web server - client 에 대해서
(어떻게 web page가 보일까?)
1. client와 server
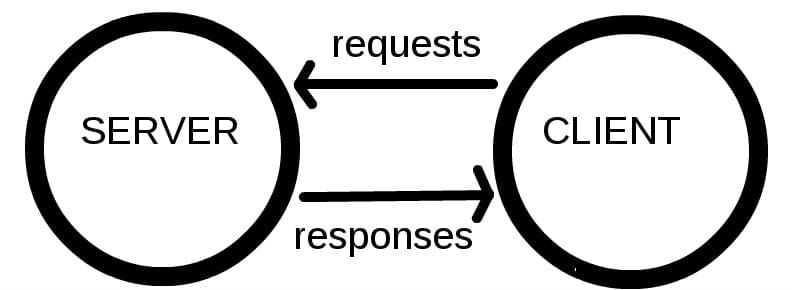
- 클라이언트(Client): 요청하는 웹 브라우저 등
- 서버(Server): 리소스(파일, 정보 등)를 응답해 주는 쪽
클라이언트에서 지정된 URL을 입력해 서버에 요청
예를 들어 http://www.naver.com를 주소창에 입력하면 Naver 웹 페이즈를 요청하는 것이다.
그러면 네이버 서버에서는 네이버 웹 페이지에 대한 정보를 클라이언트에 보내주어 화면에 표시되게 된다.
localhost란?
흔히 자신의 컴퓨터 (로컬 컴퓨터) 주소를 localhost나 127.0.0.1이라고 표현한다.
127.0.0.1
127.0.0.1 은 자신의 컴퓨터를 가리키는 IPv4 IP주소로,
자기 자신을 가리킨다고 해서, 루프백 (loopback) 주소라고도 불린다.
→ 보내면 자기 자신에게로 다시 돌아오기 때문이다.
로컬호스트
로컬호스트 (localhost)는 마찬가지로 자신의 컴퓨터를 가리키는 호스트이름 (hostname) / 도메인 이다.
Windows의 경우 C:\windows\system32\drivers\etc\hosts 여기 이 파일에 정의되어 있다.
DNS
127.0.0.1과 로컬호스트 둘 다 자신의 컴퓨터를 가리키는 역할을 하는데, 차이점이 무엇인가에 대해 알기 위해서는 DNS에 대해 알아야 한다.
DNS는 Domain Name System의 약어로 IP주소를 도메인으로 도메인을 IP주소로 변환시켜주는 서비스이다.
DNS은 우리가 인터넷 웹 사이트에 접속할 때, 해당 사이트의 IP주소를 일일히 치지 않도록 수고를 덜어 준다.
→ 예를들어, 네이버에 접속하기 위해서 우리는 www.naver.com 이라는 도메인만 알면 된다.
네이버의 IP 주소인. 202.179.177.22를 외워서 매번 칠 필요가 없다.
⇒ 즉, 127.0.0.1은 IP 주소이고, localhost는 일일히 IP주소를 쳐야하는 우리의 수고를 덜어주기 위한 도메인이다.
자기 자신의 컴퓨터를 원격 컴퓨터인 것 처럼 통신할 수 있기 때문에, 127.0.0.1 / localhost는 테스트를 비롯한 다양한 상황에서 많이 쓰인다.
때문에 OS 자체적으로 127.0.0.1 / localhost를 고정된 ip로 제공하고 있다.
이 127.0.0.1 또는 localhost는 예약된 ip주소로 일반 ip주소로는 쓰일 수 없다.
127.0.0.1 / localhost를 사용하면, 인터페이스를 사용하지 않고, OS (kernel)에서 직접 처리합니다.
ㅁ# RDBMS
관계형 데이터베이스(RDB)는 테이블, 행, 열의 정보를 구조화하는 방식이다.
RDB에는 테이블을 조인하여 정보 간 관계 또는 링크를 설정할 수 있는 기능이 있어, 여러 데이터 포인트 간의 관계를 쉽게 이해하고 정보를 얻을 수 있다.
SQL, ORM
영속성(Persistence)
영속성이란 프로그램이 종료되어도 데이터가 사라지지 않는 특성을 말한다.
