Design Issues 🌟
- 프로세스가 시스템 안에 들어왔을 때 이 프로세스를 어느 CPU 에게 할당해줄 것 인가?
- CPU 마다 개별적인 Queue 를 줄 것인지?
- Global Queue 를 줄 것인지? ✅
- MultiProgramming?
- Uni-Processor 에서는 MultiProgramming 은 당연한 것
- Block 은 주로 I/O 작업에 의해서 발생하는데,
하나의 application 안에서 여러개의 프로세스들 또는 스레드들이 만들어져서 굉장히 빈번하게 동기화를 한다고 했을 때의 Block 상태는 I/O 작업을 위한 Block 이 아니라 동기화를 위한 Block(Semaphore Wait) 또는 데이터를 주고 받기 위한 Block 과 같은 상황이 주이다.
이 경우, Switching 을 하는 것보다 잠깐 기다리면 금방 해결되는 경우가 많기 때문에 MultiProgramming 을 하지 않고(Switching 을 하지 않고) 그냥 버티는게 더 나을 수도 있다.
- 9장에서는 실행시간에 따라 프로세스를 실행시키는 순서가 매우 중요했으나,
MultiProcessor System 의 경우에는 CPU 가 2개, 3개, ... 많아지면 많아질 수록 실행시간에 따라 프로세스 순서를 변경하는 것이 별로 의미가 없다.
↳ 다른 CPU 들이 있기 때문
4가지 Scheduling 방법
- Load Sharing
- Gang Scheduling
- Dedicated Processor assignment
- Dynamic Scheduling
Load Sharing
↳ Global Queue 사용 각각의 CPU 는 스레드나 프로세스를 실행하다가 스레드가 프로세스가 실행을 끝마치게 되면 OS 의 Scheduler 를 실행 시켜서 다음에 실행할 프로세스나 스레드를 선택한다.
⇒ Idle-While-Busy 상황은 발생하지 않는다.
Load Sharing 의 문제점
Global Queue 자체가 Critical Section 이다.
즉, 여러 CPU 에서 진행되고 있는 여러 Scheduler 가 동시에 Queue 를 보고 다들 Queue 앞에 있는 걸 선택해야지 하고 같은 프로세스를 동시에 선택하면 안되기 때문에 한 번에 한 사람만 Critical Section 에 진입해서 Scheduling 을 할 수 있다.
⇒ Performance Bottleneck 이 될 수 있다.
그럼에도 불구하고 가장 많이 사용되는 기법이다..!
↳ 이유: 적은 개수의 CPU 를 갖고 있는 시스템에서도 굉장히 잘 작동하기 때문이다.
CPU 의 개수가 수십개에서 수백개인 MultiProcessor System 을 다루는 Scheduling 들에 대해서 알아보자!
↳ Parallel Computer 에 가까운 시스템들에서 사용되는 Scheduling 들
Gang Scheduling
Application 이 여러개의 Thread 들로 구성되어 있다.
↳ 여기서의 Application은 independent 한 프로세스나 Very Coarse 정도가 아니라, 적어도 Medium 이나 fine 정도의 application 을 가르킨다.
이러한 시스템에서는 여러개의 스레드들로 이루어져 있을 뿐만아니라 굉장히 자주 밀접하게 동기화를 한다. 일정하게 자주 동기화하기 때문에 잠깐 Block 이 되어도 Switching 하지 않고 기다리는 게 나은 경우가 많다.
한 프로세스의 스레드를 동시에 실행한다!
Ready Queue 에 스레드 단위가 아닌 프로세스 단위로 줄을 선다.
어떤 프로세스가 Scheduling 이 되면, 이 프로세스가 몇개의 스레드를 포함하는지 확인하고 만약 5개의 스레드가 필요하면 5개의 스레드를 나누어 준다.
⇒ 필요하다고 하는 CPU 만큼 해당하는 application 에 할당해 스레드들을 동시에 실행시킨다.
가정
동시에 실행을 하지 않으면, Performance에 심각한 Damage 가 있다.
⇒ Parallel application
시스템 안에 N 개의 프로세서가 있다고 가정했을 때, 스레드의 개수는 N보다 작거나 같아야 한다.
CPU 개수 >= Application 의 thread 의 수
문제점
CPU 개수 < Application 의 thread 의 수 라면, Scheduling 이 불가능하다.
A set of related threads is scheduled to run on a set of processors at the same time
- Threads often need to synchronize with each other
- Simultaneous scheduling of threads that make up a single
process - Useful for medium-grained to fine-grained parallel applications whose performance severely degrades when any part of the application is not running
Processor allocation must be considered
- N processors
- for M applications
- w/ N or less thread
Time sharing
- 1/M of the available time on the N processors, for each
application - Scheduling weighted by the number of threads
CPU 를 1/M 씩 나누어 실행하면 밑의 예시의 Group1 의 그림과 같이 놀고 있는 CPU 의 수가 증가하게 되며, CPU 의 Utilization 이 굉장히 나빠진다.
Utilization 은 같은 time quantum 을 사용할 때 좋지 않다.
⇒ 스레드의 개수 에 따라 time quantum 을 다르게 주어야 한다.
⇒ idle time 을 줄일 수 있다.
