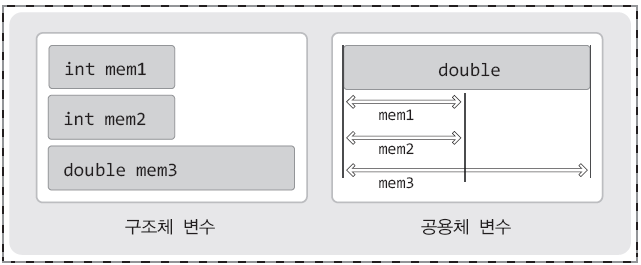
구조체 변수가 선언되면, 구조체를 구성하는 멤버는 각각 할당이 된다. 반면 공용체 변수가 선언되면, 공용체를 구성하는 멤버는 각각 할당되지 않고, 그 중 크기가 가장 큰 멤버의 변수만 하나 할당되어 이를 공유하게 된다.
이러한 특성을 확인하기 위해 다음 예제를 살펴보자.
#include <stdio.h>
typedef union ubox
{
int mem1;
int mem2;
double mem3;
} UBox;
int main()
{
UBox ubx;
ubx.mem1=20;
printf("%d \n", ubx.mem2);
ubx.mem3=7.15;
printf("%d \n", ubx.mem1);
printf("%d \n", ubx.mem2);
printf("%g \n", ubx.mem3);
return 0;
}
> 출력
20
-1717986918
-1717986918
7.15실행결과 공용체의 멤버들이 메모리 공간을 공유하고 있다는 것을 알 수 있다.
이러한 공용체는 어떤 경우에 사용될까?
공용체의 유용함
공용체의 유용함은 간단히 설명되지 않지만 결과적으로 하나의 메모리 공간을 둘 이상의 방식으로 접근할 수 있다.
공용체의 유용함을 이해할 수 있는 예제를 하나 살펴보자.
프로그램 사용자로부터 int형 정수 하나를 입력 받는다.
입력 받은 정수의 상위 2바이트와 하위 2바이트 값을 양의 정수로 출력하고 상위 1바이트와 하위 1바이트에 저장된 값의 아스키 문자를 출력하는 것이다.
#include <stdio.h>
typedef struct dbshort
{
unsigned short upper;
unsigned short lower;
} DBShort;
typedef union rdbuf
{
int iBuf;
char bBuf[4];
DBShort sBuf;
} RDBuf;
int main()
{
RDBuf buf;
printf("정수 입력: ");
scanf("%d", &(buf.iBuf));
printf("상위 2바이트: %u \n", buf.sBuf.upper);
printf("하위 2바이트: %u \n", buf.sBuf.lower);
printf("상위 1바이트 아스키 코드: %c \n", buf.bBuf[0]);
printf("하위 1바이트 아스키 코드: %c \n", buf.bBuf[3]);
return 0;
}
> 출력
정수 입력: 1145258561
상위 2바이트: 16961
하위 2바이트: 17475
상위 1바이트 아스키 코드: A
하위 1바이트 아스키 코드: D공용체 변수는 메모리 공간에 다음 그림과 같은 형태로 할당되고 공유된다.
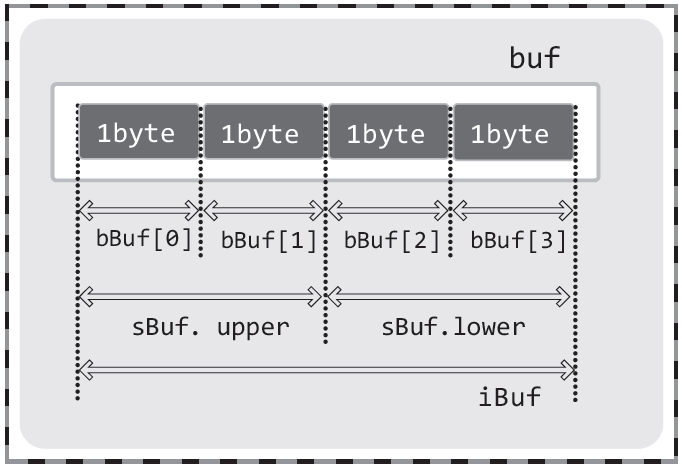
공용체의 적절한 정의를 통해서 4바이트 메모리 공간을 2바이트씩, 그리고 1바이트씩 접근할 수 있다.
23-5 "열거형(Enumerated Type)의 정의와 의미"
열거형은 구조체나 공용체와 마찬가지로 자료형을 정의하는 방법으로 사용된다.
따라서 열거형 기반의 자료형 정의방법은 구조체 및 공용체와 유사하고 정의된 열거형 기반의 변수 선언 방법은 구조체 및 공용체와 완전히 동일하다.
열거형의 정의와 변수의 선언
열거형으로 'syllable'이라는 이름의 자료형을 정의한다는 것은 "syllable형 변수에 저장이 가능한 정수 값들을 결정하겠다!"라는 의미이다.
구조체와 공용체의 경우 자료형의 선언을 통해 멤버에 저장할 값의 유형을 결정하였다.
