0. 들어가며
안녕하세요! 경기대학교 AI 컴퓨터공학부의 과 동아리 C-Lab의 CoreTeam 서버챕터 팀원 전민주입니다. 게시글에 감정 표현하는 대표적인 방법에는 “좋아요” 기능이 있습니다. 코어팀에서도 게시글과 댓글에 ‘좋아요’를 등록/취소할 수 있는 API와 총 ‘좋아요’ 개수를 반환하도록 코드를 작성했었는데요.
6월 정기회의에서 감정표현 관련 부분을 더욱 확장시키는 방향으로 기획했습니다. “좋아요”뿐만 아니라 다양한 이모지를 활용해 게시글에 감정표현을 하는 것으로 결정했습니다.
벤치마킹은 깃허브 감정표현입니다. 아래처럼 다양한 이모지를 제공하고 클릭 시 카운팅이 되는 방식입니다.
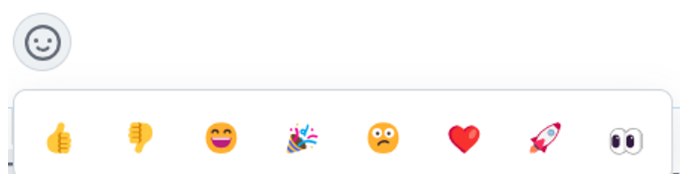
이번 작업의 핵심은 2가지입니다.
첫째, DB 조회 최적화 입니다. 약 50명의 사용자가 게시글 50개에 이모지를 5개씩 클릭한다고 하면 레코드가 총 50505 = 12,500개입니다. 점점 불어날 레코드를 어떻게 하면 효율적으로 조회할지, 이모지 취소 동작으로 인한 레코드 삭제를 어떻게 관리할지가 관건입니다.
둘째, 이모지 판별입니다. 회의 결과, 확장성을 고려하여 매번 Enum으로 이모지 리스트를 관리하는 것보다는 이모지라고 판단할 수 있는 유니코드를 허용하도록 했습니다.
1, 2 단락에서 전체적인 개발 과정과 코드들을 살펴보고 3, 4 단락에서 DB 최적화 방법을, 5 단락에서 이모지 판별을 소개해 드리갰습니다!
1. 게시글에 이모지 클릭/취소 API
먼저, 게시글에 이모지를 클릭하고, 취소하는 API를 작성해야 합니다. 게시글 이모지 작업을 함께 해주시는 프론트엔드 관식님과 의논해서 다음과 같이 API를 작성했습니다.
@PostMapping("/{boardId}/react/{emoji}")
@Operation(summary = "[U] 커뮤니티 게시글 이모지 누르기/취소하기", description = "ROLE_USER 이상의 권한이 필요함")
@Secured({"ROLE_USER", "ROLE_ADMIN", "ROLE_SUPER"})
public ApiResponse<String> toggleEmojiStatus(
@PathVariable(name = "boardId") Long boardId,
@PathVariable(name = "emoji") String emojiUniCode
) {
String id = boardService.toggleEmojiStatus(boardId, emojiUniCode);
return ApiResponse.success(id);
}하나의 API에서 이모지 등록과 취소가 가능하도록 상태 반전 로직을 만들었습니다. Service 단에서 중요한 점은 DB에 게시글에, 로그인한 사용자가, 특정 이모지를 선택하거나 취소한 기록이 있다면 isDeleted 칼럼을 반전시켜주었습니다.
코드 스타일 부분에서 한 가지 배운 점이 있었는데요. 처음에는 Optinal<BoardEmoji>로 이모지 선택/취소 기록을 조회하고 .isPresent() 를 통해 if문을 사용해서 코드를 분리해 줬습니다. 이 부분에서 람다식을 사용하면 더 깔끔하다는 피드백을 받아 수정해 아래와 같이 마무리했습니다.