Thread Example
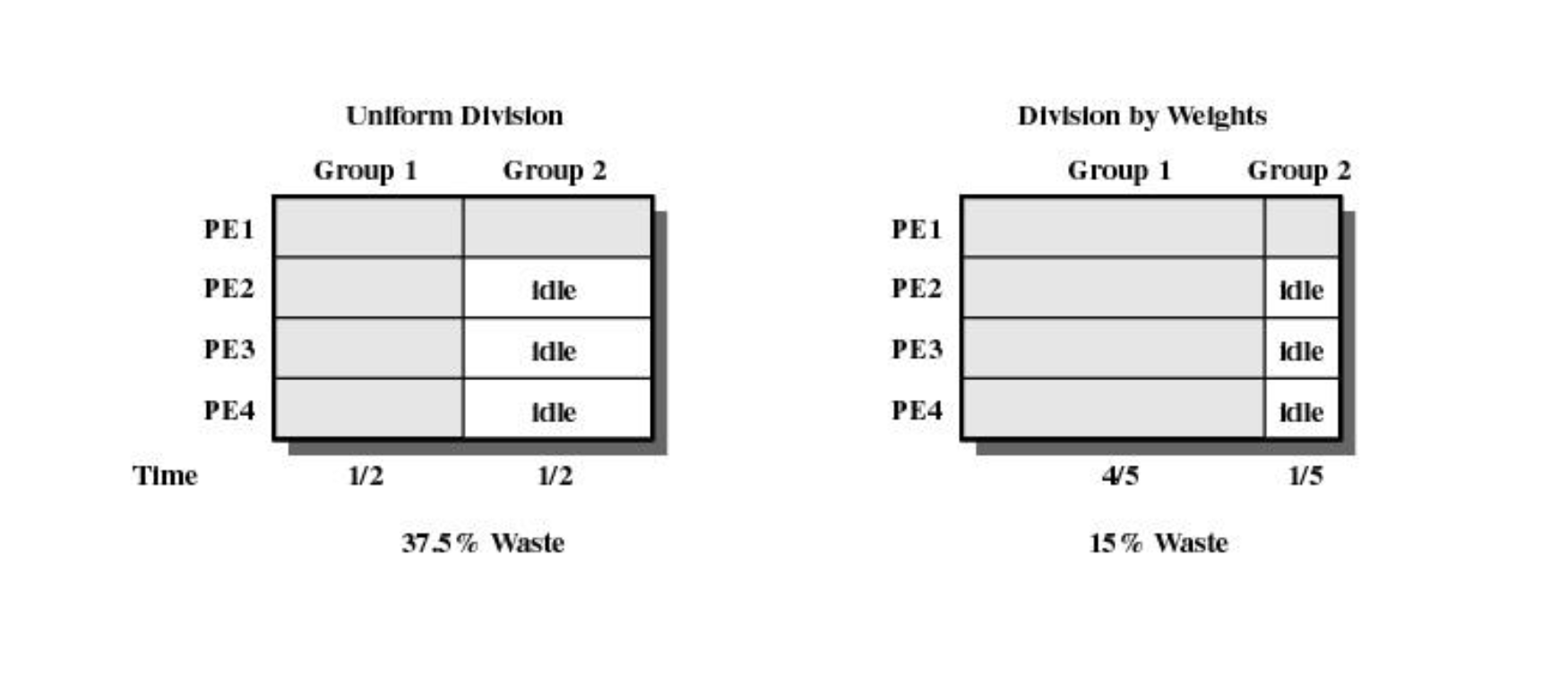
Application 이 여러개 있을 수 있다. → Gang Scheduling 은 기본적으로 Round Robin , Time Sharing 을 한다.
내가 A → B → A → B → ... Application 을 번갈아 가며 실행한다. A 라는 Application 의 스레드를 동시에 실행하고, B 라는 Application 의 스레드를 동시에 실행한다.
Time quantum 을 어떻게 결정할 것인가?
그림에서 PE 는 CPU 를 나타낸다. 즉, CPU 가 4개 존재하는 시스템이다. Group 라는 2개의 application 이 실행을 하고 있다.
- Group1 은 4개의 스레드를 가지고 있다.
- Group2 는 1개의 스레드를 가지고 있다.
↳ Group2 가 실행될 때는 CPU 2, 3, 4 는 놀게 된다.
그럼 놀고 있는 CPU 2, 3, 4 를 Group1 에게 주어도 되지 않을까? 싶지만,
여기서의 가정은, Group1 의 네개의 스레드는 굉장히 밀접하게 동기화 하기 때문에
⇒ Group 1의 2, 3, 4 만 실행해도 1을 못해서 block 될 수 있기 때문에 Group2 를 실행할 때 CPU 2, 3, 4 를 Group1에게 주지 않는다.
Time Quantum 을 group1에 더 많이 주게 되면 IDLE 이 15% 정도 줄게 된다.
Dedicated Processor Assignment
Gang Scheduling 보다 한 단계 앞선 Scheduling 기법이라고 볼 수 있다.
Gang Scheduling 과 공통점
- Global Queue 에 Process 들이 줄 서 있다.
- 어떤 프로세스가 Scheduling 되면 그 프로세스가 가지고 있는 스레드 개수만큼 CPU 를 할당한다.
- CPU 에서 스레드은 동시에 실행된다.
Gang Scheduling 과 차이점
CPU 에서 스레드은 동시에 실행되는데, Time swapping X, Round robin X, Switching X
한번할당 → 계속 실행
⇒ 이유? application 안의 애들이 밀접하게 동기화 한다.
Round Robin 이나 Time Sharing 은 time out 이 되면 Switching 을 하게 되는데 그 시간도 아깝다는 것이다. 그 시간을 아껴서 계속 실행을 하겠다는 의미이다.
가정
이 application 들은 Parallel Program 이다.
↳ User 와 interaction X, 굉장히 많은 양의 file에서 Data 를 많이 읽고 많은 computation 을 한 후, 결과값을 file 에 적는다.
⇒ I/O 에 의한 Block 이 거의 없다.
최대한 빠르게 작업을 시키기 위해서 사용되는 Scheduling 기법이다.
어떤 경우에도 멈추지 않는다.
When application is scheduled, its threads are assigned to a set of processors
- Threads are assigned to a specific processor
- # of threads = # of processors
Some processors may be idle if some threads of an application are blocked for I/O or synchronization
Avoids process switching
Dedicated Processor Assignment 의 문제점
Processor fragmentation problem
16개의 CPU와 스레드 5개를 가지는 3개의 application 3개를 동시에 실행 → 5 5 5 개씩 CPU 를 나누어 준다.
⇒ CPU 가 1개 남는다. → 너무 작기 때문에 다른 스레드를 실행시킬 수 없다.
Scheduling 의 목적
프로그램을 실행하는 순서가 아니라, CPU 를 어떻게 application에게 어떻게 (몇개씩 한번에) 할당을 할까?
application 이 Ready Queue 에 굉장히 많다고 했을 때, Processor fragmentation problem 이 없게 하려면, 5 5 5 보다 5 3 3 4 과 같이 16개를 딱 맞추는 게 훨씬 효과적이라고 생각할 수 있다.
1개의 application 에 여러개의 CPU 를 할당하고도 CPU가 남는상황에서 Gang Scheduling 이나 Dedicated Processor Assignment 를 사용하는 것이다.
Dynamic Scheduling
줄 수 있는 최대한의 CPU 를 나누어 준다.
Global Sharing ↔ Gang Scheduling , Dedicated Processor Assignment 기법의 중간 정도의 CPU 개수를 보유한 시스템에서 사용하는 기법이다.
Gang Scheduling , Dedicated Processor Assignment 기법의 Scheduling 은 많은 CPU 를 어떤 application 에게 할당할지 OS 가 관리한다.
OS is responsible for partitioning the processors among the jobs
Multi-Processor System 에서 Scheduling 은 내가 가지고 있는 굉장히 많은 CPU 를 언제 누구한테 몇개 나누어줄것인지를 결정하는 것인데, 이 작업을 OS 가 한다.
OS 는 CPU 를 잘 나눠서 각각의 application 에게 나누어 주는 역할을 한다.
각각의 application 은 CPU 를 할당을 받는데, 자기가 원하는 개수보다 부족할 수 있다. 나는 5개의 CPU 가 있으면 동시에 5개의 스레드를 실행시킬 수 있는데, application 은 5개가 필요하지만 CPU 는 3개만 줄 수 있다. 이렇게 되면 5개의 스레드를 3개의 CPU 에서 실행을 시켜야 한다. 그러면 5개의 스레드를 3개의 CPU에서 어떠한 순서대로 어떻게 실행시킬까 하는 것은 application level 에서 결정하는 것이다.
