Lowest Common Ancestor란?
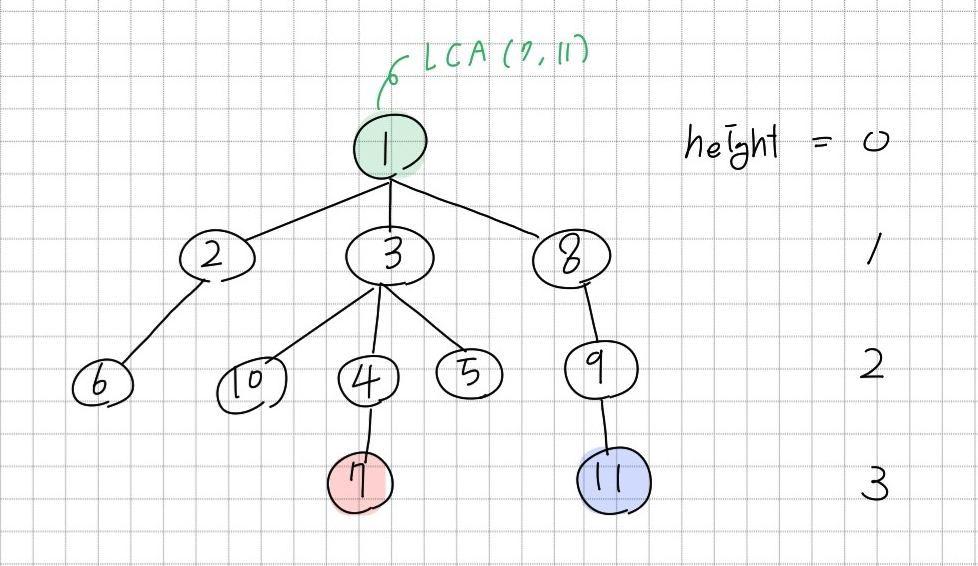
두 정점의 조상들 중 같은 조상을 Common ancestor라고 한다. Common ancestor 중 두 정점에 가장 가까운 Common ancestor가 Lowest Common Ancestor(LCA)이다. 위의 그림에서 정점 7과 11의 common ancestor는 1밖에 없다. 따라서 LCA(7,11)은 1이다. 정점 7과 10의 경우에는 common ancestor가 1, 3이다. 정점 1보다는 3이 두 정점에 더 가까우기 때문에 LCA(7,10)은 3이 된다.
1. 간단한 방법
LCA를 구하는 가장 간단한 방법은 두 정점의 parent로 동시에 이동하며 Common ancestor를 찾는 것이다. 계속 parent로 이동하다 두 정점이 같아지면 그 정점가 LCA가 된다. 이때 주의할 점은 두 정점의 parent로 동시에 이동하며 탐색하기 전 두 정점의 height를 맞춰줘야 한다는 것이다. 만약 height를 맞추지 않고 탐색을 시작하면 common ancestor가 있음에도 찾지 못하게 된다.
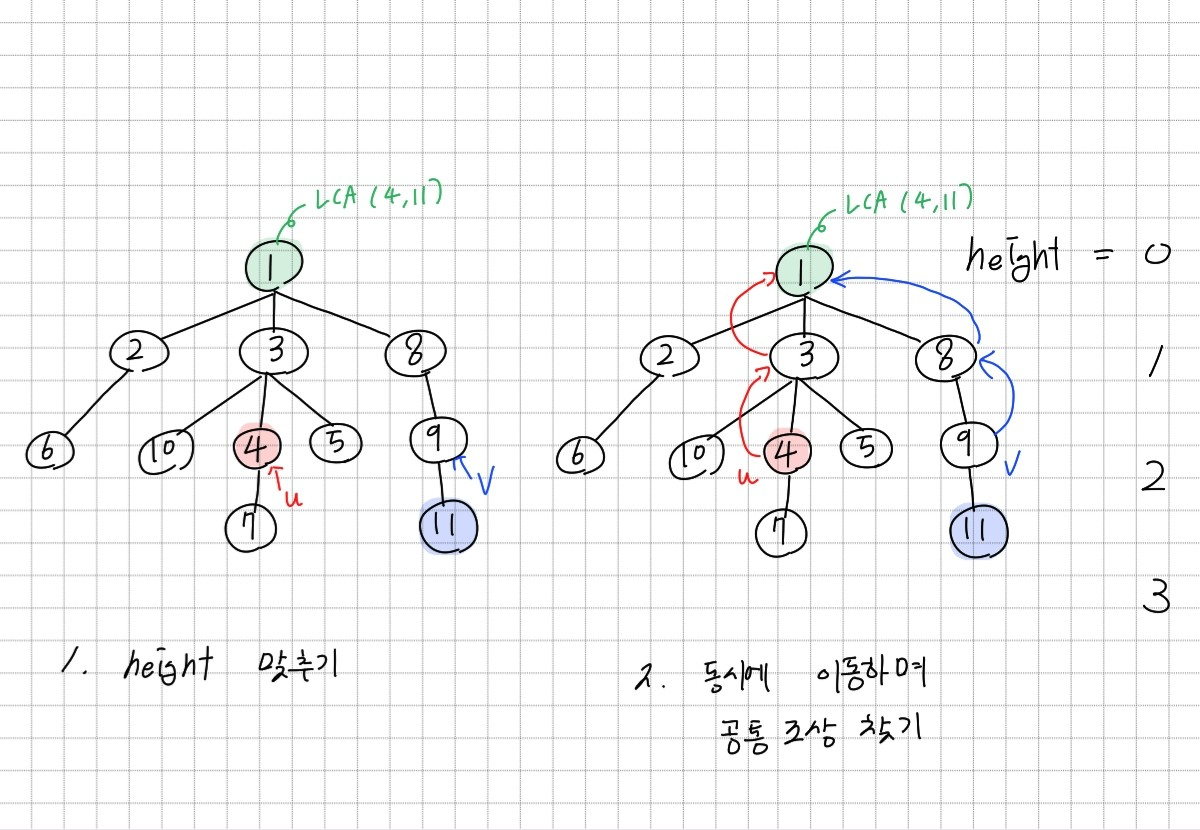