@Transactional
public String toggleEmojiStatus(Long boardId, String emoji) {
if (!EmojiUtils.isEmoji(emoji)) {
throw new InvalidEmojiException("지원하지 않는 이모지입니다.");
}
MemberDetailedInfoDto currentMemberInfo = memberLookupService.getCurrentMemberDetailedInfo();
String memberId = currentMemberInfo.getMemberId();
Board board = getBoardByIdOrThrow(boardId);
BoardEmoji boardEmoji = boardEmojiRepository.findByBoardIdAndMemberIdAndEmoji(boardId, memberId, emoji)
.map(existingEmoji -> {
existingEmoji.toggleIsDeletedStatus();
return existingEmoji;
})
.orElseGet(() -> BoardEmoji.create(memberId, boardId, emoji));
boardEmojiRepository.save(boardEmoji);
return board.getCategory().getKey();
}
/* 수정하기 전 Optional로 표현한 코드
Optional<BoardEmoji> boardEmojiOpt = boardEmojiRepository.findByBoardIdAndMemberIdAndEmoji(boardId, memberId, emoji);
BoardEmoji boardEmoji;
if (boardEmojiOpt.isPresent()) {
boardEmoji = boardEmojiOpt.get();
boardEmoji.toggleIsDeletedStatus();
} else {
boardEmoji = BoardEmoji.create(memberId, boardId, emoji);
}
*/2. 게시글에 달린 이모지 정보 조회하기
게시글 id로 조회하면 해당 게시글에 달린 이모지 정보를 조회하는 메소드를 만들어서 게시글 상세 조회 API에서 함께 반환되게 해주었습니다.
이 부분에서 API 작성 관련해서 배운 점이 있었습니다. 저는 API를 분리해서 작성하는 것이 좋다고 생각했었습니다. 게시글 상세 조회 API 따로, 이모지 정보조회 API 따로 이렇게 말이죠. 그러나 이 방식은 프론트 입장에서 여러 API를 호출해야 하므로 불편했습니다. 따라서 하나의 API로 처리할 수 있는 내용이라면 묶어주도록 했습니다.
@Transactional(readOnly = true)
public BoardDetailsResponseDto getBoardDetails(Long boardId) {
MemberDetailedInfoDto currentMemberInfo = memberLookupService.getCurrentMemberDetailedInfo();
Board board = getBoardByIdOrThrow(boardId);
boolean isOwner = board.isOwner(currentMemberInfo.getMemberId());
List<BoardEmojiCountResponseDto> boardEmojiCountResponseDtoList = getBoardEmojiCountResponseDtoList(boardId, currentMemberInfo.getMemberId());
return BoardDetailsResponseDto.toDto(board, currentMemberInfo, isOwner, boardEmojiCountResponseDtoList);
}
@Transactional(readOnly = true)
public List<BoardEmojiCountResponseDto> getBoardEmojiCountResponseDtoList(Long boardId, String memberId) {
List<Tuple> results = boardEmojiRepository.findEmojiClickCountsByBoardId(boardId, memberId);
return convertToDtoList(results);
}특히, boardEmojiRepository.findEmojiClickCountsByBoardId() 의 경우는 List을 반환하는 쿼리문을 만들어서 조회를 했습니다. 이 쿼리문을 작성할 때 아래와 같이 3가지 조회 방법을 생각했었는데요.
- List를 반환 (타입을 명시적으로 지정해주어야 함)
- List를 반환 (emoji-boardId 인덱싱의 효과를 볼 수 없음. boardId인덱싱으로 수정해야 함.)
- List (계층 분리가 안 됨)
처음에는 3번 방법을 선택하였지만, 도메인 주도 설계에서 응용 계층과 도메인 계층의 경계를 무너뜨리는 코드라는 피드백을 받아 1번 방법으로 수정했습니다.