OS의 역할 = CPU 를 나누어 주는 것- 실제 나누어 받은 CPU 안에서의 Scheduling 은
user level application에서 실행된다.
Each job uses the processors currently in its partition to execute some subset of its runnable tasks
- 일단 어떠한 job 이 필요한 CPU 의 개수를 이야기한다. → 5개가 필요하다.
- 만약 5개의 idle 한 CPU 가 있으면, 당연히 5개를 나누어준다.
- 만약 남아있는 CPU 가 3개라면 3개를 나누어준다.
⇒ 일단, 달라고 하면 존재하는 놀고 있는 CPU 들을 있는만큼 준다.
↔ 만약, 아예 줄게 없으면 다른 application 이 사용중인 CPU 뺏어서 준다.
↳ 다 뺏진 않고, 각각의 application 이 필요한 최저치보다 많이 가지고 있는 CPU 를 뺏게 된다. 경우에 따라서는 각각 다 최저치 만큼만 갖게 될 수 있는데, 이 경우 해당하는 application 은 Ready Queue 에서 기다려야 한다.
Ready Queue 에서 기다려야 하는 application 이 생길 수 있는데, 어떠한 프로세스가 실행을 끝마치면, CPU 가 많이 반납되게 되어 Ready Queue 에 5명이 기다리고 있는데 CPU 가 5개 있으면 5명에게 1개씩 나누어 준다. 즉, 최소 1개씩은 갖게되어 실행을 시작할 수 있게 된다. 그 다음에 남아있는 것은 Frist Come First Basis ( FCFS )로 가장 오래 기다린 프로세스에게 CPU 를 주게 된다.
An appropriate decision about which subset to run is left to the individual application
OS 의 역할은 실제 스케쥴링 → application level 에서 결정한다. → 가능한 만큼 준다.
⇒ 실제 CPU 개수 < application 스레드 필요 개수 여도 실행 가능하다는 장점이 있다.
When a job requests one or more processors;
- Assign idle processors
- New arrivals may be assigned to a processor that is used by a job currently using more than one processor
- Hold request until processor is available
Upon release of one or more processors;
- Assign a single processor to each job in the queue that currently has no processors
- Allocate the rest of the processors on an FCFS basis
Real-Time Scheduling
Real-Time task 는 정확도 는 기본적으로 중요하고, 거기에 Deadline 을 맞춰야 한다.
→ Deadline 을 지나치면 필요없는 결과값이 된다.
- 정확한 실행
- Deadline 맞추기
Real-time computing
type of computing in which the correctness of the system depends not only not the logical results of the computation, but also the time at which the results are produced