영속성을 갖지 못한 데이터는 메모리에만 존재하기 때문에 프로그램이 종료되면 사라지게 된다.
영속성은 파일 시스템, 관계형 데이터베이스 또는 객체 데이터 베이스를 활용하여 구현한다.
데이터가 영속성을 가지기 위해 Spring에서 사용하는 방법은 3가지가 존재한다.
- JDBC (Java)
- Spring JDBC
- Persistence Framework
Persistence Framework
Persistence Framework는 JDBC를 사용하기 위한 복잡하고 번거로운 작업 없이 간다한 작업으로 데이터베이스와 연동할 수 있게 제공하는 프레임워크이다.
이 프레임워크를 사용하면 시스템을 빠르고 안정적으로 개발이 가능하다.
Persistence Framework에는 ORM과 SQL Mapper가 있다.
ORM: JPA, HibernateSQL Mapper: Mybatis
ORM (Object-Relation Mapping)
객체와 관계형 데이터베이스의 데이터를 자동으로 매핑시켜주는 프레임워크이다.
설정된 객체 간의 관계를 바탕으로 자동으로 SQL를 생성하여 실행한다.
SQL를 직접 작성할 필요가 없다.
장점
-
객체 지향적인 코드로 직관적인 비지니스 로직을 작성할 수 있다.
-
DBMS 종속성이 줄어들고 종류에 관계 없이 빠르게 적용 가능하다.
-
쿼리에 집중할 필요 없이 빠르게 개발이 가능하다.
-
재사용 유지 보수 편리성이 증가 한다.
단점
-
초기 적용에 러닝 커브가 어느 정도 있다.
-
프로젝트의 복잡성이 커질경우 난이도가 올라간다.
-
잘못 적용할 경우 속도 저하가 발생 할 수 있다.
-
복잡한 SQL의 사용하지 못할 수 도 있다.
SQL Mapper
객체와 관계형 데이터베이스의 데이터를 개발자가 작성한 SQL로 매핑시켜주는 프레임워크이다.
개발자가 SQL을 직접 작성해야 하며 SQL문을 실행하고 얻은 데이터를 객체로 매핑시켜준다.
장점
-
SQL을 작성 할 줄 안다면 수월하게 사용이 가능하다.
-
세부적인 SQL 변경시 편리하다.
단점
-
DBMS에 따라 SQL 문법이 다르기에 DBMS에 종속적이다.
-
개발시 SQL를 작성해야 한다.
-
DBMS 변경시 SQL문의 재사용이 어렵다.
-
2개 이상의 DBMS 지원시 유지 보수가 어렵다.
Database key
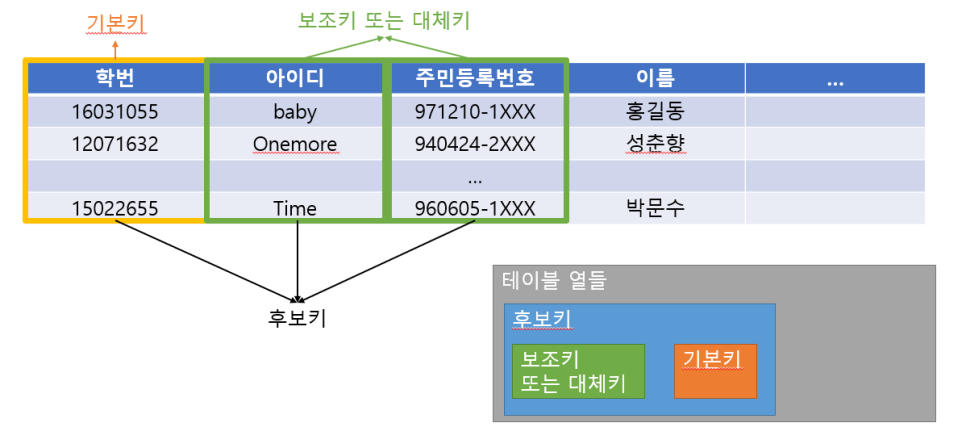
(1) 키?
하나의 테이블을 구성하는 여러 열 중에서 특별한 의미를 지닌 하나 또는 여러 열의 조합
→ 종류별로 데이터를 구별하거나 테이블 간의 연관 관계를 표현할 때, 키로 지정한 열을 사용한다.
