
1️⃣ ORM이란
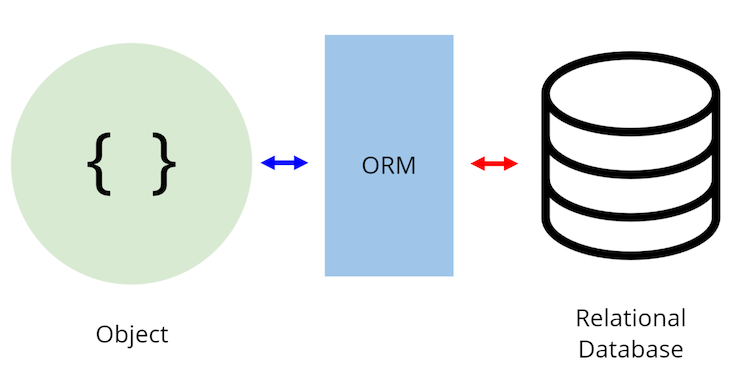
Object Relational Mapping(객체-관계 매핑)의 약자로, 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 것을 말함
- 객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용함 → 객체 모델과 관계형 모델 간 불일치가 존재하게 됨
- ORM을 통해 객체 간의 관계를 바탕으로 SQL을 자동으로 생성하여 불일치를 해결함
ex)
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=50)
body = models.CharField(max_length=1200)
위 코드를 실행하면 자동으로 아래와 같은 테이블이 생성됨
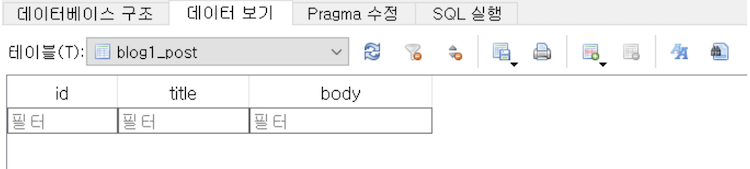
장고가 ORM으로 자동으로 아래와 같은 쿼리를 생성해서 실행했기 때문!
CREATE TABLE "blog1_post" (
"id" integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"title" varchar(50) NOT NULL,
"body" varchar(1200) NOT NULL
)객체와 테이블 사이의 불일치?
- 세분성
- 경우에 따라 데이터베이스에 있는 해당 테이블 수보다 객체 모델이 더 많은 클래스를 가질 수 있음
- 예를 들어, 사용자 세부사항에서
- 코드 재사용과 유지보수를 위해 Person과 Address라는 두 개의 클래스로 나눌 수 있음
- 그러나 데이터베이스에는 person이라는 하나의 테이블에 사용자 세부사항을 저장할 수 있음
- 상속
- RDBMS에는 객체지향 프로그래밍 언어의 ‘상속’ 개념이 존재하지 않음
- 일치
- RDBMS에서는 PK가 같으면 서로 동일한 record로 정의하지만, Java에서는 주소값이 같거나(==) 내용이 같은 경우(equals())를 구분하여 정의함
- 연관성
- 객체지향 언어는 객체 참조로 연관성을 나타내는 반면, RDBMS는 연관성을 ‘외래키’로 나타냄
// Java에서의 객체 참조 -> 방향성이 존재
public class Employee {
private int id;
private String first_name;
private Department department; // Department 객체를 참조함
...