1. Hard real-time task
one that must meet its deadline; otherwise it will cause unacceptable damage or a fatal error to the system
deadline 을 못 맞추면 시스템에 데미지가 가해지기 때문에 반드시 deadline 을 맞춰주어야 한다.
2. Soft real-time task
associated deadline is desirable but not mandatory
deadline 을 맞추면 좋은데, deadline 을 못 맞추더라도 시스템에 데미지가 가해지진 않는다.
시스템 관점 에서 중요한것: Througput ⇒ deadline 을 못맞추면 Throughput 에 포함되지 않기 때문에 Throughput 을 높이기 위해 deadline 을 맞춰야 한다.
periodic task & aperiodic task
1. periodic task
주기가 있는 task 이다.
2. aperiodic task
주기가 없는 task 이다.
주기가 없어 예측이 불가능하기 때문에 미리 Scheduling 이 불가능하다.
주로 Soft real-time task 인데 periodic 하게 도착하는 task 에 대해서 어떻게 Scheduling 하면, deadline 을 최대로 맞추고 Througput 을 최대로 만들 수 있을까? 가 Real-time Scheduling 에서 얘기가 된다.
Real-time Scheduling
1. Earliest-deadline Scheduling
Deadline 이 빠른 task 를 먼저 Scheduling 한다.
realtime task 는 우선순위가 정해져 있다.
- deadline
- 도착 주기
우선순위를 무조건 맞춰야 한다.
⇒ Real-time Scheduling 은 우선순위에 의한 Preemptive 가 존재한다.
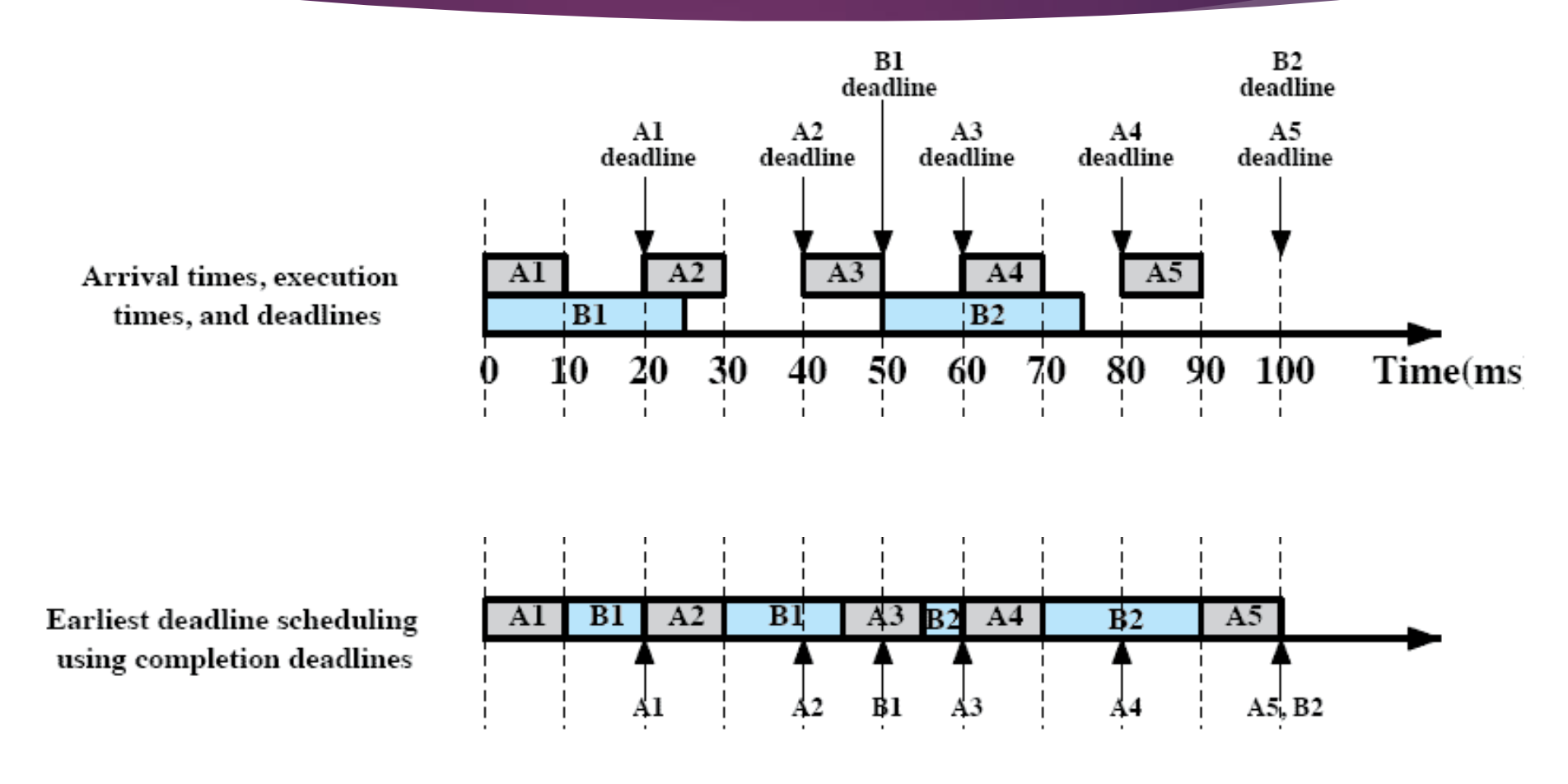
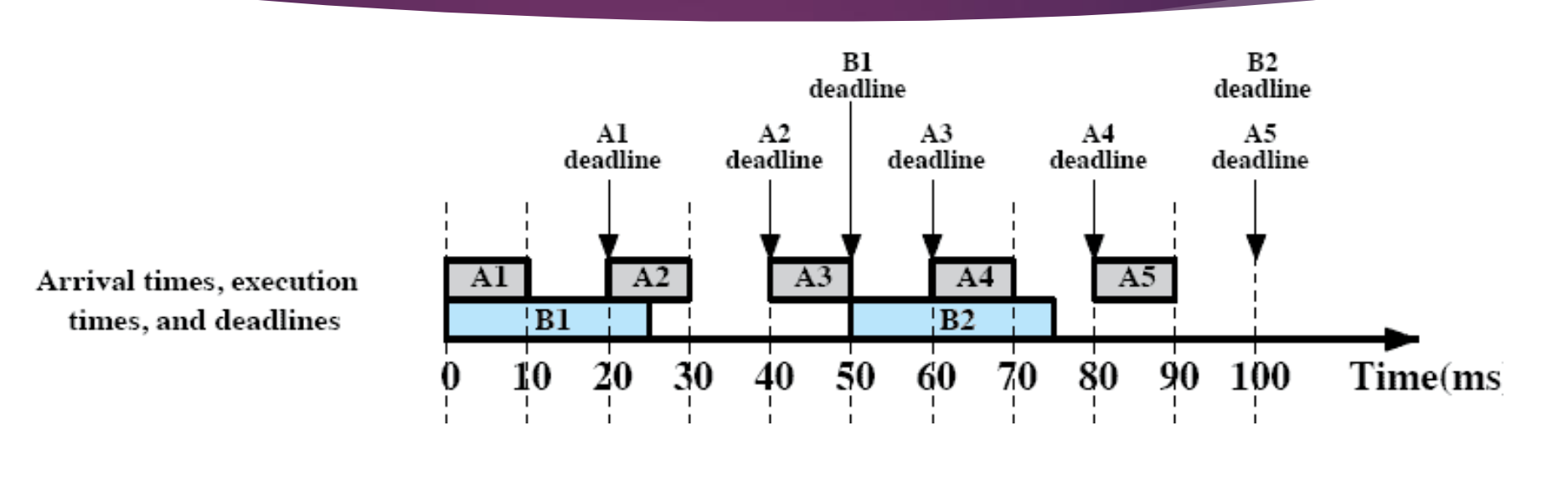
각 task 는 본인의 다음 task 가 올 떄까지 (deadline) 이 오기 전까지 작업을 마쳐야 한다.
- A task 는 20분 주기로 1번씩 도착 / 10분간 작업한다.
- B task 는 50분 주기로 1번씩 도착 / 20분간 작업한다.

↑ Scheduling 의 결과
B1과 A3 를 비교할 때는 B1의 deadline 이 먼저 끝나므로 B1 을 먼저 실행한다.
B2 와 A5 를 비교할 때, 둘 다 deadline 은 같지만 이 경우 먼저 도착한 애가 먼저 실행되기 때문에 B2 를 먼저 실행한다.
⇒ 매번 새로운 job 이 도착할 때마다 실행하고 있던 task가 끝날 때마다 다음에 누구를 실행을 시켜야 할지를 결정한다.
↳ 여기서는 Deadline 이 빠른것을 먼저 선택한다.
Real-time Scheduling
2. Rate Monotonic Scheduling
우선순위가 deadline 이 아니라 주기인 Scheduling 이다.
주기가 짧은 걸 먼저 실행한다. ⇒ 주기가 짧다는 것은 deadline 이 금방 다가온다는 뜻이므로, deadline 이 금방 끝나는 것과 일맥상통한다.
Rate Monotonic Scheduling 은 Earliest-deadline Scheduling 보다 더 많이 사용되는 방식이다.
