
리스트는 대표적인 선형 자료구조이다.
연결 리스트의 지옥에서 벗어나 이번에 배울 스택도 선형 자료구조의 일종이다.
챕터가 하나로만 이루어져 있으니 조금은 더 쉬울 것이라는 긱대를 하면서어...!
그럼 레츠고우~!

06-1. 스택의 이해와 ADT 정의
스택(Stack)의 이해
스택(Stack)은 후입선출(後入先出)방식의 자료구조로, 'LIFO(First-In, First-Out)'구조의 자료구조라고도 불린다.
한쪽은 막히고 한쪽은 뚤려 있어 먼저 들어간 것이 나중에 나온다고 생각하면 된다.
그럼 리스트보다 간단한가?
맞다고만 할 순 없다...
스택의 활용 혹은 스택 기반의 알고리즘들이 의외로 간단하지 않아 스택을 공부하는 것 보단 스택을 경험하는데 더 노력이 필요하다.
스택 ADT 정의
스택을 가지고 사용할 수 있는 기능에는 어떤 것들이 있을까?
- 데이터 저장 (push)
- 데이터 내보내기 (pop)
- 데이터 들여다보기 (peek)
이렇게 크게 세 가지가 있고 하나 더 추가한다면 데이터 유무 확인일 것이다. 위 세 가지 연산은 스택의 기본 연산이다.
이러한 기능들을 정의하면 다음과 같다.
✅Operations:
-
void StackInit(Stack * pstack);
- 스택의 초기화를 진행
- 스택 생성 후 제일 먼저 호출되는 함수
-
int SIsEmpty(Stack * pstack);
- 스택이 빈 경우 TRUE(1)을, 그렇지 않은 경우 FALSE(0) 반환
-
void SPush(Stack * pstack, Data data);
- 스택에 데이터를 저장. 매개변수 data로 전달된 값을 저장
-
Data SPop(Stack * pstack);
- 마지막에 저장된 요소 삭제
- 삭제된 데이터는 반환
- 본 함수의 호출을 위해서는 데이터가 하나 이상 존재 필수. (SIsEmpty 함수 활용)
-
Data SPeek(Stack * pstack);
- 마지막에 저장된 요소를 반환하되 삭제하지 않음
- 본 함수의 호출을 위해서는 데이터가 하나 이상 존재 필수. (SIsEmpty 함수 활용)
스택의 ADT를 정의했으니 스택 구현을 위한 구조체를 정의하고 헤더파일을 디자인할 차례다.
그 전에 결정해야할 사항이 하나 있다.
- 배열 기반의 스택 구현
- 연결 리스트 기반의 스택 구현
스택은 배열로도, 연결 리스트로도 구현이 가능하다.
차근 차근히, 하나 하나 배워보도록 하자.
06-2. 스택의 배열 기반 구현
배열 기반 스택 구현의 논리
스택은 리스트에 비해 상황이 다양하지 않다.
단순히 데이터를 추가하고 꺼내는 상황을 생각하면 된다.
먼저 데이터를 추가하는 상황을 그림으로 표현한 것이다.
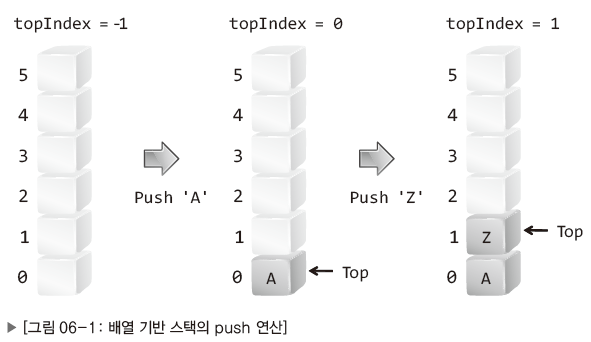
이 그림에서 주목할 것은 두 가지 있다.
- 인덱스 0의 배열 요소가 '스택의 바닥'으로 정의되었다.
- 마지막에 저장된 데이터의 위치를 기억해야 한다.
우선 인덱스 0의 배열 요소를 스택의 바닥으로 둔 이유는 "인덱스 0의 요소를 스택의 바닥으로 정의하면, 배열의 길이에 상관 없이 언제나 인덱스 0의 요소가 스택의 바닥이 되기 때문"이다.
그리고 위 그림에서는 가장 최근에 저장된 (가장 위에 저장된) 데이터를 Top으로 가리키고 있으며 이 Top이 가리키는 위치의 인덱스 값을 변수 topIndex에 저장하고 있다.
(실제로 Top은 변수 topIndex를 의미한다.)
이렇듯 마지막에 저장된 데이터의 위치를 별도로 기억해 둬야 다음과 같이 push연산과 pop 연산을 쉽게 완성할 수 있다.
- push : Top을 위로 한 칸 올리고, Top이 가리키는 위치에 데이터 저장.
- pop : Top이 가리키는 데이터를 반환하고 Top을 아래로 한 칸 내림.
배열 기반 스택 구현 1: 헤더파일의 정의
배열 기반 스택은 그 구조가 단순하다.
push와 pop에 대해 이해하였고 ADT도 개략 정의했으니 이를 기반으로 스택의 헤더파일을 정의해보자.
#ifndef __AB_STACK_H__
#define __AB_STACK_H__
#define TRUE 1
#define FALSE 0
#define STACK_LEN 100
typedef int Data;
typedef struct _arrayStack
{
Data stackArr[STACK_LEN];
int topIndex;
} ArrayStack;
typedef ArrayStack Stack;
void StackInit(Stack * pstack); // 스택의 초기화
int SIsEmpty(Stack * pstack); // 스택이 비엇는지 확인
void SPush(Stack * pstack, Data data); // 스택의 push 연산
Data SPop(Stack * pstack); // 스택의 pop 연산
Data SPeek(Stack * pstack); // 스택의 peek 연산
#endif배열 기반 스택 구현 2: 소스파일의 정의
스택을 표현한 다음 구조체의 정의를 보면 StackInit 함수를 무엇으로 채워야할지 알 수 있다.
typedef struct _arrayStack
{
Data stackArr[STACK_LEN]; // typedef int Data;
int topIndex;
} ArrayStack;이 중에서 초기화할 멤버는 가장 마지막에 저장된 데이터의 위치를 가리키는 topIndex 하나다. 따라서 StackInit 함수는 다음과 같이 정의된다.
void StackInit(Stack * pstack)
{
pstack->topIndex = -1; // topIndex의 -1은 빈 상태를 의미
}topIndex에 0이 저장되면 이는 인덱스 0의 위치에 마지막 데이터가 저장되었음을 뜻한다.
