Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors
Paper_review
단어를 vector로 표현하는 방식(embedding)에서 count-base와 predict-base 모델의 성능을 비교하는 논문입니다.
[Abstract]
Context-predicting model(embedding 혹은 neural language model)은 distributional semantic 분야에서 새롭게 주목받고 있습니다. 관련해서 많은 이야기들이 있지만, predictive model과 전통적인 count-vector-based distributional semantic 방법을 체계적으로 비교한 자료는 부족합니다. 해당 논문에서는 둘 사이의 체계적 비교를 수행하고, 결과적으로 context-predicting model이 count-based model보다 견고하고 완벽한 성능을 보이는 것을 보여줍니다.
1. Introduction
Computational linguistic 분야에서는 의미적으로 유사한 단어는 유사한 분포를 갖기 때문에, contextual information이 단어 의미의 좋은 근사라는 것을 보여왔습니다. DSMs(Distributional Semantic Models)은 단어가 등장하는 문맥을 유지하면서 의미를 표현하기 위한 대용으로 vector를 사용하였고, 단어 사이의 의미 유사도를 측정하기 위하여 기하학적인 기술을 적용하였습니다.
수십년에 걸쳐, 단순한 co-occurrence counts는 잘 맞지 않다는 것이 밝혀졌고, DSMs는 raw vector들에 다양한 변환을 적용했을 때 좋은 성능을 보였습니다.
최근 몇 년 사이에 DSMs의 새로운 세대를 만들어가는 발전이 보이기 시작했습니다. 이런 발전은 vector estimation 문제를 word vector의 가중치를 단어가 등장하는 문맥의 확률을 최대화 시키는 supervised task로 바꾸면서 생겼습니다.
Context vector를 수집하는 대신, 다양한 기준에 맞추어 vector들의 가중치를 재조정하여 vector의 단어가 등장할 수 있는 문맥을 적절하게 예측할 수 있도록합니다.
DSMs을 학습하는 새로운 방식은 단순하고 잘 정의된 supervised leargning step으로 과거의 heuristic stacking of vector transform을 대체할 수 있기에 매력적이었습니다. 또한 학습에 context window를 활용하면 annotation 비용도 들지 않았습니다. 더 나아가 input data의 양이 매우 커지더라고 효율적으로 scale up을 할 수도 있게 되었습니다.
전통적인 방식으로 설계된 DSMs를 vector를 co-occurrence counts로 초기화 하기 때문에 count model이라 부르고, 학습 기반의 방식을 predict model이라 부르겠습니다. 이제 주된 관심사는 그러면 두 방식 중에 어떠한 것이 좋은가? 입니다. 지금까지 발표된 많은 자료들에서도 count model과 predict model을 직접적으로 비교한 것은 거의 없습니다. context-predicting vector는 초기에 language modeling 그리고(혹은) neural-network-based 'deep learning' NLP 구조의 초기 vector로 활용하기 위해서 만들어졌기 때문에 semantic representation과 같은 효율성 측면은 주된 관심사가 아니었습니다.
해당 논문에서는 count model과 predict model의 체계적인 직접 비교를 통해서 직접 비교 결과가 없는 기존의 제한적인 상황을 해결하고자 합니다.
2. Distributional semantic models
- 2.8B tokens (ukWac + English Wikipedia + British National Corpus)
- 300K most top frequent words in the corpus
2.1 Count models
Count vector를 target 단어에 2~5 window를 적용하여 얻습니다.
2가지 weighting 방식(Positive Pointwise Mutual Information(PPMI), Local Mutual Information)을 활용하였습니다.
Full vector와 Compressed vector(SVD, Non-negative Matrix Factorization 적용)를 모두 활용하였습니다.
200,300,400,500 vector size
총 36개의 count model을 평가에 활용하였습니다.
2.2 Predict models
Word2Vec의 2가지 방법 중 문맥이 주어졌을 때 중심 단어를 맞추는 CBOW만 활용하였습니다.
CBOW가 계산 효율성이 높고, 큰 dataset에서도 적용이 잘 됩니다.
CBOW의 window size는 2~5를 적용하였고, 마찬가지로 200, 300, 400, 500 vector size를 활용했습니다.
Hierarchical softmax와 negative sampling(negative sample 수 = 5, 10)을 모두 활용했습니다.
학습에 활용되는 단어는 그들의 빈도에 따라서 확률적으로 버려지도록 하였습니다.
총 48개의 predict model을 평가에 활용했습니다.