(2) 키는 기본키, 후보키, 외래키, 복합키로 구분할 수 있다.
(3) 기본키(primary key)
-
가장 중요한키
-
테이블 내에서 중복되지 않는 값만 가질 수 있는 키
-
기본키의 속성
-
테이블에 저장된 행을 식별할 수 있는 유일한 값이어야 한다.
-
값의 중복이 없어야 한다.
-
NULL 값을 가질 수 없다.
-
중복되지 않는 유일한 값 → 하나 또는 여러 열의 조합으로 만들 수 있다.
-
정보 노출이 가장 적은 데이터로 기본키를 선정한다. (예; 학생 테이블에서 학번)
-
(4) 보조키
-
대체키(alternative key)라고도 불린다.
-
후보키(candidate key)에 속해 있는 키이다.
-
후보키? 기본키가 될 수 있는 모든 키를 의미 → 기본키 역시 후보키에 속한다.
-
후보키 중 기본키로 지정되지 않은 키를 보조키 또는 대체키라고 한다.
-
슈퍼키(super key)? 행 식별이 가능한 키의 모든 조합을 의미
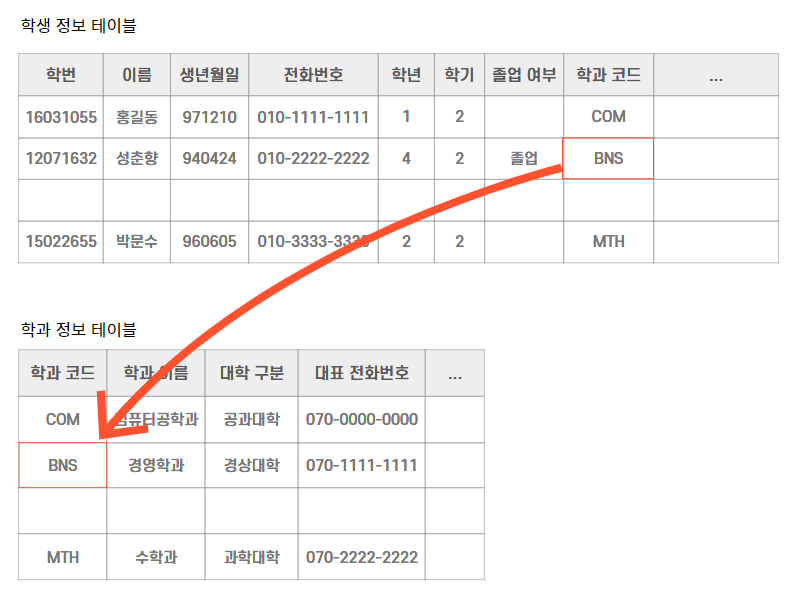
(5) 외래키(FK : Foreign Key)
-
외래키? 특정 테이블에 포함되어 있으면서 다른 테이블의 기본키로 지정된 키를 의미
-
예; 학과 테이블에서의 기본키인 학과 코드가 학생 정보 테이블의 일반 열이 될 때, 학과 코드가 외래키가 된다.
-
이 학과 코드는 학생 정보 테이블과 학과 정보 테이블을 이어 주는 역할을 한다.
-
학생 정보 테이블은 학과 코드를 통해 학과 정보 테이블의 세부정보를 찾을 수 있는데 이를 학생 정보 테이블이 학과 코드를 참조한다고 표현한다.
-
(6) 복합키(composite key)
-
복합키? 여러 열을 조합하여 기본키 역할을 할 수 있게 만든 키
-
하나의 열만으로 행을 식별하는 것이 불가능할 때 두 개 이상의 열 값을 사용하여 유일한 데이터로서 가치를 지니게 한다.
