Chapter 1
Q. Interrupt가 걸려도 왜 바로 처리를 하지 않을까?
Fetch Stage → Execute Stage → Interrupt Stage
왜 Fetch, Execute 이후에서야 Interrupt가 처리될까?
Interrupt가 처리된 이후에는 PC가 복귀가 되어 PC에 저장된 다음 명령어가 실행되기 때문에 이전 명령어는 처리가 완료되어야 있어야 한다. Instruction cycle Fetch-Execute이 진행되면 PC가 증가되어 버리기 때문에 완료되지 않은 상태에서 인터럽트가 진행되고, PC가 복구되면 이전 명령어는 진행되지 못하게 된다.
Fetch stage가 끝나고 Execute Stage가 끝나기 전에 인터럽트 처리를 하고 다시 원래 실행하던 프로그램으로 돌아오면, PC 값이 하나 증가된 값이 넣어져 있어 이전 코드가 실행되지 못한채 다음 명령어를 실행하게되기 때문이다.
Q. Interrupt Stage에서는 Interrupt가 걸린 이유를 파악하고 이 Interrupt Handling 하기 위한 적절한 프로그램을 실행시킨다.
→ X
Interrupt Stage에서는 프로그램을 실행시킬 수 없다.
명령 하나를 실행시키는 사이클이다. 따라서 인터럽트 핸들러라는 새로운 프로그램을 시작해야하기 때문에 결국 Interrupt Stage에서는 OS를 실행시킨다.
⇒ OS 실행
Q. OS의 실행 순서?
PC 값 OS 명령어로 변경하기
Q. PC, PSW 따로 저장하는 이유?
마지막에 process state 먼저하는 이유? 새로 실행을 시작할 PC 값을 저장하는 순간 인터럽트 핸들러의 작업이 끝나기 때문이다. 새로운 프로그램이 바로 시작되어 버린다. 이전의 중요한 정보들이 모두 저장되지 못한채로 새로운 프로그램이 시작된다. OS가 해야할 것을 먼저 끝내고 다른 프로그램이 시작되어야한다.
따라서 Hardware에서도 5번 이후 6번이 실행되어야 한다. 6번에선 이미 PC 가 OS 주소로 바뀌기 때문이다.
Q. I/O Interrupt는 입출력을 하기 위해서 OS를 호출하는 것이다
→ X
4번코드의 입출력하기 위함이 아니다.
Q. I/O Interrupt는 내 프로그램의 입출력 때문에 발생한다.
→X
다른 프로그램의 I/O 때문에 발생한다.
Q. I/O Interrupt는 I/O 작업이 시작할 때 발생한다.
→X
끝날 때 발생한다.
Q. 왜 이런 복잡한 이동순서를 가지고 있을까?
이동순서
Disk → Main Memory → Cache → Register 순으로 이동하게 된다.
→ Main Memory부터 휘발성이기 때문에 전원을 끄는 순간 저장되어 있던 데이터가 모두 사라지게 된다.
→ 저장용량이 문제가 된다. HDD는 용량이 크기 때문에 모든 파일을 저장할 수 있지만 Memory에는 모든 것을 저장할 수 없다.
메모리는 나누어져 있다.
실행되는 프로그램도 나누어져 있다.
Q. why is cache memory invisible to the operating system?
(OS에서 Cache를 관리하지 않고 Hardware에서 관리하는 이유?) 컴퓨터의 성능향상을 위해서이다. 속도 향상 → 더 빠르고 빈번하게 명령어와 데이터에 접근할 수 있다. OS로 인한 overhead나 delay를 없애기 위함이다.
캐시는 빠른 액세스가 가능한 하드웨어에서 데이터를 가져오면서 속도 향상을 노리며, 동시에 동일 데이터에 대한 접근 시 미리 구성된 데이터를 응답하여 불필요한 검색 작업을 방지할 수 있다.
