
개요
Elasticsearch프로젝트는 Logstash, Kibana와 함께 사용 되면서 한동안 ELK Stack (Elasticsearch, Logstash, Kibana) 이라고 널리 알려지게 된 Elastic은 2013년에 Logstash, Kibana 프로젝트를 정식으로 흡수하여 한 지붕 아래에서 함께 개발을 해 나가고 있습니다. 2015년에는 회사명을 Elasticsearch 에서 Elastic으로 변경 하고, ELK Stack 대신 제품명을 Elastic Stack이라고 정식으로 명명하면서 모니터링, 클라우드 서비스, 머신러닝 등의 기능을 계속해서 개발, 확장 해 나가고 있습니다.
Elasticsearch
Elastic 홈페이지에서는 Elasticsearch를 Elastic Stack의 심장이라고 소개하고 있는 만큼 Elasticsearch는 전체 스택의 중심이며 가장 중요한 역할을 하고 있습니다. 기본적으로 모든 데이터를 색인하여 저장하고 검색, 집계 등을 수행하며 결과를 클라이언트 또는 다른 프로그램으로 전달하여 동작하게 합니다. Elasticsearch는 뛰어난 검색 능력과 대규모 분산 시스템을 구축할 수 있는 다양한 기능들을 제공하지만, 설치 과정과 사용 방법은 비교적 쉽고 간편합니다.

오픈소스 (open source)
Elasticsearch의 핵심 기능들은 Apache 2.0 라이센스로 배포되고 있고 Elastic Stack의 모든 제품들은 (https://github.com/elastic) 깃헙 리파지토리 에서 소스들을 찾을 수 있습니다. 6.3 버전 부터는 Elastic 라이센스와 Apache 라이센스가 섞여 있지만 각각의 버전에 대해 별도 배포판이 존재하고 license 파일에서 어떤 경로의 파일들이 어떤 라이센스로 되어 있는지 확인이 가능합니다.
루씬이 자바로 만들어졌기 때문에 Elasticsearch도 마찬가지로 자바로 코딩이 되어 있습니다. 루씬은 하둡을 개발한 더그 커팅(Doug Cutting)에 의해 처음 만들어졌지만 Elasticsearch 엔지니어들 중에는 루씬 커미터들이 다수 있어서 루씬을 매우 깊은 레벨에서 다루고 있습니다.
실시간분석(real-time)
Elasticsearch의 가장 큰 특징 중 하나는 실시간(real-time) 분석 시스템 입니다. 현재 대용량 데이터 분석에 가장 널리 사용되고 있는 것은 하둡(Hadoop) 플랫폼 위에서 실행되는 Pig, Hive와 같은 다양한 맵 리듀서(Map reducer) 들입니다.
하둡은 기본적으로 배치 기반의 분석 시스템으로 분석에 사용될 소스 데이터, 분석을 수행 할 프로그램을 올려 놓고 분석을 실행하여 결과 셋이 나오도록 하는 하나의 루틴으로 실행됩니다.
Elasticsearch는 하둡 시스템과 달리 Elasticsearch 클러스터가 실행되고 있는 동안에는 계속해서 데이터가 입력 (검색엔진에서는 색인 – indexing 이라고 표현합니다) 되고, 그와 동시에 실시간에 가까운 (near real-time) 속도로 색인된 데이터의 검색, 집계가 가능합니다.
(하둡은 리얼타임 데이터분석 X / Elasticsearch 리얼타임 데이분서 O)
전문(full text) 검색 엔진
루씬은 기본적으로 역파일 색인(inverted file index)라는 구조로 데이터를 저장합니다. 루씬을 사용하고 있는 Elasticsearch도 마찬가지로 색인된 모든 데이터를 역파일 색인 구조로 저장하여 가공된 텍스트를 검색합니다.. 이런 특성을 전문(full text) 검색이라고 합니다.