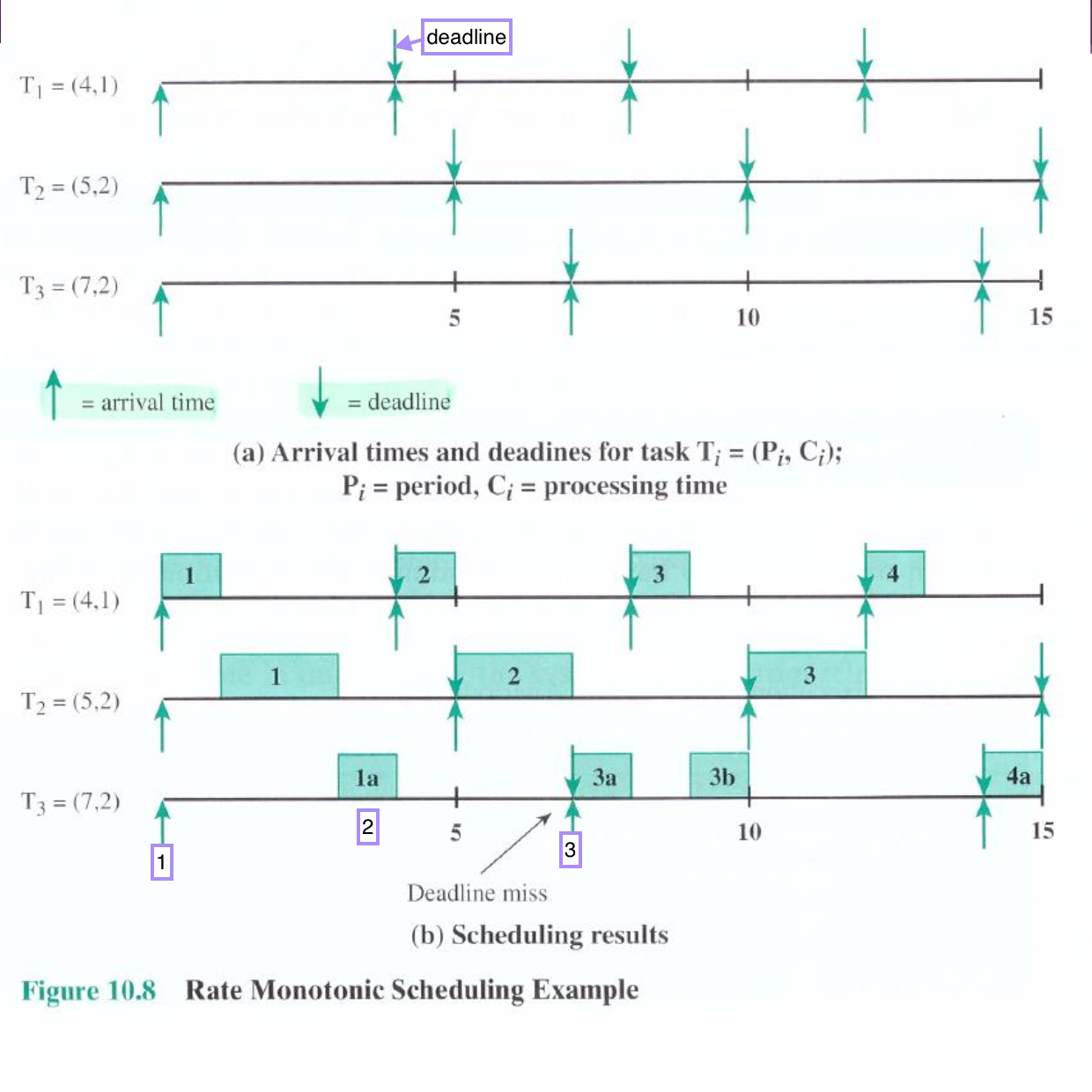
↓: deadline 시간↑: 도착 시간
3개의 task T1, T2, T3 가 존재한다.
- T1 - 주기: 4시간 / 실행: 1시간
- T2 - 주기: 5시간 / 실행: 2시간
- T3 - 주기: 7시간 / 실행: 2시간
따라서 우선순위는 T1 > T2 > T3 이다.
- 0시에 동시 도착하고 우선순위가 제일 높은 T1 부터 실행한다.
- T3는 한시간 작업하고 T1의 다음번 Task 가 와서 중지하고 T1 을 서비스 한다.
- T3 는 deadline 이 지나버렸다..!
Real-time Scheduling
→ Priority Inversion
Priority Inversion: 모종의 이유로 우선순위가 더 높은 task 가 우선순위가 더 낮은 task 를 기다리는 상황
여기서 우리가 어떻게 해결할 수 있는 상황이 아니다.
- Scheduling 은 Scheduler 가 한다.
- OS 가 application 안의 code 를 실행하는데 Critical Section(semWait) 에서 우선순위를 따지지 않는다.
→ 먼저 통과한 애가 먼저 실행된다.
⇒ Scheduling과 Critical Section 은 완전히 별개의 작업이다.
Priority Inversion 은 발생할 수 밖에 없지만, Unbounded priority inversion 은 막아야 한다.
Unbounded priority inversion
Unbounded priority inversion: 계속해서 Priority Inversion 이 발생하는 상황
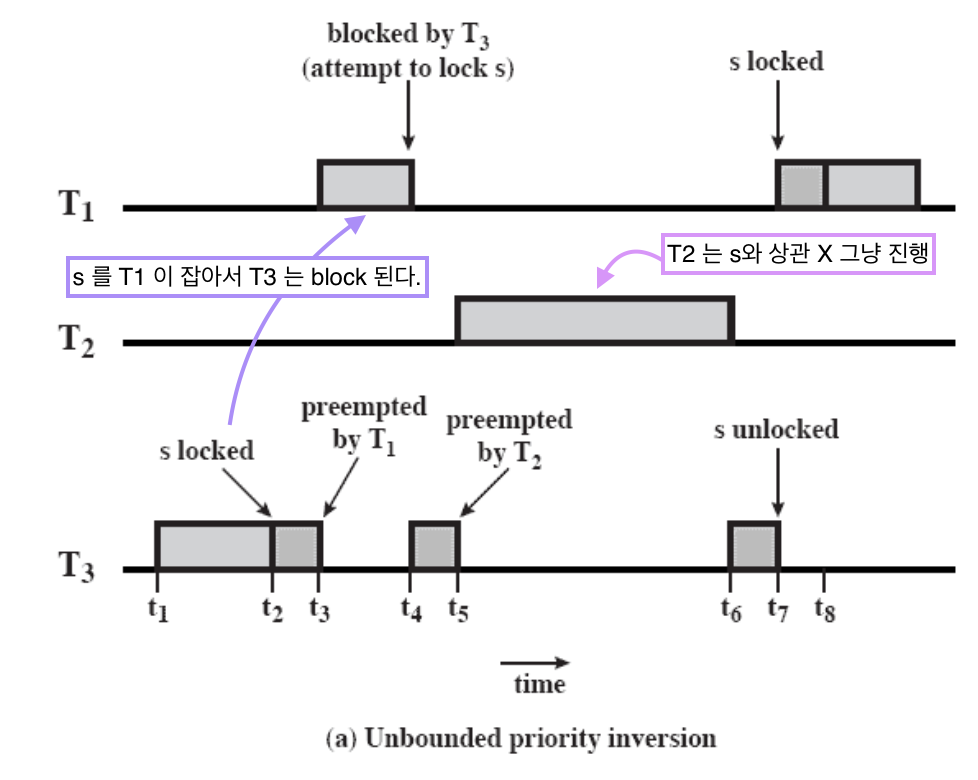
우선순위 T1 > T2 > T3
- T3 가 critical section 인 s 를 lock 시킨다.
- t3에 우선순위가 높은 T1 에게 CPU 를 빼앗기지만 s 는 이미 T3 가 이용 중이므로 T1 은 s 를 이용할 수 없다.
- T3 는 잠깐 동안 진행하다 t5에 온 T2 에게 CPU 를 빼앗긴다.
- CPU 를 빼앗은 T2 는 s 와 상관이 없어 계속 진행한다.
- t6에 다시 CPU 를 잡은 T3 는 작업을 마치고 s 를 unlocked 한다.
- T1 이 CPU 를 잡고 다시 s 를 lock 시키고 작업을 한다.
