Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features
Paper_review
CBOW의 개념을 확장하여 unsupervsied 방식으로 sentecne embedding을 구하는 Sent2Vec을 소개하는 논문입니다.
[Abstract]
많은 분야에서 unsupervised word embedding의 최근 성공은 word sequences들의 더 나은 성능의 단순한 embedding을 만들 수 있을까에 대한 질문의 만들어냈습니다. 해당 논문에서는 문장의 representation을 학습할 수 있는 단순하면서 효율적인 unsupervised objective를 제안합니다. 해당 논문에서 제안한 방법으로 많은 benchmark task들에서 SOTA 성능을 뛰어넘는 걸 보였으며, 특히 general-purpose sentence embedding을 robust하게 만들 수 있었습니다.
1. Introduction
매우 많은 양의 data를 학습에 활용할 수 있기 때문에 unsupervised learning의 발전은 machine learning 발전의 주된 요인입니다. Deep learning의 최근 성공은 주로 supervised learning이었습니다. 하지만 text와 NLP영역에서는 unsupervised 방식으로 semantic word embedding을 학습는 등 supervised learning에만 의존하지는 않았습니다.
단어에는 다양한 semantic representation들이 있지만 문장, 문당, 문서 전체와 같이 길이가 긴 text의 semantic embedding을 학습하는 것은 여전히 어려운 문제입니다. 더 나아가, unsupervised 방식으로 general-purpose representation을 학습하는 것이 주된 목표입니다.
최근, 2개의 서로 다른 연구 경향이 등장하였습니다. 하나는 강력하고 복잡한 모델을 활용하여 NLP에 deep learning을 활용하는 것입니다. 주로 RNN, LSTM, attention 등이 활용되고 있습니다. 이러한 방법은 성능이 좋지만 모델의 복잡도가 올라감에 따라 학습 dataset이 커질수록 학습이 매우 느려지게 됩니다. 또 다른 경향은 단순한 matrix factorization과 같은 shallow model을 통해 매우 큰 dataset을 통한 학습의 이점을 얻을 수 있다는 것입니다. 이러한 이점은 매우 큰 장점이 될 수 있으며 특이 unsupervised setting에서 중요합니다.
놀랍게도 sentence embedding을 구성할 때 단순히 word vector를 평균내는 것만으로도 LSTM의 성능을 넘길 수 있었습니다. 해당 논문에서는 sentence embedding의 발전된 unsupervised learning을 소개합니다. 해당 논문에서 제안한 모델은 학습의 objective가 word embedding이 아닌 sentence로 바꾼 CBOW의 확장으로 볼 수 있습니다. 해당 논문에서는 실증적 실험을 통하여 제안한 모델이 모델의 단순함을 유지했기 때문에 학습과 추론에서 일반적인 모델들보다 복잡도가 낮아짐과 동시에 general-purpose sentence embedding에 있어 SOTA 성능을 갖는 것을 보였습니다.
Contribution
- Model : 해당 논문에서 제안한 모델은 sent2vec입니다. N-gram word embedding을 사용하여 sentence embedding을 만들 수 있는 unsupervised model입니다.
- Efficiency & Scalability : 해당 논문에서 제안한 모델의 계산 복잡도는 각 단어별 O(1)에 불과합니다. 빠른 추론속도는 downstream task와 실제 적용에 있어서 큰 이점이 됩니다.
- Performance : 해당 논문에서 제안한 모델은 기존의 unsupervised와 심지어 semi-supervised model의 SOTA 성능과 비교하여도 더 좋은 성능을 보였습니다.
2. Model
해당 논문의 모델은 단순한 matrix factor model에서 영감을 받았습니다. 더 자세히는 matrix factor model들은 아래 형태의 식을 최적화하는 문제를 방식으로 정의됩니다.

임의의 길이의 문장 S가 주어졌을 때, indicator vector l_S는 binary vector encoding S입니다. (해당 문장에 포함된 단어들만 나타내는 indicator 라고 생각하면 될 듯)
CBOW와 GloVe에서는 말뭉치에서 고정된 길이의 context window를 활용하여 word embedding을 학습합니다. 이러한 모델들에서는 k = |V|이고, 각 cost function f_S는 input의 single row에 의존합니다. 이는 곧, 주어진 길이의 context S에서 target word를 갖는다는 것을 의미합니다.