역색인, 역 인덱스(inverted index), 역 파일(inverted file)은
낱말이나 숫자와 같은 내용물로부터의 매핑 정보를 데이터베이스 파일의 특정 지점이나 문서 또는 문서 집합 안에 저장하는 색인 데이터 구조이다.
JSON 문서 기반 Elasticsearch는 내부적으로는 역파일 색인 구조로 데이터를 저장하고 있으나, 사용자의 관점에서는 JSON 형식으로 데이터를 전달합니다.
key-value 형식이 아닌 문서 기반으로 되어 있기에 복합적인 정보를 포함하는 형식의 문서를 있는 그대로 저장이 가능하며 사용자가 직관적으로 이해하고 사용할 수 있습니다. Elasticsearch에서 질의에 사용되는 쿼리문이나 쿼리에 대한 결과도 모두 JSON 형식으로 전달되고 리턴됩니다.
다만 JSON이 Elasticsearch가 지원하는 유일한 형식이기 사전에 입력할 데이터를 JSON 형식으로 가공하는 것이 필요합니다. CSV, Apache log, syslog등과 같이 널리 사용되는 형식들은 Logstash에서 변환을 지원하고 있습니다.
RESTFul API
현재 대규모 시스템들은 대부분 마이크로 서비스 아키텍처(MSA)를 기본으로 설계됩니다. 이러한 구조에 빠질 수 없는 것이 REST API와 같은 표준 인터페이스 입니다. Elasticsearch는 Rest API를 기본으로 지원하며 모든 데이터 조회, 입력, 삭제를 http 프로토콜을 통해 Rest API로 처리합니다.
멀티테넌시 (multitenancy)
Elasticsearch의 데이터들은 인덱스(Index) 라는 논리적인 집합 단위로 구성되며 서로 다른 저장소에 분산되어 저장됩니다. 서로 다른 인덱스들을 별도의 커넥션 없이 하나의 질의로 묶어서 검색하고, 검색 결과들을 하나의 출력으로 도출할 수 있는데, Elasticsearch의 이러한 특징을 멀티테넌시 라고 합니다.
Logstash
Logstash는 원래 Elasticsearch와 별개로 다양한 데이터 수집과 저장을 위해 개발된 프로젝트였습니다. 데이터의 색인, 검색 기능만을 제공하던 Elasticsearch는 데이터 수집을 위한 도구가 필요했는데, 때마침 Logstash가 출력 API로 Elasticsearch를 지원하기 시작하면서 많은 곳에서 Elasticsearch의 입력 수단으로 Logstash를 사용하기 시작했습니다.

Logstash는 JRuby로 되어 있습니다. 루비 코드로 개발되어 자바의 런타임 머신 위에서 돌아갑니다. Elasticsearch와 마찬가지로 Apache 2.0 라이센스를 따르고 있어 자유롭게 사용이 가능합니다. Logstash는 데이터 처리를 위해서 크게 다음과 같은 과정들을 거치게 됩니다.

입력 기능에서 다양한 데이터 저장소로부터 데이터를 입력 받습니다.
필터 기능을 통해 데이터를 확장, 변경, 필터링 및 삭제 등의 처리를 통해 가공을 합니다.
출력 기능을 통해 다양한 데이터 저장소로 데이터를 전송하게 됩니다.
Elasticsearch외에도 다양한 경로의 출력이 가능하기 때문에 Elasticsearch에 데이터를 색인하는 동시에 로컬 파일이나 아마존 AWS S3 저장소로 동시에 송출도 가능합니다. 그리고 Elasticsearch와 상관 없이 Redis의 데이터를 Kafka로 전송하는 경우 등과 같이 독자적으로 사용되기도 합니다.