@Query("SELECT b.emoji as emoji, COUNT(b) as count, " +
"CASE WHEN SUM(CASE WHEN b.memberId = :memberId THEN 1 ELSE 0 END) > 0 THEN true ELSE false END as isClicked " +
"FROM BoardEmoji b " +
"WHERE b.boardId = :boardId " +
"GROUP BY b.emoji")
List<Tuple> findEmojiClickCountsByBoardId(@Param("boardId") Long boardId, @Param("memberId") String memberId);
/* 3번 방법
@Query("SELECT new page.clab.api.domain.board.dto.response.BoardEmojiCountResponseDto(b.emoji, COUNT(b), " +
"CASE WHEN SUM(CASE WHEN b.memberId = :memberId THEN 1 ELSE 0 END) > 0 THEN true ELSE false END) " +
"FROM BoardEmoji b " +
"WHERE b.boardId = :boardId " +
"GROUP BY b.emoji")
List<BoardEmojiCountResponseDto> findEmojiClickCountsByBoardId(@Param("boardId") Long boardId, @Param("memberId") String memberId);
*/1번 방법을 선택하면서 List → List 변환 작업이 필요해서 아래와 같이 타입 명시를 위한 메소드를 작성했습니다.
private List<BoardEmojiCountResponseDto> convertToDtoList(List<Tuple> results) {
return results.stream()
.map(result -> new BoardEmojiCountResponseDto(
result.get("emoji", String.class),
result.get("count", Long.class),
result.get("isClicked", Boolean.class)))
.collect(Collectors.toList());
}지금까지 전체적인 개발을 소개해드렸고, 이제부터는 DB 최적화에 대해 고민한 점을 구체적으로 설명해드리겠습니다.
3. 인덱싱 사용하기
인덱싱 기법은 데이터를 빠르게 검색하고 쿼리 성능을 향상하기 위해 사용됩니다. 테이블에서 한두 개 이상의 열을 포함하는 데이터 구조로 이루어져 있습니다.
인덱스가 없는 경우에는 테이블의 모든 레코드를 순차적으로 확인하면서 원하는 데이터를 찾습니다. 따라서 스캔해야 하는 레코드가 많을수록 검색 속도가 느려집니다.
그렇다면 인덱싱은 어떻게 작동하길래 빠른 조회가 가능하다고 하는 것일까요?
- 인덱스를 통해 데이터를 정렬한다.
제가 사용한 B-트리 인덱스의 경우는 데이터를 트리 구조로 정렬하여 저장합니다. 따라서 레코드를 순서대로 탐색하지 않고 정렬된 구조를 바탕으로 이진 탐색 등의 알고리즘을 사용합니다. 자연스럽게 검색 시간이 크게 단축될 수 있습니다.
- 읽어야 하는 데이터 블록의 수가 줄어든다.
검색 작업을 수행할 때 디스크에서 읽는 작업이 필요한데, 인덱스를 사용하면 읽어야 하는 데이터 블록의 수가 줄어듭니다. 인덱스는 데이터가 저장된 위치를 직접 가리키기 때문에 모든 레코드를 읽는 대신 필요한 데이터 블록만 가져올 수 있습니다.
- 작은 데이터 구조로 메모리 효율/캐시 사용에 유리하다.
인덱싱을 사용하면 테이블을 조회하기 전에 인덱스를 먼저 검색합니다. 인덱스는 테이블보다 더 작은 자료구조이기 때문에, 메모리에 효율적으로 적재되고, 캐시를 활용해 검색 성능을 더욱 향상할 수 있습니다.
이번 작업에서는 가장 대표적인 B-Tree 인덱싱을 사용해 보았습니다.
게시글에 대한 이모지 정보를 파악하기 위해 두 가지 메소드를 BoardEmojiRepository에 작성했는데요.
@Query(value = "SELECT b.* FROM board_emoji b WHERE b.board_id = :boardId AND b.member_id = :memberId AND b.emoji = :emoji", nativeQuery = true)
Optional<BoardEmoji> findByBoardIdAndMemberIdAndEmoji(@Param("boardId") Long boardId, @Param("memberId") String memberId, @Param("emoji") String emoji);
@Query("SELECT b.emoji as emoji, COUNT(b) as count, " +
"CASE WHEN SUM(CASE WHEN b.memberId = :memberId THEN 1 ELSE 0 END) > 0 THEN true ELSE false END as isClicked " +
"FROM BoardEmoji b " +
"WHERE b.boardId = :boardId " +
"GROUP BY b.emoji")
List<Tuple> findEmojiClickCountsByBoardId(@Param("boardId") Long boardId, @Param("memberId") String memberId);이때 아래와 같이 인덱싱을 설정해서 빠르게 조회를 할 수 있도록 했습니다.