따라서 topIndex를 0이 아닌 -1로 초기화해야한다.
이어서 SIsEmpty 함수는 스택이 비어있는지 확인할 때 호출하는 함수다.
스택이 비어있는 경우 topIndex의 값이 -1인지로 알 수 있고 다음과 같이 구현 가능하다.
int SIsEmpty(Stack * pstack)
{
if(pstack->topIndex == -1) // 스택이 비어있는 상태일 경우
return TRUE;
else
return FALSE;
}이제 스택의 핵심인 SPush 함수와 SPop함수를 구현해보자.
void SPush(Stack * pstack, Data data) // push 연산 함수
{
pstack->topIndex += 1; // 데이터 추가를 위한 인덱스 값 증가
pstack->stackArr[pstack->topIndex] = data; // 데이터 저장
}
Data SPop(Stack * pstack) // pop 연산 함수
{
int rIdx;
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
rIdx = pstack->topIndex; // 삭제할 데이터가 저장된 인덱스 값 저장
pstack->topIndex -= 1; // pop 연산의 결과로 topIndex 값 하나 감소
return pstack->stackArr[rIdx]; // 삭제되는 데이터 반환
}SPop 함수에서 유의해야할 점은 데이터를 꺼낸다는 것이 삭제와 반환의 의미를 모두 담고 있다는 것이다.
꺼냈으니 삭제된 것이고, 반환도 이뤄진 것이다.
topIndex의 값을 근거로 데이터를 저장하니 이 변수에 저장된 값을 하나 감소시키는 것만으로도 데이터의 소멸은 완성된다.
이제 마지막으로 SPeek 함수를 정의하자.
SPop 함수와 달리 반환한 데이터를 삭제시키진 않는다.
Data SPeek(Stack * pstack) // peek 연산 함수
{
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
return pstack->stackArr[pstack->topIndex]; // 맨 위에 저장된 데이터 반환
}프로그램을 구현하다보면 스택이 반환할 다음 데이터를 확인할 필요가 간혹있다. 데이터 확인을 하되 소멸시키지 않는 함수가 필요한데 그 때 peek 연산을 담당한 함수를 사용하면 된다.
소스파일을 하나로 정리하면 다음과 같다.
#include <stdio.h>
#include <stdlib.h>
#include "ArrayBaseStack.h"
void StackInit(Stack * pstack)
{
pstack->topIndex = -1;
}
int SIsEmpty(Stack * pstack)
{
if(pstack->topIndex == -1)
return TRUE;
else
return FALSE;
}
void SPush(Stack * pstack, Data data)
{
pstack->topIndex += 1;
pstack->stackArr[pstack->topIndex] = data;
}
Data SPop(Stack * pstack)
{
int rIdx;
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
rIdx = pstack->topIndex;
pstack->topIndex -= 1;
return pstack->stackArr[rIdx];
}
Data SPeek(Stack * pstack)
{
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
return pstack->stackArr[pstack->topIndex];
}배열 기반 스택 구현 3: 실행파일의 정의
배열 기반의 스택을 잘 구현했는지 확인하기 위한 실행 파일(main 함수)는 다음과 같다.
#include <stdio.h>
#include "ArrayBaseStack.h"
int main()
{
// Stack의 생성 및 초기화
Stack stack;
StackInit(&stack);
// 데이터 넣기
SPush(&stack,1);
SPush(&stack,2);
SPush(&stack,3);
SPush(&stack,4);
SPush(&stack,5);
// 데이터 꺼내기
while(!SIsEmpty(&stack))
printf("%d ", SPop(&stack));
return 0;
}
> gcc .\ArrayBaseStack.c .\ArrayBaseStackMain.c
> .\a.exe
> 출력
5 4 3 2 1 실행결과에서 입력된 데이터가 역순으로 출력되는 것을 알 수 있다. 이것이 스택의 가장 중요한 특성이다.
06-3. 스택의 연결 리스트 기반 구현
기능적인 부분만 고려한다면 배열은 대부분 연결 리스트로 교체가 가능하다.
배열도 연결 리스트도 기본적인 선형 자료구조이기 때문이다.
연결 리스트 기반 스택 구현 1: 헤더파일의 정의
앞서 구현한 스택에서 배열을 연결 리스트로 변경할 경우, 연결 리스트가 갖는 특징이 그대로 스택에 반영된다.
스택을 연결 리스트로 구현할 때 생각하면 될 부분을 저장된 순서의 역순으로 조회(삭제)가 가능한 연결리스트라는 것이다.
앞서 배운 연결 리스트 종류 중에서 새로운 노드를 꼬리가 아닌 머리에 추가한 형태의 연결 리스트가 스택과 유사하다!
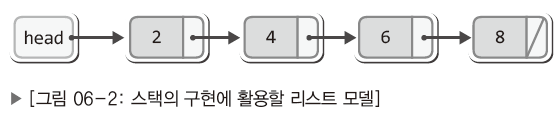
따라서 스택을 구현하기 위해서 필요한 것은 포인터 변수 head 하나다.
연결 리스트 기반의 스택을 위한 헤더파일은 다음과 같이 정의할 수 있다.
// ListBaseStack.h
#ifndef __LB_STACK_H__
#define __LB_STACK_H__
#define TRUE 1
#define FALSE 0
typedef int Data;
typedef struct _node // 연결 리스트의 노드를 표현한 구조체
{
Data data;
struct _node * next;
} Node;
typedef struct _listStack // 연결 리스트 기반 스택을 표현한 구조체
{
Node * head;
} ListStack;
typedef ListStack Stack;
void StackInit(ListStack * pstack); // 스택 초기화
int SIsEmpty(Stack * pstack); // 스택이 비어 있는지 확인
void SPush(Stack * pstack, Data data); // 스택 push 연산
Data SPop(Stack * pstack); // 스택 pop 연산
Data SPeek(Stack * pstack); // 스택 top (peek) 연산
#endif연결 리스트 기반 스택 구현 2: 소스파일의 정의
가장 먼저 정의할 함수는 스택을 초기화하는 StackInit 함수와 스택이 비어있는지 확인하는 SIsEmpty 함수다.
void StackInit(Stack * pstack)
{
pstack->head = NULL; // 포인터 변수 head를 NULL로 초기화
}
int SIsEmpty(Stack * pstack)
{
if(pstack->head == NULL) // 스택이 비어 있는 경우 head에 NULL이 저장.
return TRUE;
else
return FALSE;
}그 다음엔 SPush 함수를 정의해보려 한다.
