9장에서의 CPU 는 1개만 존재한다.
Replacement 의 성능 → Page Fault 수가 증가하면 성능이 낮아진다.
Aim of Scheduling
- Response time
- Throughput
- Processor efficiency
- Fairness
위의 네가지가 스케쥴링의 목표이지만, 애매하고, 동시 만족이 불가능하다.
1. Response time
Input ↔ Output 사이의 걸리는 시간
응답 시간이 짧으면 짧을 수록 좋다.
2. Throughput
User 의 관점이 아니라 시스템의 관점에서 단위 시간 동안 몇 개의 request 를 완료했는지를 말한다.
⇒ 크면 클수록 성능이 높아진다.
3. Processor efficiency
CPU 가 의미 있는 일에 사용된 시간
CPU 는 OS 실행이 아니라 User Program 이 정확하고 신속하게 사용하려고 만들어진 애이다.
4. Fairness
얼마나 공정한가?
→ 수로 표현할 수 없다. 단위도 없다.
1, 2, 3은 단위도 붙일 수 있고 수적으로 나타낼 수도 있다.
메모리는 기준이 명확하지만, 스케쥴링은 기준이 명확하진 않다.
Types of Scheduling
3가지 Scheduling
Long-term Scheduling
어떤 프로세스가 만들어 졌을 때 Ready Queue 로 가냐, Ready/Suspend Queue 로 가냐를 결정하는 스케쥴링
↳ 시스템 바깥쪽에서 시스템 안쪽으로 들어올 수 있느냐 없느냐를 결정한다.
어떤 프로세스가 만들어 졌을 때, 스케쥴링이 만들어진다고 바로 메모리에 들어오지 못할 수도 있다.
Ready Queue 에 너무 많은 프로세스들이 있고 메모리에 너무 많은 프로세스들이 있으면 시작부터 Suspend 가 될 수도 있다.
- New → Ready
- New → Ready/Suspend
대부분의 프로세스들은 생성되면, Ready Queue 로 가지만 Batch Job 이라고 프로그램 실행
→ 입력과 출력 모두 파일에서 작업한다.
이 경우 User 가 실행을 시켜놓고 나중에 와서 결과만 확인한다. 이러한 프로세스 같은 경우 시스템 상황에 따라 Ready 상태로 보내기도 하고 Ready/Suspend 로 보내기도 한다.
performed when new process is created
Medium-term Scheduling
swapping 할 때, 언제 얼만큼 누구랑 바꿀지를 결정하는 스케쥴링이다.
swapping 과 관련이 있다.
시스템 안에 메모리가 한정적이기 때문에 어느 순간 Ready Queue 가 비고, Ready Queue 에 있었던 프로세스들이 전부 Blocked 상태가 되면 Blocked 상태의 메모리에 있는 프로세스와 하드디스크의 Swapping Area 에 있는 Ready/Suspend 상태의 프로세스들을 서로 자리를 바꾼다.
Short-term Scheduling
CPU 에서 실행할 프로세스를 선택하는 스케쥴링
Ready 상태에 있는 프로세스가 CPU 를 잡을 때, Ready Queue 에는 굉장히 많은 프로세스들이 존재한다.
CPU 안에 굉장히 많은 프로세스 존재 → CPU 가 하나인 시스템이므로 프로세스를 한번에 하나만 실행 → 누구를 선택할지? 하나를 고름
Ready → Running
which ready process to execute next
Block 상태 메모리
Types of Scheduling(2)
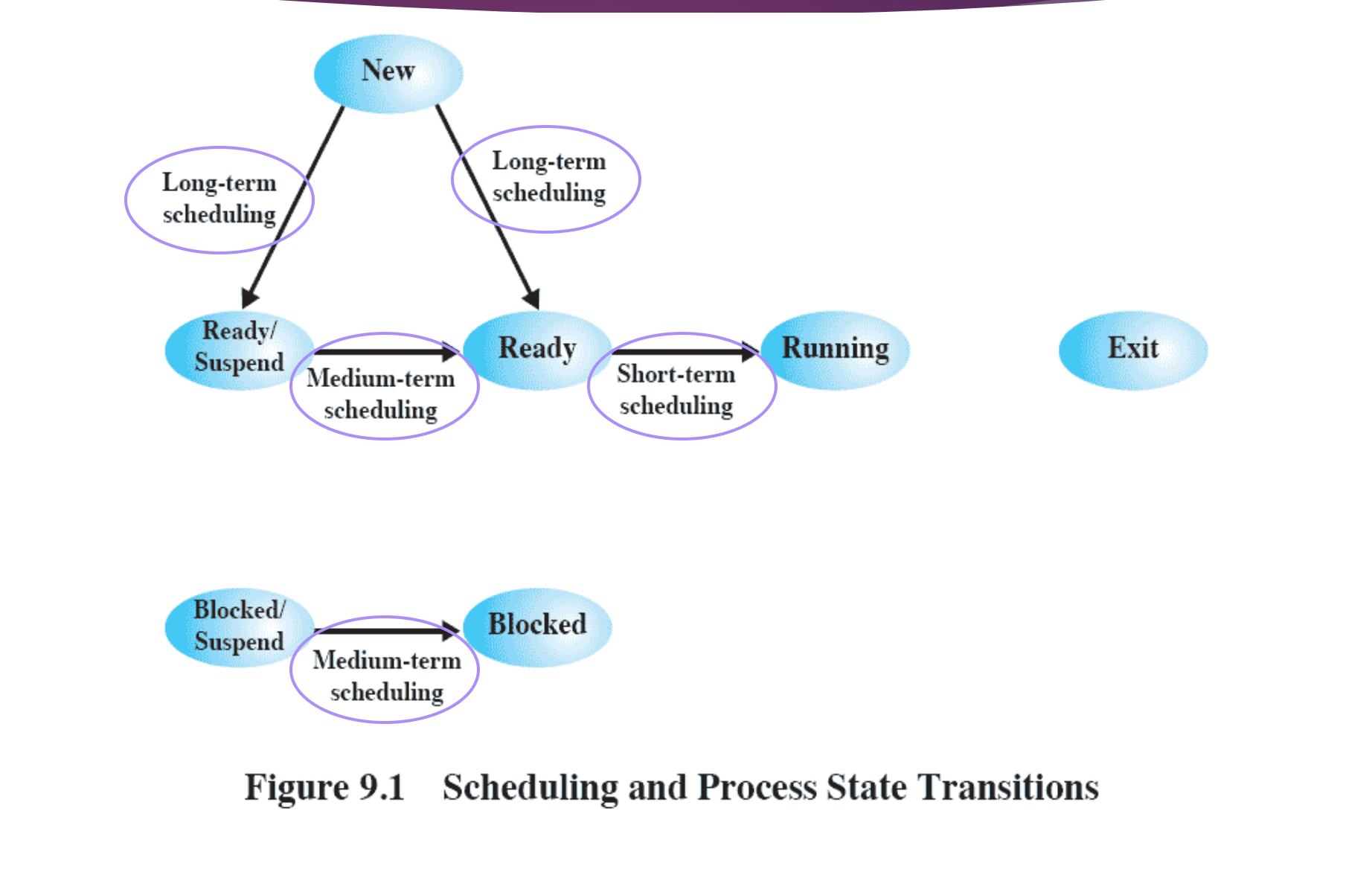