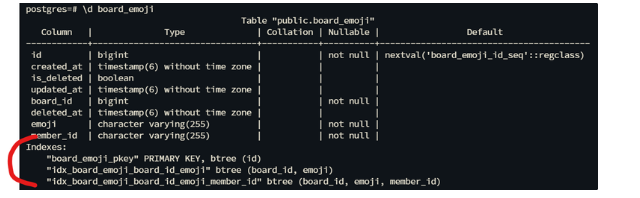
@Table(name = "board_emoji", indexes = {
@Index(name = "idx_board_emoji_board_id_emoji", columnList = "board_id, emoji"),
@Index(name = "idx_board_emoji_board_id_emoji_member_id", columnList = "board_id, emoji, member_id")
})실제로 btree 방식을 사용한 인덱싱이 테이블에 적용됨을 확인할 수 있었습니다.
4. 소프트 딜리트와 하드 딜리트의 혼용
소프트 딜리트는 데이터를 실제로 테이블에서 삭제하지 않고 삭제된 것처럼 표시합니다. isDeleted 칼럼을 두어서 삭제됐는지 상태를 확인합니다. 복구나 추적이 필요한 데이터에 많이 사용합니다.
하드 딜리트는 데이터를 실제로 테이블에서 제거합니다. 다시 복구가 불가능합니다. 필요 없는 데이터를 삭제하기 때문에 저장공간을 확보할 수 있습니다.
clab.page의 삭제된 데이터는 소프트 딜리트를 통해 사용자에게는 보이지 않지만, 관리자가 확인하여 동아리 정책을 위반하는 행동을 관리하고 있습니다.
BoardEmoji의 경우에는 소프트 딜리트의 취지인 복원과 관리가 필요한 데이터가 아니라고 생각했습니다. 그래서 복원보다는 DB 성능에 의미를 두어 소프트 딜리트를 활용해 보았습니다.
람다식으로 표현한 이 코드에서 게시글-사용자-이모지 데이터가 존재한다면 isDeleted를 반전시켜 주는데요. toggleIsDeletedStatus()를 통해 반전시켜 줄 때마다 deletedAt의 정보를 초기화하거나 다시 세팅하는 로직을 담고 있습니다.
BoardEmoji boardEmoji = boardEmojiRepository.findByBoardIdAndMemberIdAndEmoji(boardId, memberId, emoji)
.map(existingEmoji -> {
existingEmoji.toggleIsDeletedStatus();
return existingEmoji;
})
.orElseGet(() -> BoardEmoji.create(memberId, boardId, emoji));
public void toggleIsDeletedStatus() {
this.isDeleted = !this.isDeleted;
this.deletedAt = this.isDeleted ? LocalDateTime.now() : null;
}사용자가 게시글을 확인하고 초반에 이모지를 누르는 시기에는 여러 개의 이모지를 클릭하고 취소하는 동작을 할 것이라고 예상했습니다.
isDeleted와 DeletedAt 칼럼은 인덱싱에 포함되지 않고 있고, memberId, boardId, emoji에 인덱싱이 되어 있습니다.
따라서 소프트 딜리트를 사용할 경우 isDeleted와 DeletedAt 칼럼의 UPDATE문이 실행될 것이고, 하드 딜리트를 사용할 경우 memberId, boardId, emoji에 추가 인덱스 INSERT와 DELETE문이 필요한 것을 고려했을 때, 소프트 딜리트를 사용하면 시간이 덜 드는 UPDATE문으로 데이터를 수정할 수 있다고 판단했습니다.
이렇게 되면 isDeleted = true인 레코드가 점점 쌓이게 되어 DB 용량이 부족할 수 있을 것입니다. 따라서 스케쥴링으로 DeletedAt과 현재 날짜를 비교해 7일 이상 지난 레코드는 하드 딜리트로 삭제할 수 있도록 했습니다.