2.3 Out-of-the-box models
Barnoi and Lenci(2010) 논문에서는 Distributional Memory(dm) model로 vector를 만들어 좋은 성능을 보였습니다. dm model은 count-based DSM에 linguistically rich 최대화를 raw 단어 대신 lemma에 집중하고, target과 context를 연결하는 lexico-syntatic pattern과 syntactic relation을 encode를 통해 이루었습니다.
Ronan Collobert의 Collobert and Weston(cw) vector 역시 사용했습니다.
3. Evaluation materials
Semantic relatedness
두 단어 사이의 유사성과 연관성을 수치로 표현하는 task입니다.
Synonym detection
4개의 동의어 후보가 있는 80개의 다지선다 문제의 정답을 맞추는 task입니다.
Concept categorization
단어의 상위 개념을 맞추는 task입니다. (ex. 헬리콥터와 오토바이 -> 탈 것)
Selectional preferences
동사-명사 쌍에 대해서 명사가 동사에 대해 주어, 목적어로 사용될 수 있는 점수를 측정하는 task입니다. (ex. 사람이라는 명사는 먹다라는 동사의 주어로는 높은 점수를 받지만 목적어로는 낮은 점수를 받습니다)
Analogy
Word2Vec 논문에서 소개된 task이며 predict model의 성능 지표 측정을 위해 가장 많이 활용되는 task입니다. 주어진 단어들 사이의 관계를 잘 나타낼 수 있는 단어를 찾는 task 입니다. (ex. 서울 - 한국 + 도쿄 = ? 일 때 ?에 들어갈 단어는 일본이 나와야 합니다)
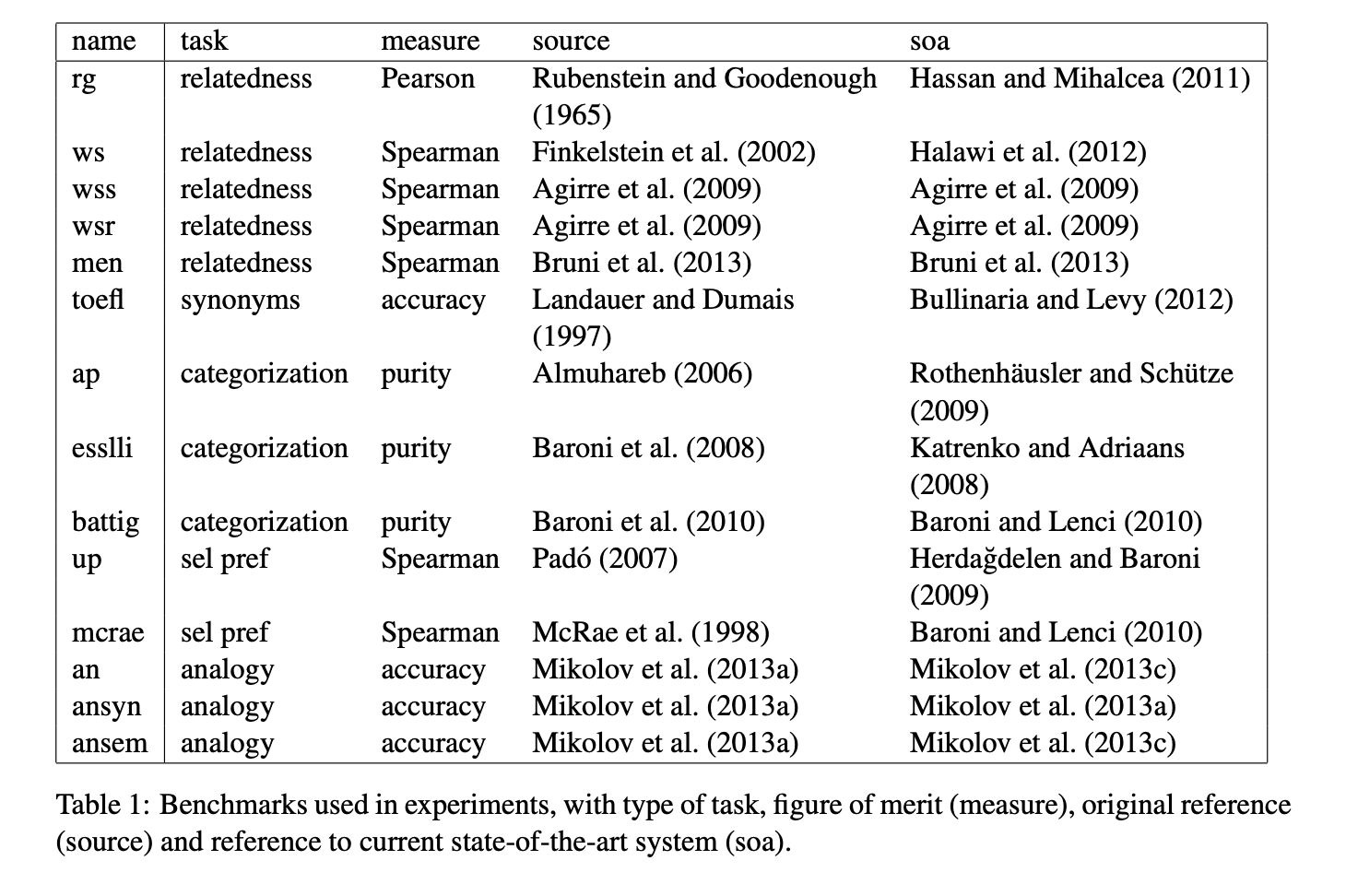
4. Results
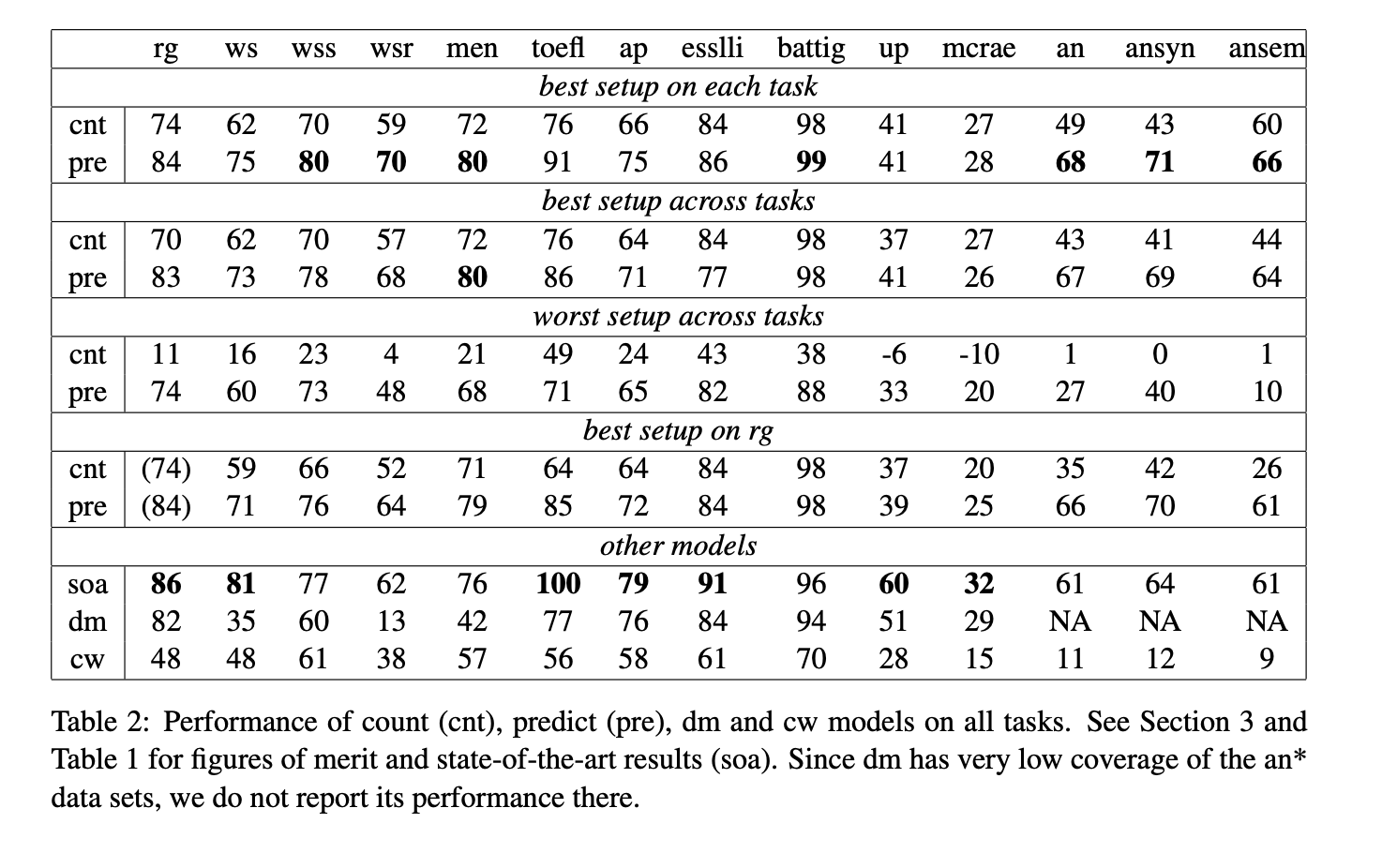
Predict model은 다양한 task에서 매우 좋은 성능을 보였습니다. 또한 predict model은 robust한 성능을 보였습니다.