예를 들어 위의 트리에서 LCA(4,11)을 구한다고 해보자. 먼저 두 정점 4와 11의 height가 다르므로 height를 맞춰줘야 한다. 정점 4가 11보다 height가 낮으므로 정점 11을 가르키던 v를 정점 4의 height인 2가 될 때 까지 parent로 계속 이동시킨다. 그러면 왼쪽 그림과 같이 u는 정점 4를, v는 정점 9를 가르킨다. 이제 u, v가 같은 정점을 가르킬 때까지 parent로 동시에 이동시키는 작업을 반복한다. 그 결과 u와 v는 동시에 정점 1을 가르키게 된다. 정점 1은 정점 4와 정점 11의 LCA가 된다.
시간 복잡도 : O(N)
한쪽으로 편향된 트리와 같이 최악의 경우에는 N개의 정점을 모두 거슬러 올라가야 LCA 를 구하는 경우가 발생할 수 있다.
2. 개선된 방법
- 아이디어
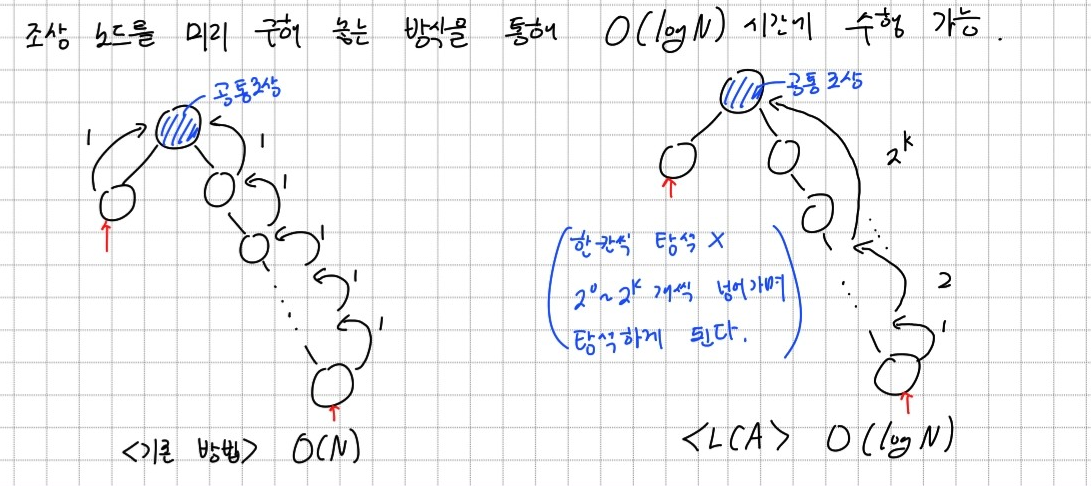
첫번째 방법은 구현이 매우 간단하다는 장점이 있지만, 시간 복잡도가 O(N)이므로 정점이 많은 트리의 경우 사용하기 어려울 수 있다. 개선된 방법은 시간 복잡도가 O(logN)으로 트리의 정점이 많은 경우 첫번째 방법보다 더 좋은 성능을 보장한다. 개선된 LCA 구하기 방법은 한 정점의 parent만 저장하는 것이 아니라 ancestor 정보를 저장하여, 한번에 여러 세대를 뛰어 넘을 수 있도록 하여 수행 시간을 줄인다.