// BoardEmojiService
@Scheduled(cron = "0 0 0 * * ?")
public void cleanUpOldSoftDeletedRecords() {
LocalDateTime cutoffDate = LocalDateTime.now().minusDays(7);
boardEmojiRepository.deleteOldSoftDeletedRecords(cutoffDate);
}
// BoardEmojiRepository
@Transactional
@Modifying
@Query(value = "DELETE FROM board_emoji b WHERE b.is_deleted = true AND b.deleted_at < :cutoffDate", nativeQuery = true)
void deleteOldSoftDeletedRecords(LocalDateTime cutoffDate);
5. 이모지 판별
이번 작업에서 흥미로웠던 부분이 바로 이모지 판별입니다. 제가 생각한 방법은 프론트에서 게시글 감정표현에 사용될 이모지들을 백엔드에서 Enum으로 저장하고, 그 이외의 유니코드가 입력되면 요청을 거부하는 방식이었습니다.
이 방법은 매번 프론트에서 이모지 리스트를 수정하면 백엔드에서도 같이 Enum을 수정해주어야 합니다. 따라서 숫자, 일반 String이 아닌 이모지를 판별할 수 있는 로직이 필요했습니다.
그 전에 이모지가 어떻게 구성되어 있는지 알아야 합니다.
저는 이모지별로 유니코드가 각각 다르게 할당된 줄 알았습니다. 따라서 유니코드를 보고 이모지인지 아닌지 판별해 주는 라이브러리를 찾아보면 쉽게 판단할 수 있지 않을까? 라고 생각했습니다.
그러나 단일 이모지 여러 개와 이들을 연결해 주는 유니코드 등이 합쳐지는 방식으로 아래와 같이 복합 이모지라는 개념이 존재했습니다.
👨👩👧👦 (U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F466)
따라서 입력을 받고 유니코드를 분석해서 이모지인지를 판단해야 합니다.
아래의 코드를 이해하기 위해서 몇 가지 사전 개념이 필요합니다.
코드 포인트
유니코드 코드 포인트는 유니코드 표준에서 각 문자를 고유하게 식별하는 정수 값입니다. 유니코드에서 문자는 0x0000부터 0x10FFFF까지의 범위에서 고유한 번호를 가집니다.
코드 포인트는 단일 문자, 숫자, 기호 등을 나타내며, 여러 코드 포인트가 조합되어 복합 문자를 형성할 수 있습니다.
그래프 임 클러스터(Grapheme Cluster)
그래프 임은 텍스트에서 인간이 인식할 수 있는 최소의 글자 단위입니다. 이는 문자 하나, 여러 문자의 조합, 또는 결합 문자 등을 포함할 수 있습니다. 그래프 임 클러스터는 이러한 글자 단위가 결합된 형태를 말합니다.
단일 그래프 임 클러스터 (Single Grapheme Cluster)
단일 그래프 임 클러스터는 하나의 그래프 임으로 인식되는 문자 단위입니다. 이는 하나의 코드 포인트로 구성될 수도 있고, 결합된 여러 코드 포인트로 구성될 수도 있습니다. 단일 그래프 임 클러스터는 사용자에게 하나의 문자처럼 보입니다.
이제 이모지인지 판별하는 메소드를 어떻게 만들었는지 소개해드리겠습니다.
BreakIterator.getCharacterInstance()를 사용해 String을 grapheme cluster로 분할할 준비를 합니다.it.setText()로 이모지로 추정되는 text를 입력으로 설정합니다.if (end != BreakIterator.DONE && it.next() == BreakIterator.DONE)를 통해서 text에 최소 하나의 문자가 있고, 단일 grapheme cluster로 구성됨을 확인합니다.
→ 특히 복합 grapheme cluster를 허용한다면 이모지가 앞에 나오는 경우 뒤쪽에 다른 문자열이 있어도 이모지로 판단합니다.
if (grapheme.length() == 1 && UCharacter.isDigit(grapheme.codePointAt(0)))를 통해 단일 숫자인 경우에 즉 1, 123 등의 숫자이면 이모지가 아니기 때문에 false를 반환합니다.
