신경망을 활용한 word embedding의 성능이 count-based 모델보다 뛰어난 것이 알고리즘 그 자체가 아닌 hyperparameter setting에 의한 것임을 보이고 hyperparameter를 전통 방식에도 적용해 본 논문입니다.
[Abstract]
Word similarity와 analogy detection task에서 neural-network-inspired word embedding model의 성능이 count-based distributional model보다 좋다는 것이 최근의 흐름입니다. 해당 논문에서는 word embedding의 좋은 성능은 word embedding 알고리즘 그 자체 보다는 특정 system design과 hyperparameter 최적화에서 기인했다는 것을 보였습니다. 더 나아가, hyperparameter 최적화 같은 방법을 전통적인 distributional model에 적용했을 때 마찬가지로 좋은 성능을 얻을 수 있었습니다. 기존의 연구들과는 반대로, 해당 논문은 특정 모델의 성능이 다른 모델에 비해 비해 두드러지는 성능 차이가 있지 않다는 것을 보였습니다.
1. Introduction
Embedding이라 불리는 neural-network based 방식은 많은 연구에서 다뤄지고 있습니다. 이 방식들은 각각의 단어들은 d 차원의 vector로 표현하고, 유사한 vector는 유사한 단어 의미를 지닌다고 여겨졌습니다.
과거의 한 연구에서는 embedding 방식이 다양한 task에서 전통적인 방식들보다 월등한 성능을 보인다고 했습니다. 하지만 SOTA 성능을 보이는 많은 embedding 방식들은 모두 bag-of-context 방식을 기반으로 하고 있습니다. 더 나아가 한 연구에서는 word2vec의 SGNS가 PMI matrix를 factorizing한 것과 동일하다는 것을 보였습니다. 즉, SGNS의 수리적인 목적과 정보의 출처가 사실은 전통적인 방식과 매우 유사하는 것입니다.
그러면 도대체 최근의 embedding 방식이 좋은 성능의 원천은 어디일까요?
Word embedding 연구들의 주된 관심사가 수리적인 modeling과 최적화이지만 다른 요인들 역시 결과에 영향을 주고 있습니다. 특히, embedding 알고리즘들은 조절할 수 있는 hyperparameter들을 가지고 있습니다. 이런 hyperparameter들은 모델링을 수행한 사람들에 의해서 최적의 값들로 조정이 이미 되어 있습니다. 몇몇 hyperparameter들은 명백하게 조절할 수 있는 것들(ex. negative sample 수)이 있는 반면, 또 다른 몇몇은 자연스럽게 알고리즘을 일부로 여겨지기도 합니다.(ex. smoothing negative-samplig distribution). 그 외에 다른 몇몇은 언급조차 되고 있지 않지만 중요한 역할을 하고 있는 것들이 있습니다. (ex. dynamically-sized context window) 이런 모든것들을 다루는 system design choice는 최종 알고리즘의 일부이며 성능에 큰 영향을 미칩니다.
해당 논문에서는 이런 hyperparameter들을 명확히 하고, 이들이 어떻게 전통적인 count-based model에 적용될 수 있는지 보여줍니다.
Hyperparameter tuning은 모든 task에 대해 성능 향상을 보여주었습니다. 하나의 hyperparameter setting 변화만으로도 더 나은 알고리즘으로 바꾸거나, 더 큰 dataset에 다시 학습하는 것보다 좋은 성능을 얻을 수 있었습니다.
해당 논문은 또한 모든 알고리즘들이 유사한 hyperparameter set에서 조절될 수 있을 때, 성능들은 모두 엇비슷하다는 것을 보였습니다. 하나의 알고리즘은 또 다른 어떤 알고리즘보다 무조건적으로 성능이 좋다는 것은 담보할 수 없으며, 이는 곧 embedding이 count-based 방식보다 무조건적으로 낫다는 기존의 주장에 반하고 있습니다.
2. Background
해당 논문에서는 4개의 word representation 방법들을 다룹니다. 모든 방법들은 bag-of-word를 기반으로 하고 있습니다.
- Count-based : PPMI, SVD
- Predict-based(neural-based) : SGNS, Glove
Notation
- V_w : word vocabulary
- V_c : context vocabulary
- w : word
- c : contexts
- D : word-context pairs
- #(w,c) : D에서 등장하는 pair (w,c)의 수
- #(w) : D에서 등장하는 w의 수
- #(c) : D에서 등장하는 c의 수
- W : 단어 vector matrix, |V_w|Xd 차원, 각 단어들은 d차원 row vector
- C : context vector matrix, |V_c|Xd 차원, 각 context들은 dc원 row vector
모든 vector들은 inner product 값과 cosine 유사도 결과가 동일하도록 길이를 1로 맞춰주는 normalized를 수행합니다.
Contexts
D는 L-size window를 통해서 얻어집니다. (w_(i-L), ... w(i+L))
2.1 Explicit Representations(PPMI Matrix)
단얼를 표현하는 전통적인 방식은 고차원의 sparse matrix M을 활용하는 것입니다. M의 각각의 row는 V_w의 단어 w를 표현하며 column은 V_c의 문맥 c를 표현합니다. 행렬 M의 원소 M_ij는 단어 w_i와 문맥 c_j의 연관도를 나타냅니다. 연관도를 나타내는 대표적인 방법이 PMI(Pointwise Mutual Information)입니다.
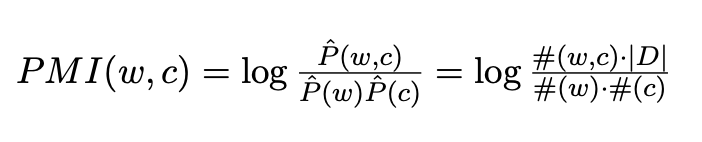
PMI에서 #(w,c)가 0일 경우, PMI값이 음의 무한대로 발산하기 때문에 이를 방지하기 위하여 positive PMI(PPMI)를 활용하기도 합니다.