이와는 반대로 해당 논문에서 제안하는 sentence embedding에서는 S는 전체 문장 혹은 전체 문서입니다.
2.1 Proposed Unsupervised Model
해당 논문에서는 sentence embedding을 학습하는 새로운 unsupervised model인 Sent2Vec을 소개합니다. 개념적으로 해당 모델은 CBOW로부터 얻을 수 있는 word embedding의 sentenc로의 확장버전으로 볼 수 있습니다.
사전에 있는 단어 w에 대해 source(context) embedding v_w와 target embedding u_w을 dimension h와 k=|V|에 대해 (1)을 통해 얻을 수 있습니다. Sentence embedding은 아래의 (2)와 같이 문장을 구성하는 단어들의 word embedding의 평균으로 정의할 수 있습니다. 해당 논문에서는 이 모델을 단지 unigram뿐만 아니라 n-gram으로 확장하여 source embedding을 학습하여 발전시켰습니다. 그 후 각 단어 별 n-gram embedding을 평균을 계산하였습니다. 즉, sentence embedding v_S는 아래 식과 같이 모델링할 수 있습니다.
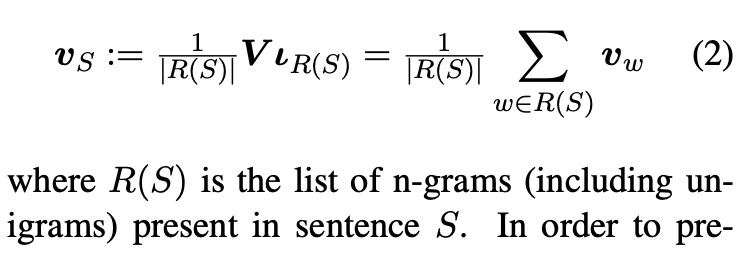
Context로부터 missing word를 예측하기 위하여, negative sampling을 사용하여 softmax output의 근사값을 구합니다.

2.2 Computational Efficiency
다른 복잡한 nerual network based 모델과 비교하였을 때 해당 논문에서 제안한 모델의 주된 장점 중 하나는 inference와 tarining 모두에서 computational cost가 매우 낮다는 것입니다. 문장 S와 학습된 모델이 주어졌을 때, sentence representation v_S 계산을 위해서는 오직 |S| * h floating point 연산이 필요합니다. 모델이 단순하기 때문에 parallelized or distributed SGD를 사용한 병렬 처리가 가능합니다.
또한, higher-order n-grams을 효율적으로 활용하기 위하여 standard hashing trick을 사용할 수도 있습니다.
2.3 Comparision to CBOW
CBOW는 고정된 크기의 context가 주어졌을 때 target word를 예측하는 것을 목표로 합니다. Context는 hyperparameter인 w_s로 정해진 window size보다 작은 거리만큼 target word에서 떨어진 단어들의 vector들의 평균으로 사용됩니다. 해당 논문에서 소개한 모델의 관점에서는 unigram feature로 제한하였을 때는 CBOW의 확장으로 볼 수 있으며 이 때 context window는 문장 전체가 될 수 있습니다. 실질적으로 word embedding 학습을 빠르게 하기 위한 중요한 trick에 있어서는 CBOW과 약간의 주된 차이점이 있습니다. 먼저, CBOW는 문장에서 각 token w을 q_p(w) 확률로 버릴지 말 지 결정하는 frequent word subsampling을 사용합니다. Subsampling은 n-gram feature의 생성을 방해하고, 문장의 중요한 문법적 특징을 없애버립니다. 이는 또한 subsampled word 사이의 거리를 단축시키고 실질적으로 context window를 늘리는 것과 동일합니다. 2번째 trick은 dynamic context window입니다. 각 subsampled word w에 대하여 1과 w_s 사이의 값에서 context window size가 결정되는 것입니다.
2.4 Model Training
해당 논문의 모델은 weight를 SGD with a linearly decaying learning rate를 활용하여 업데이트 합니다.
Overfitting을 방지하기 위하여 각 문장마다 dropout을 활용하였습니다.
다양한 dropout을 실험을 통하여 확인하여 각 문장마다 K n-grams을 droping 했을 때 각 token 별 고정된 확률로 droping하는 것보다 좋은 성능을 갖는다는 것을 확인할 수 있었습니다. 하지만 dropout은 오히려 짧은 문장에서는 부정적인 영향을 주었습니다.