리스트의 머리에 새 노드를 추가해야하는 함수로 다음과 같이 구현할 수 있다.
void SPush(Stack * pstack, Data data)
{
Node * newNode = (Node*)malloc(sizeof(Node)); // 새 노드 생성
newNode->data = data; // 새 노드 데이터 저장
newNode->next = pstack->head; // 새 노드가 최근에 추가된 노드를 가리킴
pstack->head = newNode; // 포인터 변수 head가 새 노드를 가리킴
}반대로 SPop 함수는 포인터 변수 head가 가리키는 노드를 소멸시키고, 소멸된 노드의 데이터를 반환해야하므로 다음과 같이 정의해야한다.
Data SPop(Stack * pstack)
{
Data rdata;
Node * rnode;
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
rdata = pstack->head->data; // 삭제할 노드의 데이터를 임시로 저장
rnode = pstack->head; // 삭제할 노드의 주소 값을 임시로 저장
pstack->head = pstack->head->next; // 삭제할 노드의 다음 노드를 head가 가리킴
free(rnode); // 노드 삭제
return rdata; // 삭제된 노드의 데이터 반환
}마지막으로 SPeek 함수의 정의다.
Data SPeek(Stack * pstack)
{
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
return pstack->head->data; // head가 가리키는 노드에 저장된 데이터 반환
}위에서 정의한 함수들을 정리한 소스파일은 다음과 같다.
// ListBaseStack.c
#include <stdio.h>
#include <stdlib.h>
#include "ListBaseStack.h"
void StackInit(Stack * pstack)
{
pstack->head = NULL;
}
int SIsEmpty(Stack * pstack)
{
if(pstack->head == NULL)
return TRUE;
else
return FALSE;
}
void SPush(Stack * pstack, Data data)
{
Node * newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = pstack->head;
pstack->head = newNode;
}
Data SPop(Stack * pstack)
{
Data rdata;
Node * rnode;
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
rdata = pstack->head->data;
rnode = pstack->head;
pstack->head = pstack->head->next;
free(rnode);
return rdata;
}
Data SPeek(Stack * pstack)
{
if(SIsEmpty(pstack))
{
printf("Stack Memory Error!");
exit(-1);
}
return pstack->head->data;
}연결 리스트 기반 스택 구현 3: 실행파일의 정의
지금까지 구현한 연결 리스트 기반 스택이 잘 작동하는지 확인하기 위한 main 함수는 다음과 같다.
// ListBaseStackMain.c
#include <stdio.h>
#include "ListBaseStack.h"
int main()
{
// Stack의 생성 및 초기화
Stack stack;
StackInit(&stack);
// 데이터 넣기
SPush(&stack, 1);
SPush(&stack, 2);
SPush(&stack, 3);
SPush(&stack, 4);
SPush(&stack, 5);
// 데이터 꺼내기
while(!SIsEmpty(&stack))
printf("%d ", SPop(&stack));
return 0;
}
>gcc .\ListBaseStack.c .\ListBaseStackMain.c
> .\a.exe
> 출력
5 4 3 2 1 06-4. 계산기 프로그램 구현
구현할 계산기 프로그램 특징
구현할 계산기의 특징은 다음과 같다.
- 소괄호를 파악하여 그 부분을 먼저 연산한다.
- 연산자의 우선수위를 근거로 연산의 순위를 결정한다.
스택만 알아서는 계산기를 구현하기 어렵다.
계산기 구현에 필요한 별도의 알고리즘에 대해 알아보자.
수식의 표기법 - 중위, 전위, 후위 표기법
계산기 구현에 필요한 부가 알고리즘에 대해 알아보기 전에 계산기의 기능을 어느정도 제한하고자한다.
수식을 이루는 피연산자는 한자리 숫자로만 이뤄진다는 점이다.
따라서 1의 자리 숫자들로만 계산을 진행할 예정이다.
계산기 구현에 필요한 알고리즘의 첫 번째 단계로 수식의 표기법에 대해 알아보자.
수식을 표기하는 방법에는 세 가지 방법이 있다.
- 중위 표기법 (Infix Notation)
ex) 5 + 2 / 7 - 전위 표기법 (Prefix Notation)
ex) + 5 / 2 7 - 후위 표기법 (Postfix Notation)
ex) 5 2 7 / +
우리가 평소에 사용하고 많이 봐온 표기법이 중위 표기법이다.
이 표기법에는 수식의 연산 순서에 대한 정보가 담겨 있지 않다.
우리는 어렸을 때부터 +(덧셈)와 -(뺄셈)보다 X(곱셈)과 /(나눗셈)이 먼저 계산되어야 한다는 것을 배웠기 때문에 알고 있는 것이지 단순히 연산만 처음 본 것이면 알 수 없다.
전위 표기법이나 후위 표기법에는 이러한 연산들의 순서에 대한 정보가 담겨져 있다.
예를 들어 5 + 2 / 7이 수식을 연산자를 OP1, OP2로 보고 후위 표기법으로 표현하고 나면 5 2 7 OP1 OP2와 같은 방식으로 표현할 수 있다.
그러면 단순히 OP1과 OP2가 뭔진 몰라도 OP1 연산자를 먼저 실행하고 OP2 연산자를 실행해야하겠구나를 알 수 있다.
그리고 연산자의 배치 순서를 바꿈으로써 연산의 순서를 바꿀 수 있기 때문에 소괄호가 필요하지도 않다.
즉, 전위 표기법의 수식이나 후위 표기법의 수식은 연자나의 배치 순서에 따라서 연산순서가 결정되기 때문에 이 두 표기법의 수식을 계산하기 위해서 연산자의 우선순위를 알 필요가 없고, 소괄호도 삽입되지 않으니 소괄호에 대한 처리도 불필요하다.