화살표 방향이 잘못되었다. 맨 밑 Blocked → Blocked/Suspend 방향으로 내려보내야 한다.
혹은 Ready/Suspend 상태 (Swapping Area) → Ready (Memory)
Types of Scheduling(3)

Short-Term Scheduling Criteria
Short-Term Scheduling 은 시스템 성능에 가장 큰 영향이 있다.
어떻게 해야 Scheduling 을 잘하는 건지 기준이 필요하다.
User-Oriented
- User System 의 관점에서 중요
- System 의 관점에서 상관 X
Response Time ↓
User 입장에서 Response Time은 짧은 게 좋다.
Elapsed time between the submission of a request until there is output.
Turnaround Time ↓
프로그램이 실행하고 끝날때까지 걸리는 시간
User 입장에서 Turnaround Time 은 짧은 게 좋다.
Elapsed time between the submission of a process and its completion
System-Oriented
- System 의 관점에서 중요
- 그나마 수치적으로 얘기가 가능하다.
utilization
System 입장에서는 Processor 를 얼마나 내가 효율적으로 사용하고 있는지가 중요하다.
Effective and efficient utilization of the processor
Throughput
단위 시간 동안 얼만큼 많은 작업을 끝낼 수 있는가?
Number of processes completed per unit of time
양적 성능 O , 질적 성능 → 예측 가능성, fairness(공정성)
예측 가능성
어떤 프로세스가 실행을 시작했을 때 언제쯤 끝날 지 예측을 할 수 있어야 한다.
우선 순위를 중요하게 생각하는 시스템에서는 예측 가능성이 떨어져서 최악의 경우에는 Starvation 이 발생하여 영영 실행되지 않을 수 있다.
fairness(공정성)
기회가 얼만큼 공정하게 주어지는가?
Performance-related
- Quantitative
- Measurable such as response time and throughput
Not performance related
- Qualitative
- Predictability and fairness
Priorities
우선순위를 결정해야한다.
시스템 스케쥴러는 어떤걸 기준으로 우선순위를 정할지 정해야한다.
→ fairness? 성능?
프로세스들을 우선순위가 높은 순서대로 줄을 쭉 세운다.
우선 순위가 동일할 경우 큐에 같이 넣는다.
Ready Queue 가 한 개있는 것 X → 여러개의 Multiple Ready Queue 로 나뉘어져 존재한다.
우선순위 Ready Queue 의 개수
- Windows → 32 개 (32개의 우선순위로 프로세스를 구분한다.)
- 다른 시스템 → 128 개 (128개의 우선순위로 프로세스를 구분한다.)
⇒ 우선순위에 따른 프로세스의 실행 순서가 시스템 성능에 어마어마하게 영향을 끼친다.
ex) 우선순위 Queue 가 300개일 때,
300번째 Queue 에 들어있는 프로세스가 CPU 를 잡으려면,
위의 299개의 Queue 가 다 비워져야 300번째 프로세스를 실행할 수 있다.
⇒ 시스템 마다 fairness 를 같이 고려우선순위가 낮을 수록 Starvation 이 발생할 수 있다.
