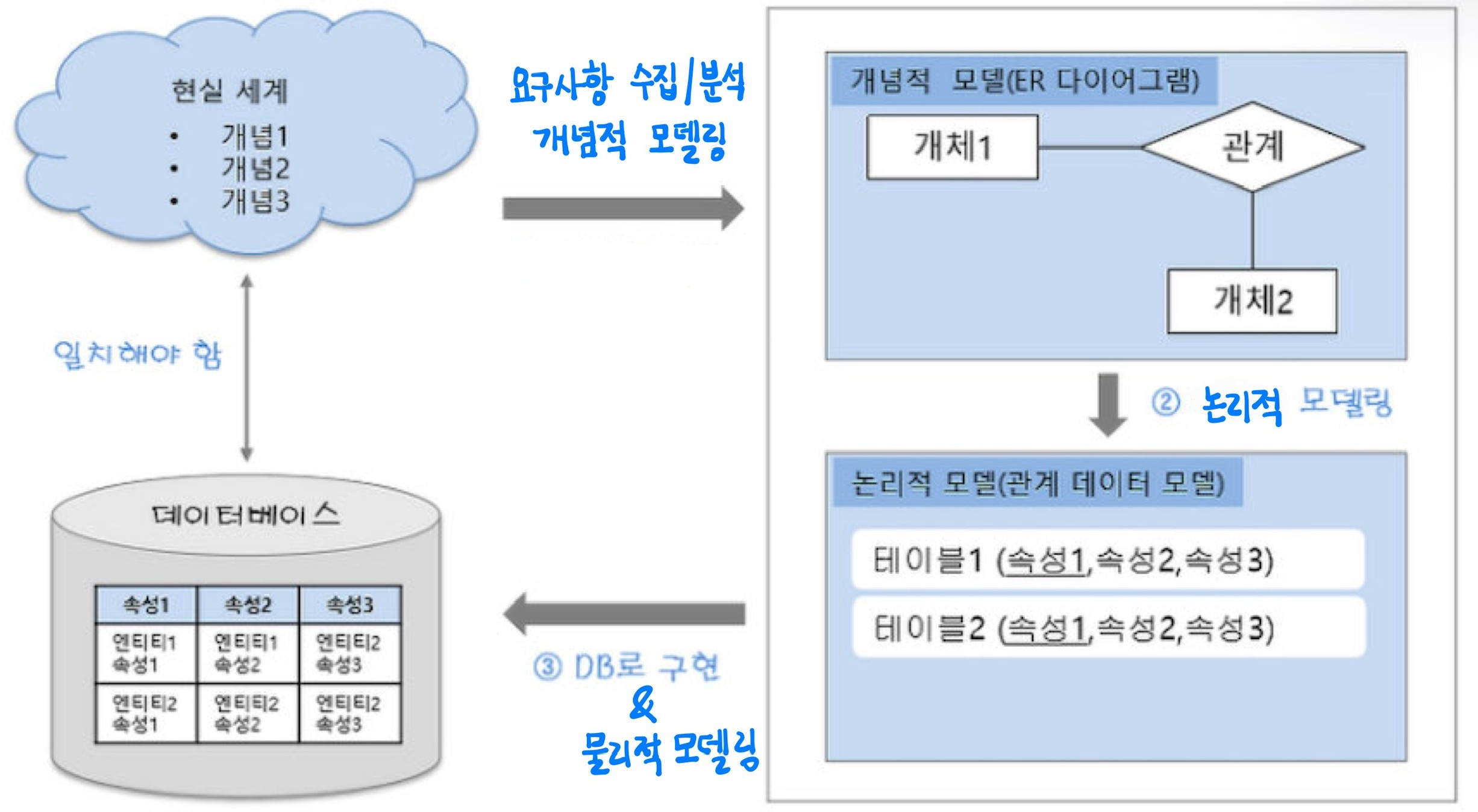
1️⃣ 데이터 모델링
비즈니스에서 수집하고 생성하는 각기 다른 모든 데이터를 분석하고 정의하는 것은 물론
데이터 간의 관계도 분석하고 정의하는 프로세스
→ 이렇게 분석된 모델을 가지고 실제 데이터베이스를 생성하여 개발 및 데이터 관리에 사용함
1. 요구사항 수집 및 분석
어떤 데이터를 모델링할 것인지에 대한 요구사항 수집 및 분석
2. 개념적 모델링
전체 모델에서 중요한 골격이 되는 엔티티와 관계 위주로 모델링
→ 각 개체들과 개체 간의 관계를 표현하기 위해 ERD 다이어그램을 생성함
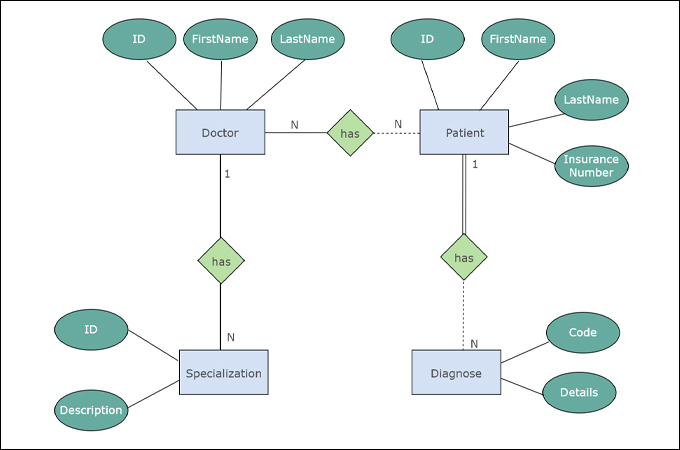
3. 논리적 모델링
개념적 모델링에서 추출된 개체와 개체들의 관계를 구조적으로 설계하는 단계
- 데이터에 대한 Key, 속성, 관계 등을 표시하며, 정규화 활동을 수행함
- 정규화를 통해 데이터모델의 일관성을 확보하고 중복을 제거하여 신뢰성 있는 데이터 구조를 얻을 수 있음
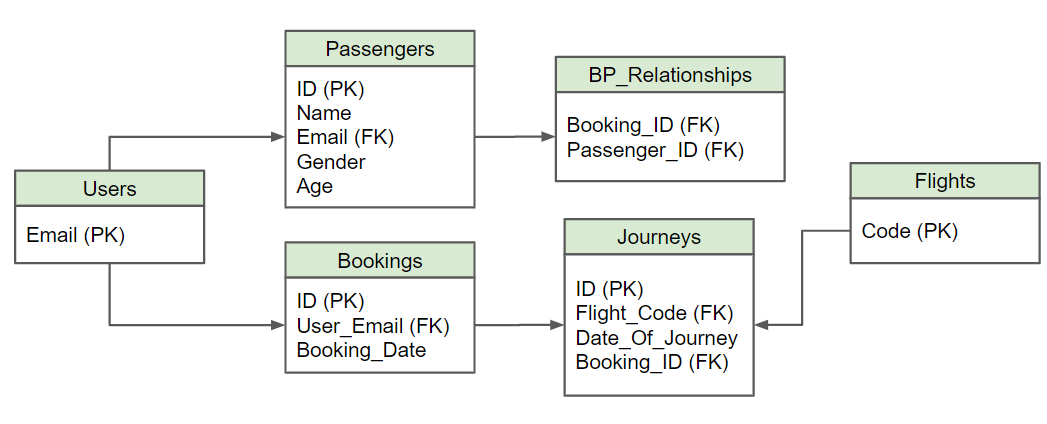
4. 물리적 모델링
최종적으로 데이터를 관리할 데이터베이스를 선택하고, 논리적 모델을 특정 데이터베이스로 설계함 (실제 저장 공간, 분산, 저장 방법 등까지도 고려)
-> 논리 모델을 각 DBMS의 특성에 맞게 데이터 베이스 저장 구조(물리 데이터 모델)로 변환