각 word vector마다 L1 regularization을 적용하였습니다.

3. Related Work
3.1 Unsupervised Models Independent of Sentence Ordering
ParagraphVector DBOW model은 word embedding 뿐만 아니라 sentence를 학습할 수 있는 log-linear model이며 sentence vector representation이 주어졌을 때 문장 안의 word를 예측하기 위해 softmax를 활용합니다.
ParagraphVector DM은 sentence vector representation과 연속된 단어의 n-gram을 활용하여 다음 단어를 예측하였습니다.
(Lev et al., 2015)에서는 word2vec model에서 sentence embedding을 얻기위하여 단순 평균, multivariate Gaussian의 Fisher vector 등의 다른 compositional 기술을 활용하였습니다.
(Hill et al. 2016a) 에서는 Sequentail (Denoising) Autoencoder, S(D)AE를 제안하였습니다. 이 모델은 먼저 input data에 noise를 최초로 추가하였습니다. 먼저 각 단어들은 p_0 확률로 제거 된 뒤 각 non-overlapping bigram 단어들은 확률 p_x로 순서가 뒤바뀌게됩니다. 그 후 LSTM basd 모델을 활용하여 바뀐 문장으로 부터 원본 문장을 찾는 것을 목표로 합니다. 만약 p_0=p_x=0일 때 이 모델은 단순히 Sequential Autoencoder가 됩니다. 더 나아가 S(D)AE+embs 모델어서는 각 단어들이 기존의 pre-trained word embedding을 통해 표현됩니다.
(Arora et al. 2017)에서는 sentence가 (pre-trained) word vector들의 가중 평균으로 표현된다고 제안하였습니다.

(Pham et al. 2015)에서 제안한 C-PHRASE는 각 문장의 syntatic parse tree로부터 추가적인 정보에 의존합니다.
3.2 Unsupervised Models Depending on Sentence Ordering
(Kirose et al. 2015)의 SkipThought model에서는 sentence 수준 model을 RNN을 활용하였습니다.
(Hill et al. 2016a)의 FastSent는 문장 수준의 log-linear bag-of-words model입니다.
해당 논문에서 제안한 모델과 비교하였을 때, (Kenter et al. 2016)의 Siamese CBOW는 문장에서 word embedding의 평균을 구한다는 점에서 유사한 아이디어를 공유합니다. 하지만 이 모델은 문장 주변을 예측하기 위하여 Siamese neural network 구조에 의존하고 있습니다.
(Bojanowski et al. 2017)의 FastText는 word sequence가 아닌 character sequence level의 특징을 지니고 있으며 비슷한 컨셉의 모델을 사용하고 있습니다. 하지만 2가지 주된 차이점이 있습니다. 해당 논문에서 제안한 모델은 source word sequence로부터 target word를 예측하지만 FastText에서는 character sequence로부터 target word를 예측합니다. 두 번째는 해당 논문의 모델은 source embedding을 단순 평균하지만 FastText에서는 평균이 아닌 합을 구합니다.
3.3 Models requiring structured data
(Hill et al. 2016b)의 DictRep는 단어의 사전적 정의를 mapping하기 위해 학습됩니다. DictRep는 BOW와 RNN(LSTM) 2가지 서로 다른 구조를 활용합니다.
4. Evaluation Tasks
해당 논문에서는 unsupervised task뿐만 아니라 supervised task 역시 수행하였습니다.