Starvation 발생 하지 않게 하기 위해 → 우선순위 고려 및 정의해야 한다.
- Scheduler will always choose a process of higher priority over one of lower priority
- Have multiple ready queues to represent each level of priority
- Lower-priority may suffer starvation
allow a process to change its priority based on its age or execution history
Scheduing Algorithms
- First-Come-First-Served
- Round-Robin
- Shortest Process Next
- Shortest Remaining Time
- Highest Response Ratio Next
First-Come-First-Served 과 Round-Robin 은 Fariness 가 높고 성능이 떨어진다.
Shortest Process Next 과 Shortest Remaining Time 은 성능은 높지만 Fairness 를 전혀 고려하지 않는다. ⇒ Starvation 발생 가능성이 있다.
Highest Response Ratio Next 은 성능과 Fairness 를 모두 고려한다.
An Example
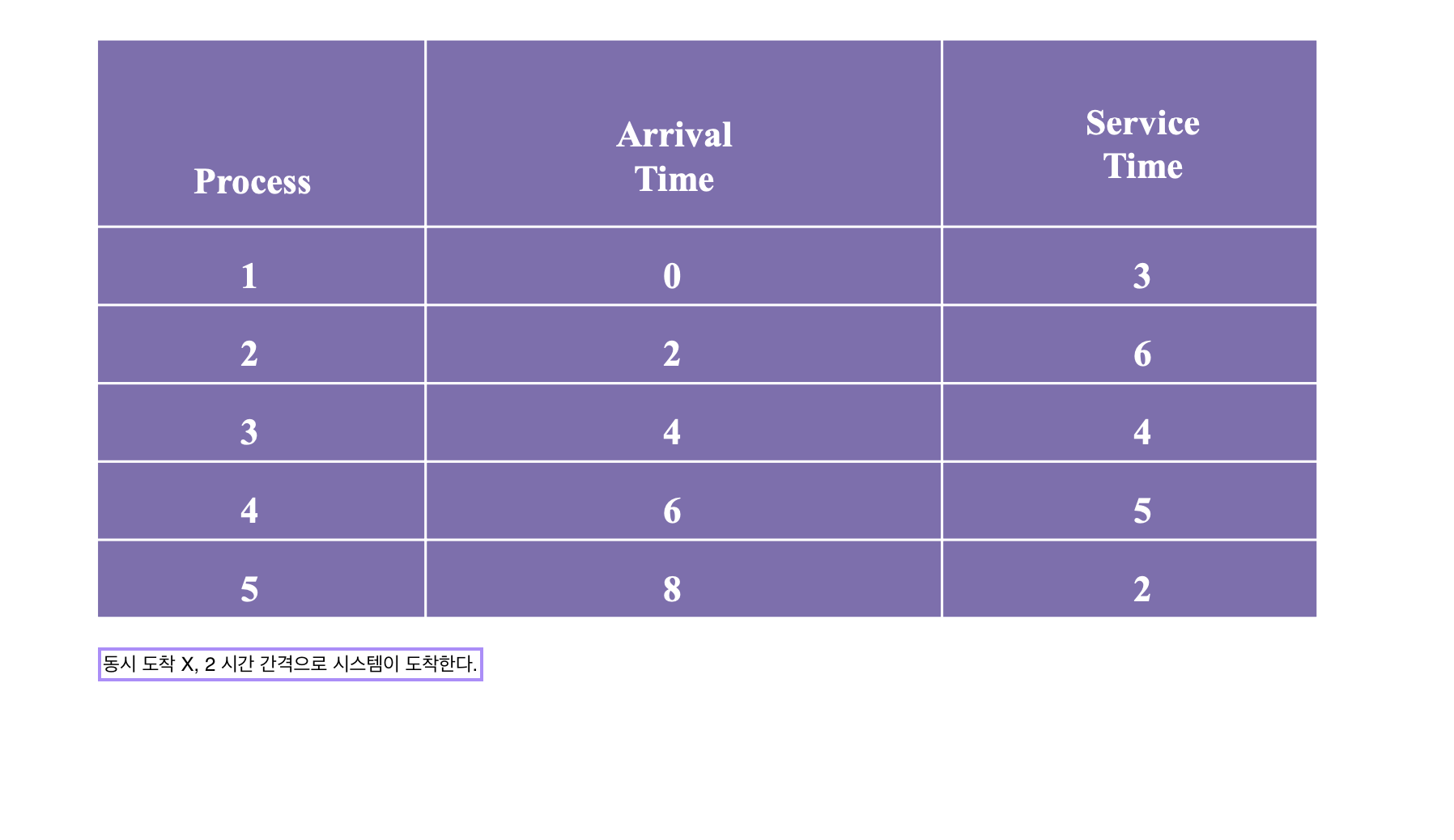
- 0시 → 2시 → 4시 → 6시 → 8시 순으로 프로세스 도착
- Service Time = 실행시간
Response Time
Response Time = Waiting Time + Executing Time 의 평균
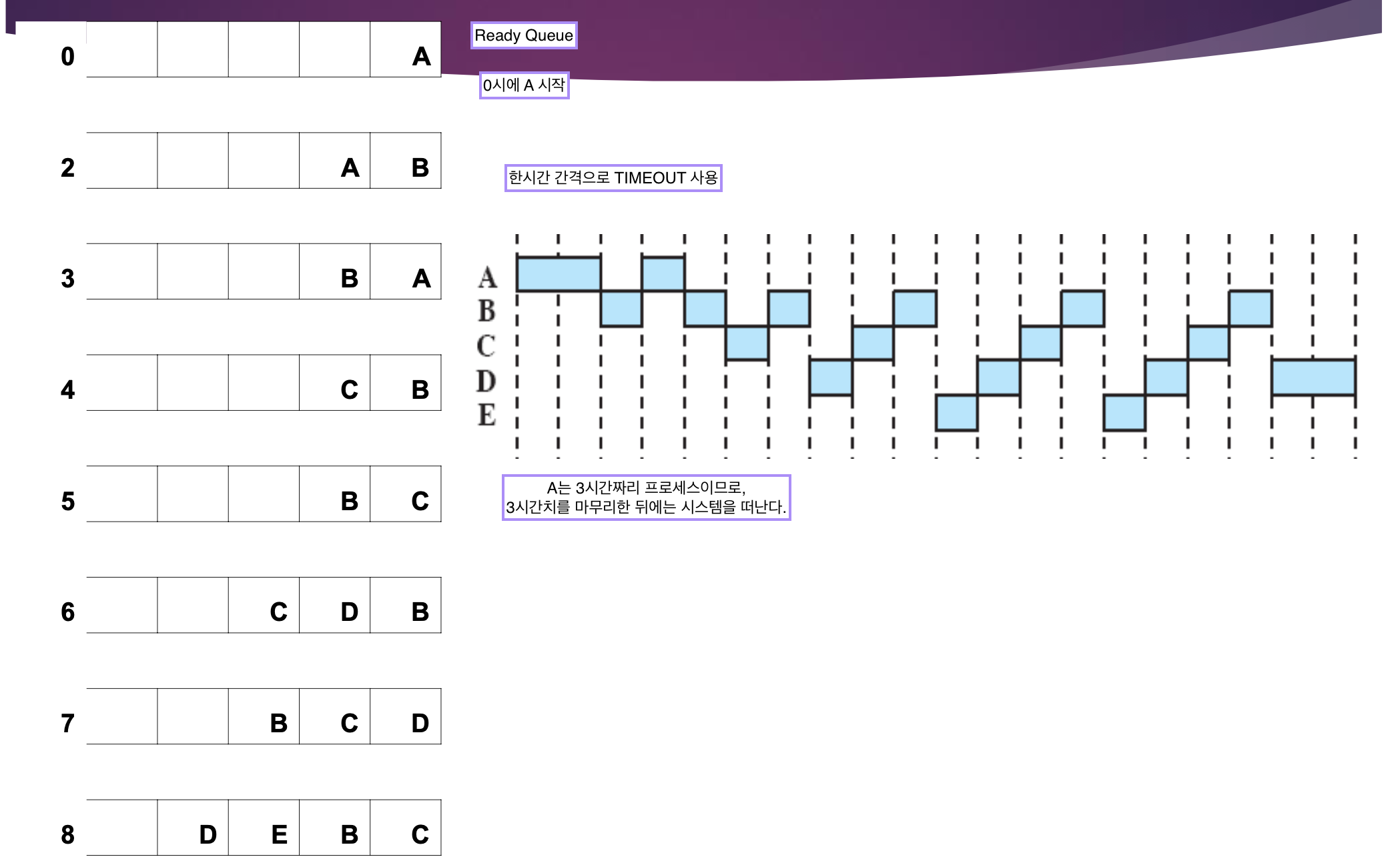
First-Come-First-Served (FCFS)
시스템 큐에 프로세스들이 도착한 순서대로 실행을 시킨다.
우선순위
우선순위 : 큐에 도착한 순서
↳ 프로세스가 Queue 에 먼저 도착할 수록 우선순위가 높아진다.
Non-Preemtion
한 번 실행을 시작하면 끝까지(service time 까지) 실행을 시킨다. 중간에 프로세스를 중단시키지 않는다. (중간에 CPU 를 빼앗지 않는다.)