5. 코딩을 통해 실제 DB로 구현
ERD (Entity Relationship Diagram)
Entity(개체)와 Relationship(관계)를 중점적으로 표시함으로써 데이터베이스 구조를 한 눈에 알아볼 수 있게 하는 다이어그램
ERD 표기법은 크게 Peter-Chen 표기법과 까마귀 발 표기법으로 나눌 수 있음
- Peter Chen 표기법
- 흔히 대학교에서 배우는 ERD 표기법으로 실무에서는 보통 사용되지 않음
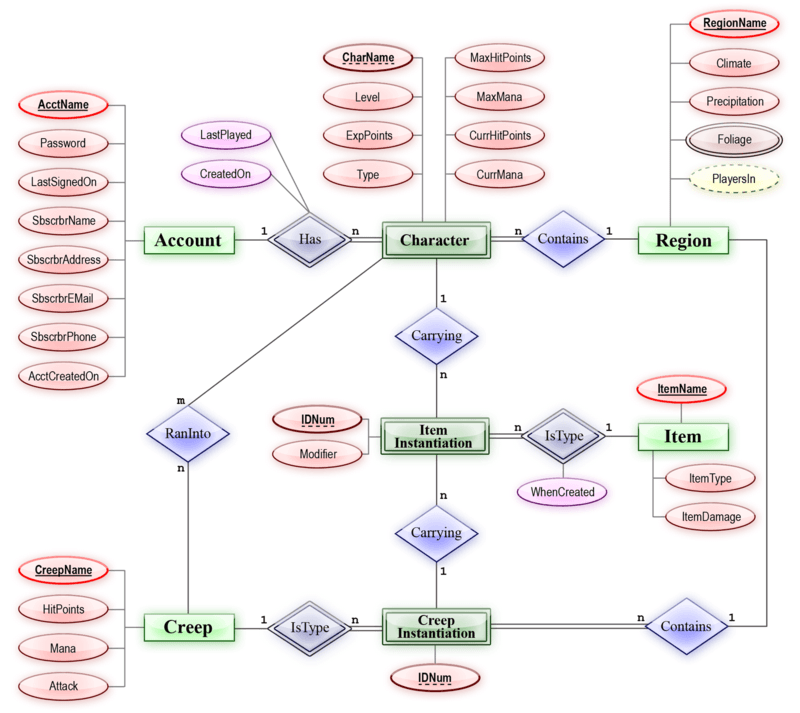
- 까마귀 발 표기법
- 표기 방법이 까마귀의 발을 닮았다고 하여 붙여진 이름
- 실무에서 가장 많이 사용되는 방식으로 IE 표기법, Barker 표기법 등이 있음
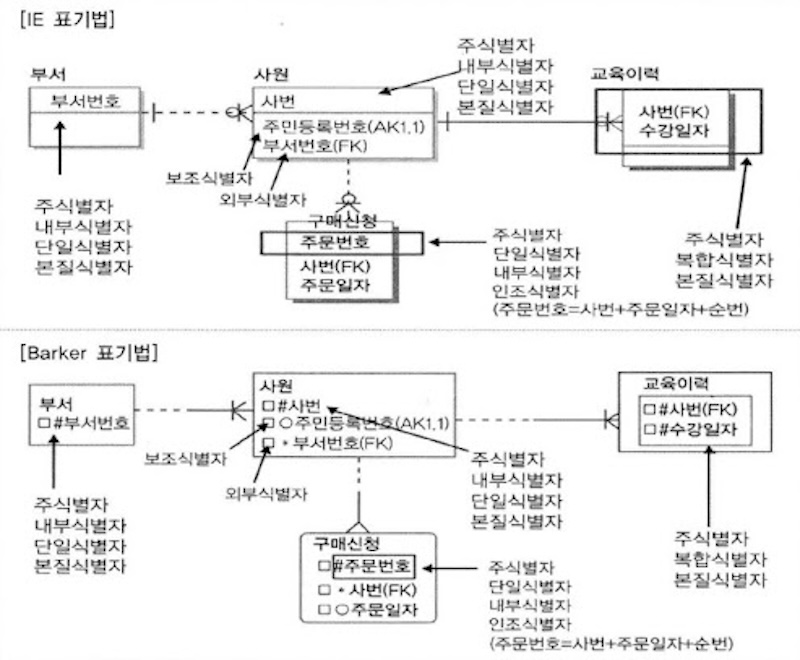
엔티티
정의 가능한 사물 또는 개념(사람, 도서 정보 등) → 데이터베이스의 테이블이 엔티티로 표현됨
- IE 표기법 : 직사각형에 Entity 의 이름을 상단에 표기함
- Barker 표기법 : 꼭지점이 둥근 형태인 Soft Box로 표기함, 엔티티 이름은 박스 상단에 표기
속성(Attribute)
- IE 표기법 : 엔티티 이름 하단 좌측에/속성 옆에 괄호로 PK, FK 등의 정보를 표기하고, 우측에는 어트리뷰트의 이름을 표기