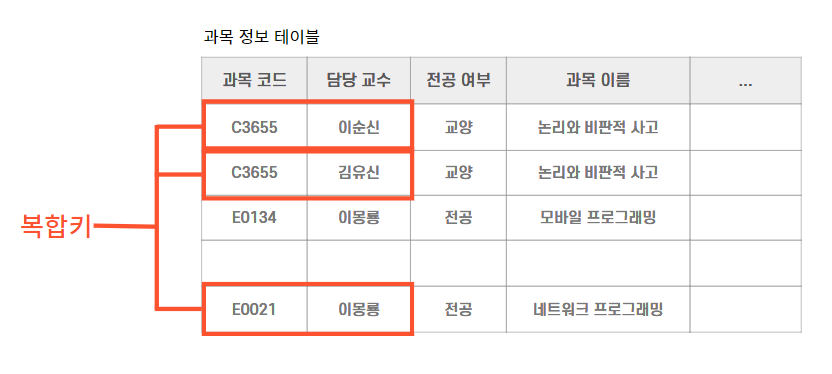
⇒ 관계형 데이터베이스에서 테이블 행을 구분하기 위해, 그리고 여러 테이블 간의 관계를 정의하기 위해 키를 사용한다.
Database 관계 (1:1. 1:N, N:M)
관계형 데이터베이스(Oracle, MySQL, MS-SQL, SQLite 등등)는 엔티티끼리 관계를 맺을 수 있어서 관계형 DB라는 이름이 붙었다.
엔티티(Entity)
DataBase에 표현하려고 하는 유형, 무형의 객체로서 서로 구별되는 것을 뜻한다.
관계는 두 엔티티가 서로 관련이 있을 때를 말하는데, 1:1, 1:N, N:M 관계를 맺을 수 있다.
1:1 관계(일대일 관계)
1:1 관계란 어느 엔티티 쪽에서 상대 엔티티와 반드시 단 하나의 관계를 가지는 것을 말한다.
예를 들어, 우리나라에서 결혼 제도는 일부일처제로, 한 남자는 한 여자와, 한 여자는 한 남자와 밖에 결혼을 할 수 없다.
남편 또는 부인을 2명 이상 둘 수 없는데, 이러한 관계가 1:1 관계다.
1:N 관계(일대다 관계)
1:N 관계는 한 쪽 엔티티가 관계를 맺은 엔티티 쪽의 여러 객체를 가질 수 있는 것을 의미한다.
현실세계에는 1:N관계가 많이 있는데, 실제 DB를 설계할 때 자주 쓰이는 방식이다.
1:N 관계는 N:M 관계처럼 새로운 테이블을 만들지 않는다.
예를 들어, 부모와 자식 관계를 생각해보면, 부모는 자식을 1명, 2명, 3명, 그 이상도 가질 수 있다.
이를 부모가 자식을 소유한다고(has a 관계) 표현한다.
반대로 자식 입장에서는 부모(아버지, 어머니의 쌍)를 하나만 가질 수 밖에 없다.
이러한 관계를 1:N 관계라고 하며, 계층적인 구조로 이해할 수도 있다.
여러 명의 자식(N)의 입장에서 한 쌍의 부모(1)중 어떤 부모에 속해 있는지 표현해야하므로 부모 테이블의 PK를 자식 테이블에 FK로 집어 넣어 관계를 표현한다.
⇒ 즉 부모 테이블(1)에서는 내 자식들이 누구인지 정보를 넣을 필요가 없고, 자식 테이블(N)에서만 각각의 자식들이 자신의 부모 정보(FK)를 넣음 으로써 관계를 표현할 수 있다.
N:M 관계(다대다 관계)
N:M 관계는 관계를 가진 양쪽 엔티티 모두에서 1:N 관계를 가지는 것을 말한다.
⇒ 즉, 서로가 서로를 1:N 관계로 보고 있는 것이다.
예를들어, 학원과 학생의 관계를 생각해보면, 한 학원에는 여러명의 학생이 수강할 수 있으므로 1:N 관계를 가진다.
반대로 학생도 여러개의 학원을 수강할 수 있으므로, 이 사이에서도 1:M 관계를 가진다.
그러므로 학원과 학생은 N:M 관계를 가진다고 할 수 있다.
N:M 관계는 서로가 서로를 1:N 관계, 1:M 관계로 갖고 있기 때문에, 서로의 PK를 자신의 외래키 컬럼으로 갖고 있으면 된다.
일반적으로 N:M 관계는 두 테이블의 대표키를 컬럼으로 갖는 또 다른 테이블을 생성해서 관리한다.