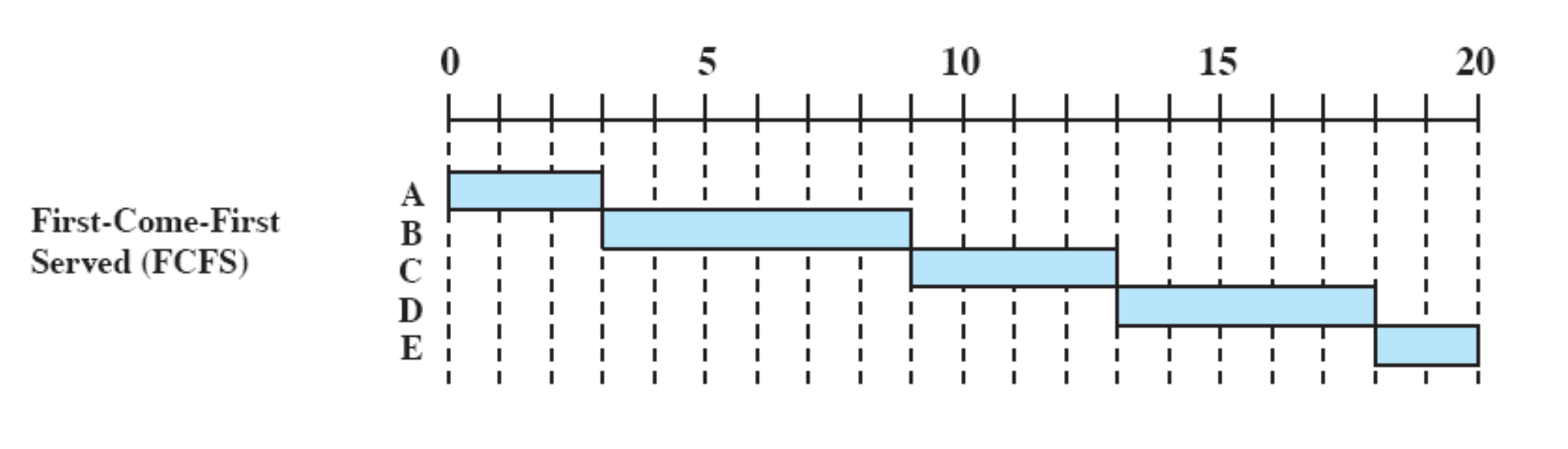
A → B → C → D → E 순차적로 실행
- The oldest process in “ready queue” is selected
- Non-Preemption
- A short process may have to wait a very long time before it can execute
FCFS Response Time
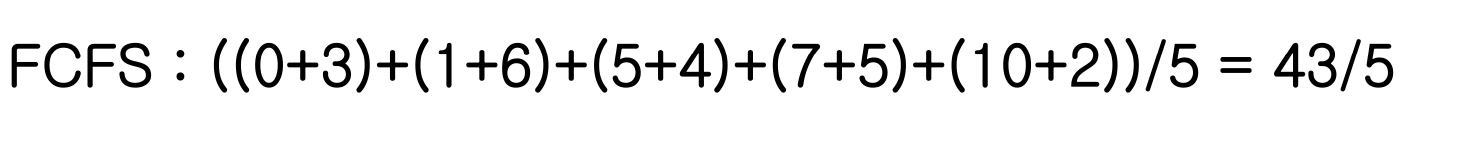
Response Time = Waiting Time + Executing Time 의 평균
- B: 1시간 기다림
- C: 4시 도착, 5시간 기다림
- D: 6시 도착, 7시간 기다림
- E: 8시 도착, 10시간 기다림
B: 2시에 도착했지만 3시에 시작하므로 1시간 기다림FCFS는 성능이 좋지 않다,,
몇시간을 기다린 수는 중요하지 않고, 실행시간 짧은게 뒤로 밀려서 오래 기다리는 상황이 발생할 수 있다. 이때 기다리는 시간이 길다는 생각을 하게 된다.
일찍 끝날줄 알았는데 오래걸리네..?
Round-Robin
Time-out 사용하는 방식이다. 프로세스가 일단 실행을 시작하면 타이머를 세팅하고 타임 아웃이 되면 프로세스를
Ready Queue로 돌려보내고 다음 프로세스를 실행시킨다.
Queue 에 들어 있는 프로세스 입장에서 봤을 때, A → B → C → D → E → A → B → C → D → E 순으로 실행되어서 이름이 Round-Robin 방식이다.
Preemtion
Clock 에 기반한 Preemption 방식을 사용한다. 실행을 하다가 TIMEOUT 되며 CPU 를 뺏긴다.
우선순위
큐에 들어온 순서대로 차근차근 실행된다.
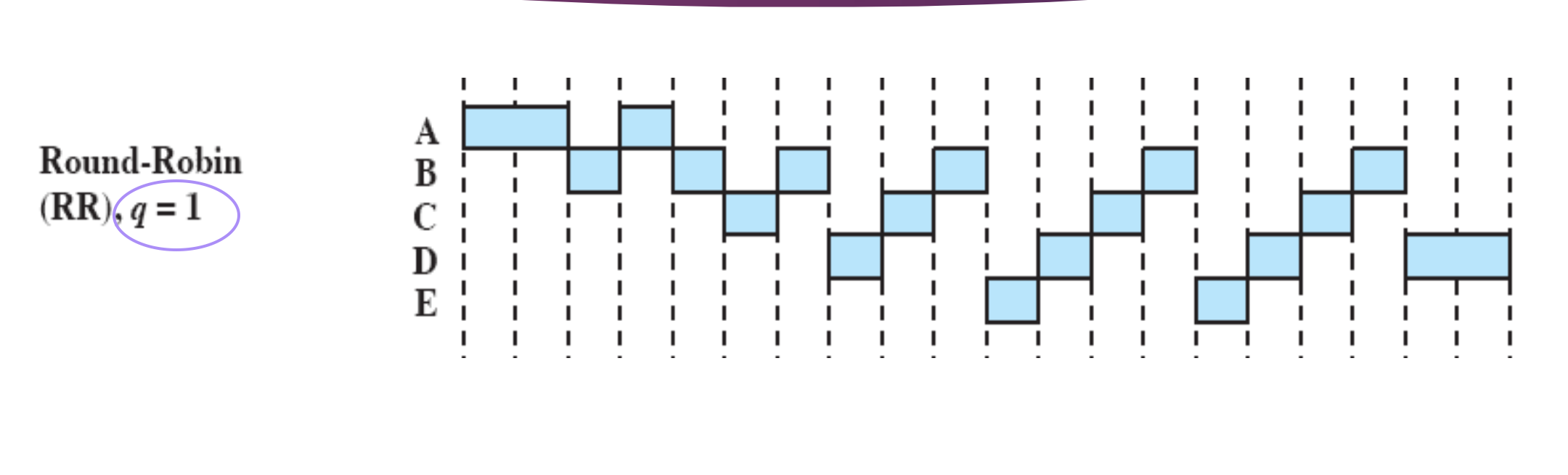
q = Time quanterm 한번 CPU 를 잡으면 얼만큼 작업을 할지를 나타낸다.