}
// Employee -> Department
// 자바에서 양방향 관계가 필요한 경우, 연관을 두 번 정의해야 함 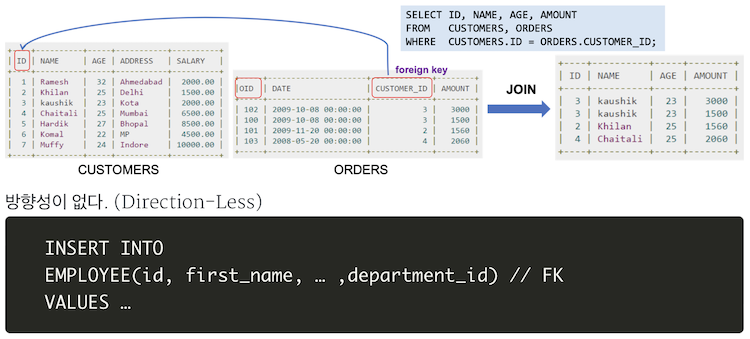
- 탐색/순회
- 객체지향 언어와 RDBMS에서 객체에 액세스하는 방법은 근본적으로 다름
- Java에서는 하나의 연결에서 다른 연결로 이동하면서 탐색/순회함 (그래프 형태)
- 예를 들어, aUser.getBillingDetails().getAccountNumber()
- RDBMS에서는 일반적으로 SQL 쿼리 수를 최소화하고 JOIN을 통해 여러 엔티티를 로드하고 원하는 대상 엔티티를 선택함
ORM 프레임워크 종류
ORM을 구현하기 위한 구조와, 구현을 위해 필요한 여러 기능들을 제공하는 소프트웨어
- JAVA(JPA) : Hibernate, EclipseLink, DataNucleus 등
- JPA는 자바 진영에서 ORM 기술 표준으로 사용되는 인터페이스의 모음으로, JPA를 구현한 대표적인 오픈소스로는 Hibernate가 있음
- C++ : ODB, QxOrm 등
- Python : Django, SQLAlchemy, Storm 등
- iOS : DatabaseObjects, Core Data 등
- .NET : NHibernate, DatabaseObject, Dapper 등
- PHP : Doctrine, Propel, RedBean 등
ORM의 장단점
- 장점
- 객체지향적인 코드로 인해 더 직관적이고 비즈니스 로직에 더 집중할 수 있게 도와줌
- ORM을 이용하면 SQL Query가 아닌 직관적인 코드(메소드)로 데이터를 조작할 수 있어, 개발자가 객체 모델로 프로그래밍하는 데 집중할 수 있도록 도와줌
- 각종 객체에 대한 코드를 별도로 작성하기 때문에 코드의 가독성을 올려줌
- SQL의 절차적이고 순차적인 접근이 아닌 객체 지향적인 접근으로 인해 생산성이 증가함
- 재사용 및 유지보수의 편리성이 증가함
- ORM은 독립적(하나의 클래스)으로 작성되어 있고, 해당 객체들을 재활용할 수 있음