Unbounded priority inversion 해결 방법
⇒ Priority inheritance
해결방법: T3 의 우선순위를 일시적으로 높여준다.
a lower-priority task inherits the priority of any higher-priority task pending on a resource they share
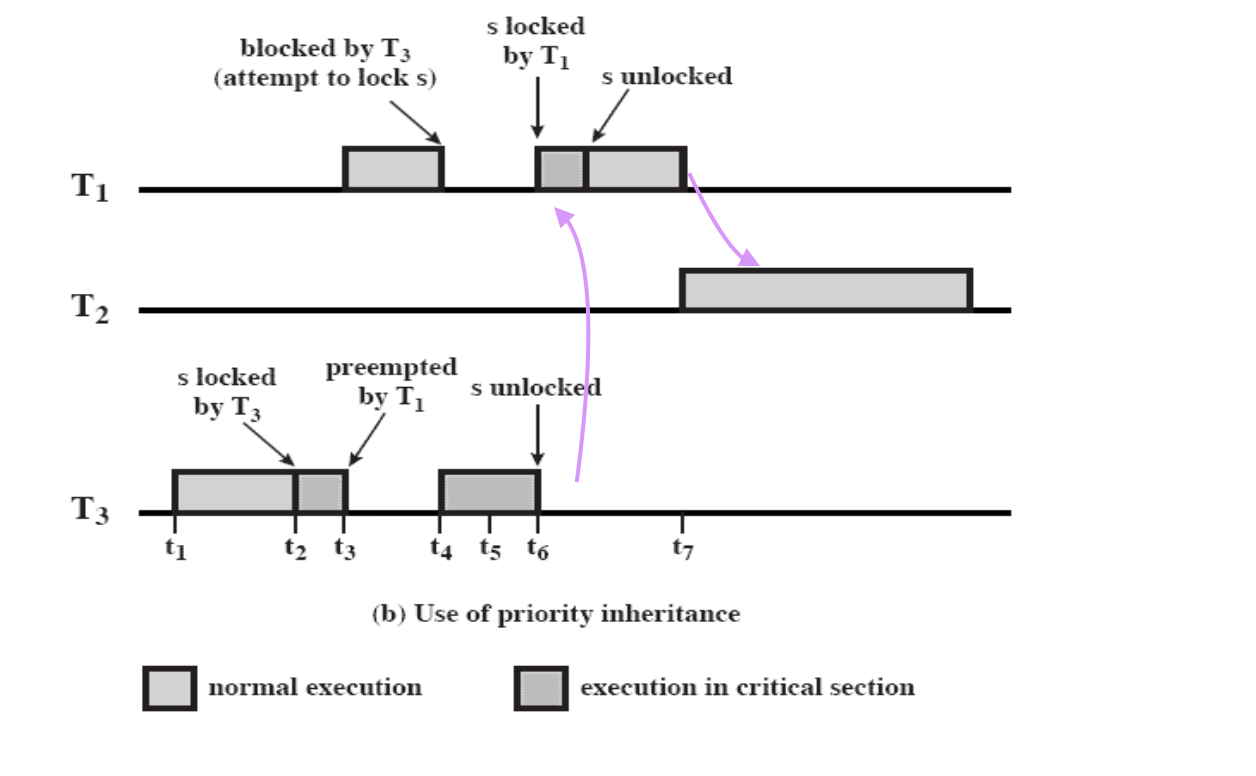
T3 가 작업하다 T1 에게 CPU 를 걸고 T1 이 s 에 lock 을 걸려고 할 때, T3 의 우선순위를 T1 만큼 높여준다.
⇒ T2 보다도 우선순위가 높아져서 T3 가 먼저 실행된다.
Window Scheduling
Multi-level Priority Queue
- Real-time Priority Queues (16 Levels)
- Variable Priority Queues (16 Levels)
총 32 개의 Ready Queue 가 있으며 각각 16개씩 나누어져 있다.
Real-time Priority Queues
→ Real-time task 를 위한 queue
↳ fixed priority 를 가진다.
Real-time task 는 우선순위가 deadline 이므로 우선순위가 변하지 않는다. 같은 우선순위를 갖는 task 는 존재할 수 있는데, 이때는 Round-Robin 으로 스케쥴링을 한다.
Variable Priority Queues
→ Non-real-time task 를 위한 queue
↳ 우선순위가 변한다.
내가 CPU 를 한번 잡고 실행을 하고 나면, 어떻게 실행을 했느냐에 따라 우선순위가 달라질 수 있다. 일종의 Feedback Queue 라고 생각할 수 있다. 우선순위가 높아질 수도 낮아질 수도 있다.
Jobs in Real-time Priority Queues
- Fixed Priority
↳ 우선순위: DeadLine 인 애들이 많다. - RR within a Queue
↳ 같은 우선순위를 갖는 task 들
Jobs in Variable Priority Queues
- Feedback Queue
↳ 내가 지금 작업한 내용에 따라서 우선순위가 높아질 수도 작아질 수도 있다.
Windows Thread Dispatching Priorities
Starvation 에 대한 고려를 전혀 하지 않는다.
우선순위는 다음과 같다.