- 사전 준비
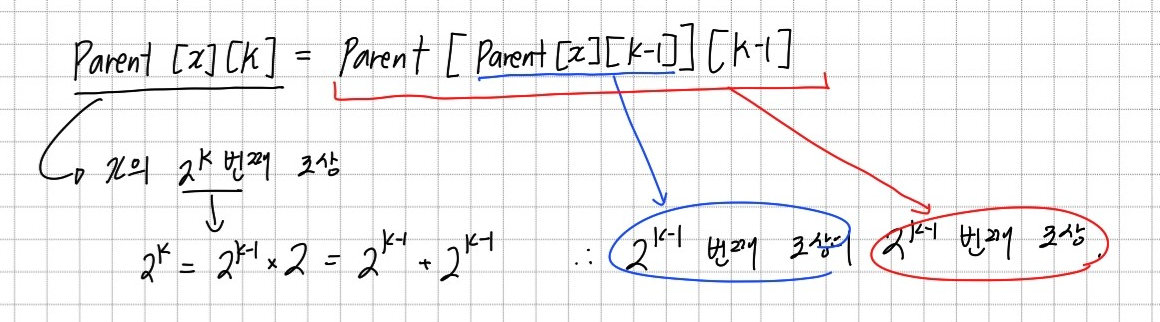
먼저 각 정점의 ancestor 정보를 저장해야 한다. 모든 ancestor의 정보를 저장하는 것은 아니고, 번째 ancestor를 저장한다. (2의 배수 번째 ancestor를 저장하는 이유는 이후 탐색 과정에서 이진 탐색과 비슷한 방식으로 탐색 범위를 절반으로 줄이며 탐색하기 때문이다.) ancestor 정보를 저장하는 과정에서는 직접 parent로 이동하며 저장하는 것이 아니라, 위의 점화식을 사용하여 dynamic programming를 사용한다. 이때 k는 편향된 트리에서 가장 밑의 정점이 바로 root까지 이동할 수 있도록 정한다. 따라서 전체 정점의 개수가 N일때 가 된다.
- 탐색
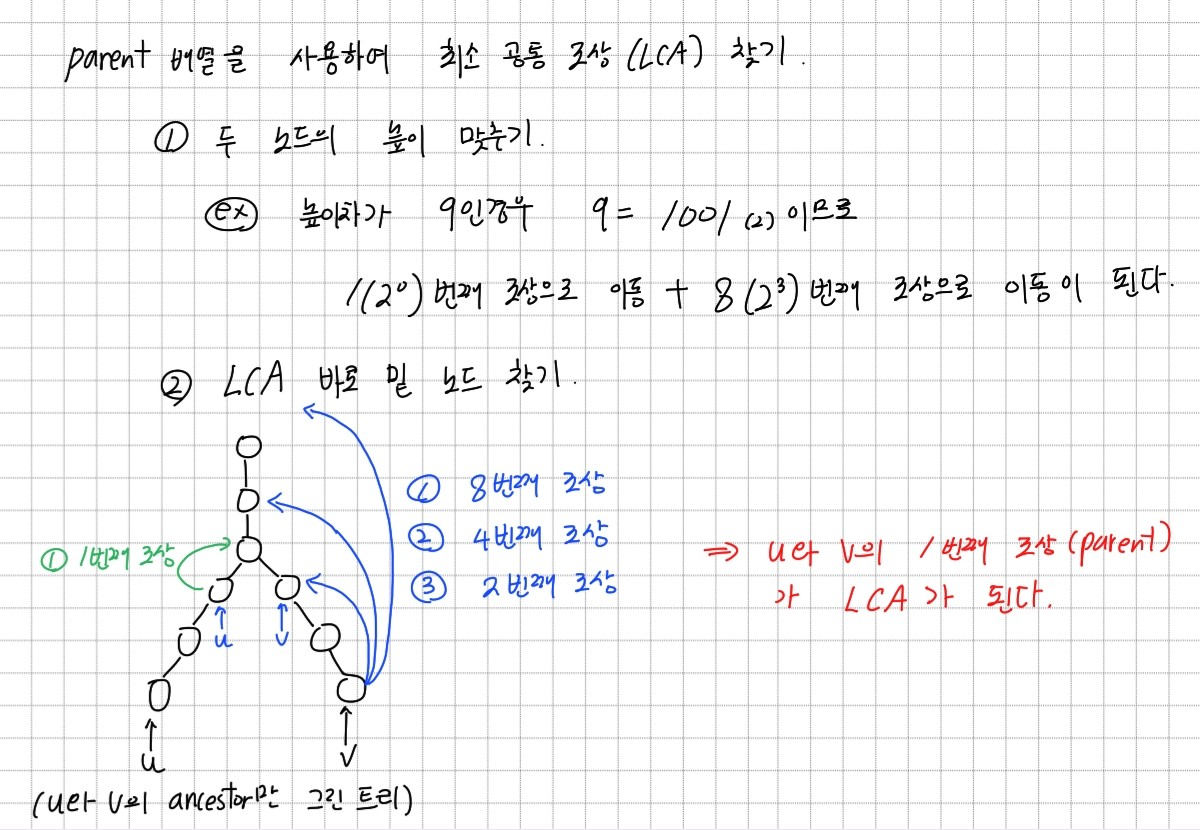
각 정점의 ancestor 정보를 저장한 parent 배열을 완성하였다면 이제 LCA를 찾는 탐색을 시작한다. 간단한 방법과 마찬가지로 먼저 u와 v의 height를 맞춰준다. 다른 점은 만들어둔 parent 배열을 사용하여 n번째 부모로 바로 이동할 수 있다는 점이다.
height를 맞추었으면 번째 조상부터 번째 조상까지 탐색한다. 만약 u와 v의 조상이 달라졌다면 u와 v를 해당 조상으로 각각 옮긴 후 탐색을 계속한다. 이 단계에서는 LCA를 찾는 것이 아니라 LCA 바로 밑 정점을 찾는 것이 목표이다. u와 v의 ancestor는 LCA 밑에서 부터 달라지기 시작하기 때문이다.
위의 그림과 같은 경우 우선 8번째 조상을 탐색한다. 하지만 u와 v의 8번째 조상이 같다. 이는 찾고자 하는 LCA 바로 밑 정점이 1~8번째 조상 안에 있음을 의미한다. 따라서 다음에는 4번째 조상을 탐색한다. 이번에도 두 조상이 같으므로 찾고자 하는 정점이 1~4번째 조상 안에 존재함을 알 수 있다. 마치 binary search처럼 범위를 반으로 줄여가며 탐색을 진행한다. u와 v의 조상이 2번째 조상에서는 달라지므로 u와 v를 각각 2번째 조상으로 이동한다. 이제 다시 탐색을 시작한다. 하지만 처음과 달리 8번째 조상부터 탐색하지는 않는다. 첫 탐색에서 탐색 범위를 줄여놨기 때문이다. 따라서 이 경우에는 1번째 조상부터 탐색한다. 탐색이 끝나면 u와 v는 LCA 바로 밑의 정점을 가리키게 된다. u의 parent 정점이 LCA이다.
- 구현 코드
