HashSet의 가장 큰 특정은 중복을 걸러낸다는 것이다.
즉, Java에서 무언가 중복 없이 저장해 놓고 싶을 때 사용하면 좋은 class이다.
HashSet이란?
- HashSet은 자바의 Set 인터페이스를 구현한 클래스이다.
- Set 인터페이스를 구현한 클래스에는 HashSet 이외에도 TreeSet이 존재한다.
- HashSet은 자동으로 정렬이 되지 않는 반면, TreeSet은 자동으로 정렬이 된다.
HashSet을 사용하면 좋은 경우?
중복을 허락하지 않고 정렬이 필요 없는 경우에 HashSet을 사용한다.
Set의 경우, 순서가 없기때문에 index가 있을 수 없다. 따라서 특정 index에 있는 무언가를 가져오고 싶을 때는 HashSet을 사용할 수 없다.
또한 값을 추가하거나 삭제하는 것이 많은 알고리즘을 구현할 때 HashSet의 사용은 피하는 것이 좋다.
→ 값 추가/삭제에 시간이 오래 소요되기 때문이다.
HashSet의 특징
- 값을 중복 저장하지 않는다.
- Set은 집합을 의미한다.
- 집합에서는 중복값을 허용하지 않는다.
- 값의 중복 여부는 hashCode()의 리턴 값이 같고, equals()의 검사 결과가 true일 때 같은 값으로 취급한다.
- 즉, 중복된 값을 저장하고 싶지 않을 때 HashSet을 사용한다.
- 값을 순서대로 저장하지 않는다.
- 값 객체의 hashCode()의 리턴 값으로 저장 위치를 계산하기 때문에 add() 한 순서대로 저장되지 않는다.
- 그래서 값을 index를 이용하여 꺼낼 수 없다.
java.util.HashSet 클래스 사용
- 중복저장 불가 테스트
- Primitive type과 Wrpper class 데이터 타입들은 hashCode()와 equals() 메소드들이 이미 오버라이딩 되어 있어서 중복값을 비교할 때 자동으로 제거가 된다.
- 따라서 String은 이미 HashCode와 equals() 메소드가 오버라이딩 된 클래스여서 중복된 값이 자동으로 제거되는 것이다.
import java.util.HashSet;
public class Exam0110 {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
// Set에 값 추가하기
set.add(new String("aaa"));
set.add(new String("bbb"));
set.add(new String("ccc"));
// Set은 집합의 특성을 따른다.
// 같은 값을 중복해서 넣을 수 없다.
set.add(new String("aaa"));
set.add(new String("bbb"));
set.add(null);
set.add(null);
System.out.println(set);
}
}HashSet과 사용자 정의 데이터 타입
- Primitive type과 Wrpper class 데이터 타입들은 hashCode()와 equals() 메소드들이 이미 오버라이딩 되어 있어서 중복값을 비교할 때 자동으로 제거가 되지만,
- 사용자 정의 데이터 타입의 경우에는 내가 따로 hashCode()와 equals() 메소드들을 오버라이딩 해주어야 HashSet의 기능인 요소 중복 제거가 가능하다.
// HashSet과 사용자 정의 데이터 타입 - hashCode()와 equals() 모두 오버라이딩
import java.util.HashSet;
import java.util.Objects;
public class Exam0340 {
// 사용자 정의 데이터 타입
static class Member {
String name;
int age;
public Member(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Member [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Member other = (Member) obj;
return age == other.age && Objects.equals(name, other.name);
}
}
public static void main(String[] args) {
Member v1 = new Member("홍길동", 20);
Member v2 = new Member("임꺽정", 30);
Member v3 = new Member("유관순", 16);
Member v4 = new Member("안중근", 20);
Member v5 = new Member("유관순", 16);
System.out.printf("v3 == v5: %b\n", v3 == v5);
System.out.printf("equals(): %b\n", v3.equals(v5));
System.out.printf("hashCode(): %d, %d\n", v3.hashCode(), v5.hashCode());
HashSet<Member> set = new HashSet<>();
set.add(v1);
set.add(v2);
set.add(v3);
set.add(v4);
set.add(v5); // 중복 저장되지 않는다.
System.out.println(set);
}
}
HashSet vs. HashMap
HashSet
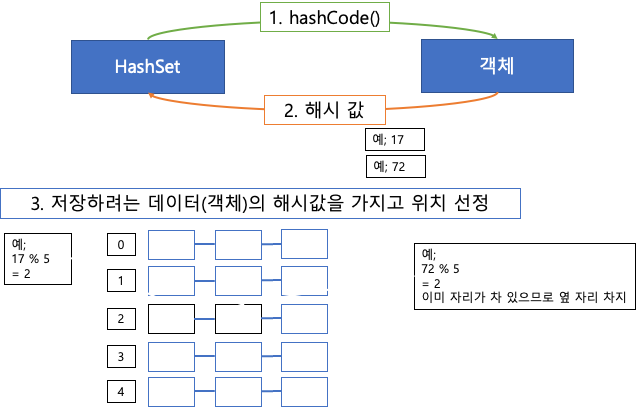
- 저장하려는 데이터의(객체) 해시값을 가지고 저장 위치를 설정
- 값을 꺼낼 때 임의의 순서로 꺼낸다. ⇒ 특정 객체를 꼭 집어서 꺼낼 수 없다.