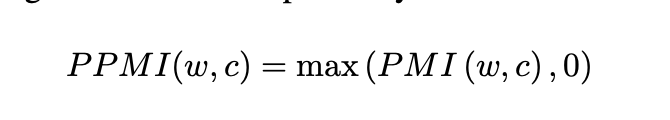
PMI와 PPMI가 공통적으로 갖는 한계점은 자주등장하지 않는 것들에 대해서 bias가 발생한다는 것입니다. 단어 w와 자주 등장하지 않는 문맥 c(단어 와 동시 등장한 횟수는 1회 존재)에 대해서 PMI의 분모 값이 매우 작아지기 때문에 PMI값은 매우 커지게 됩니다. 실질적으로 w와 c는 연관성이 매우 낮지만 rare한 context c 때문에 PMI 값만 봤을 때는 둘의 연관성이 매우 높다고 혼란을 일으킬 수 있습니다.
2.2 Singular Value Decomposition(SVD)
Sparse vector 표현 방식이 매우 잘 역할을 수행하더라도 저차원의 dense vector의 장점이 있습니다. 저차원의 dense vector를 활용한다면 계산 효율성과 일반화에 있어서 강점을 보입니다.
저차원의 dense vector를 얻는 대표적인 방식은 truncated SVD입니다. truncated SVD는 L2 loss를 활용하여 최적의 rank d를 찾아 factorization을 수행합니다.
NLP에서 PPMI matrix에 SVD를 수행한 후 word matrix와 context matrix를 아래 식과 같이 얻습니다.
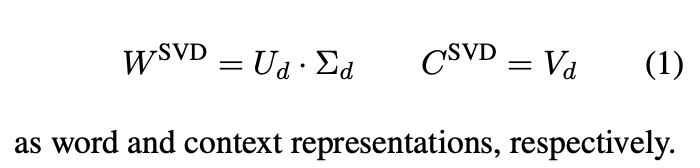
2.3 Skip-grams with Negative Sampling(SGNS)
SGNS는 단어 w와 문맥 c를 d차원의 vector w, vector c를 얻어, 유사한 단어들은 유사한 vector 표현식을 갖도록 해줍니다. SGNS는 D에 존재하는 pair (w, c)에 대해서는 vector w와 vector c의 inner product 값을 최대화하고, 그렇지 않은 negative sample (w, c_N)에 대해서는 inner product 값을 최소화합니다.
SGNS as Implicit Matrix Factorization
과거 연구에서 SGNS는 최적 값이 아래와 같을 때라고 밝혔습니다.
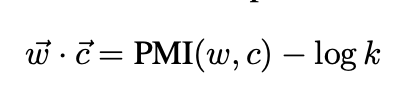
따라서 SGNS는 PMI값을 특정 상수 logk값만큼 평행이동한 값을 value로 하는 word-context matrix를 factorizing하는 것과 동일합니다.
2.4 Gloval Vectors(Glove)
Glove는 단어 w와 문맥 c의 d차원 vector를 아래와 같은 식을 만족하도록 만들어줍니다.

Glove의 목적은 log-count matrix에서 vocabulary의 bias term만큼 평행이동시킨 것을 factorization을 하는 것으로 정의할 수 있습니다.

3. Transferable Hyperparameters
Word2vec와 Glove에 적용되는 hyperparameter들을 소개하고 이들을 어떻게 count-based 방법에 적용시킬 수 있는지 소개합니다.
Hyperparameter들을 해당 논문에서는 3종류로 분류합니다.
- Pre-processing hyperparameter : input data에 영향
- Association metrix hyperparameter : word-context interaction을 어떻게 정의 하는 지에 영향
- Post-processing hyperparameter : word vector 결과를 수정
3.1 Pre-processing Hyperparameters
모든 matrix-based 알고리즘들은 input인 word-context pair (w,c)의 집합인 D에 의존합니다.
Dynamic Context Window (dyn)
전통적인 방식에서는 정해진 크기의 가중치가 따로 없는 context window를 사용합니다. 만약 window size가 5라고 하면 문맥은 target 단어 앞 뒤 5개의 단어, 총 10개의 단어로 선택됩니다. Target 단어와 가까이 있는 주변 단어들이 더 중요할 것이라는 본능에 따르면 context word들은 target word의 거리에 따라 가중치가 주어져야 할 것입니다.
이런 방식을 dynaic context window라고 합니다.
Subsampling (sub)
Subsampling은 stop-word를 제거하는 것과 유사하게 자주 등장하는 단어들을 줄이는 방법입니다. Subsampling 방법은 특정 기준 t 값보다 넘게 등장하는 단어들에 대해 확률 p로 임의로 제거해줍니다.
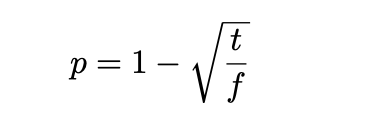
Deleting Rare Words (del)
Training dataset에서 거의 등장하지 않는 단어를 무시하는 것이 일반적인 반면, word2vec에서는 이런 단어들을 context window를 만들기 이전에 제거합니다.
3.2 Association Metric Hyperparameters
단어와 문맥 사이의 PMI(PPMI) 값은 word similarity에서 둘의 연관성을 잘 표현할 수 있다고 알려져 있습니다. 해당 논문에서는 이를 넘어 PMI의 2가지 변형 버전을 소개합니다.
Shifted PMI (neg)
SGNS는 negative sampling 수인 hyperparameter k를 갖고 있습니다. 이 k는 SGNS가 각 (w,c) pair에 대해 최적화 해야 하는 PMI(w,c)-logk에 영향을 미칩니다.