#include<iostream>
#include<set>
#include<queue>
using namespace std;
typedef struct _node
{
int parent;
int height;
set<int> children;
}Node;
Node tree[100001];
int parents[100001][21];
int N;
int K;
int getLCA(int u, int v)
{
// height 맞추기
int diff = tree[v].height - tree[u].height;
int jump = 0;
while (diff > 0)
{
if (diff & 1 == 1)
{
v = parents[v][jump++];
}
diff = diff >> 1;
}
if (u == v) return u;
// 공통 조상 찾기
for (jump = K; jump >= 0; jump--)
{
if (parents[u][jump] != parents[v][jump])
{
u = parents[u][jump];
v = parents[v][jump];
}
}
return parents[u][0];
}
int main(int argc, char** argv)
{
cin >> N;
// tree 구성
tree[1].parent = -1;
tree[1].height = 0;
tree[1].children.clear();
for (int i = 2; i <= N; i++)
{
int parent;
cin >> parent;
tree[i].parent = parent;
tree[i].height = tree[parent].height + 1;
tree[i].children.clear();
tree[parent].children.insert(i);
}
// parent 배열 만들기
K = ceil(log2(N) + 0.5);
for (int i = 0; i <= K; i++)
parents[1][i] = -1;
for (int r = 2; r <= N; r++)
{
parents[r][0] = tree[r].parent;
for (int c = 1; c <= K; c++)
{
if (parents[r][c - 1] == -1)
parents[r][c] = -1;
else
parents[r][c] = parents[parents[r][c - 1]][c - 1];
}
}
return 0;
}