HashMap
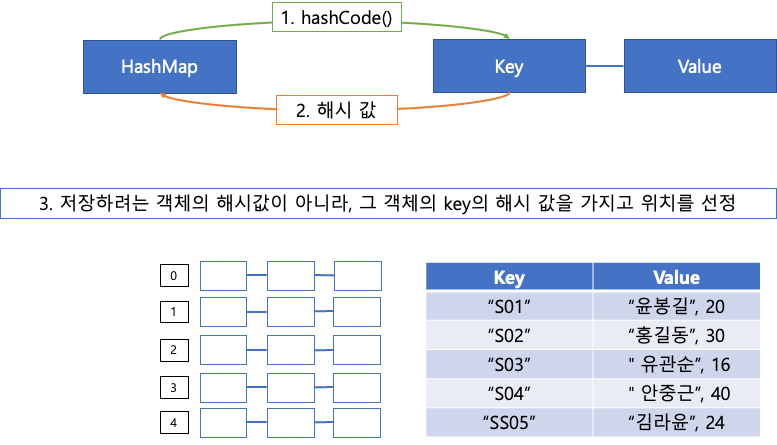
- 저장하려는 데이터(객체)의 key의 해시값을 가지고 저장 위치를 설정한다.
- 값을 꺼낼 때 key를 가지고 특정 객체를 꼭 집어서 꺼낼 수 있다.
- Wrapper와 Primitive 데이터 타입의 클래스에서 이미 HashCode()와 equals() 메소드가 오버라이딩 되어 있기 때문에, 따로 다시 오버라이딩 할 필요가 없어서 Key 값으로 주로 이 데이터 타입들을 이용한다.
Map 사용법 - put(), get()
- Map 구현체
- HashMap과 HashTable이 있다.
- Key를 가지고 value를 저장하고 꺼낸다.
- put()
put(key,value) : 맵에 값 저장하기
- key 객체에 대해 hashCode()를 호출하여 정수 값을 얻는다.
- 이 해시값을 가지고 저장할 위치를 결정한다.
- 이전에 저장할 때 사용한 같은 키로 다른 값을 저장하면 기존 값을 덮어쓴다.
map.put("s01", new Member("홍길동", 20));
1. "s01" String 객체에 대해 hashCode()를 호출하여 해시 값을 얻는다.
2. 그 해시 값을 사용하여 저장할 위치를 결정한다.
3. 해당 위치에 Member 객체(의 주소)를 저장한다.
- get()
get(key) : 맵에서 값 꺼내기
- 저장할 때 사용한 키를 가지고 꺼낸다.
- 존재하지 않는 key를 지정하면 null을 리턴한다.
System.out.println(map.get("s01"));
1. key 객체에 대해 hashCode()를 호출한다.
2. hashCode()의 리턴 값을 가지고 데이터를 찾을 위치를 결정한다.
3. 해당 위치에 있는 key 객체에 대해 equals()를 호출하여 리턴값을 확인한다.
4. equals()의 리턴 값이 true라면 같은 key로 간주하여 해당 위치의 값을 꺼낸다.
mport java.util.HashMap;
public class Exam0110 {
public static void main(String[] args) {
HashMap<String,Member> map = new HashMap<>();
map.put("s01", new Member("홍길동", 20));
map.put("s02", new Member("임꺽정", 30));
map.put("s03", new Member("유관순", 16));
map.put("s04", new Member("안중근", 20));
// 이전에 저장할 때 사용한 같은 키로 다른 값을 저장하면 기존 값을 덮어쓴다.
map.put("s02", new Member("윤봉길", 30));
System.out.println(map.get("s01"));
System.out.println(map.get("s02"));
System.out.println(map.get("s03"));
System.out.println(map.get("s04"));
// 존재하지 않는 key를 지정하면 null을 리턴한다.
System.out.println(map.get("s05"));
}
}Map - 사용자 정의 데이터 타입을 key로 사용할 경우
- 키 객체의 해시값으로 위치를 정하므로 해시값이 다르면, 인스턴스 필드 값이 같아도 키 객체로 원하는 값을 찾을 수 없다.
- 인스턴스가 달라도 같은 값 → 같은 객체로 인식
⇒ equals()랑 hashcode() 메서드들로 구분 - HashMap의 key 객체로 사용할 클래스는 반드시 hashCode()와 equals()를 오버라이딩 하여 같은 값을 갖는 경우 같은 해시 값을 리턴하게 해야한다.
- 개발자가 만든 클래스를 key 객체로 사용하려면 이런 번거로움이 있다.
- 그래서 대부분 현업에서는 그냥 String을 key로 사용한다.
- 또는 Wrapper 클래스인 Integer를 사용하기도 한다.

https://github.com/Dingadung