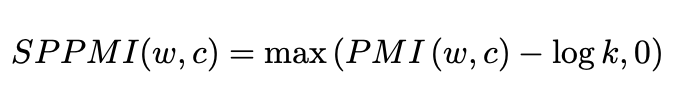
SGNS에서 k는 2가지 역할을 합니다. 첫째, k는 negative example들의 분포를 더 잘 추정하기 위해 사용합니다. k값이 크면 더 많은 data들을 사용할 수 있고 더 나은 추정치를 얻을 수 있습니다. 둘째, k는 negative examplie 대비 positive example을 관측하는 확률의 prior 역할을 할 수 있습니다. k값이 크면 negative sample이 더 자주 관측될 수 있다는 것을 의미합니다. Shifted PPMI(SPPMI)는 k의 2번째 역할(a prior)만 반영할 수 있습니다.
Context Distribution Smoothing (cds)
Word2vec에서 negative example들은 smootehd unigram distribution에 따라 sampling됩니다. 원래의 context들의 distribution을 smoothing하기 위해 모든 context counts들은 a를 지수값으로 갖는 값만큼 커집니다.
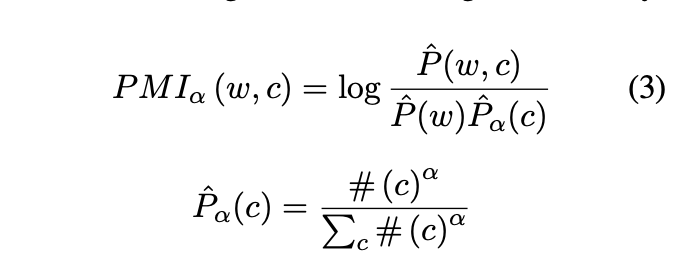
Context distribution smoothing은 거의 등장하지 않는 단어들에 대한 PMI 값의 bias를 줄여주는 역할을 합니다. 이는 또한 거의 등장하지 않는 context를 좀 더 많이 sampling할 수 있도록 해줍니다.
3.3 Post-preprocessing Hyperparameters
알고리즘의 결과를 수정하는 역할을 합니다.
Adding Context Vectors (w+c)
과거 연구에서는 context vector를 word vector에 더한 값을 Glove의 결과로 사용하였습니다.
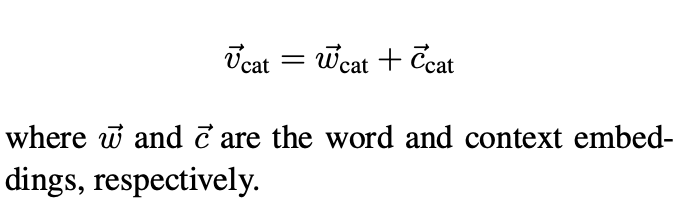
이러한 방식은 앙상블에서 아이디어를 얻어 활용되었습니다.

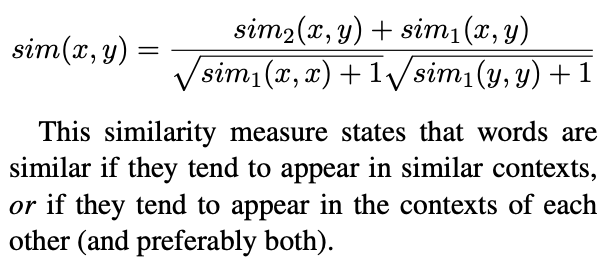
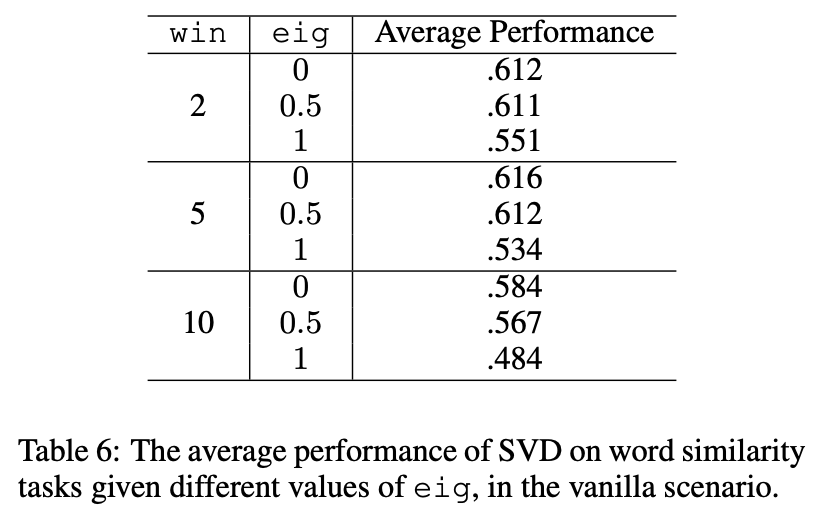
Eigenvalue Weighting (eig)
SVD를 통해 얻은 결과를 word, context vector로 활용하기 위해 아래와 같이 사용합니다.
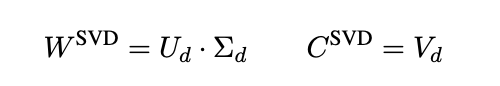
SVD-based factorization에서 word와 context 행렬의 결과가 매우 다른 특성을 지니고 있습니다. context matrix는 orthonormal하지만 word matrix는 그렇지 않습니다. 반면에 SGNS 학습을 통해 얻어진 factorization에서는 좀 더 symmetric하지만 word matirx, context matrix 모두 orthonormal하지 않습니다.