<중위 표기법> ( 1 + 2 ) 7
<전위 표기법> + 1 2 7
<후위 표기법> 1 2 + 7 *
따라서 우리는 계산기 사용자는 중위 표기법으로 수식을 입력하면
우리는 이것을 전위 표기법 또는 후위 표기법으로 바꿀 수 있도록 할 것이다. (후위 표기법으로 구현할 예정.)
그렇다면 실제로 구현을 위해 중위 표기법을 후위 표기법으로 변환하는 과정에 대해 알아보자.
중위 표기법 → 후위 표기법 방법 1: 소괄호 고려 X
이번에 구현할 계산기는 다음과 같은 과정을 거쳐서 연산을 하도록 할 것이다.
- 중위 표기법의 수식을 후위 표기법의 수식으로 바꾼다.
- 후위 표기법으로 바뀐 수식을 계산하여 그 결과를 얻는다.
각각의 과정 모두 별도의 알고리즘이 필요하다.
두 과정은 별개의 과정으로 진행되며 우리는 그 중 첫 번째 과정에 대해 이해해보려 한다.
이해를 돕기 위해서 예시로 5 + 2 / 7수식을 구성하는 연산자와 피연산자가 블록들로 있고 쟁반이 하나 있다고 가정한다.

우리는 5블록부터 7블록까지 후위 표기법이라는 일관된 방식으로 처리할 것이다.
우선 피연산자는 바로 통과가 되어 변환된 수식 자리로 이동한다.
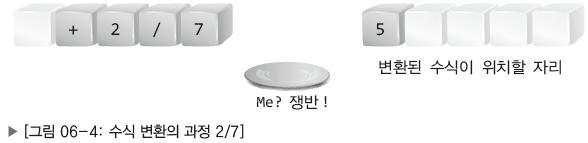
이 후 연산자 블록을 만나게 되면 쟁반에 담아둔다.
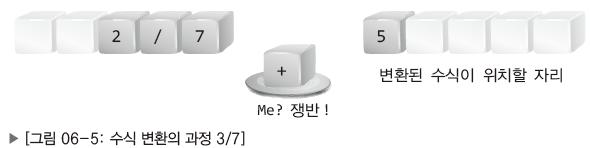
이 후 만난 피연산자 블록을 변환된 수식 자리로 이동시킨다.
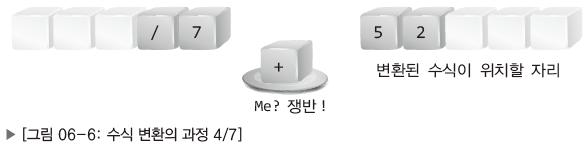
이번에는 /라는 연산자를 만나게 되었는데 여기서 두 연산자의 우선순위를 비교해야한다.
-
쟁반에 위치한 연산자의 우선순위가 높다면
: 쟁반에 위치한 연산자를 꺼내어 변환된 수식 자리로 이동시키고 새 연산자를 쟁반에 놓는다. -
쟁반에 위치한 연산자의 우선순위가 낮다면
: 쟁반에 위치한 연산자 위에 새 연산자를 놓는다. (스택)
/(나눗셈)은 +(덧셈)보다 우선순위가 높기 때문에 2번 방법을 통해 다음과 같이 이동한다.
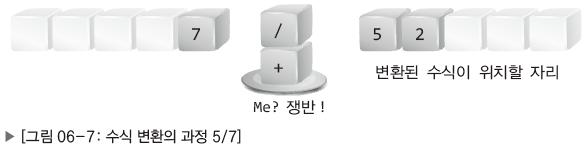
우선순위가 높은 연산자를 우선순위가 낮은 연산자 위에 올려서 우선순위가 낮은 연산자가 변환된 수식 자리로 이동하지 못하게 한다.
이 후 피연산자인 7을 변환된 수식 자리로 이동시킨다.
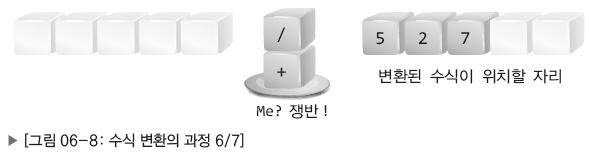
이제 쟁반 위에 있는 연산자 블록들을 처리해야하는데 이때 스택의 원리를 이용해서 위에 있는 블록부터 차례대로 변환된 수식 자리로 이동시킨다.

따라서 위 과정을 정리하면 다음과 같다.
<중위 표기법 → 후위 표기법 (소괄호 X)>
1. 피연산자는 그냥 옮긴다.
2. 연산자는 쟁반으로 옮긴다.
3. 연산자가 쟁반에 있다면 우선순위를 비교하여 처리 방법을 결정한다.
4. 마지막으로 쟁반에 남아있는 연산자들을 하나씩 옮긴다.
만약 우선순위가 동일한 연산자 둘이 만나면 어떻게 될까?
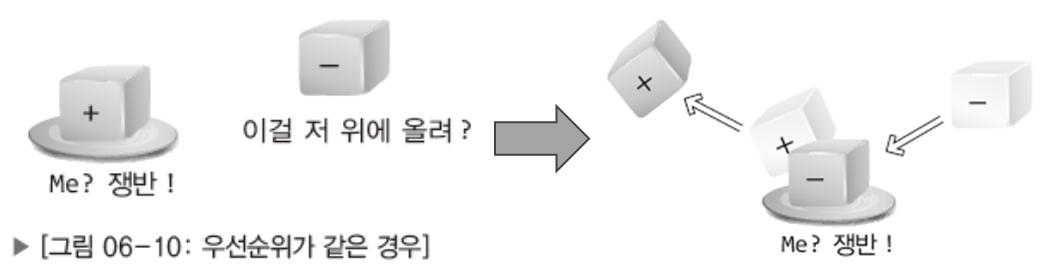
위 그림과 같이 +블록과 -블록이 만나면 +블록을 변환된 수식으로 옮긴 뒤 빈 쟁반에 -블록을 올려놓는다.