Downstream Supervised Evaluation
- paraphrase identification (MSRP)
- classification of movie review sentiment (MR)
- product reviews (CR)
- subjectivity classification (SUBJ)
- opinion polarity (MPQA)
- question type classification (TREC)
Unsupervised Similarity Evaluation
- STS 2014
- SICK 2014
5. Results and Discussion
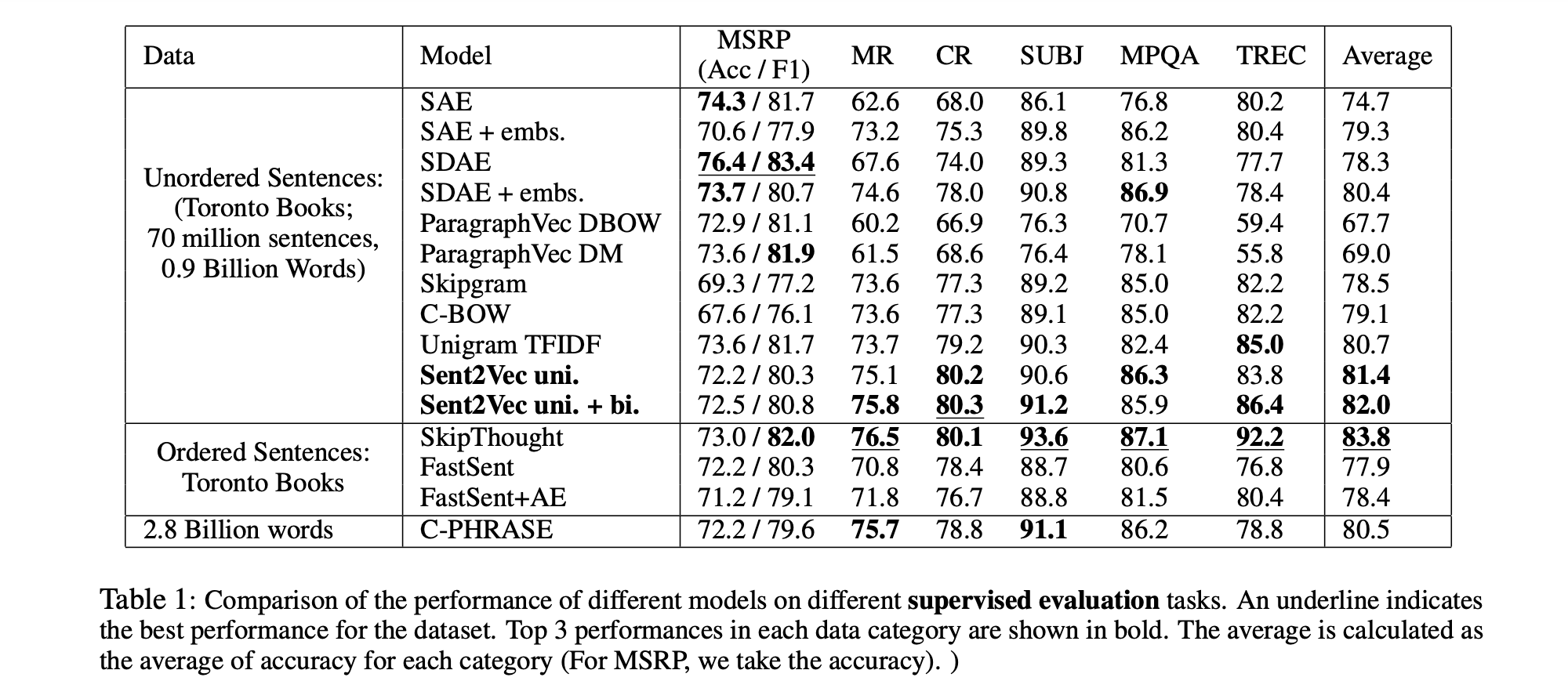
Downstream Supervised Evaluation Results