→ 이 코드가 없는 경우에는 1️⃣ 이모지가
- U+0031: DIGIT ONE (숫자 1)
- U+FE0F: VARIATION SELECTOR-16 (이모지 스타일)
- U+20E3: COMBINING ENCLOSING KEYCAP (키캡 섀도우)
위처럼 분석되기 때문에 for문을 돌면서 숫자 1이 U+0031 값을 가지기 때문에 이모지로 분류가 되는 문제가 발생했습니다.
- 마지막으로 for문을 돌면서 grapheme cluster의 각 코드 포인트를 확인합니다.
UCharacter.hasBinaryProperty() 를 통해서 코드 포인트가 특정 유니코드 속성을 가지고 있는지 확인합니다. 이모지 관련된 3가지 주요 유니코드 속성을 확인하고 있는데요.
UProperty.EMOJI
이 속성은 해당 코드 포인트가 이모지인지 여부를 나타냅니다. 유니코드 표준에서 이모지로 정의된 문자에 할당됩니다. 예를 들어, 웃는 얼굴, 동물, 음식, 활동 등 다양한 범주에 속하는 이모지가 포함됩니다.
- "😀" (U+1F600): SMILING FACE
- "🍕" (U+1F355): SLICE OF PIZZA
UProperty.EMOJI_PRESENTATION
이 속성은 해당 코드 포인트가 기본적으로 이모지 스타일로 표시되어야 하는지 여부를 나타냅니다. 일부 문자는 텍스트와 이모지 스타일 모두로 표시될 수 있으며, 이 속성은 기본적으로 이모지 스타일로 표시될 문자를 지정합니다.
- "🎉" (U+1F389): PARTY POPPER (기본적으로 이모지 스타일로 표시)
- "✈️" (U+2708 U+FE0F): AIRPLANE (기본적으로 이모지 스타일로 표시)
UProperty.EXTENDED_PICTOGRAPHIC
이 속성은 이모지로 확장될 수 있는 픽토그램(그림 문자)인지 여부를 나타냅니다. 이 속성은 복잡한 이모지 시퀀스를 포함하여 추가 그래픽 요소로 확장 가능한 문자를 지정합니다. 주로 사람, 동물, 물건 등의 그림 문자에 적용됩니다.
- "👩👩👦👦" (U+1F469 U+200D U+1F469 U+200D U+1F466 U+200D U+1F466): FAMILY: WOMAN, WOMAN, BOY, BOY
public static boolean isEmoji(String text) {
if (text == null || text.isEmpty()) {
return false;
}
BreakIterator it = BreakIterator.getCharacterInstance();
it.setText(text);
int start = it.first();
int end = it.next();
if (end != BreakIterator.DONE && it.next() == BreakIterator.DONE) {
String grapheme = text.substring(start, end);
if (grapheme.length() == 1 && UCharacter.isDigit(grapheme.codePointAt(0)))
return false;
for (int i = 0; i < grapheme.length();) {
int codePoint = grapheme.codePointAt(i);
if (UCharacter.hasBinaryProperty(codePoint, UProperty.EMOJI) ||
UCharacter.hasBinaryProperty(codePoint, UProperty.EMOJI_PRESENTATION) ||
UCharacter.hasBinaryProperty(codePoint, UProperty.EXTENDED_PICTOGRAPHIC)) {
return true;
}
i += Character.charCount(codePoint);
}
}
return false;
}6. 마무리 하며
이번 작업을 통해 DB 최적화의 인덱싱 기술과 이모지에 대해 자세히 공부해 볼 수 있었습니다..
DB 최적화의 경우는 데이터가 많이 쌓이면 인덱싱만으로는 빠른 응답이 안 될 것 같아 추가적인 방안을 찾고, 더 발전시켜 볼 예정입니다.
오히려 이모지에 대해서 깊이 있게 분석하고 판별 로직을 세워볼 수 있는 시간이라 흥미로웠습니다. 코드 리뷰 및 많은 생각을 할 수 있게 이끌어주신 팀원분들과 함께여서 더욱 의미 있었습니다.
7. 참고자료
https://velog.io/@shjung53/Unicoode와-Grapheme-Cluster