만약에 우선순위가 높은 연산자를 만나 쟁반에 블록 2개가 있는데 이보다 우선 순위가 낮은 경우엔 어떻게 될까?
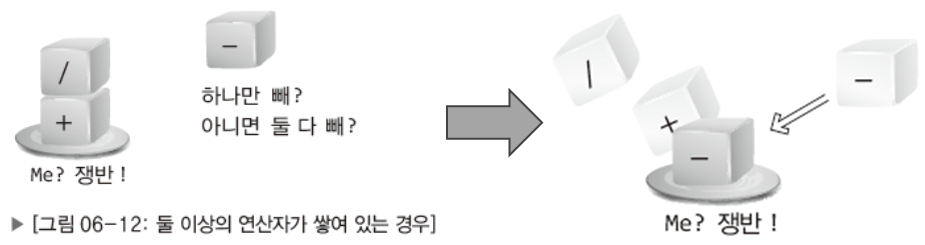
위 그림과 같이 +블록과 /블록이 쌓여 있는 상태에서 -블록을 만나게 되면 쟁반 위에 있는 블록들을 하나씩 변환된 수식으로 옮긴 후 빈 쟁반에 -블록을 올려놓으면 된다.
따라서 쟁반에는 자신보다 나중에 연산이 이뤄져야 하는 연산자의 위에 올라서 있어야한다.
중위 표기법 → 후위 표기법 방법 2: 소괄호 고려 O
이번에는 소괄호도 포함되어 있는 중위 표기법을 후위 표기법으로 바꾸는 방법에 대해 생각해보자.
후위 표기법의 수식에서는 먼저 연산이 이뤄져야 하는 연산자가 뒤에 연산이 이뤄지는 연산자보다 앞에 위치해야한다는 점을 생각하며 이해해보자.
예시로 ( 1 + 2 * 3 ) / 4라는 수식에 대해 블록과 쟁반으로 그 과정을 이해해보자.

(연산자의 우선순위는 그 어떤 사칙 연산자들보다 낮다고 간주하자.
따라서 ) 연산자가 등장할 때까지 쟁반에 남아 소괄호의 경계 역할을 해야한다.

이후에 )연산자가 나오기 전까지는 소괄호가 없을 때의 경우와 동일하게 진행한다.


)연산자를 만나고 쟁반 위에 있던 연산자들을 모두 변환된 수식으로 하나씩 옮기고 괄호들은 옮길 필요가 없다.

마지막으로 남은 블록들도 정리하면 아래와 같이 정리된다.

따라서 괄호가 있을 때 유의할 점은 )연산자를 만나면 (연산자를 만날 때까지 연산자를 변환된 수식 자리로 이동시키고 괄호 블록들은 삭제된다는 것이다.
중위 표기법을 후위 표기법으로 바꾸는 방법: 프로그램의 구현 (소스파일)
이제 위에서 설명한 것들을 코드로 구현해보자.
후위 표기법으로 변환하는 함수를 다음과 같은 형태로 정의하자.
void ConvToRPNExp(char exp[]) // 후위 표기법의 수식으로 변환
{
....
}
// RPN : Reverse Polish Notation함수의 매개변수 형과 반환형을 위와 같이 정의한 의도는 중위 표기법의 수식을 담고 있는 배열의 주소 값을 인자로 전달하면서 ConvToRPNExp 함수를 호출하면 인자로 전달된 주소 값의 배열에는 후위 표기법으로 바뀐 수식이 저장된다는 것이다.
따라서 실행 파일에서는 다음과 같이 함수가 호출되어야 한다.
int main()
{
char exp[] = "3-2+4"; // 중위 표기법 수식
ConvToRPNExp(exp); // 후위 표기법으로 수식 변환 요청
}ConvToRONExp 함수를 도와주는 함수도 몇가지 있다.
그 중 첫 번째는 인자로 전달된 연산자의 우선순위 정보를 정수의 형태로 반환하는 함수다.
int GetOpPrec(char op) // 연산자의 연산 우선순위 정보 반환
{
switch(op)
{
case '*':
case '/':
return 5; // 가장 높은 연산의 우선순위
case '+':
case '-':
return 3; // 중간정도의 연산 우선순위
case'(':
return 1; // 가장 낮은 연산의 우선순위
}
return -1; // 등록되지 않은 연산자 알림
}반환 값이 클수록 우선순위가 높음을 의미한다.
(연산자의 우선순위가 가장 낮은 이유는 )연산자가 등장하기 전까지 쟁반 위에 남아있어야하기 때문에 다른 사칙 연산들보다 연산의 우선순위가 낮아야한다.
그리고 )연산자는 소괄호의 끝에 관한 메시지를 전달할 뿐이므로 메시지만 취하고 사라지기 때문에 연산의 우선순위가 부여되지 않았다.
연산의 우선순위를 매겼다면 GetOpPrec 함수의 호출결과를 바탕으로 두 연산자의 우선순위를 비교하여 그 결과를 반환하는 함수가 필요하다.
쟁반 위의 연산자를 어떻게 처리할지 결정하는 함수라고 할 수 있다.
그 함수의 정의는 다음과 같다.
int WhoPrecOp(char op1, char op2)
{
int op1Prec = GetOpPrec(op1);
int op2Prec = GetOpPrec(op2);
if(op1Prec > op2Prec) // op1의 연산 우선순위가 더 높을 경우
return 1;
else if(op1Prec < op2Prec) // op2의 연산 우선순위가 더 높을 경우
return -1;
else // op1과 op2의 연산 우선순위가 같은 경우
return 0;
}이제 마지막으로 후위 표기법으로 변환하는 함수인 ConvToRPNExp 함수를 정리해보자.