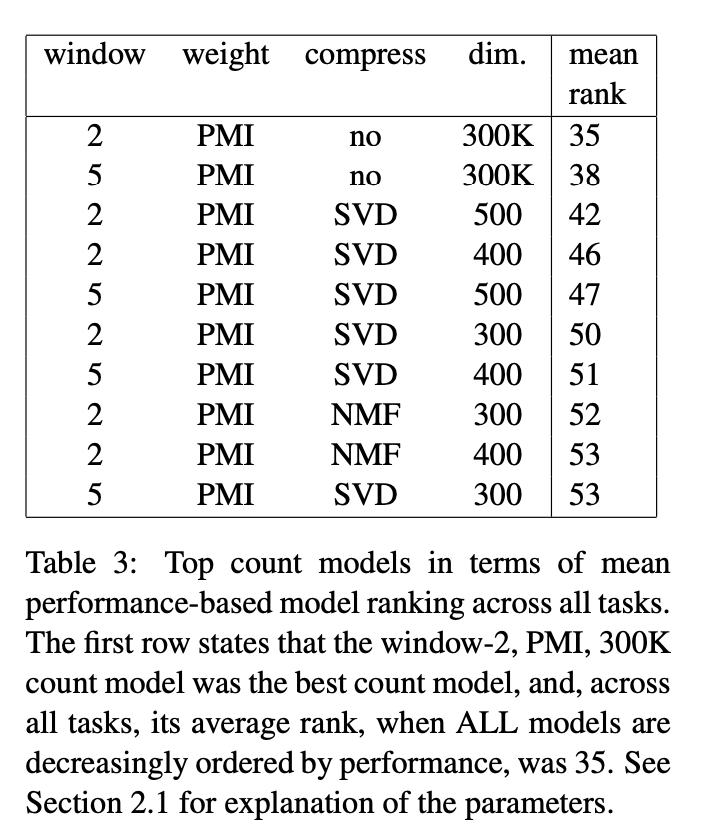
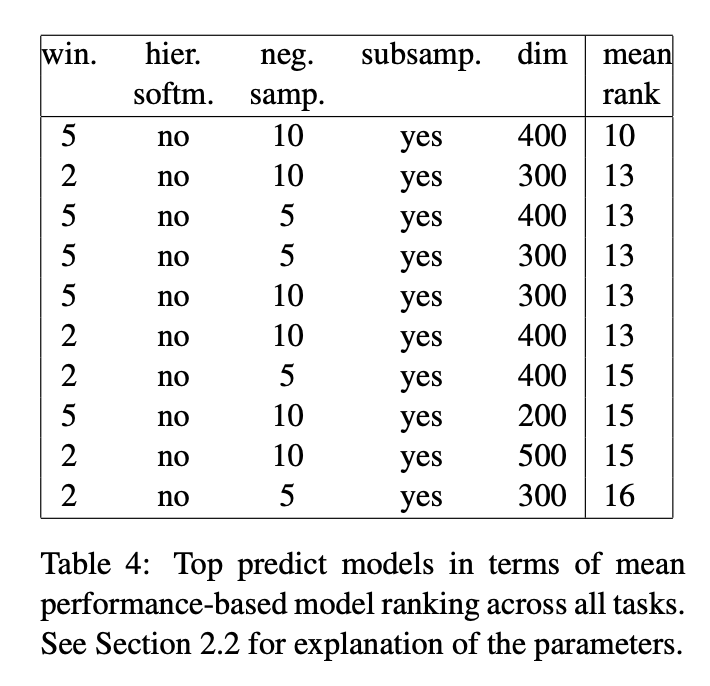
5. Conclusion
해당 논문은 count vector와 predict vector 간의 체계적인 비교를 수행하였습니다.
해당 논문은 predict model에 관한 너무 과도한 긍정적인 시선이 있기는 하지만 새로운 architecture로 변화하는 충분한 역할을 할 수 있는 좋은 성능을 갖는다는 점을 발견했습니다.
Count vector는 매우 높은 차원의 vector가 필요하기 때문에 count vector에서 고려하지 못한 option을 고려했더라면 더 좋은 성능을 count vector에서도 볼 수 있을 것이라 생각합니다.