(우리 프로젝트도 이상적인 아키텍처를 그릴 때 Kafka로 전송후에 보내려고 하였다. 데이터 손실을 줄이기 위해서)
Kibana
Kibana는 Elasticsearch를 가장 쉽게 시각화 할 수 있는 도구입니다. 검색, 그리고 aggregation의 집계 기능을 이용해 Elasticsearch로 부터 문서, 집계 결과 등을 불러와 웹 도구로 시각화를 합니다. Discover, Visualize, Dashboard 3개의 기본 메뉴와 다양한 App 들로 구성되어 있고, 플러그인을 통해 App의 설치가 가능합니다.

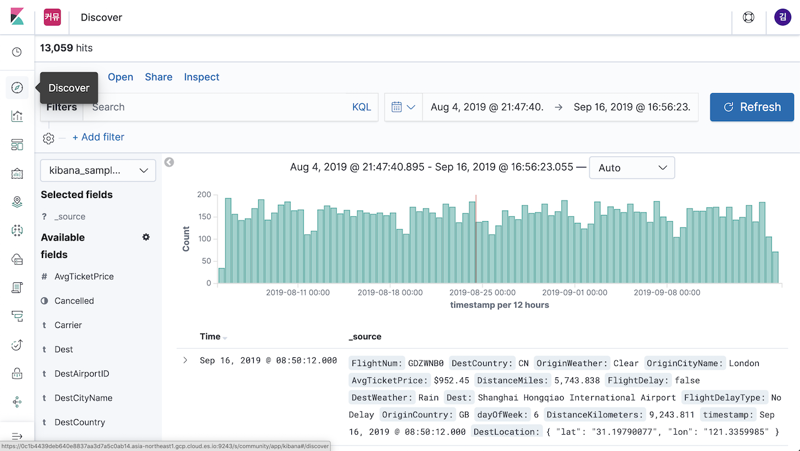
Discover
Discover는 Elasticsearch에 색인된 소스 데이터들의 검색을 위한 메뉴입니다. 검색 창에 질의문을 통해 데이터를 간편하게 검색, 필터링 할 수 있으며, 검색된 데이터의 원본 문서를 확인하거나 보고 싶은 필드만 선택해서 테이블 형태로 조회가 가능합니다. 시계열(time series) 기반의 로그 데이터인 경우 시간 히스토그램 그래프를 통해 시간대별 로그 수도 표시됩니다.
Visualize
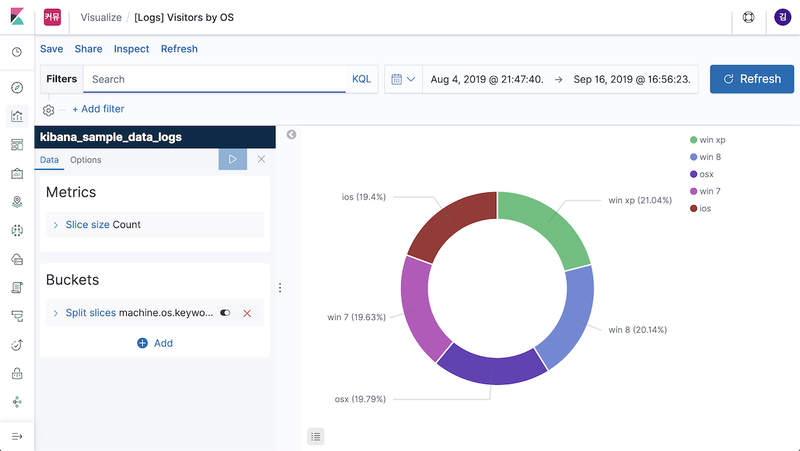
Visualize는 aggregation 집계 기능을 통해 조회된 데이터의 통계를 다양한 차트로 표현할 수 있는 패널을 만드는 메뉴입니다. 영역차트, 바차트, 파이차트, 라인차트 등 다양한 시각화 도구들의 사용이 가능하며 여기서 만들어진 패널들을 조합해서 대시보드를 만들게 됩니다.