void ConvToRPNExp(char exp[])
{
Stack stack;
int expLen = strlen(exp);
char * convExp = (char*)malloc(expLen+1); // 변환된 수식을 담는 공간 마련
int i, idx = 0;
char tok, popOp;
memset(convExp, 0, sizeof(char)*expLen+1); // 할당된 배열을 0으로 초기화
StackInit(&stack);
for(i=0; i<expLen; i++)
{
tok = exp[i]; // exp로 전달된 수식을 한 문자씩 tok에 저장
if(isdigit(tok)) // tok에 저장된 문자가 숫자인지 확인
convExp[idx++] = tok; // 숫자일 경우 배열 convExp에 바로 저장
else // 숫자가 아닐 경우 (연산자일 경우)
{
switch(tok)
{
case '(': // 여는 소괄호일 경우
SPush(&stack, tok); // 스택(쟁반)에 놓기
break;
case ')': // 닫는 소괄호일 경우
while(1) // 반복해서 연산자 우선순위 판단
{
popOp = SPop(&stack); // 스택에서 연산자를 꺼내기
if(popOp == '(') // 연산자 '('를 만나면 반복 종료
break;
convExp[idx++] = popOp; // 배열 convExp에 연산자 저장
}
break;
case '+':
case '-':
case '*':
case '/':
while(!SIsEmpty(&stack) && WhoPrecOp(SPeek(&stack), tok) >= 0) // 스택이 비지 않았고 우선순위 확인 함수 확인시 0이상일 경우
convExp[idx++] = SPop(&stack);
SPush(&stack, tok);
break;
}
}
}
while(!SIsEmpty(&stack)) // 스택에 남아있는 모든 연산자들
convExp[idx++] = SPop(&stack); // 배열 convExp에 저장
strcpy(exp, convExp); // 변환된 수식 exp에 복사
free(convExp); // convExp 배열 소멸
}위에서 우선순위 확인 함수에서 반환하는 값이 0이상인 경우는 쟁반 위에 있는 연산자가 뒤이어 오는 연산자보다 우선순위가 높거나 같을 때다.
그리고 추가로 호출된 표준 함수가 두 가지 있었는데 이것의 의미는 다음과 같다.
void * memset(void * ptr, int val, size_t len);<헤더파일 ctype.h>
: ptr로 전달된 주소의 메모리서부터 len 바이트를 val의 값으로 채운다.
그래서 위 코드에서memset(convExp, 0, sizeof(char)*expLen+1);로 사용되었으며,
변환된 수식들을 저장하는 convExp란 배열을 0으로 초기화하여 하나 생성한 것으로 이해하면 된다.int isdigit(int ch);<헤더파일 string.h>
: ch로 전달된 문자의 내용이 10진수라면 1을 반환한다.
그래서 위 코드에서 if문 안에isdigit(tok)이란 조건으로 사용되었는데,
처음 주어진 배열에서 숫자와 연산자를 구별하는 조건으로 10진수 숫자일 경우 1을 반환하여 바로 convExp라는 변환된 수식 배열에 저장할 수 있게 한다.
중위 표기법을 후위 표기법으로 바꾸는 방법: 프로그램의 실행 (헤더파일, 소스파일, 실행파일)
이제 이 ConvToRPNExp 함수의 동작결과를 확인해볼 차례다.
함수의 선언은 InFixToPostfix.h 이란 헤더파일에, 함수의 정의는 InFixToPostfix.c란 소스파일에 저장한다.
그리고 실행파일인 InFixToPostfixMain.c에는 중위 표기법의 수식을 후위 표기법의 수식으로 변환하여 그 결과를 보여주는 main함수를 저장한다.
// InfixToPostfix.h
#ifndef __INFIX_TO_POSTFIX_H__
#define __INFIX_TO_POSTFIX_H__
// 중위 표기법 -> 후위 표기법 변환 함수 선언
void ConvToRPNExp(char exp[]);
#endif// InfixToPostfix.c
#include <string.h>
#include <stdlib.h>
#include <ctype.h>
#include "ListBaseStack.h"
// 연산자의 연산 우선순위 정보 반환
int GetOpPrec(char op)
{
switch(op)
{
case '*':
case '/':
return 5; // 가장 높은 연산의 우선순위
case '+':
case '-':
return 3; // 중간정도의 연산 우선순위
case'(':
return 1; // 가장 낮은 연산의 우선순위
}
return -1; // 등록되지 않은 연산자 알림
}
// 연산자의 연산 우선순위 비교 및 처리 함수
int WhoPrecOp(char op1, char op2)
{
int op1Prec = GetOpPrec(op1);
int op2Prec = GetOpPrec(op2);
if(op1Prec > op2Prec) // op1의 연산 우선순위가 더 높을 경우
return 1;
else if(op1Prec < op2Prec) // op2의 연산 우선순위가 더 높을 경우
return -1;
else // op1과 op2의 연산 우선순위가 같은 경우
return 0;
}
// 중위 표기법을 후위 표기법으로 변환
void ConvToRPNExp(char exp[])
{
Stack stack;
int expLen = strlen(exp);
char * convExp = (char*)malloc(expLen+1); // 변환된 수식을 담는 공간 마련
int i, idx = 0;
char tok, popOp;
memset(convExp, 0, sizeof(char)*expLen+1); // 할당된 배열을 0으로 초기화
StackInit(&stack);
for(i=0; i<expLen; i++)
{
tok = exp[i]; // exp로 전달된 수식을 한 문자씩 tok에 저장
if(isdigit(tok)) // tok에 저장된 문자가 숫자인지 확인
convExp[idx++] = tok; // 숫자일 경우 배열 convExp에 바로 저장
else // 숫자가 아닐 경우 (연산자일 경우)
{
switch(tok)
{
case '(': // 여는 소괄호일 경우
SPush(&stack, tok); // 스택(쟁반)에 놓기
break;
case ')': // 닫는 소괄호일 경우
while(1) // 반복해서 연산자 우선순위 판단
{
popOp = SPop(&stack); // 스택에서 연산자를 꺼내기
if(popOp == '(') // 연산자 '('를 만나면 반복 종료
break;
convExp[idx++] = popOp; // 배열 convExp에 연산자 저장
}
break;
case '+':
case '-':
case '*':
case '/':
while(!SIsEmpty(&stack) && WhoPrecOp(SPeek(&stack), tok) >= 0)
// 스택이 비지 않았고 우선순위 확인 함수 확인시 0이상일 경우
convExp[idx++] = SPop(&stack);
SPush(&stack, tok);
break;
}
}
}
while(!SIsEmpty(&stack)) // 스택에 남아있는 모든 연산자들
convExp[idx++] = SPop(&stack); // 배열 convExp에 저장
strcpy(exp, convExp); // 변환된 수식 exp에 복사
free(convExp); // convExp 배열 소멸
}// InfixToPostfixMain.c
#include <stdio.h>
#include "InfixToPostfix.h"
int main()
{
char exp1[] = "1+2*3";
char exp2[] = "(1+2)*3";
char exp3[] = "((1-2)+3)*(5-2)";
printf("<Infix Notation(Origin)>\n");
printf("%s", exp1);
printf("%s", exp2);
printf("%s", exp3);
ConvToRPNExp(exp1);
ConvToRPNExp(exp2);
ConvToRPNExp(exp3);
printf("<Postfix Notation(Fix)>\n");
printf("%s \n", exp1);
printf("%s \n", exp2);
printf("%s \n", exp3);
return 0;
}
> gcc .\InfixToPostfix.c .\L istBaseStack.c .\InfixToPostfixMain.c
> .\a.exe
> 출력
<Infix Notation(Origin)>
1+2*3
(1+2)*3
((1-2)+3)*(5-2)
<Postfix Notation(Fix)>
123*+
12+3*
12-3+52-*참고로 쟁반을 연결리스트 기반의 스택을 사용할 것이기 때문에 이 세 파일과 이전에 작성한 ListBaseStack.h과 ListBaseStack.c 파일을 함께 둬야한다.