- 때문에 모델에서 가공된 데이터를 컨트롤러에 의해 뷰와 합쳐지는 형태로 디자인 패턴을 견고하게 다지는데 유리함
- 매핑정보가 명확하여, ERD를 보는 것에 대한 의존도를 낮출 수 있음
- ORM은 독립적(하나의 클래스)으로 작성되어 있고, 해당 객체들을 재활용할 수 있음
- DBMS에 대한 종속성이 줄어듦
- 대부분 ORM 솔루션은 DB에 종속적이지 않음 → DBMS를 교체해야 하더라도 비교적 적은 리스크와 시간이 소요됨
- 자바에서 가공할 경우(JPA를 사용할 경우), equals, hashCode의 오버라이드 같은 자바의 기능을 이용할 수 있고, 간결하고 빠른 가공이 가능함
- 객체지향적인 코드로 인해 더 직관적이고 비즈니스 로직에 더 집중할 수 있게 도와줌
- 단점
- ORM은 프레임워크가 자동으로 SQL을 작성하기 때문에, 의도대로 SQL이 작성되었는지 확인할 필요가 있음(즉, SQL을 알고 있어야 함)
- 완벽히 ORM으로만 서비스를 구현하기 어려움
- 사용하기는 편하지만 설계는 매우 신중하게 해야함 (프로젝트의 복잡성이 커질 경우 난이도가 올라감)
- 잘못 구현된 경우, 속도 저하 및 일관성이 무너지는 문제점이 발생할 수 있음
- 일부 자주 사용되는 대형 쿼리는 속도를 내기 위해 SP를 쓰는 등 별도의 튜닝이 필요할 수 있음
- 프로시저가 많은 시스템에서는 ORM의 객체 지향적인 장점을 활용하기 어려움
- 이미 프로시저가 많은 시스템에선 다시 객체로 바꿔야하며, 그 과정에서 생산성 저하나 리스크가 많이 발생할 수 있음
2️⃣ JPA란
Java Persistence API의 약자로, 자바 진영의 ORM 기술 표준으로 채택된 인터페이스의 모음
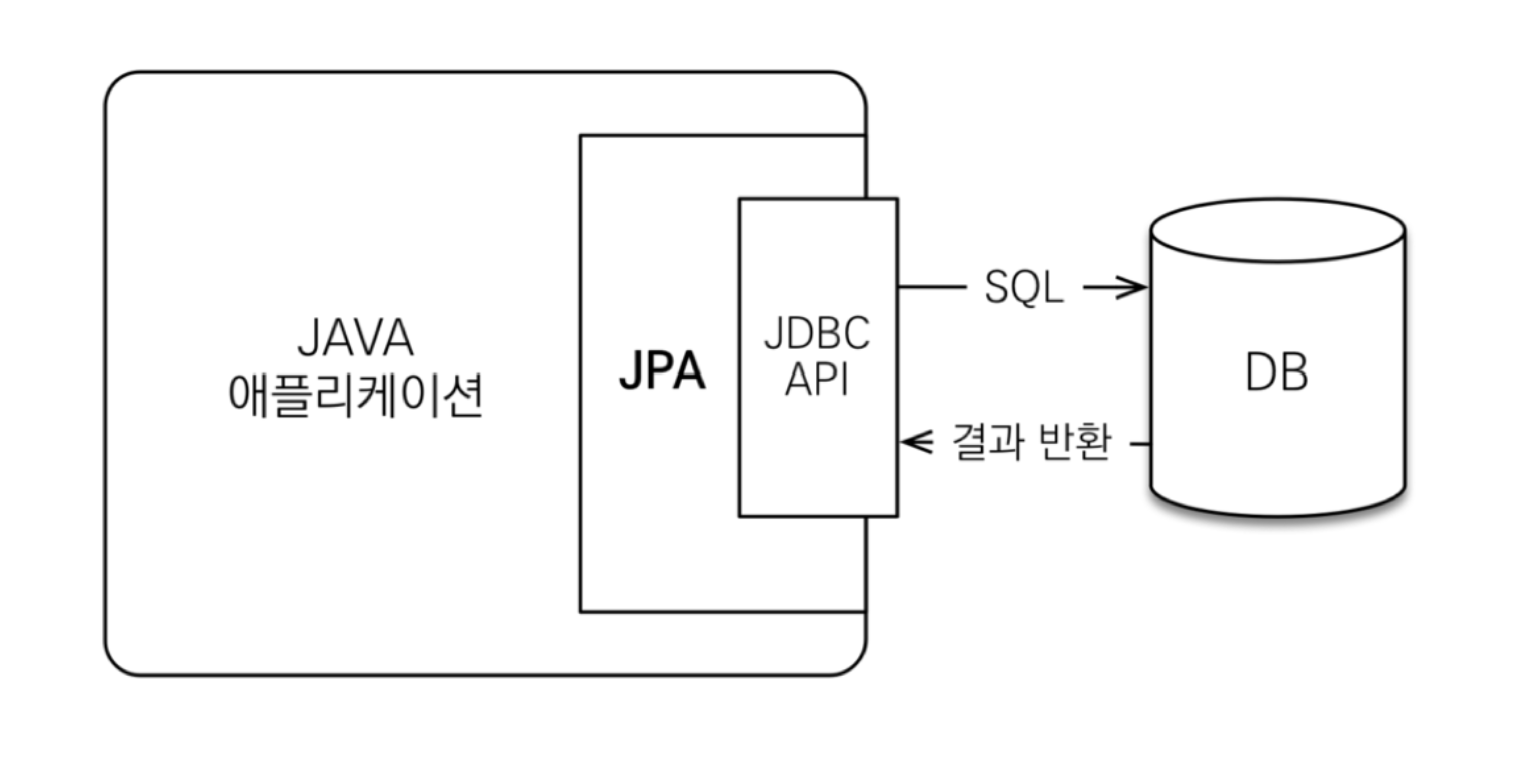
❓ JDBC (Java Database Connectivity)
자바 기반 애플리케이션의 데이터를 DB에 저장 및 업데이트하거나, DB에 저장된 데이터를 자바에서 사용할 수 있도록 하는 자바 API
- JPA는 JDBC를 통해 DB와 통신함
- JDBC가 JPA보다 훨씬 오래된 버전임 (JPA의 이전 버전?)