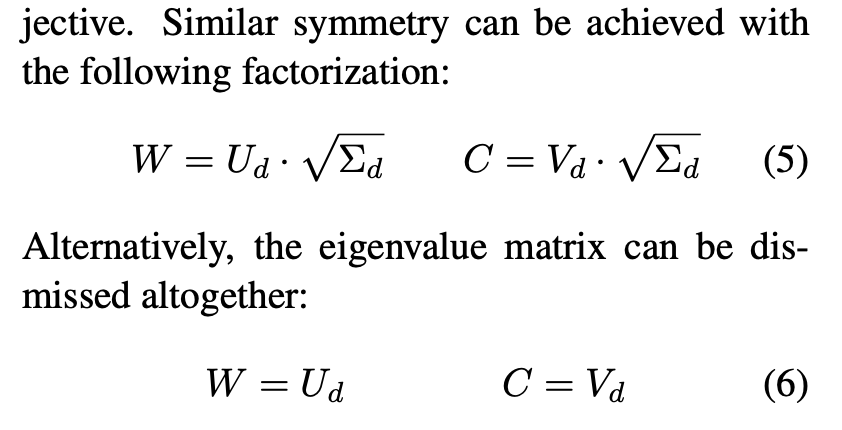
Symmetric이 왜 더 좋은 성능을 보이는지 이론적으로는 설명이 잘 되어 있지 않지만 많은 연구들에서 경험적으로 밝혔습니다.

Vector Normalization (nrm)
모든 vector들은 길이가 1이 되도록 normalization을 해주고 dot product 연산이 cosine similarity가 될 수 있도록 해줍니다.
4. Experimental Setup
4.1 Hyperparameter Space
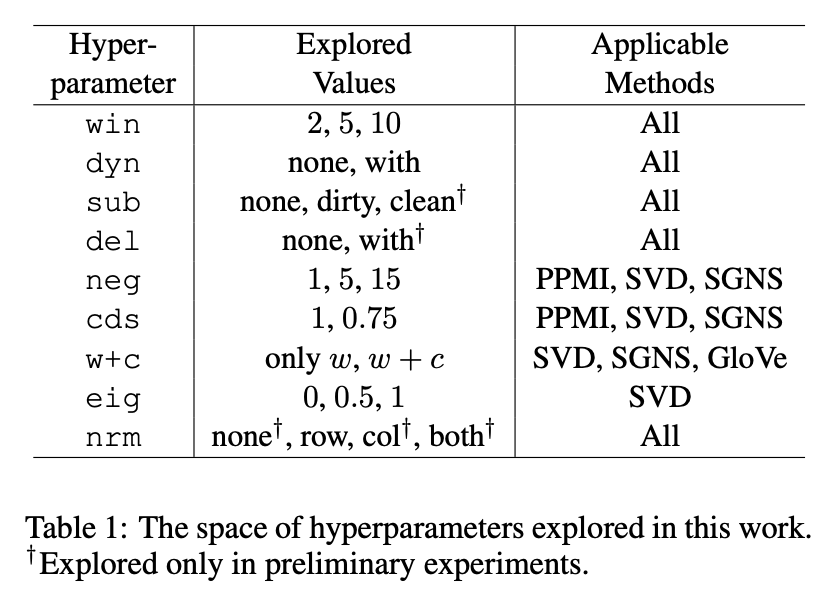
4.2 Word Representations
Corpus
English Wikipedia, pre-processed by removing non-textual elements, sentence splitting, tokenization
Training Embeddings
500 dimensional representaion
4.3 Test Datasets
Word Similarity
WordSim353, WordSim Similarity, WordSim Relatedness, MEN dataset, Mechanical Turk dataset, Rare Words dataset, SimLex-999
Analogy
MSR's analogy dataset, Google's analogy dataset
5. Results
해당 논문에서는 다양한 hyperparameter setting의 효율적인 비교와 각 setting이 결과에 어떤 영향을 미치는지 확인하였습니다. 또한 hyperparameter를 잘 조절하는 것이 data를 추가하는 것보다 더 나은 성능을 보인다는 것을 밝혔습니다. 마지막으로 embedding model 자체의 성능이 좋다는 기존 연구들과는 반대로 알고리즘 그 자체가 아닌 hyperparameter setting이 좋은 성능의 기반이라는 것을 보였습니다.
5.1 Hyperparameters vs Algorithms
Vanilla scenario
모든 hyperparameter들의 조정이 되어 있지 않습니다.