후위 표기법으로 표현된 수식의 계산 방법
이제 계산기 구현에서 마지막 단계인 변환된 후위 표기법의 수식을 계산하여 그 결과를 얻는 것이다.
이 과정을 구현하려면 먼저 후위 표기법의 수식을 계산하는 방법에 대해 알아야한다.
3 + 2 * 4라는 중위 표기법 수식을 후위 표기법 수식으로 변경하면 3 2 4 * +와 같다.
후위 표기법에서는 먼저 연산되어야 하는 연산자가 수식의 앞쪽에 배치된다.
따라서 곱셈(*)이 우선 진행되고 이후 덧셈(+)이 진행된다.
그렇다면 곱셈의 피연산자는 무엇일까?
후위 표기법의 수식에서는 연산자의 앞에 등장하는 두 개의 숫자가 피연산자다.
따라서 2와 4가 곱셈의 피연산자가 된다.
곱셈 이후의 표기법을 3 8 +이 되고 덧셈의 피연산자는 덧셈 연산자 앞 두개가 된다.
따라서 결과는 11이 된다.
다른 예를 하나 더 생각해보자.
( 1 * 2 + 3 ) / 4라는 중위 표기법 수식이 있고 이를 후위 표기법으로 바꾸면 1 2 * 3 + 4 /가 된다.
곱셈 연산자가 가장 앞에 있고 그 앞에는 피연산자 1과 2가 있기 때문에 첫 연산자의 결과는 2 3 + 4 /가 된다.
그 다음 연산자는 덧셈이고 피연산자 2와 3이 앞에 있으므로 두 번째 연산자의 결과는 5 4 /가 된다.
마지막으로 5를 4로 나누는 연산이 진행되고 마무리 된다.
후위 표기법 수식 계산 구현 1: 프로그램의 구현
프로그램으로 구현하기 위한 기본 원칙이 세 가지 있다.
- 피연산자는 무조건 스택으로 옮긴다.
- 연산자를 만나면 스택에서 두 개의 피연산자를 꺼내서 계산을 한다.
- 계산 결과는 다시 스택에 넣는다.
이 기본 원칙을 적용해서 3 2 4 * +라는 수식 계산을 예시로 이해해보자.
3, 2, 4 모두 피연산자이므로 하나씩 스택으로 쌓는다.

이어서 *연산자를 처리해야한다.
따라서 스택에서 두 개의 피연산자를 꺼내 연산을 진행한다.
여기서 주목할 점은 진행되는 연산이 4 * 2가 아닌 2 * 4로 되어야한다는 점이다.
곱셈이나 덧셈은 피연산자의 위치가 바껴도 상관 없지만 뺄셈과 나눗셈은 값이 달라지기 때문에 연산의 순서는 중요하다.
스택에서 먼저 꺼낸 피연산자가 연산자의 오른쪽(두번째)로 오고 나중에 꺼낸 피연산자가 연산자의 왼쪽(첫번째)로 와야한다.
따라서 그 연산의 결과가 다시 스택으로 들어가게 된다.

이제 마지막 남은 덧셈 연산의 진행을 위해 스택에 남은 두 개의 피연산자 모두 꺼내어 덧셈을 진행하고 그 결과로 11을 얻게 된다.
이 내용을 바탕으로 함수를 정의해보자.
int EvalPRNExp(char exp[]) // 후위 표기법의 수식을 계산하여 그 결과를 반환
{
....
}이 함수는 후위 표기법의 수식을 담고 있는 문자열의 주소 값을 인자로 전달받는다.
그리고 그 수식의 계산결과를 반환한다.
이제 함수의 정의 내용을 채워보자...!
int EvalRPNExp(char exp[])
{
Stack stack;
int expLen = strlen(exp);
int i;
char tok, op1, op2;
StackInit(&stack);
for(i=0; i<expLen; i++) // 수식을 구성하는 문자 각각을 대상으로 반복
{
tok = exp[i]; // 한 문자씩 tok에 저장해서
if(isdigit(tok)) // 문자의 내용이 연산자인지 피연산자인지 확인
SPush(&stack, tok - '0'); // 피연산자(정수)일 경우 숫자로 변환 후 스택에 Push
else // 연산자일 경우
{
op2 = SPop(&stack); // 스택에서 두 번째 피연산자 꺼내기.
op1 = SPop(&stack); // 스택에서 첫 번째 피연산자 꺼내기.
switch(tok) // 연산하고 그 결과를 다시 스택에 Push
{
case '+':
SPush(&stack, op1+op2);
break;
case '-':
SPush(&stack, op1-op2);
break;
case '*':
SPush(&stack, op1*op2);
break;
case '/':
SPush(&stack, op1/op2);
break;
}
}
}
return SPop(&stack); // 마지막 연산결과 스택에서 꺼내어 반환
}후위 표기법 수식 계산 구현 2: 프로그램의 실행
위에서 정의한 EvalRPNExp 함수의 실행 결과를 확인해볼 차례다.
헤더파일(PostCalculator.h)과 소스파일(PostCalculator.c), 실행파일(PostCalculatorMain.c)을 정리하면 아래와 같다.