https://stackoverflow.com/questions/11881548/jpa-or-jdbc-how-are-they-different
JPA 기반의 구현체는 대표적으로 세 가지가 있음
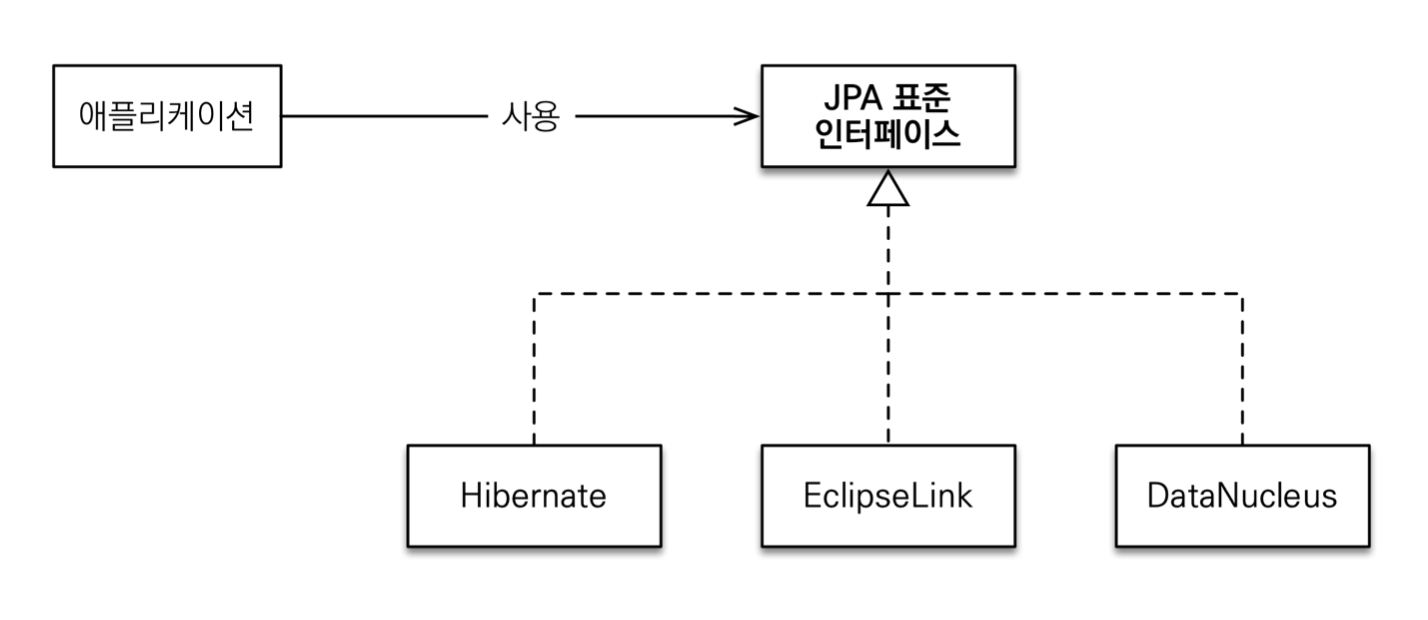
가장 많이 사용되는 구현체는 하이버네이트이다!