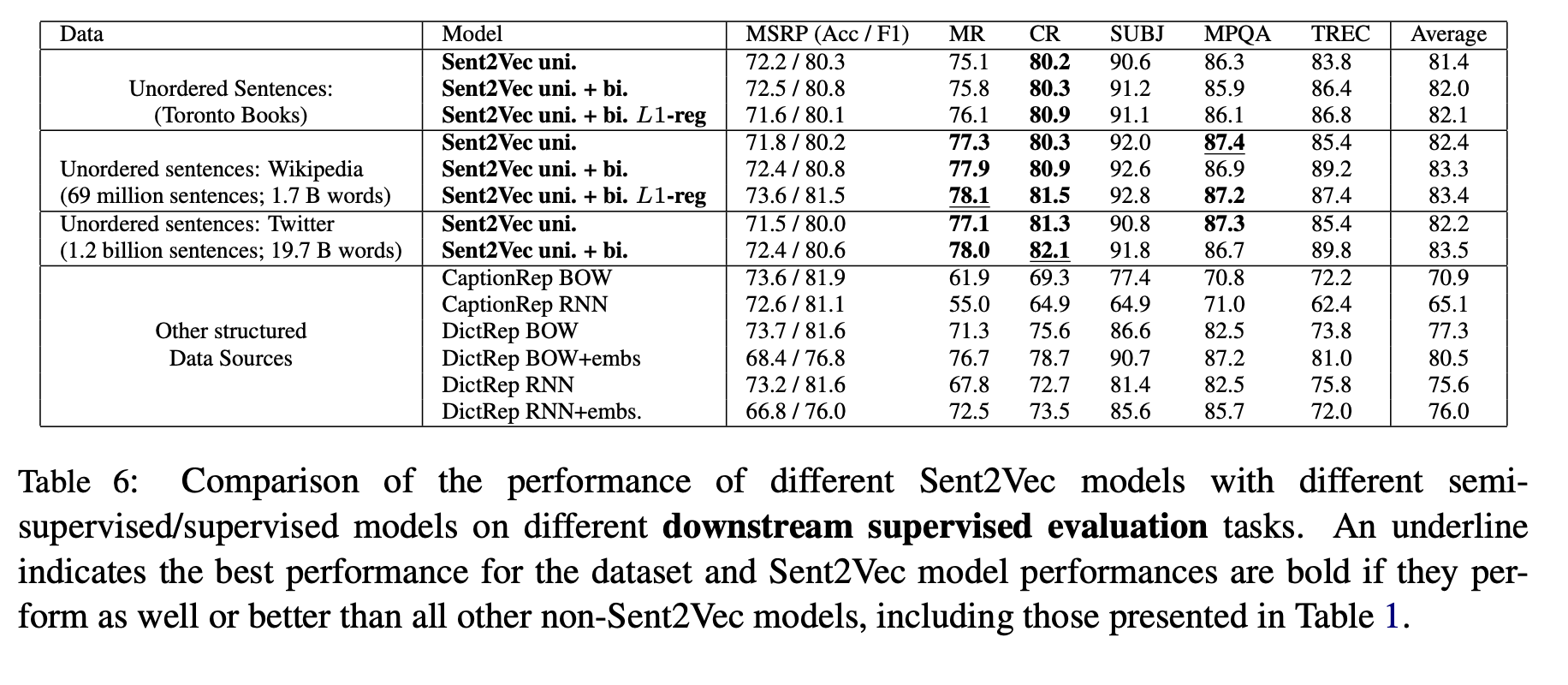
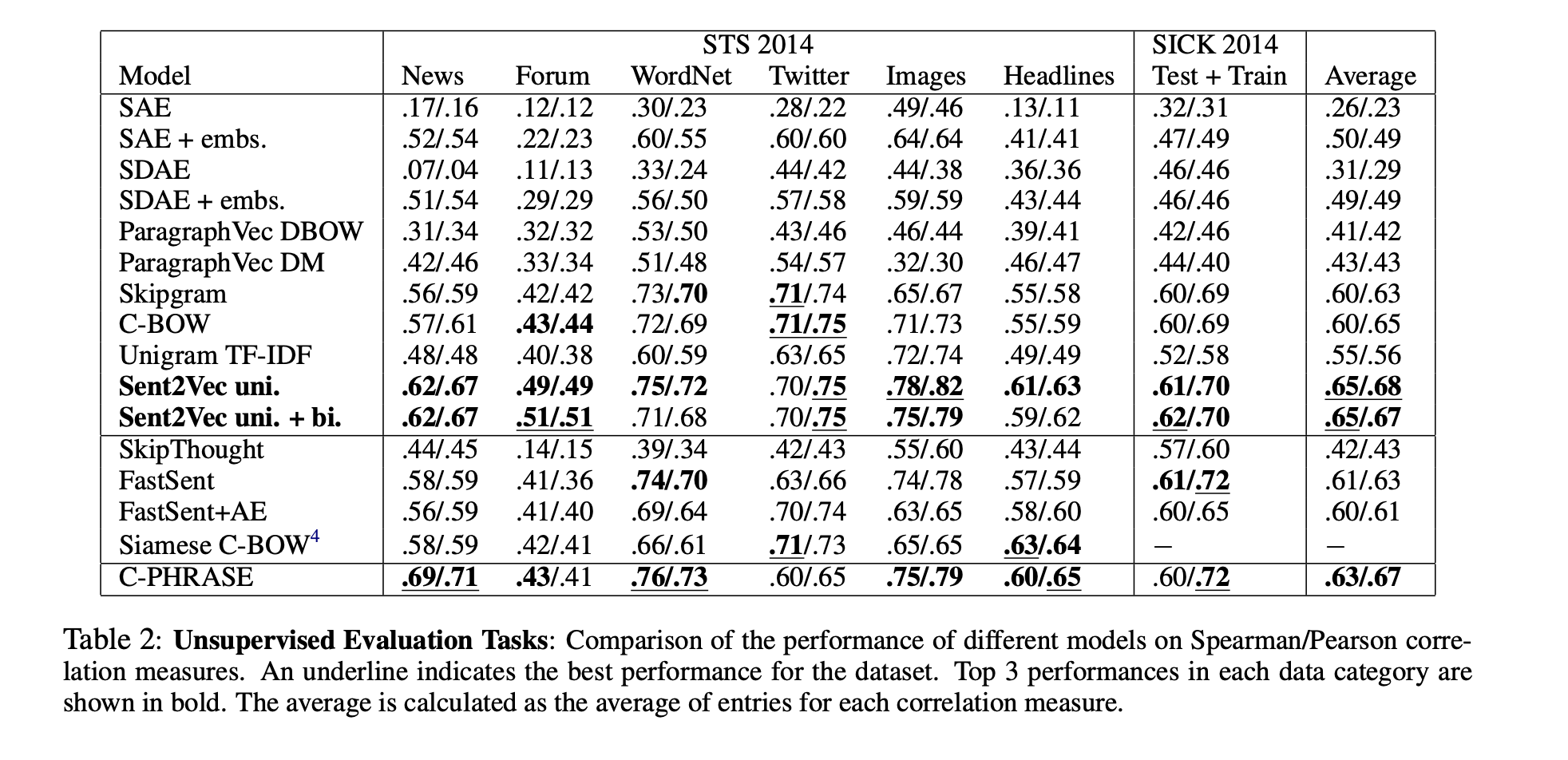
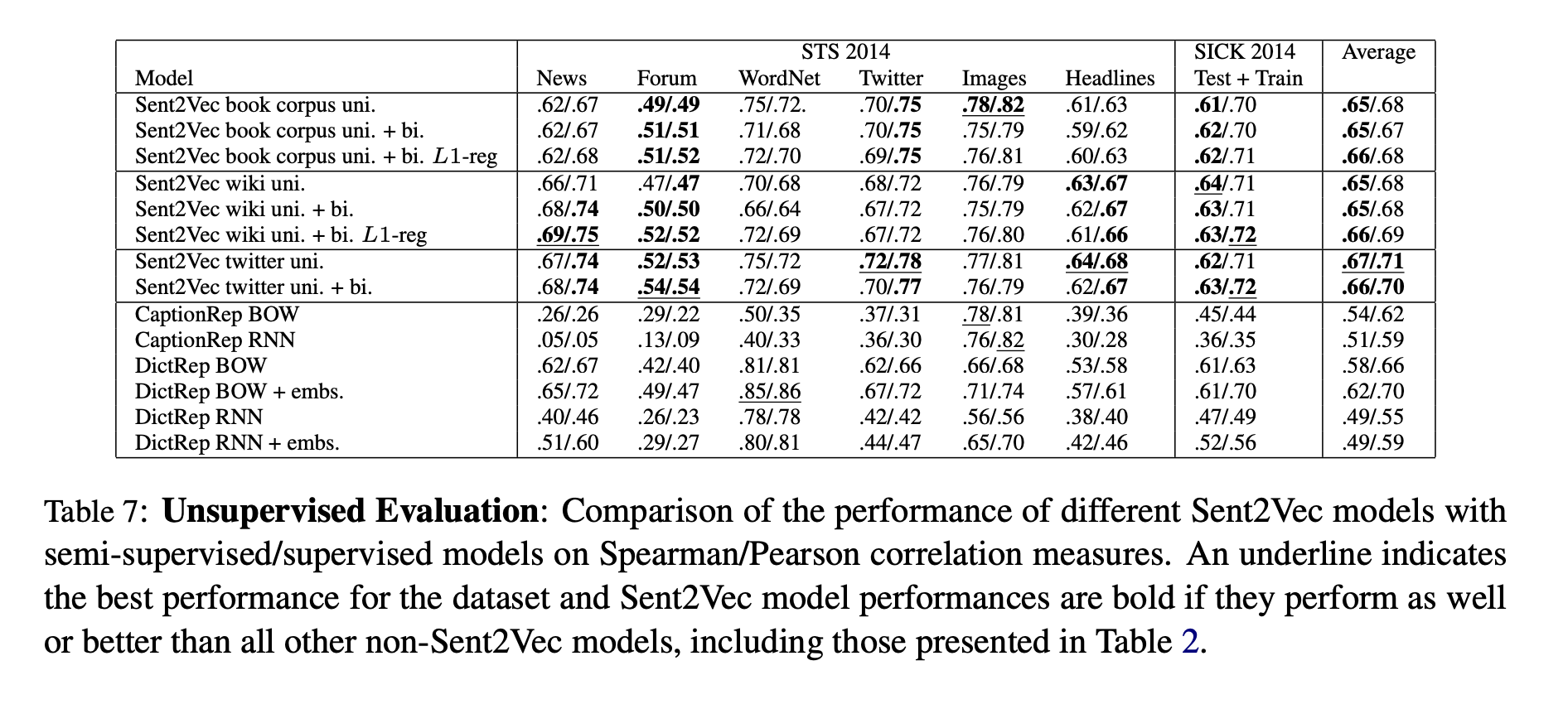
Unsupervised Similarity Evaluation Results