- Barker 표기법 : 식별자&필수 입력='#'로 표기, 일반 속성&필수 입력='*'로 표기, 일반 속성&선택적 입력='o'로 표기
도메인(Domain)
개념적 모델링 단계이기 때문에 도메인 작성은 선택적임!
릴레이션
💡 식별자 vs 키
식별자는 논리적 모델링 관점으로 여러 개의 집합체를 담고 있는 하나의 통(엔티티)에서 각각을 구분할 수 있는 논리적인 이름
키는 물리적 모델링 관점으로 데이터베이스 테이블에 접근하는 물리적 매개체
식별자 관계와 비식별자 관계
- 식별자 관계 (실선)
부모 엔티티의 기본키/유니크키를 자식 엔티티의 기본키로 사용하는 관계 -> 자식 엔티티는 부모 엔티티가 존재해야 존재할 수 있음
ex) 학생과 성적 간 관계 (성적 데이터는 학생이 존재해야 존재할 수 있음)
- 비식별자 관계 (점선)
부모 엔티티의 기본키/유니크키를 자식 엔티티의 외래키로 사용하는 관계 -> 자식 엔티티는 부모 엔티티의 존재유무와 관계 없이 독립적으로 존재할 수 있음
ex) 학생과 과목 간 관계 (수강하는 학생이 없어도 과목은 독립적으로 존재할 수 있음)
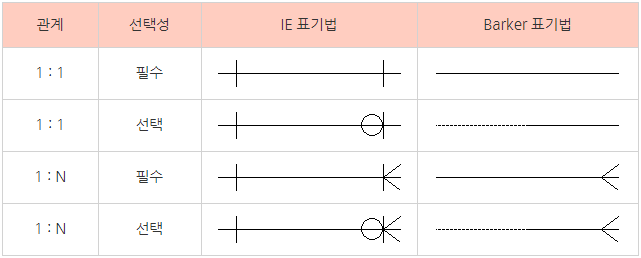
카디널리티
관계가 존재하는 두 엔티티 사이 관계 → 한 엔티티에서 다른 엔티티의 몇 개의 개체와 대응되는지 제약조건을 선을 그어 표기함
- One to One (1대 1)
- One to Many (1대 N)
- Many to Many (M대 N)