Dashboard
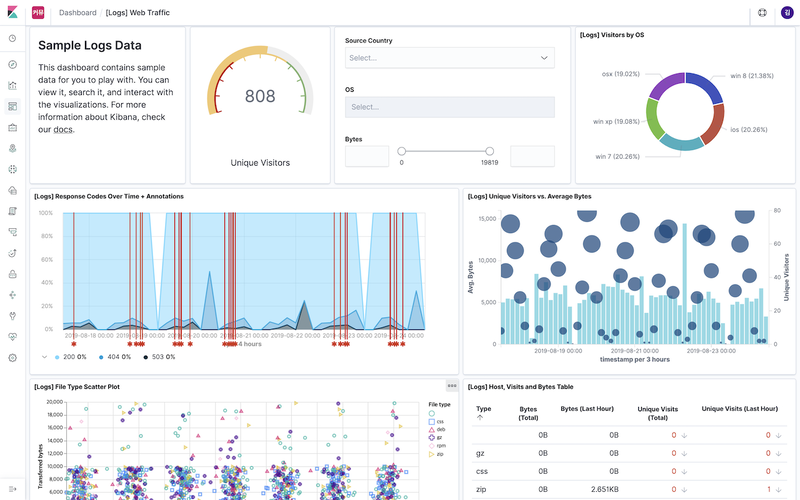
Visualize 메뉴에서 만들어진 시각화 도구들을 조합해서 대시보드 화면을 만들고 저장, 불러오기 등을 할 수 있는 메뉴입니다. 다른 메뉴들과 마찬가지로 검색 창에 쿼리를 입력하거나 시각화 도구들을 클릭해서 조회할 데이터들의 필터링이 가능하고, URL로 대시보드를 다른 사람들과 공유하거나 json 형식으로 내보내고 불러오기 등이 가능합니다.
Beats
Logstash가 데이터 수집기로서의 역할을 훌륭하게 해 내고 있지만 너무 다양한 기능 때문에 프로그램의 부피가 컸고 실행하는 데에 꽤 많은 자원을 필요로 했습니다. Elasticsearch 클러스터로의 대용량 데이터 전송은 보통 하나의 소스가 아닌 다양한 시스템들로부터 수집을 하였기에 그 모든 단말 시스템에 Logstash를 설치하는 것은 적지 않은 부담이었습니다. 그래서 Logstash팀은 단말 시스템으로 부터 데이터를 수집하고 필터기능 없이 가볍게 Elasticsearch 또는 Logstash로 데이터를 전송하는 Lumberjack 이라는 이름의 일종의 포워더 성격의 원격 수집기를 개발 중에 있었습니다.

그러던 중 독일에서 어느 두 개발자들이 Packetbeat라는 프로그램을 이용해 네트워크 패킷을 스니핑하여 Elasticsearch에 저장하여 모니터링 하는 시스템을 공개했는데, 개발 중이던 Logstash 원격 수집기 프로젝트는 중단되었고 그 역할을 Beats가 대신 실행하게 되었습니다. Beats는 구글에서 개발된 Go 언어로 개발되었습니다. Go는 매우 가볍고 바이너리 실행 파일로 컴파일 되는 언어라 라이브러리 종속성도 적습니다. 현재 Elastic 에서는 Packetbeat, Libbeat, Filebeat, Metricbeat, Winlogbeat, Auditbeat 등을 개발하여 배포하고 있으며 전 세계 오픈소스 개발자들로부터 50여가지 이상의 Beats 들이 개발되고 있습니다.
(이 부분이 ELK 스택에서 가장 궁금했던 것이다. Logstash로 데이터 전송이 가능한데 왜 Beat까지 만들었는지에 대해서이다. 여기서 말하는 이유로는 Logstash의 기능이 다양해지면서 프로그램이 무거워져서 이를 대체하기 위한 원격 데이터 수집기가 필요하였고 이를 경량화 되어있는 Beat가 Logstash로 보내서 이를 가공하고 Elasticsearch로 보내고 Kibana로 시각화까지 하는 하나의 Flow가 만들어지게 된다.)