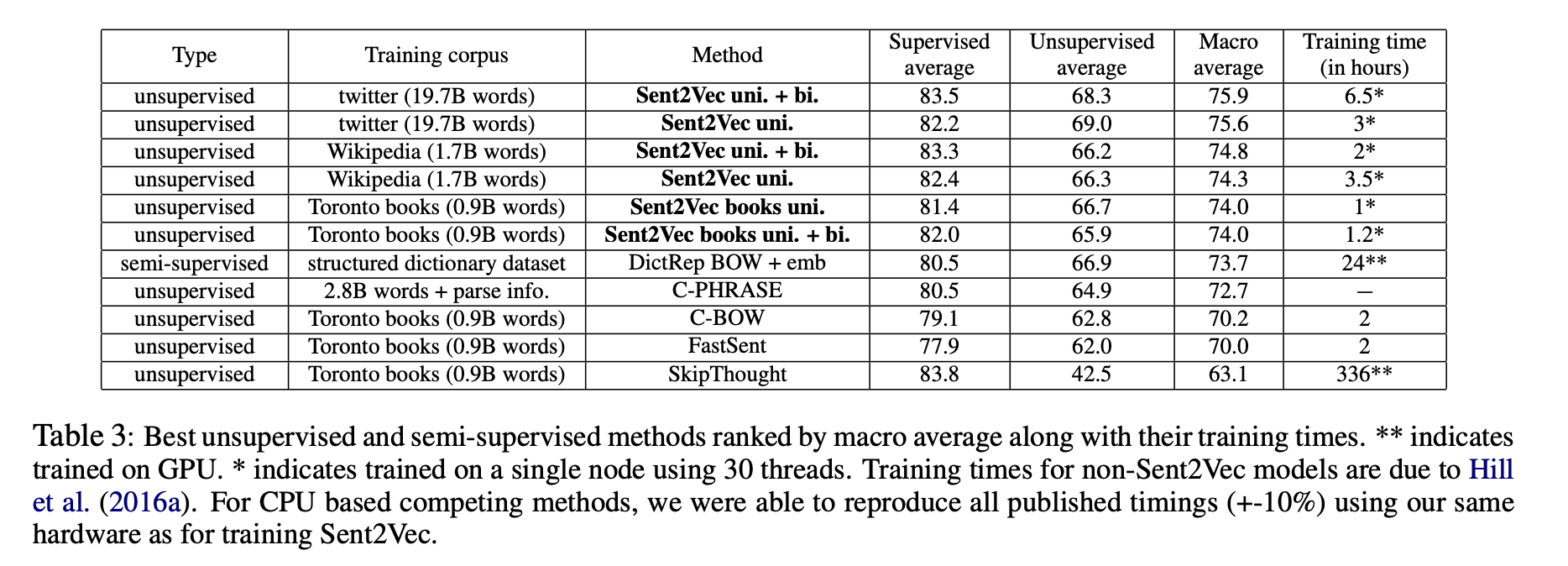
Macro Average
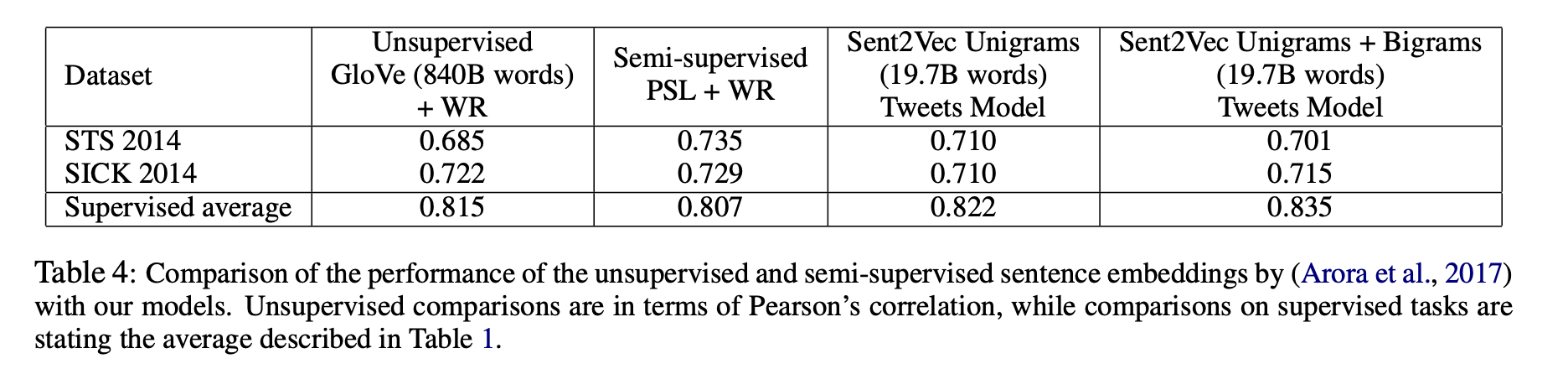
Comparison with Arora et al. (2017)
On learning the importance and the direction of the word vectors