- small context windows : win = 2
- no dynamic contexts : dyn = none
- no sub-sampling : sub = none
- one negative sample : neg = 1
- no smoothing : cds = 1
- no context vectors : w+c = only w
- default eigenvalue weights : eig = 0.0
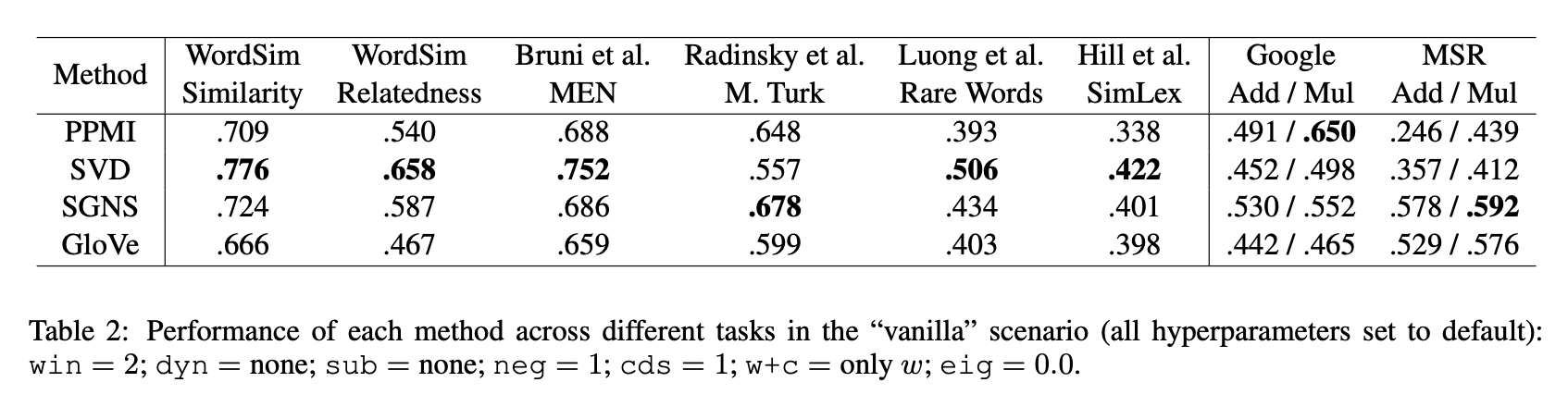
Word2Vec default setting scenario
- small context windows : win = 2
- dynamic contexts : dyn = with
- dirty sub-sampling : sub = dirty
- five negative sample : neg = 5