Libbeat
먼저 Beats 팀은 처음 개발한 PacketBeat 프로그램에서 Elasticsearch로 전송하는 부분만을 따로 추출하여 일종의 공통 라이브러리로 만들었습니다. 특정한 데이터를 수집하는 부분만 코딩 하고 나면 데이터를 JSON 문서로 변환하고, 데이터가 유실되지 않게 관리하고, Elasticsearch로 전송하는 역할은 이 공통 라이브러리인 Libbeat이 담당하게 됩니다.
(데이터 수집은 코드에 따라 바꾸고 Elasticsearch로 전송하는 이 메커니즘은 Libbeat 라이브러리로 재사용을 한다.)
Packetbeat
가장 처음 존재했던 Beat이 바로 Packetbeat 입니다. 설치된 시스템에 유통되는 패킷들을 스니핑 해서 Elasticsearch에 적재시키는 기능을 합니다.
스니핑이란?
Sniffing이란 단어의 사전적 의미는 '코를 킁킁거리다', '냄새를 맡다' 등의 뜻이 있다.
사전적인 의미와 같이 해킹 기법으로서 스니핑은 네트워크 상에서 자신이 아닌 다른 상대방들의 패킷 교환을 엿듣는 것을 의미한다. 간단히 말하여 네트워크 트래픽을 도청(eavesdropping)하는 과정을 스니핑이라고 할 수 있다. 이런 스니핑을 할 수 있도록 하는 도구를 스니퍼(Sniffer)라고 하며 스니퍼를 설치하는 과정은 전화기 도청 장치를 설치하는 과정에 비유될 수 있다.
Filebeat
사용자들이 가장 필요로 하는 기능은 파일의 내용을 수집하는 기능입니다. Web log 또는 machine log 등이 저장되는 log 파일 경로를 지정하기만 하면 Filebeat은 해당 경로에 적재되는 파일을 읽어들이며 새로운 내용이 추가될 때 마다 그 내용을 Elasticsearch로 색인합니다.
Metricbeat
Metricbeat은 실행시켜놓기만 하면 시스템에서 실행중인 프로세스들의 정보와 이 프로세스들이 소모중인 CPU, Memory 등에 대한 상태들을 수집해서 Elasticsearch에 적재하고 손쉽게 이것들을 모니터링 할 수 있는 시스템을 만들 수 있습니다.
Winlogbeat
Winlogbeat은 Microsoft Windows 기반 시스템에서 시스템에 적재되는 Windows event 들을 수집해 Elasticsearch로 색인하여 모니터링 할 수 있도록 합니다.
Auditbeat
Auditbeat은 리눅스 시스템의 사용자 접속과 실행 이벤트 로그들과 같은 감사 데이터를 수집합니다. 주로 시스템의 보안 분석을 할 때 사용됩니다.
Heartbeat
다른 Beats 들도 이름에서 손쉽게 어떤 역할을 하는지 짐작이 가능한데, Heartbeat은 Beats 의 종류이면서도 심장 박동과 동일한 단어이기 때문에 재미있습니다. 역시 이름에서 유추할 수 있듯이 Heartbeat은 다른 프로세스들의 가동 시간 등을 모니터링 합니다. ICMP, TCP, HTTP 프로토콜 등을 통해 Ping 명령으로 원격의 프로세스의 가동 여부를 확인하는데, 동작은 단순하지만 다양한 시스템을 동시에 모니터링 할 때 매우 유용합니다.
Functionbeat
가장 최근에 추가된 Functionbeat은 요즘 유행하는 마이크로 서비스 아키텍쳐(MSA)와 같은 FaaS 클라우드 기반의 시스템에서 서버리스 프레임워크를 이용하여 클라우드 인프라를 모니터링 합니다. 다른 Beats 들과 달리 수집을 위한 데이터가 있는 시스템에 설치되는 것이 아니라 Lamda와 같은 기능으로 배포됩니다.
Reference