Time quanterm 에 따라 Response Time 이 바뀐다. ⇒ 성능이 달라진다.
- q = 1 → 프로세스마다 1시간씩 작업한다.
q 를 2나 3, 4로 잡으면 실행되는 순서와 Response Time 이 바뀐다. - q = 2 → Response Time 이 줄어든다. ⇒ 성능이 달라질 수 있다. ⇒ 적절한 TIMEOUT 시간을 잡아야 한다.
Time Slicing
Time Slicing 기법이라고도 불린다.
- Clock interrupt is generated at periodic intervals
- When an interrupt occurs, the currently running
process is placed in the ready queue - Known as time slicing
- Queue 를 같이 그려야 한다.
- 1시에 TIMEOUT 이 되어도 큐에 A 밖에 없기 때문에 중단되지 않는다.
- 여러개의 프로세스가 동시에 Queue 에 들어오는 일은 없다.
↳ 인터럽트마다 우선순위가 존재한다. OS 가 순서대로 처리할 것이다.
여기서는 외부에서 들어오는 프로세스가 Queue 의 앞쪽에 서 있다.
작업 순서: A → B → C → D → E 순서 X 언제 CPU 를 잡고 언제 Queue 에 들어가는지 등의 순서를 따져봐야 한다.
Round-Robin 의 Response Time
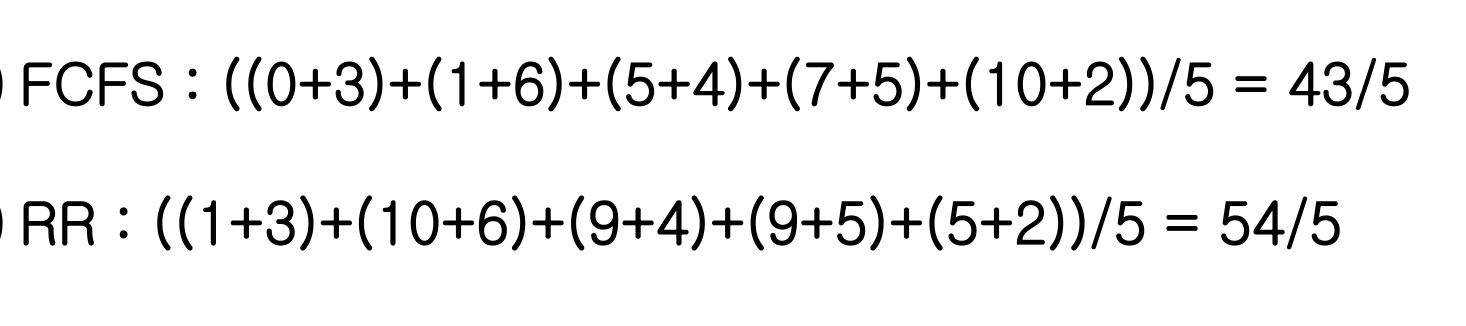
Waiting Time 은 중간중간 비어 있는 공간을 다 따져봐야 한다.
- A: 1시간 기다림
- B: 10시간 기다림
→ FCFS 보다 RR 의 Response Time 이 더 길어졌다.
시스템 입장에서 똑같은 시간만큼 일하면 좋은 것 같지만, User 입장에서는 CPU 가 얼만큼 일하는지는 중요하지 않다. → 입장에 따라 성능이 달라진다.
CPU 입장에서는 한번도 쉬지 않고 일함. CPU 가 얼만큼 일하는지 중요 X, 각각의 프로세스가 실행을 시작해서 언제 끝났는지(Response Time)가 중요하다.
↳ Response Time 은 작업 순서에 따라 달라진다.
FCFS 와 RR
공통점
우선순위
↳ FCFS 와 RR 모두 먼저 도착한 애가 우선순위를 갖는다.
차이점
Preemption Vs. Non-Preemption
Shortest Process Next (SPN)
우선순위
실행시간이 짧은 프로세스가 우선순위가 높아 먼저 실행한다.
Non-Preemption
⇒ 실행시간이 긴 프로세스가 큐에 이 프로세스밖에 없으면 먼저 실행한다. 하지만, 멈추지 않는다.