- context distribution smoothing : cds = 0.75
- no context vectors : w+c = only w
- default eigenvalue weights : eig = 0.0
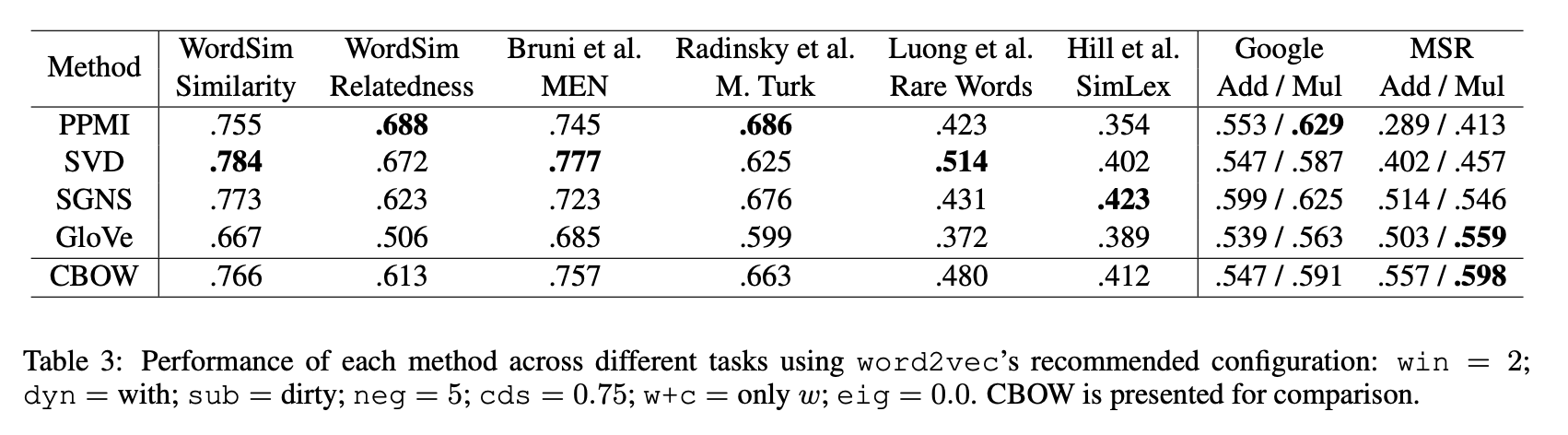
Full range of hyperparameters given small context window
가장 성능이 좋은 hyperparameter의 결과를 선택
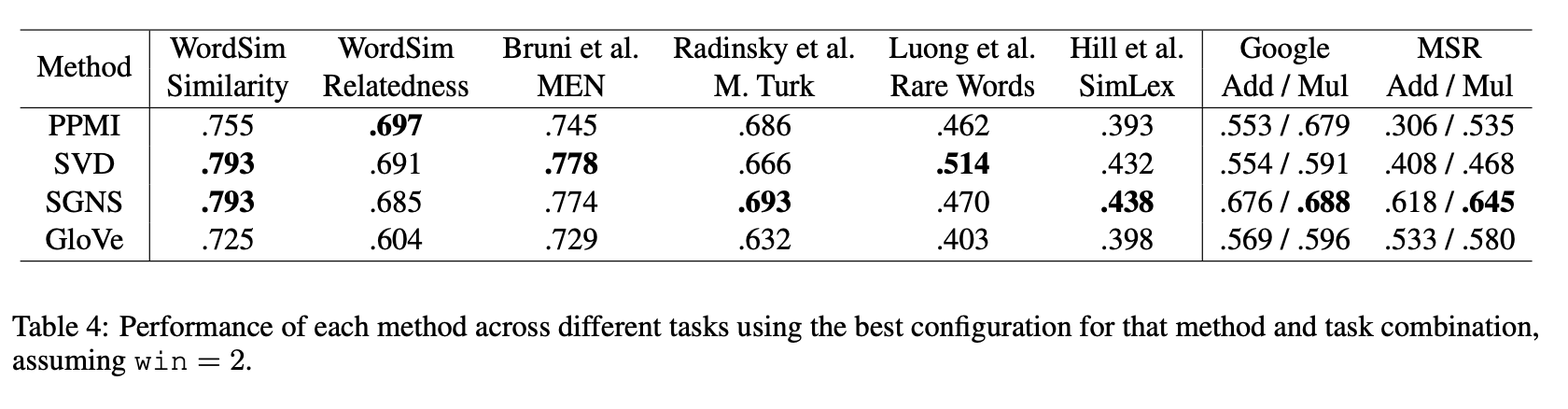
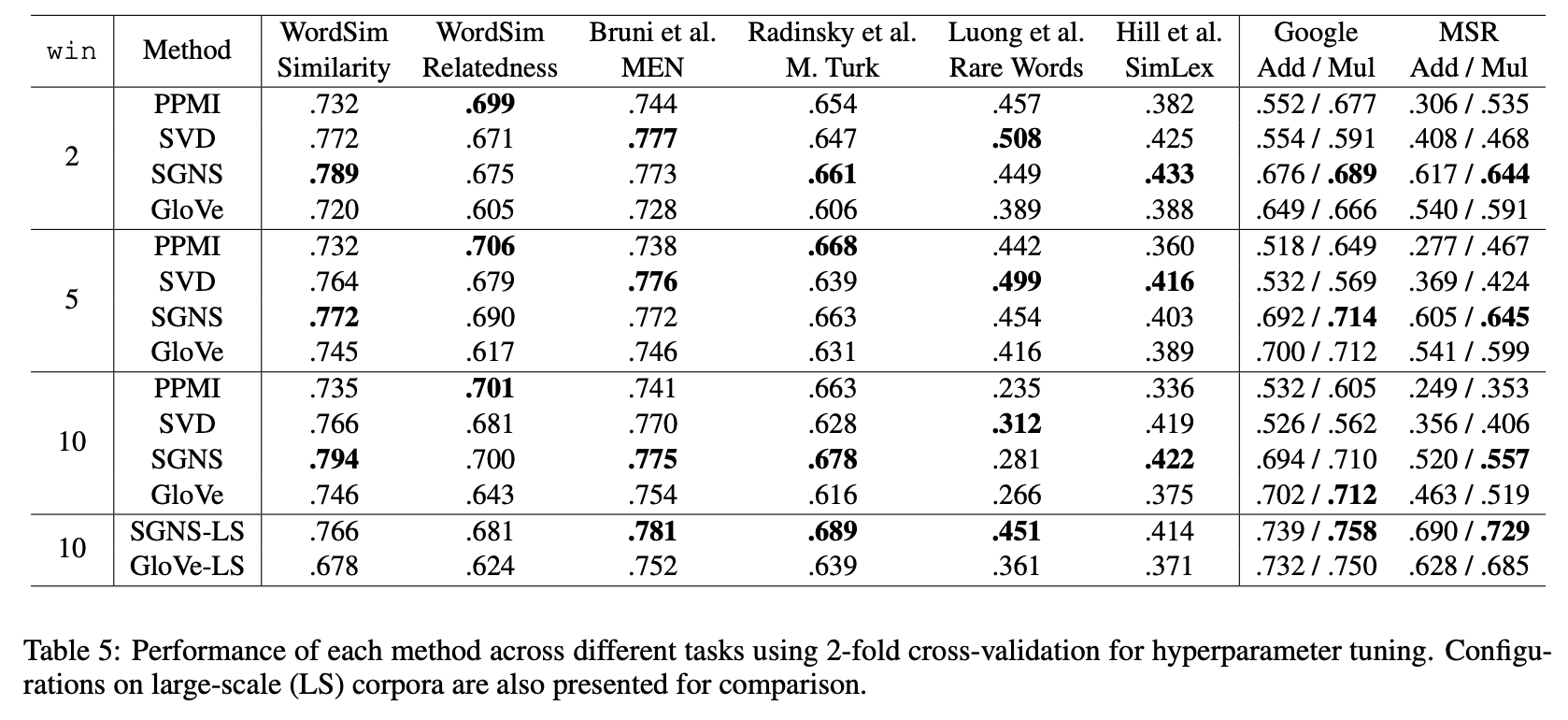
Main Results
Hyperparameter는 tarining set에서만 tuning 되었고 unseen test data에는 적용되어 있지 않음, 2-fold cross validataion 활용