하지만 열거형의 경우에는 저장이 가능한 값 자체를 정수의 형태로 결정한다.
간단하게 열거형을 하나 정의해 보겠다.
enum syllable // syllable이라는 열거형 정의
{
Do=1, Re=2, Mi=3, Fa=4, So=5, La=6, Ti=7
};struct 키워드 대신에 enum 키워드가 있고 구조체의 정의방식과 마찬가지로 enum에 이어 자료형의 이름 syllable이 등장했다.
그리고 syllable에 관한 내용은 중괄호 안에 선언되었다.
그 중 가장 첫 번째 멤버 Do=1의 의미는 "Do를 정수 1을 의미하는 상수로 정의한다. 그리고 이 값은 syllable형 변수에 저장이 가능하다."라는 뜻이다.
자세한 이해를 위해 예제를 하나 살펴보자.
#include <stdio.h>
typedef enum syllable
{
Do=1, Re=2, Mi=3, Fa=4, So=5, La=6, Ti=7
} Syllable;
void Sound (Syllable sy)
{
switch(sy)
{
case Do:
puts("도는 하얀 도라지 ♪"); return;
case Re:
puts("레는 둥근 레코드 ♩"); return;
case Mi:
puts("미는 파란 미나리 ♩ ♪"); return;
case Fa:
puts("파는 예쁜 파랑새 ♪ ♭"); return;
case So:
puts("솔은 작은 솔방울 ♩ ♪ ♪"); return;
case La:
puts("라는 라디오고요~ ♪ ♩ ♭ ♩"); return;
case Ti:
puts("시는 졸졸 시냇물 ♩ ♭ ♩ ♪"); return;
}
puts("다 함께 부르세~ 도레미파 솔라시도 솔 도~ 짠~");
}
int main()
{
Syllable tone;
for(tone=Do; tone<=Ti; tone+=1)
Sound(tone);
return 0;
}
> 출력
도는 하얀 도라지 ♪
레는 둥근 레코드 ♩
미는 파란 미나리 ♩ ♪
파는 예쁜 파랑새 ♪ ♭
솔은 작은 솔방울 ♩ ♪ ♪
라는 라디오고요~ ♪ ♩ ♭ ♩
시는 졸졸 시냇물 ♩ ♭ ♩ ♪위 반복문에서 Do나 Ti는 1과 7로 바꿔도 결과가 동일하다.
Case 레이블에 사용된 Do~Ti를 대신해서 정수 1~7로 바꿔도 결과가 동일하다.
따라서, int형 데이터가 올 수 있는 위치에는 열거형 상수가 올 수 있다.
열거형 상수의 값이 결정되는 방식
열거형을 정의하는데 상수 값을 명시하지 않으면 어떻게 될까?
예시로 enum color {RED, BLUE, WHITE, BLACK};을 선언하면 열거형의 상수 값은 0부터 시작해서 1씩 증가하는 형태로 결정된다. enum color {RED=0, BLUE=1, WHITE=2, BLACK=3};
이번에는 일부만 정의하면 어떻게 될까?
enum color {RED=3, BLUE, WHITE=6, BLACK};
선언되지 않은 상수는 선언된 상수보다 1 증가된 값이 자동으로 할당된다. enum color {RED=3, BLUE=4, WHITE=6, BLACK=7};
열거형의 유용함
열거형은 구조체 및 공용체와 정의하는 방식이 유사함에도 불구하고 정의하는 목적에는 큰 차이가 있다.
구조체와 공용체는 자료형의 정의에 의미가 있다.
즉, 변수를 선언하기 위해서 자료형을 정의하는 것이다.
열거형도 마찬가지로 정의하고 나면 해당 열거형의 변수 선언이 가능하다는 점에서 비슷하지만, 연관이 있는 이름을 동시에 상수로 선언할 수 있다는 점에서 차이가 있다.
따라서, 열거형의 유용함은 둘 이상의 연관이 있는 이름을 상수로 선언함으로써 프로그램의 가독성을 높이는데 있다.
실제로 변수의 선언이 목적이 아닌 경우에는
enum{Do=1, Re=2, Mi=3, Fa=4, So=5, La=6, Ti=7};와 같이 정의하기도 한다.
<Review>
구조체의 응용과 더불어 공용체와 열거형까지 배워봤다.
재밌고 신기한 C언어의 세계!
파이썬에서 기본적으로 제공해주는 자료형들이 어떻게 나오게되었는지 이해할 수 있는 날이었다.
지금 인턴십과 더불어 공부하려고 하니 쉽지 않은데,,,
이렇게 공부함으로써 머리를 환기시키고 두뇌를 회전시키는 느낌은 너무 좋다 ㅎㅎㅎ
피할 수 없으면 즐겨라!
이따가 인턴십에, 책 대출, 택배 편의점 수령, 장례식(🥲) 참석, C언어 스터디도 있지만,,,
하루하루 알차게 살 수 있어 뿌듯하다!
내일도 화이팅~!