Spring Data JPA
JPA를 사용하기 편하도록 만들어놓은 모듈
- CRUD 처리에 필요한 인터페이스를 제공함
- 하이버네이트의 엔티티 매니저를 직접 다루지 않고 'Repository'를 정의해 사용함으로써 스프링이 적합한 쿼리를 동적으로 생성하는 방식으로 데이터를 조작함
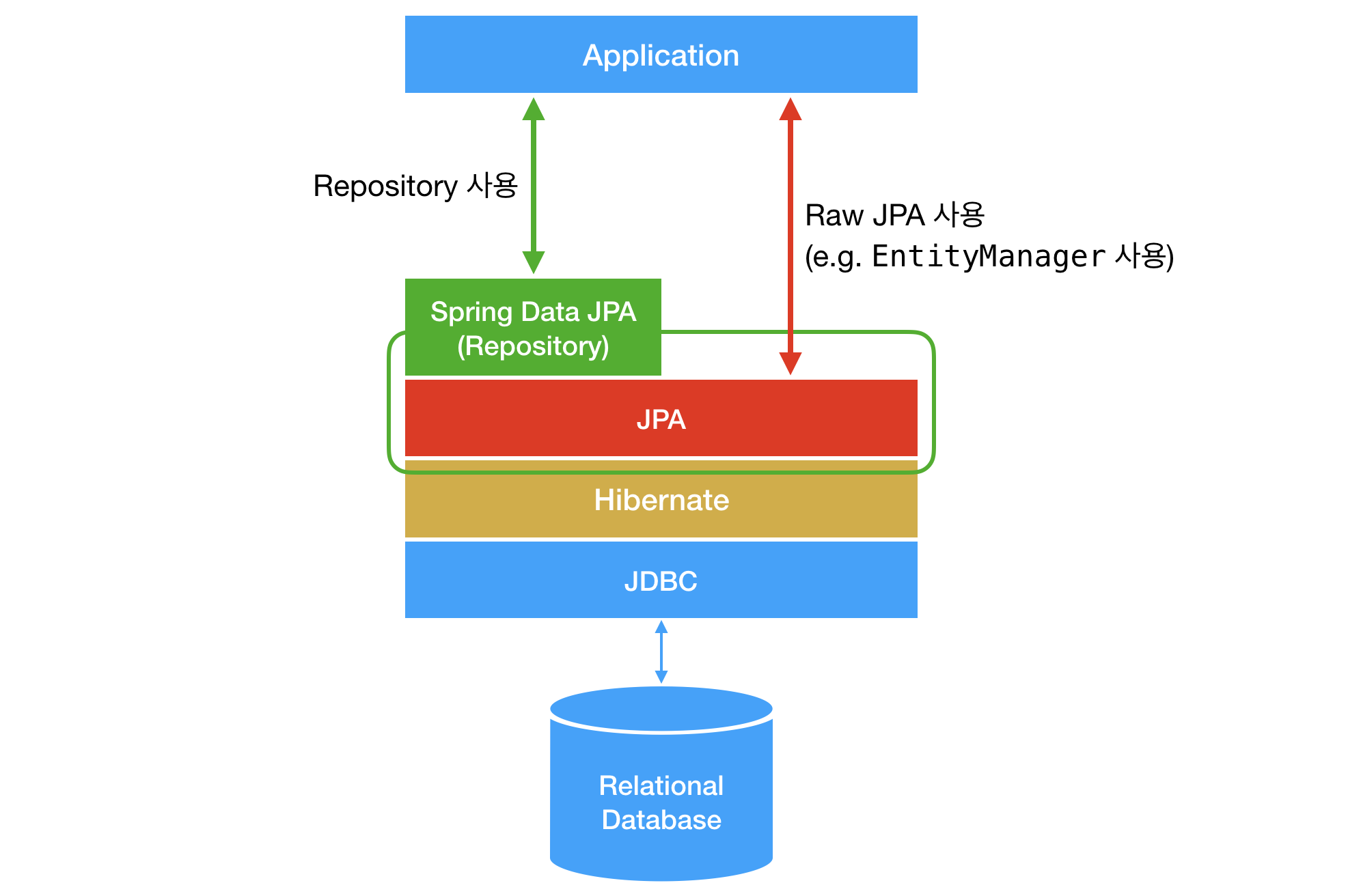
리포지토리는 아래와 같이 JpaRepository를 상속받음
public interface ItemRepository extends JpaRepository<Item, Long>, ItemRepositoryCustom { ... }
따라서 생성된 리포지토리는 아래와 같은 많은 기능을 별도의 메서드 구현 없이도 사용할 수 있음
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> saveAll(Iterable<S> entities);
void flush();
...