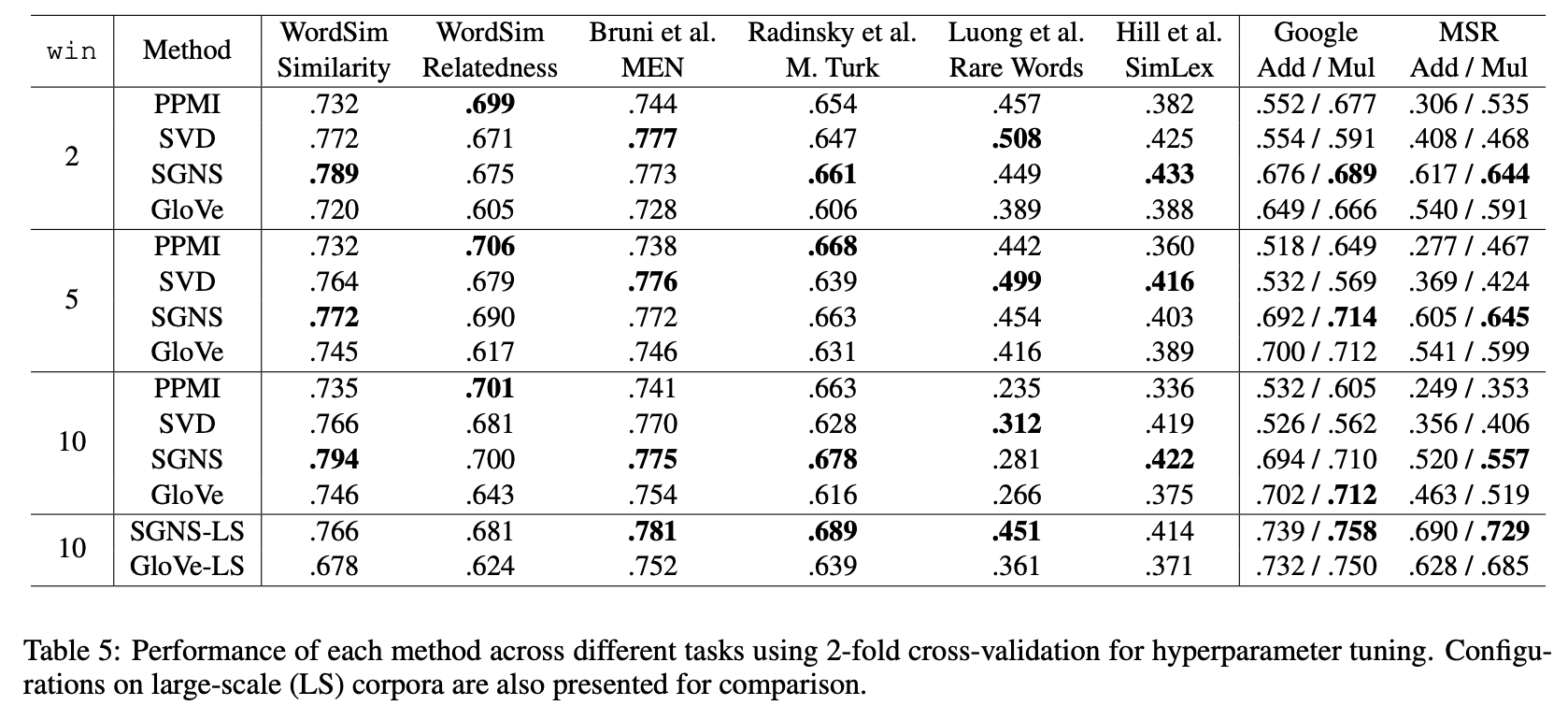
5.2 Hyperparameters vs Big Data
5.3 Re-evaluating Prior Claims
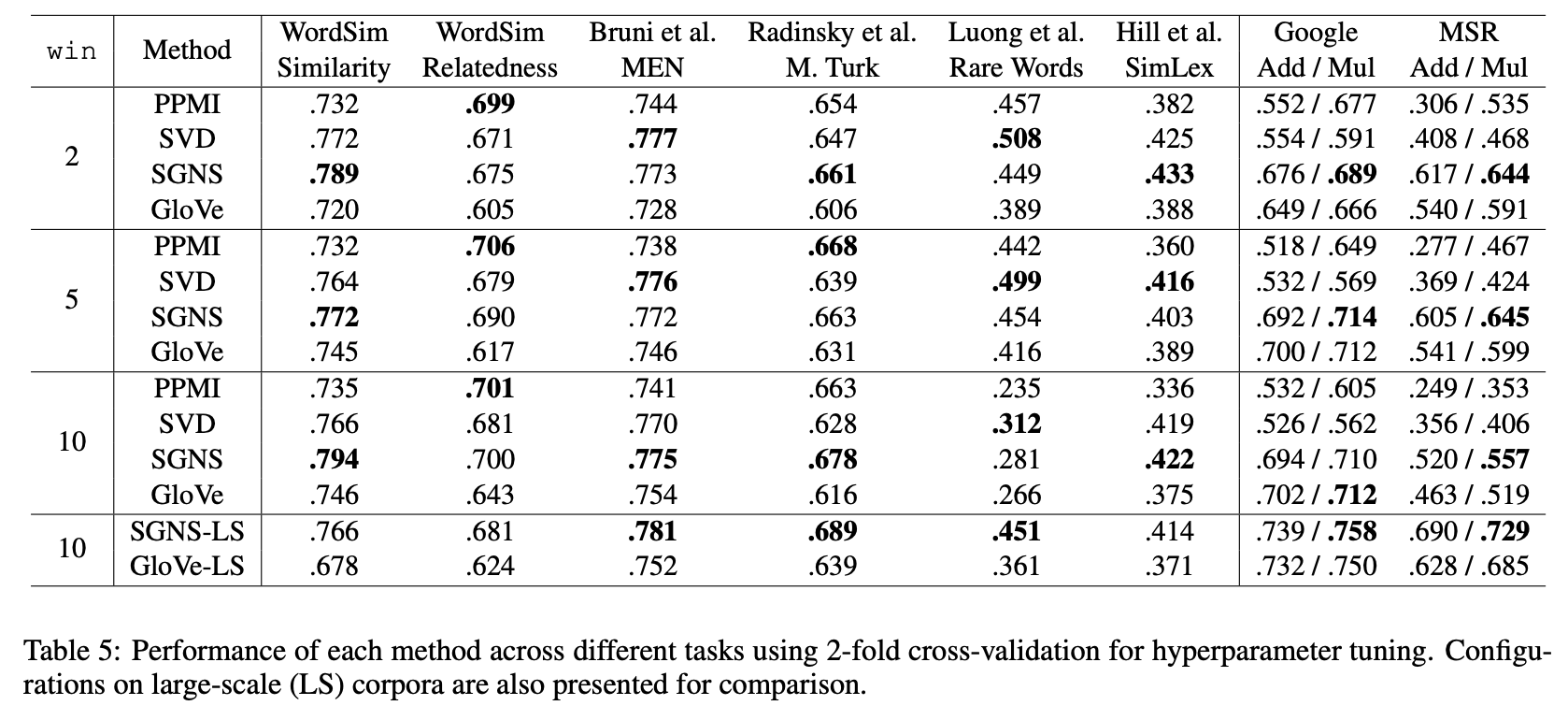
Are embeddings superior to count-based distributional methods?
Is Glove superior to SGNS?
Is PPMI on-par with SGNS on analogy tasks?
Does 3CosMul recover more analogies than 3CosAdd
5.4 Comparision with CBOW
6. Hyperparameter Analysis
6.1 Harmful Confugurations
특정 hyperparameter setting들은 특정 방법의 성능에 악영향을 줄 수 있습니다.