참고로 두 엔티티가 다대다 관계일 경우, 두 개의 엔티티만으로는 서로를 표현하는데 부족함
데이터모델링에서는 M대N 관계를 완성되지 않은 모델로 간주하여, 두 엔티티의 관계를 1:N, N:1로 조정하는 작업이 필요함
즉 두 엔티티의 관련성을 표현하기 위해서는 중간에 또 다른 엔티티를 필요로 하며, 이 중간 엔티티가 두 엔티티의 공유 속성 역할을 하게 됨
참여도
- IE 표기법 : ‘|’ 표시가 있는 곳은 반드시 있어야 하는 필수 엔티티, ‘O’ 표시가 있다면 없어도 되는 선택 엔티티
- Barker 표기법 : 필수 엔티티는 실선으로, 선택 엔티티는 점선으로 표기
2️⃣ 키(Key)
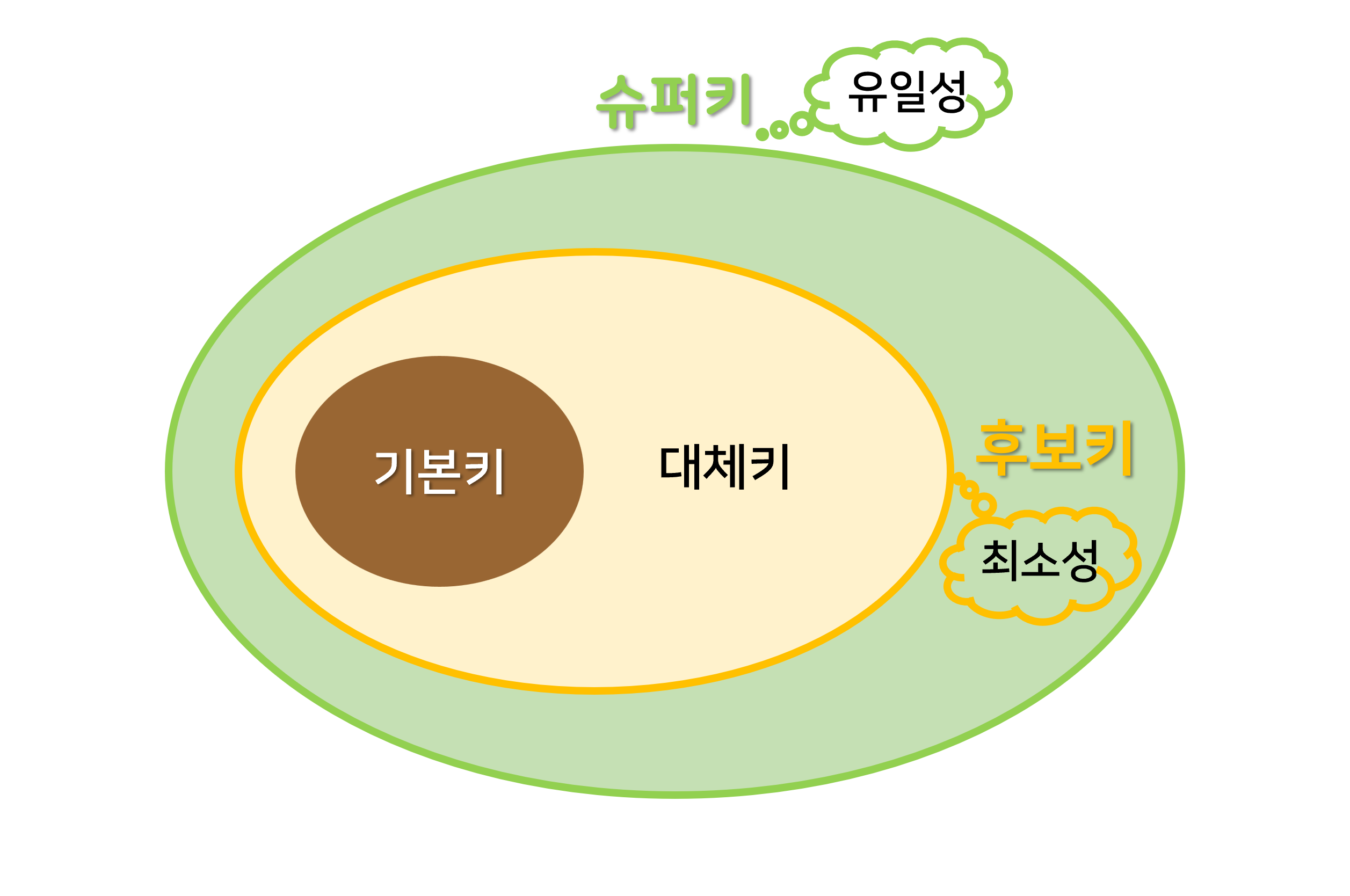
기본키(Primary Key)
- 유일성과 최소성을 만족하는 키, 줄어서 PK라고 표시함
- Null 값 허용하지 않음
- 테이블에 특정 레코드를 구별하기 위해 후보키 중 선택된 고유한 식별자
자연키(Natural Key)
ex)
유저 테이블을 만든다고 가정하면 주민번호, 이름, 성별 등의 속성이 있음
이름, 성별은 중복값이 들어올 수 있으므로 부적절하고 남는 것은 주민등록번호가 됨
이런식으로 중복값을 제외하며 중복되지 않는 것을 ‘자연스레’ 뽑다가 나오는 속성으로 기본키를 정한다고 해서 이 키를 자연키라고 표현함
자연키는 사용자에게 입력받는 정보이므로 언젠가 변할 가능성이 있음