}3️⃣ 영속성 컨텍스트
엔티티를 영구 저장하는 환경이라는 뜻으로, 애플리케이션과 DB 사이에서 객체를 보관하는 가상의 데이터베이스 같은 역할을 함
영속성 컨텍스트는 엔티티 관리 개념이고, 이 개념은 하이버네이트 같은 구현체에서 매우 복잡하게 구현되어 있음
- 개발자는 엔티티 매니저를 통해서 영속성 컨텍스트에 접근할 수 있음
- 즉, 엔티티 매니저를 통해 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리하게 됨
Spring Data JPA를 사용하면, 리포지토리를 사용해서 데이터베이스에 접근하는데
실제 내부 구현체인 SimpleJpaRepository가 아래와 같이 리포지토리에서 엔티티 매니저를 사용하는 것을 알 수 있음
public SimpleJpaRepository(JpaEntityInformation<T, ?> entityInformation,
EntityManager entityManager) {
Assert.notNull(entityInformation, "JpaEntityInformation must not be null!");
Assert.notNull(entityManager, "EntityManager must not be null!");
this.entityInformation = entityInformation;
this.em = entityManager;
this.provider = PersistenceProvider.fromEntityManager(entityManager);
}- 영속성 컨텍스트는 엔티티 매니저를 생성할 때 하나 만들어짐
- 영속성 컨텍스트는 엔티티를 식별자값(DB의 기본키)으로 구분하므로, 영속 상태는 식별자 값이 반드시 있어야 함
엔티티의 생명주기
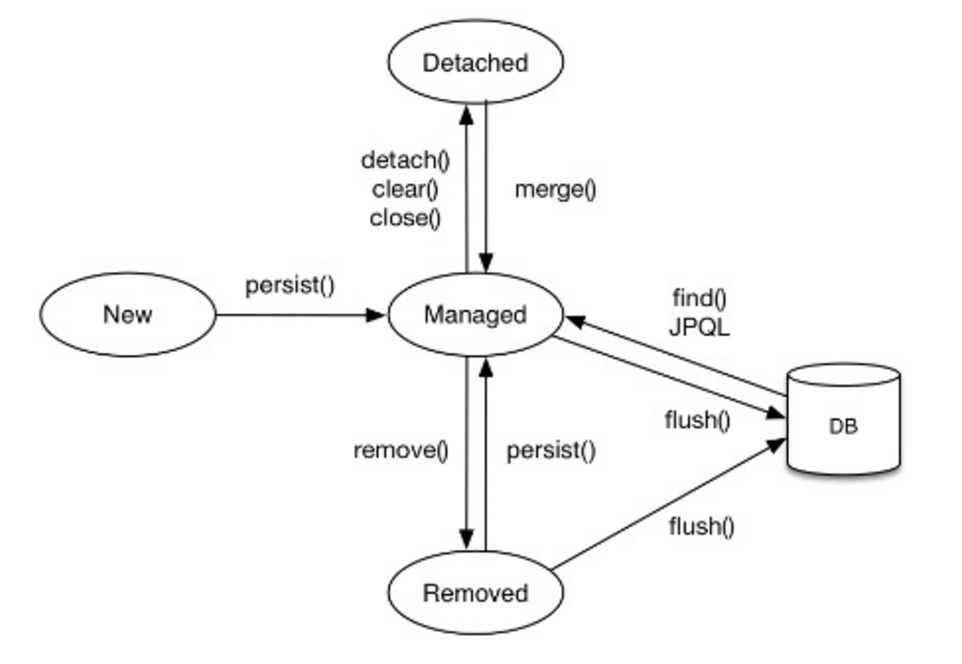
- 비영속(New)
- 엔티티 객체를 생성했지만 아직 영속성 컨텍스트에 저장되지 않은 상태
Member member = new Member();- 영속(Managed)
- 영속성 컨텍스트에 저장된 상태로, 영속성 컨텍스트에 의해 관리됨
em.persist(member);- 준영속(Detached)
- 영속성 컨텍스트에 의해 관리되었다가, 더이상 관리되지 않은 상태
- 1차 캐시, 쓰기 지연, 변경 감지, 지연 로딩을 포함한 영속성 컨텍스트가 제공하는 어떠한 기능도 동작하지 않음
- 식별자 값을 가지고 있음
// 엔티티를 영속성 컨텍스트에서 분리해 준영속 상태로 만든다.
em.detach(member);
// 영속성 콘텍스트를 비워도 관리되던 엔티티는 준영속 상태가 된다.