SVD does not benefit from shifted PPMI
Using SVD 'correctly' is bad
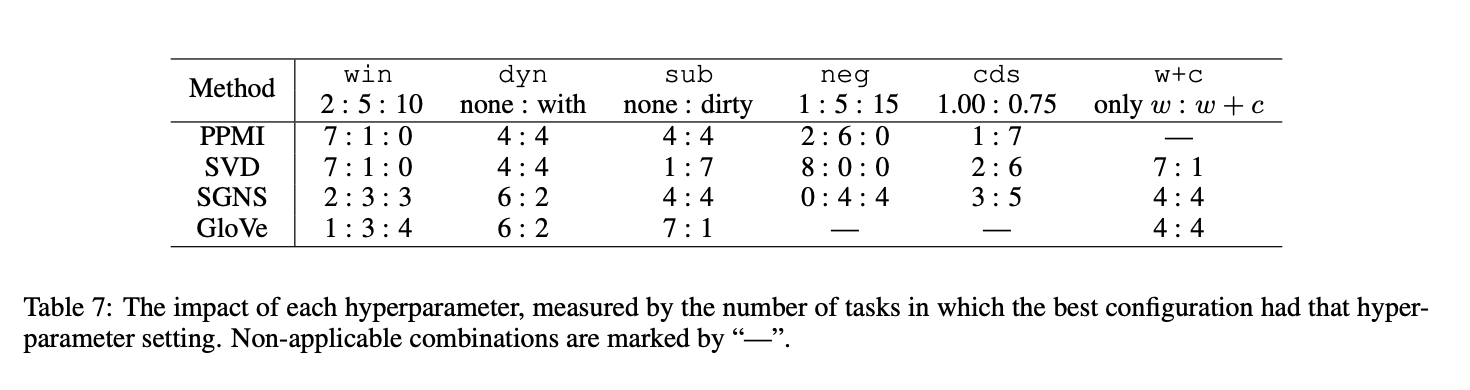
6.2 Beneficial Configurations
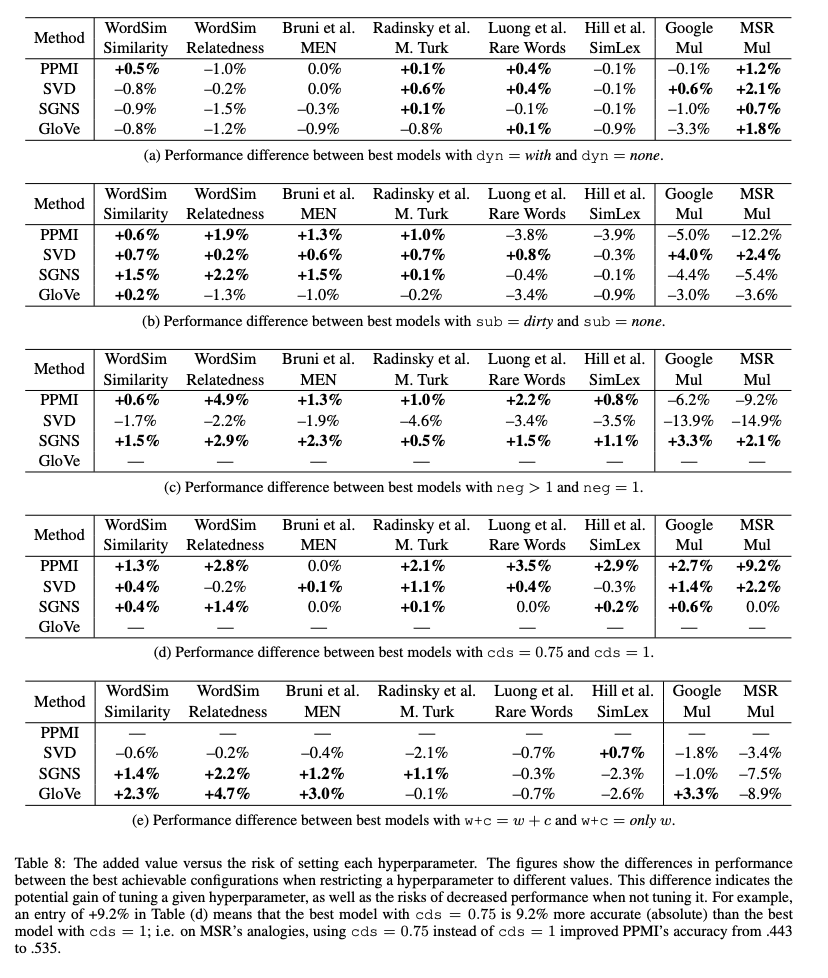
7. Practical Recommendations
모든 hyperparameter들을 조정하는 것을 가장 추천하지만 비용적인 문제가 있을 수 있습니다. 따라서 해당 논문에서는 아래와 같은 방법들을 제안합니다.
- PMI를 수정하기 위해 context distribution smoothing은 항상 사용 : cds = 0.75
- SVD를 'correctly' 하게(eig = 1) 사용하지 않고 대신 symmetric 변형 버전 중 하나를 사용
- SGNS는 robust한 baseline
- SGNS를 사용한다면 많은 수의 negative sample을 사용
- SGNS와 Glove 모두에서 w+c를 사용하는 것은 도움
8. Conclusion
해당 논문에서는 word representaion 방법들에서 약간의 수정만으로도 좋은 성능을 보인다는 것을 보였습니다. 전통적인 방식들에 hyperparameter들을 어떻게 적용하는 지 보여주어 방법들 사이의 좀 더 적잘한 비교를 수행하였습니다.
해당 논문은 controlled-variable 실험을 필요성을 보여주었고, variable의 개념을 task, data, method를 넘어서 때떄로 무시되는 preprocessing step과 hyperparameter setting까지 확장시켰습니다.