- 31: A
- 30: B
- 29: C, D
- 28: E
CPU 가 1개라면, A → B → C D C D (Round-Robin) ... → E
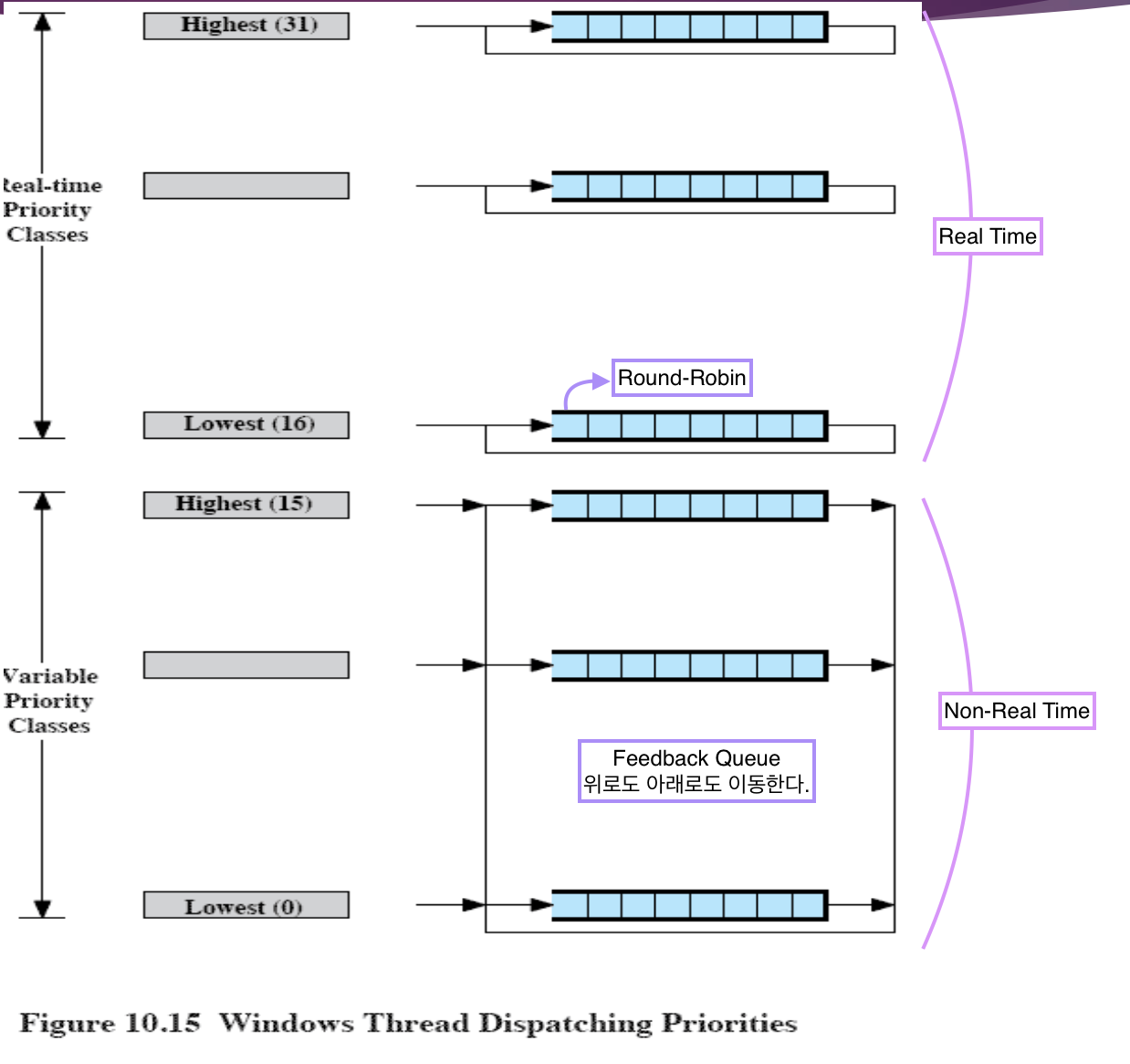
Priority-Driven Preemptive Scheduling
우선순위 기반 Preemptive Scheduling 이다.
Real Time Task
- 위에 큐가 다 비어져야 밑의 큐 Scheduling 가능
- 위의 큐에 task 가 오면 현재 작업 중단 하고 우선 순위가 높은 task 먼저 실행한다.
- 우선순위가 같은 경우에만 round-robin 을 한다.
Jobs in Real-time Priority Queues
RR for the Jobs w/ the Same Priority
29하다가 30 드들어오면 무조건 멈추고 우선순위 높은 애를 먼저 실행한다. 같은 경우에만 round-robin 방식을 실행한다.
Non Readl Time Task
→ 9Priority Feedback for Jobs in Variable Priority Queues
Processor-bound threads down
OS 가 봤을 때, 내 실행 방식이 좋으면 우선순위가 높아지고, 내 실행방식이 좋지 않으면 우선순위가 낮아진다.
OS 가 좋아하는 실행 방식이란?
↳ CPU 를 안쓰고 I/O 작업이나 동기화를 많이 하는 것을 좋아한다.
만약 내가 10번 큐에서 나가서 CPU 를 잡았다면, 기본적으로 Variable Priority Queue 에 있는 task 들은 Timeout 을 둬서 작업을 할 것이다. Timeout 까지 작업을 할 수 있는데, Timeout 을 다 쓴 경우, OS 는 얘를 싫어하게 된다.
I/O-bound threads up
주어진 Timeout 을 다 쓴 스레드를 의미한다.
이 스레드들은 다음번에 우선순위를 낮추어서 9번, 8번, 7번 큐에 집어 넣게 된다. 반면, 내가 10번 큐에서 나가서 CPU 를 잡았는데 CPU 잡자마자 I/O 작업을 한다든지, 메시지 receive 를 한다든지, 동기화를 한다든지 block 상태가 된다.
⇒ blocked queue 로 온다.
→ 이후 작업을 마치고 다시 Ready Queue 로 올 때, 10번에서 나왔지만 11번, 12번, 13번 큐로 올려주게 된다.
Feedback Queue 에 있는 task 들의 우선순위
- CPU 를 많이 사용 → 우선순위 ↓
- CPU 를 적게 사용, I/O, 동기화, ... 많이 할 수록 → 우선순위 ↑
within a certain range
그러나 우선순위가 무조건 낮아지고 무조건 높아지는 것은 아니다. 범위가 존재한다.
프로세스의 우선순위, 스레드의 base 우선순위, 스레드의 dynamic 우선순위
→ 모든 프로세스는 프로세스의 base priority 를 가진다. 이것은 어떤 일을 하는 프로세스냐에 따라 달라진다.
- 일반적인 user process 인 경우에는, 우선순위가 낮다.
- 시스템 작업을 하는 process 의 경우에는 우선순위가 높다.
⇒ 프로세스의 종류에 따라서 base priority 가 결정된다.