이번에도 스택을 사용하기 때문에 스택과 관련된 ListBaseStack.h과 ListBaseStack.c 파일을 함께 둬야한다.
// PostCalculator.h
#ifndef __POST_CALCULATOR_H__
#define __POST_CALCULATOR_H__
int EvalRPNExp(char exp[]);
#endif// PostCalculator.c
#include <string.h>
#include <ctype.h>
#include "ListBaseStack.h"
int EvalRPNExp(char exp[])
{
Stack stack;
int expLen = strlen(exp);
int i;
char tok, op1, op2;
StackInit(&stack);
for(i=0; i<expLen; i++) // 수식을 구성하는 문자 각각을 대상으로 반복
{
tok = exp[i]; // 한 문자씩 tok에 저장해서
if(isdigit(tok)) // 문자의 내용이 연산자인지 피연산자인지 확인
SPush(&stack, tok - '0'); // 피연산자(정수)일 경우 숫자로 변환 후 스택에 Push
else // 연산자일 경우
{
op2 = SPop(&stack); // 스택에서 두 번째 피연산자 꺼내기.
op1 = SPop(&stack); // 스택에서 첫 번째 피연산자 꺼내기.
switch(tok) // 연산하고 그 결과를 다시 스택에 Push
{
case '+':
SPush(&stack, op1+op2);
break;
case '-':
SPush(&stack, op1-op2);
break;
case '*':
SPush(&stack, op1*op2);
break;
case '/':
SPush(&stack, op1/op2);
break;
}
}
}
return SPop(&stack); // 마지막 연산결과 스택에서 꺼내어 반환
}// PostCalculatorMain.c
#include <stdio.h>
#include "PostCalculator.h"
int main()
{
char postExp1[] = "42*8+";
char postExp2[] = "123+*4/";
printf("<Postfix Calculation>\n");
printf("%s = %d \n", postExp1, EvalRPNExp(postExp1));
printf("%s = %d \n", postExp2, EvalRPNExp(postExp2));
return 0;
}
> gcc .\ListBaseStack.c .\PostCalculator.c .\PostCalculatorMain.c
> .\a.exe
> 출력
<Postfix Calculation>
42*8+ = 16
123+*4/ = 1여기서는 후위 표기법의 수식을 입력 받아서 이를 계산하여 결과를 출력하는 과정만 보여주고 있다.
우리가 생각하는 계산기를 만들려면 중위 표기법으로 수식을 입력해서 이것을 후위 표기법으로 저장하고 계산된 값이 도출되어야하기 때문에 이 모든 함수를 정리할 필요가 있다.
계산기 프로그램 최종 정리하기
중위 표기법의 수식을 후위 표기법의 수식으로 변환하는 함수도 정의하였고,
후위 표기법의 수식을 계산하는 함수도 정의했다.
프로그램 사용자로부터 소괄호를 포함하는 중위 표기법의 수식을 입력 받아서 그 결과를 출력하는 프로그램, 즉 계산기를 최종 정리해서 구현해보자.
그 과정을 간략하게 표현하면 중위 표기법 수식 → ConvToRPNExp → EvalRPNExp → 연산결과가 출력하게 된다.
이 과정을 EvalInfixExp라는 함수로 정리할 것이고 이 함수의 선언, 정의, 실행 파일은 다음과 같이 정리할 수 있다.
// InfixCalculator.h
#ifndef __INFIX_CALCULATOR_H__
#define __INFIX_CALCULATOR_H__
int EvalInfixExp(char exp[]);
#endif// InfixCalculator.c
#include <string.h>
#include <stdlib.h>
#include "InfixToPostfix.h" // ConvToRPNExp 함수
#include "PostCalculator.h" // EvalRPNExp 함수
int EvalInfixExp(char exp[])
{
int len = strlen(exp);
int ret;
char * expcpy = (char *)malloc(len + 1); // 문자열 저장공간 마련
strcpy(expcpy, exp); // exp를 expcpy에 복사
ConvToRPNExp(expcpy); // 후위 표기법의 수식으로 변환
ret = EvalRPNExp(expcpy); // 변환된 수식 계산
free(expcpy); // 문자열 저장공간 해제
return ret; // 계산 결과 반환
}// InfixCalculatorMain.c
#include <stdio.h>
#include "InfixCalculator.h"
int main()
{
char exp1[] = "1+2*3";
char exp2[] = "(1+2)*3";
char exp3[] = "((1-2)+3)*(5-2)";
printf("<Calculator>\n");
printf("1: %s = %d\n", exp1, EvalInfixExp(exp1));
printf("2: %s = %d\n", exp2, EvalInfixExp(exp2));
printf("3: %s = %d\n", exp3, EvalInfixExp(exp3));
return 0;
}
> gcc .\InfixCalculator.c .\InfixToPostfix.c .\ListBaseStack.c .\PostCalculator.c .\InfixCalculatorMain.c
> .\a.exe
> 출력
<Calculator>
1: 1+2*3 = 7
2: (1+2)*3 = 9
3: ((1-2)+3)*(5-2) = 6마지막으로 계산기 프로그램 실행에 필요한 헤더파일, 소스파일들을 정리하면 다음과 같다.
- 스택의 활용: ListBaseStack.h, ListBaseStack.c
- 후위 표기법의 수식으로 변환: InfixToPostfix.h, InfixToPostfix.c
- 후위 표기법의 수식을 계산: PostCalculator.h, PostCalculator.c
- 중위 표기법의 수식을 계산: InfixCalculator.h, InfixCalculator.c
- main 함수: InfixCalculatorMain.c
<Review>
길고 길었던 스택 공부가 끝이 났다.
연결리스트에 비해 이해하는데 쉬웠지만
계산기 프로그램 구현에서 헤더파일과 소스파일이 많아지니 헷갈렸다...
궁금한 점은 왜 InfixCalculator에서는 기존에 사용한 ListBaseStack 헤더파일을 불러오지 않아도 작동하는지 (이 전 PostCalculator나 InfixToPost 헤더파일에서 불러져서 그런건지)
이런 점에 대해서 설명이 더 있었으면 좋았겠다란 생각이 있었다. (있었는데 내가 못 본걸수도!)
아무튼 오늘도 공부 완!