em.claer();
// 영속성 콘텍스트를 종료해도 관리되던 엔티티는 준영속 상태가 된다.
em.close();- 삭제(Removed)
- 엔티티를 영속성 컨텍스트와 DB에서 삭제함
em.remove(member);영속성 컨텍스트의 특징
- 1차 캐시
- 영속성 컨텍스트 내부에는 캐시가 있는데 이를 1차 캐시라고 하며, 영속 상태의 엔티티를 이곳에 저장함
- 1차 캐시의 Key는 식별자 값이고, Value는 엔티티 인스턴스임
- 조회하는 방법
- 1) 1차 캐시에서 엔티티를 찾음
- 2) 있으면 메모리에 있는 1차 캐시에서 엔티티를 조회함
- 3) 없으면 데이터베이스에서 조회함
- 4) 조회한 데이터로 엔티티를 생성해 1차 캐시에 저장함 (엔티티를 영속 상태로 만듦)
- 5) 조회한 엔티티를 반환함
// em.find(엔티티 클래스 타입, 식별자 값);
Member member = em.find(Member.class, "member1");
- 영속성 컨텍스트의 동일성 보장
- 영속성 컨텍스트는 엔티티의 동일성(주소값과 내용이 모두 같음)을 보장함
Member a = em.find(Member.class, "member1");
Member b = em.find(Member.class, "member1");
System.out.print(a==b) // true
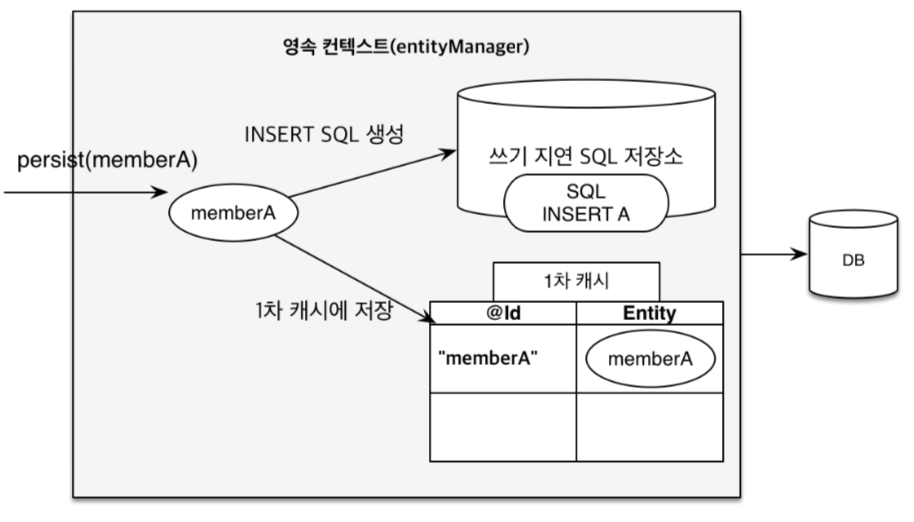
- 트랜잭션을 지원하는 쓰기 지연
- 여러 개의 엔티티를 생성하고 persist()를 하더라도, commit()을 하기 전에는 DB에 저장되지 않음
- 즉, commit()을 해야 DB에 INSERT SQL을 보내 DB에 저장하는 것
- persist()를 실행할 때, 영속성 컨텍스트의 1차 캐시에는 member 엔티티가 저장되고, 쓰기 지연 SQL 저장소에는 member 엔티티의 INSERT SQL 쿼리문이 저장됨
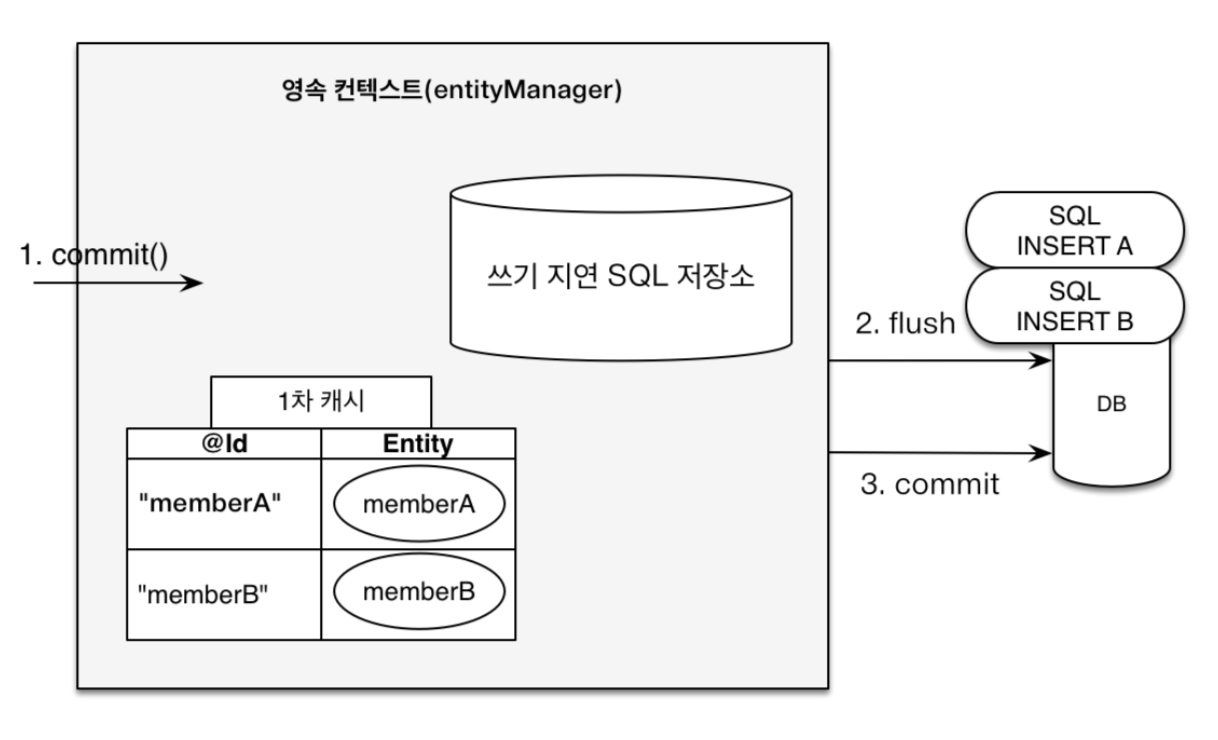
- 변경 감지 (Dirty Checking)