인조키(Artificial Key)
ex)
위 상황에서 주민등록번호를 사용하지 않고 인위적으로 유저 아이디를 부여하여 고유 식별자를 생성할 경우, 이 키를 인조키라고 함
Oracle dml sequence, MySQL의 auto increment 등으로 설정함
인조키는 변하지 않으며, 참여자(데이터)가 몇 명이든 그들을 구분할 수 있음
보통 자연키보다는 인조키를 기본키로 설정하는 것을 권장함
복합키(Composite Key)
- 두 개 이상의 칼럼을 묶어서 하나의 기본키로 지정하는 것
유니크 키(Unique Key)
- 특정 컬럼에 유니크 속성을 부여한 것을 유니크 키라고 표현함
- null을 허용함
- 하나의 테이블에 컬럼마다 지정이 가능함 (PK는 오직 하나)
- 기본키가 유니크 키의 성질을 포함하는 것
외래키(Foreign Key)
- FK라고도 하며, 다른 테이블의 기본키를 그대로 참조하는 값
- 개체와의 관계를 식별하는 데 사용
- 테이블A가 테이블B를 참조할 때, A의 외래키는 B의 레코드를 유일하게 식별할 수 있어야 함
- 하나의 필드 또는 전체 필드의 부분집합으로 중복값이나 Null 값을 가질 수 없음
후보키(Candidate Key)
- 기본키가 될 수 있는 후보들
- 유일성과 최소성을 동시에 만족하는 키
- 대체키(Alternate Key): 후보키가 2개 이상일 경우 기본키로 지정 후 남은 키
슈퍼키(Super Key)
- 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키
- 테이블 내 필드 전체의 부분집합 중 레코드를 유일하게 식별해 낼 수 있는 속성 또는 속성 집합
참고자료
https://hanamon.kr/관계형-데이터베이스-설계-관계-종류/
TOPCIT ESSENCE ver3 기술영역 - 데이터 이해와 활용
[책]면접을 위한 CS전공지식 노트
https://velog.io/@kw78999/DB-바커와-IE-표기법
https://multifrontgarden.tistory.com/180
https://velog.io/@hanblueblue/UML-UML-기초
https://lotuus.tistory.com/43
면접질문참고 : https://hyonee.tistory.com/41
https://velog.io/@kon6443/DB-기본키-외래키-후보키-복합키-개념-4x1bgz5w https://unluckyjung.github.io/db/2020/11/16/PrimaryKey_VS_Unique/
https://jjeongil.tistory.com/1234
https://snepbnt.tistory.com/68
https://im-codding.tistory.com/59
https://sabarada.tistory.com/72
