🔑 일반화 데이터 모델이란?
일반화 데이터 모델을 이해하기 전에, 먼저 일반화의 개념을 알 필요가 있다. 일반화는 복잡한 현실세계의 사물, 사건을 단순화하여 표현하는 추상화 기법이다. 조금 더 쉽게 풀어 쓰자면 '유사한 것의 집합'이라고 할 수 있다. 기존에 유사하다고 분류되는 것을 묶을 수도 있고, 인위적으로 유사하다고 정의하여 묶을 수도 있다.
일반화 데이터 모델에서는 DB에 필요한 데이터를 유사한 것끼리 묶어 Super Type과 Sub Type으로 계층화한다. 계층 구조상 Super Type은 Sub Type의 상위 개념이다.
🔑 일반화 모델링의 특징
- 일반화 모델링은 Super Type으로 Sub Type을 통합하고 분리한다.
- Fundamental Entity 간 관계를 단순화한다.
- Type Entity에 관계 정보를 유지해야 한다.
일반화 모델의 장점
- 신규 요구사항이나 변경사항이 있을 경우 모델 변경을 최소화: 확장성 확보 및 시스템 유지보수 비용의 절감
- MSA 수용에 용이한 모델: Service별 클라우드 환경에서 분리 시 프로그램 수정이 최소화
🔑 일반화 모델링 Entity 유형
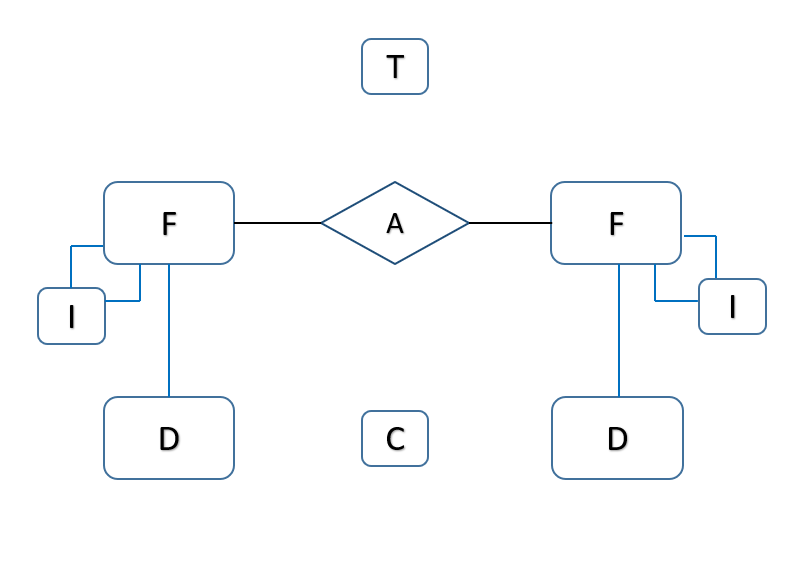
'F'undamental Entity
- 독자적으로 존재하는 기준인 Entity
'D'ependent Entity
- Fundamental의 종속적인 정보
'A'ssociative Entity
- Fundamental과 Fundamental의 관계를 정의
'I'nvolution Entity
- Fundamental 간의 관계를 정의
'C'ode Entity
- Entity Attribute의 코드 내역 정의
'T'ype Entity
- Associative Entity 관계 타입 정의
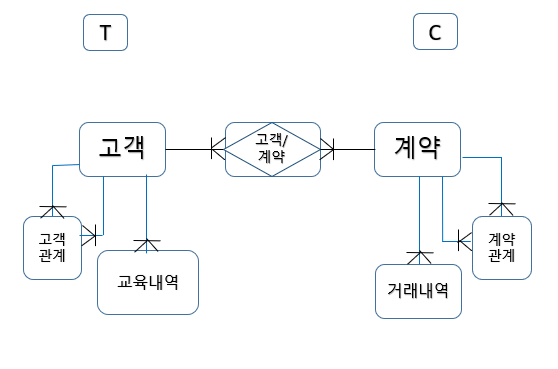
🔑 일반화 모델링의 예시
계약을 관리하는 서비스를 구축하기 위한 일반화 모델링을 떠올려 보자.
가장 먼저 독자적으로 존재해야 하는 기준(Fundamental)을 정해야 한다. 단순화하여 생각해 보면 정의할 수 있는 기준은 '고객'과 '계약'일 것이다. 고객이 있어야 계약을 진행할 수 있고, 계약이 있어야 고객에게 제안할 수 있기 때문이다.
이후 결정한 기준에 따른 종속적인 정보(Dependent)를 설정해야 한다. '고객' 아래에는 '사업자 정보'가 있을 것이고 '계약' 아래에는 '거래 내역'을 다룰 수 있을 것이다.
그렇다면 생성된 '고객'과 '계약' DB를 연결하기 위한 관계(Associative)는 어떻게 정의되어야 할까? 고객과 계약은 다대다 관계일 수 있다. 즉, 고객은 다수의 계약을 맺을 수 있고 하나의 계약이 다수의 고객(단체 고객)과 계약을 맺을 수 있다. 그러나 DB는 다대다 관계를 최대한 기피해야 하는 만큼 Associative Entity에 '고객/계약'을 정의하여 관리한다.
'고객'과 '계약' 내부에서도 각각 관계가 정의(Involution)될 수 있다.
고객 구분, 거래 유형 코드와 같은 코드 내역도 정의(Code)되어야 한다.
계약자 관계, 직원 관계와 같은 Associative Entity 내 관계타입(Type)도 정의될 수 있다.
모든 조건을 고려하여 최종적으로 도출된 일반화 모델링은 다음과 같다.