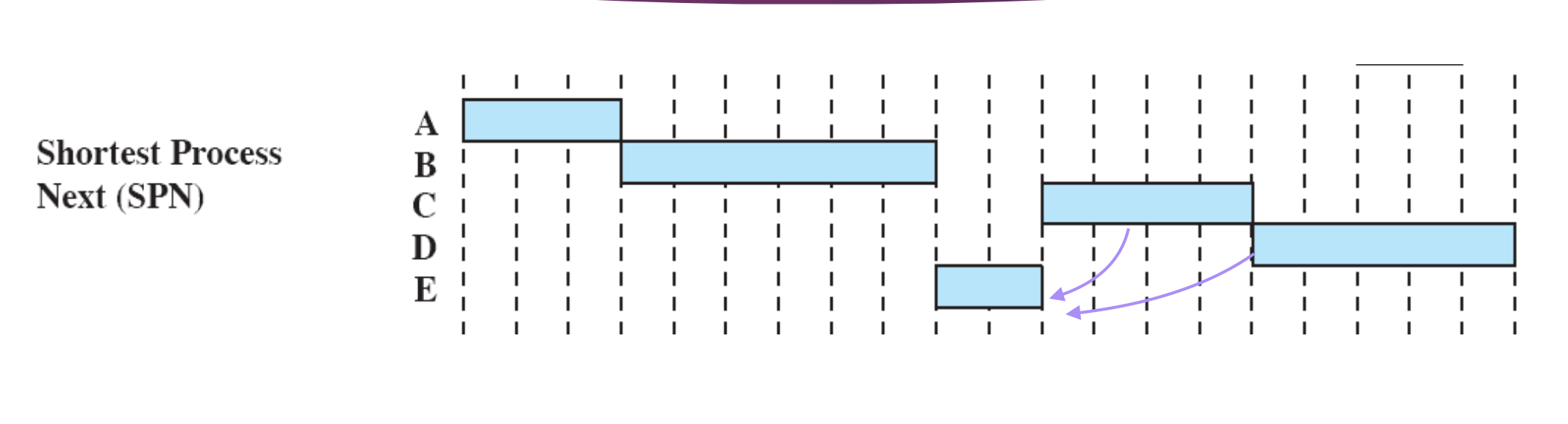
Queue: (A) A → Queue:(B) B → Queue: (CDE) E → C → D
E 때문에 C 와 D 는 우선순위에서 밀려 Waiting Time 이 각각 2시간 해서 총 4시간이 증가하게 되지만, E가 실행시간이 짧고 E의 Waiting Time 이 9시간이 줄어들어서 전체적인 Waiting Time 은 줄어들게 된다.
Process with shortest expected processing time is selected next
문제점 2개 존재
- 실행시간 긴데 뒤로 밀려 실행시간이 짧은게 계속 오면
Starvation이 발생할 수 있다. ⇒ Fairness X , 예측 가능성이 떨어진다.
앞에 두 알고리즘은 굉장히 fair 하고 예측 가능성도 높았다. - 두 번째 문제: 앞으로의 프로세스의 실행시간을 알 수 있는 방법이 없다.
⇒ 실행 안해보고 실행시간을 예측하기 힘들다.
- Predictability of longer processes is reduced
- If estimated time for process not correct, the
operating system may abort it - Possibility of starvation for longer processes
Shortest Process Next 의 Response Time
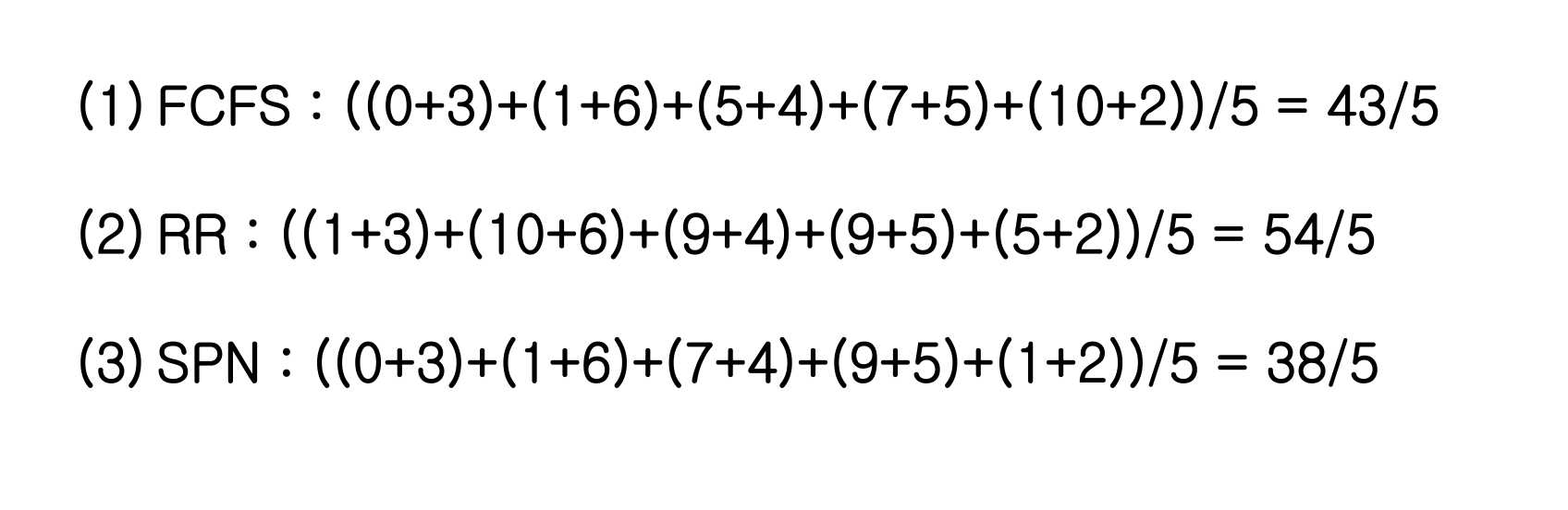
다른 사람의 실행시간이 내 waiting time 이 된다.