base priority
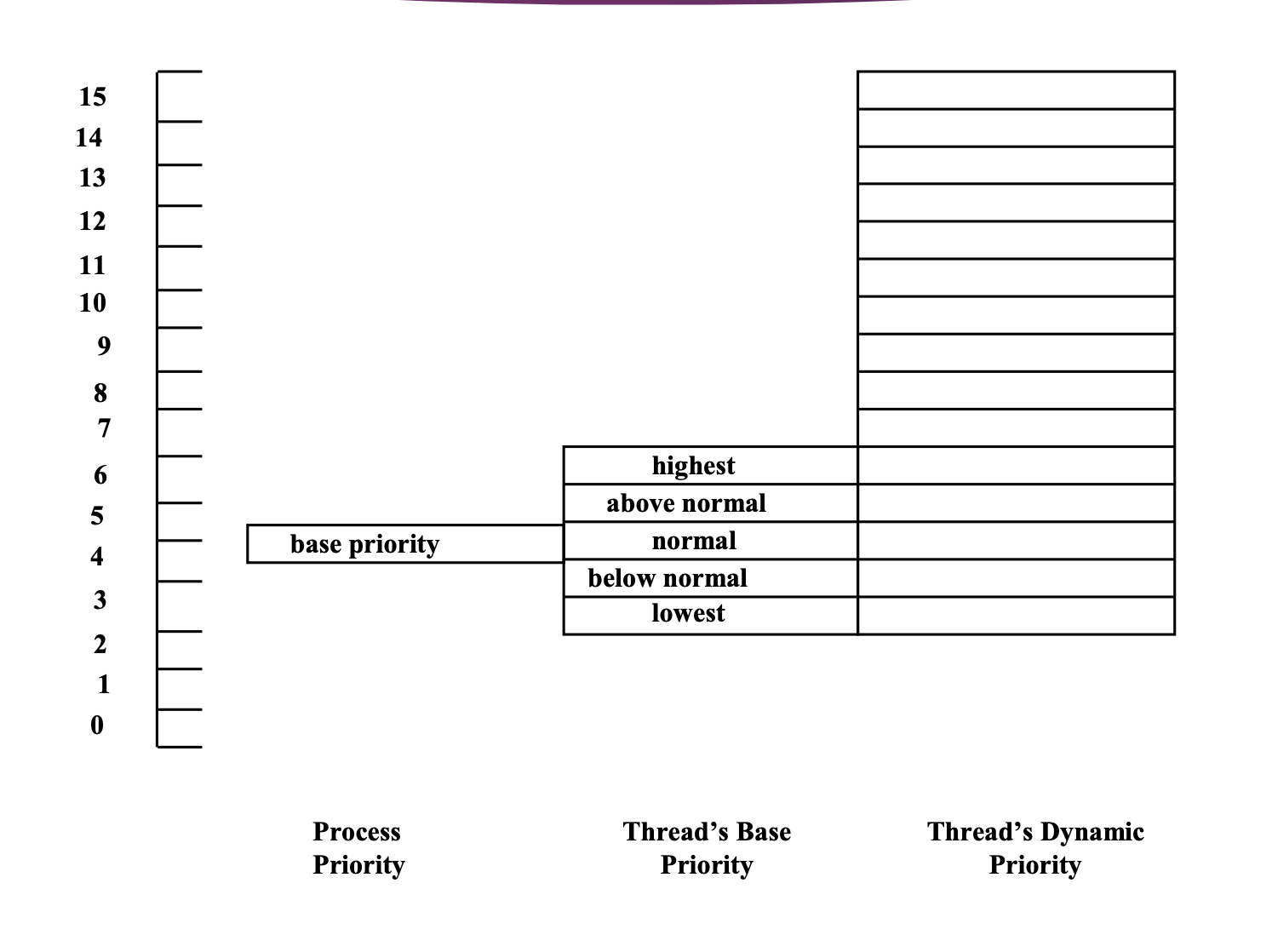
현재는 base priority 가 5로 정해져 있다.
스레드의 base priority 는 프로세스 안에서 스레드를 만들어 낼 때 자체적으로 결정하는데, 여러 스레드를 만들 때 스레드들에게 다 똑같은 우선순위를 줄 수도 있지만, 이 스레드는 조금 더 중요한 일을 하므로 우선순위를 조금 더 주고 저 스레드는 조금 덜 중요한 일을 하니까 우선순위를 낮춰주고 할 수 있다.
이러한 스레드들의 base priority 는 프로세스의 base priority +- 2 만큼이다.
즉, 프로세스의 base priority 가 5인 경우의 최저 3, 최대 7까지 스레드의 base priority 를 application 안에서 조정할 수 있다.
3 ← 5(proces) → 7 (base)
프로세스의 base priority 나 스레드의 base priority 는 프로그램 성격에 따라 조정이 된다. 실제로 실행이 되며 조정되는 부분은 마지막 스레드의 dynamic priority 이다.
처음에는 굉장히 낮은 base priority 로 시작했지만 얘는 CPU 잡을 때마다 계속 I/O 작업을 하거나 동기화 작업을 해서 Timeout 을 다 못 쓰면, 점점 우선순위가 위로 올라간다.
→ 최대치로 15까지 우선순위가 올라갈 수 있다.
당연히 16부터는 real-time-task 이므로 거기까지는 올려주지 않는다.
↳ Variable Queue 에서 제일 높은데 까지만 올라갈 수 있다.
단, 내려갈 때는 막 내려가서 0까지 내려가진 않고 스레드의 base priority 의 최저값까지만 내려간다.
↳ 왜냐하면 application 자체가 어떤 특정한 역할을 하는 application 이기 때문에 스레드가 CPU 를 많이 쓴다고 해서 우선순위를 너무 낮추어서 (시스템 작업을 하는 application 인데,) 실행이 안되면 안되기 때문이다.
⇒ 이렇게 적절한 범위 안에서 스레드의 우선순위를 우리가 바꿔준다.
Multiprocessor Scheduling w/ N Processors
Windows 시스템은 당연히 Multiprocessor 를 가정하고 Scheduler 를 만든다. 실제 CPU 는 하나가 아니라 여러 개가 되는 것이다.
N 개의 CPU 를 가지는 시스템이라고 했을 때, Queue 그림을 보여주면 Queue 도 32개, CPU 도 32개라 0번 CPU 가 0번 Queue, 1번 CPU 가 1번 Queue, ... 와 같이 담당하나 착각할 수 있지만, 그게 아니라 언제나 우선순위가 높은 것 부터 작업을 해야한다.
실제 CPU가 몇개든 상관 없이 모든 N개의 CPU 는 내가 실행을 하다가 실행하던 작업이 끝나면(Timeout 등으로) Queue 에 가서 다음에 실행할 스레드를 가져오는데, 제일 우선순위가 높은 Queue 부터 다음에 실행할 스레드를 가져온다.
⇒ Idle-While-Busy 는 존재하지 않는다.
⇒ 32개의 Queue 가 하나의 Global Queue 이다.
우선순위가 낮은 스레드가 실행되고 있는데, 우선순위가 더 높은 스레드가 Queue 에서 기다리는 상황도 존재하지 않는다.
↳ 왜냐하면, 항상 우선순위가 높은 것 부터 스레드를 가져오기 때문이다.
언제나 N 개의 제일 우선순위가 높은 스레드가 동시에 N개의 프로세서에서 실행이 되는 방식이다.
제일 우선 순위가 높은 것부터 N 개를 가져다가 실행을 한다.
- Dispatcher assigns a ready thread to the next available processor - No processor is idle or executing a lower-priority thread when a higher-priority thread is ready
- Kernel tries to give the N processors to the N highest-priority threads that are ready to run
Soft affinity
dispatcher tries to assign a ready thread to the same processor it last ran on – processor’s cache reuse
어떤 스레드가 N개의 CPU 가 있다고 할 때 캐시는 무용지물이 된다. CPU 를 계속 바꾸는 것은 캐시의 입장에서는 좋지 않다.
Thread 의 Processor affinity : 이 스레드는 몇번몇번 CPU에서 실행을 하는 것이 좋다.
↳ 왜냐하면 거기에 내 캐시가 존재하기 때문이다.
Soft affinity: Scheduling 를 할 때, 우선순위가 높은 것 부터 꺼내가는 것은 맞지만, 가급적 내가 아까 실행한 적이 있는Processor affinity에 맞는 CPU 에 우선적으로 할당을 하는 것이다.
문제점
Traditional Unix System 에서는 CPU 사용 시간을 우선순위에 기준으로 잡아 공정성을 중요하게 여겨 Starvation 가능성을 0 이라고 봐도 좋다. 하지만, Windows System 은 Starvation 은 전혀 고려하지 않고 있다.