- 영속성 컨텍스트는 변경 감지 기능을 제공하기 때문에, 엔티티의 수정은 set 메서드를 통해서 변경한 뒤, 별다른 로직 없이 트랜잭션 커밋을 하는 순간 업데이트 됨
- 변경 감지의 흐름
- 1) 트랜잭션을 커밋하면 엔티티 매니저 내부에서 flush()가 호출됨
- 2) 엔티티와 스냅샷을 비교하여 변경된 엔티티를 찾음
- 3) 변경된 엔티티가 있다면, UPDATE 쿼리를 생성하여 쓰기 지연 SQL 저장소에 저장함
- 4) 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송함 (flush 과정)
- 5) 데이터베이스 트랜잭션을 커밋함
flush는 쓰기 지연 SQL 저장소에 있는 쿼리를 DB에 반영하는 행위로,em.flush()는 위의 2~4번을 모두 포함하는 과정임
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin();
Member member = em.find(Member.class, "member1");
member.setName("노영삼");
transaction.commit();
5️⃣ SQL Mapper
Object와 SQL의 필드를 매핑하여 데이터를 객체화 하는 기술
참고자료
https://gmlwjd9405.github.io/2019/02/01/orm.html
https://lipcoder.tistory.com/366
https://tibetsandfox.tistory.com/17
https://thisisprogrammingworld.tistory.com/132
도서 '스프링부트 핵심 가이드'
https://velog.io/@yebali/Spring-Data-JPA%EB%9E%80
https://www.inflearn.com/questions/246769/영속성-컨텍스트에-관한-질문입니다
https://velog.io/@neptunes032/JPA-영속성-컨텍스트란
https://ittrue.tistory.com/254
https://www.inflearn.com/questions/351605/55초-x27-플러시-발생-x27-관련-문의-드립니다