SPN 은 Response time 이 매우 줄어든다.
순서를 바꾼게 왜 Response time 을 줄어들게 할까?
→ Waiting Time + 실행시간 에서 실행시간 은 고정 되어 있기 때문에, Waiting Time 을 줄여야 Response time 이 줄어든다.
SNP의 실행시간을 정확히 예측하는 두가지 방법
1. CALCULATING PROGRAM ‘BURST’
대부분의 프로세스들은 실행을 하는데 실행을 시작해서 Ready Queue 에 있다가 CPU 를 잡아서 실행하고 끝인 프로그램은 별로 없고, 대부분의 프로그램들은 입출력이 있기 때문에 Ready Queue 에 있다가 CPU 를 잡아서 실행하고 그다음에 I/O 작업 때문에 Block 이 된다. 다시 Ready Queue 에 있다가 실행하고 또 I/O 작업 때문에 Block 이 된다.
프로세스의 실행 순서: 실행 → block → 실행 → block → ...
Burst Time
실행 시간

프로세스는 반복해서 Ready Queue 에 들어온다.
프로세스가 Ready Queue에 들어왔을 때 다음 실행시간은 어떻게 될지 모르지만, 옛날 Burst time 은 알기 때문에 이를 이용해 다음 걸 예측할 수 있다. → 산술 평균 이용
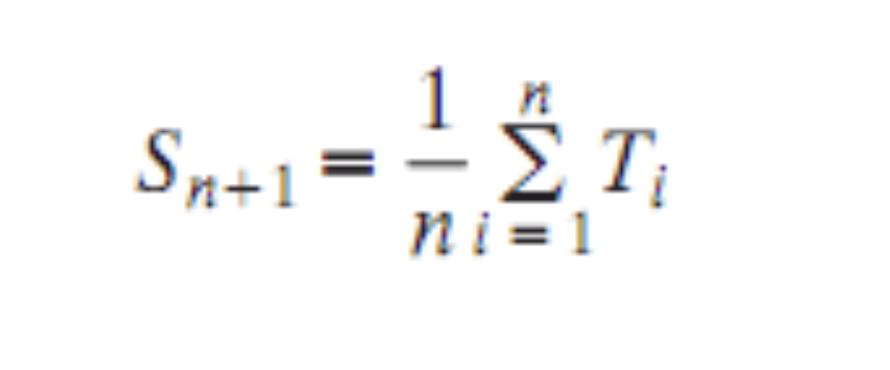
- Ti = processor execution time for the i-th instance of this process
i 번째 Time 의 작업 시간 - Sn+1 = predicted value for the i-th instance
예측값 - S1 = predicted value for first instance; not calculated
첫 번째 기본 값 필요 (초기값) - n = Ready Queue 의 개수
⇒ 전체 Ti 를 더해서 n 으로 나눈것이 다음의 예측 값이다.
( 1 + 2 + 3 ) / 3 = 2 ⇒ 네번째 실행시간은 2일 것2. Exponential Averaging
가중 평균
A common technique for predicting a future value on the basis of a time series of past values is exponential averaging
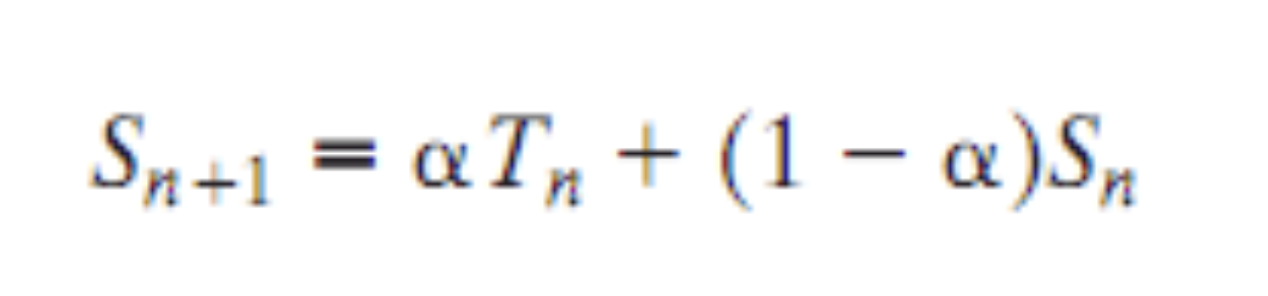
- Tn = Ti 는 i 번째 실제로 작업한 시간
- a = 0~1 사이의 수, 0.5면 Ti 와 Sn 값의 평균이고 아니면 가중치가 붙는 것
- Sn = 매번 예측한 값으로 n+1 번째 실행전 예측한 값
문제에 표가 주어지면 S 값을 구할 줄 알아야 한다.