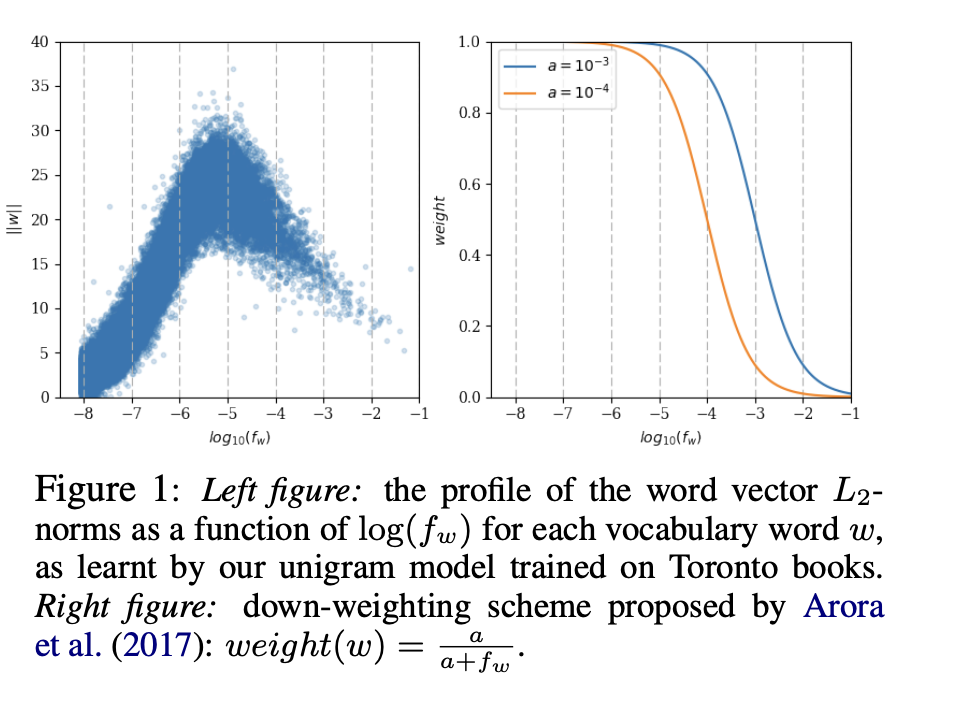
6. Conclusion
해당 논문에서는 sentence embedding을 학습하고 추론하는 새로운 계산 효율성이 높으면서 unsupervised CBOW에서 파상된 모델을 소개하였습니다.
해당 모델은 generalizable하고 학습 속도가 매우 빠르며 이해하기 쉬우면 해석도 쉽습니다.