Chapter 2
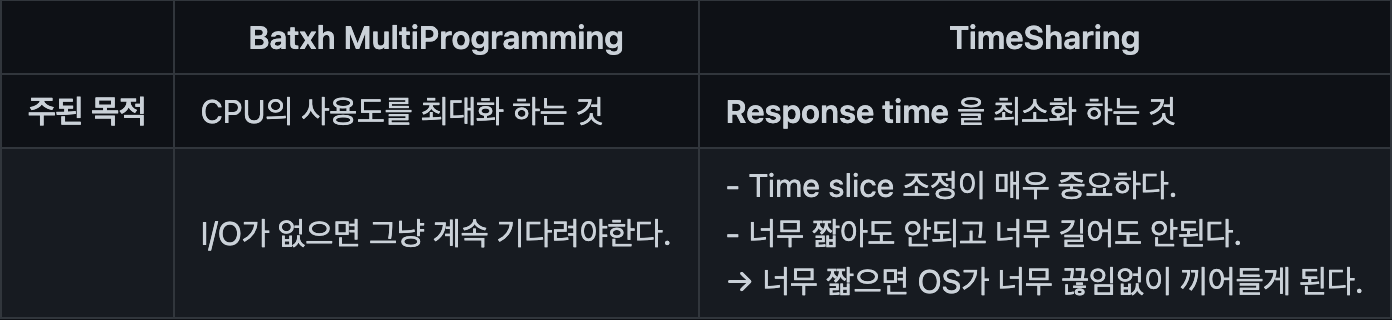
Q. Multi Programming 시스템은 TimeSharing 시스템이다.
→ 맞을 수도 있고 아닐 수도 있다.
Q. TimeSharing 시스템은 Multi Programming 시스템이다.
→ O 단, TimeSharing 시스템과 Multi Programming 시스템은 프로그램이 바뀌는 시점이 다르다.
TimeSharing 시스템 = 시간에 의해서 프로그램이 바뀐다.
Multi Programming 시스템 = I/O 입출력에 의해서 프로그램이 바뀐다.
Chapter 3
Q. 메모리에 있는 프로세스와 실행파일이 같냐?
→ X
메모리에 있는 프로세스 != 실행파일
실행파일 코드와 데이터만 존재한다. 즉, 전역변수와 스태틱변수를 저장하는 데이터 영역은 원래 컴파일 할 때부터 실행파일 안에 존재한다.
프로세스 실행파일이 메모리로 올라오며 원래 있던 값들에 stack영역과 PCB영역이 추가된다.

Q. Process "Image" 라는 용어를 사용하는 이유?
밑에 모든 것을 포함한 것을 Process Image라고 부른다.
하나의 Process는 Memory에 다 들어갈 수 없기 때문에, Process의 일부만 들어가게 되는데, OS가 전체 Process가 Memory에 들어가 관리를 하는 것처럼 상상하여 사용하기 때문에 Process "Image" 라는 용어를 사용한다.
Q. 미리 만들어 놓지 않고, 그때 그때 호출할 때 만드는 이유?
→ 내가 모든 함수를 다 동시에 사용하지 않는데, 모든 함수에서 사용할 변수의 공간을 미리 만들어 둔다면, 프로그램의 크기가 너무 커질 것이다.
실제로 함수는 한 번에 하나씩 호출이 된다. → 그래서 호출 됐을 때 필요한 딱 최소한의 공간만 만들어야 한다. 그러기 위해서 Stack 을 사용한다.
당연히 Stack 에는 함수 호출이 끝나고 Return 할 주소가 함께 들어있다.
Q. Tree 형태로 Process를 관리하는 이유?
→ A Process는 B Process를 만들고 끝나는게 아니라, B Process가 제대로 종료되었는지 확인하고 OS에게 보고할 의무가 있다.
⇒ 즉, Parent Process ID 가 PCB안에 저장되어 있어야 한다.
Q.Control Stack에 있는 정보를 Copy해서 PCB 안에 저장을 해두는 건가요?
→ CPU 안에 Register가 100개쯤 있다고 가정했을 때, Register 값을 다 저장하면 100개의 정수값을 다 저장해야 한다. 그거를 Control Stack에 다 저장하고, Copy해서 여기에도 저장하고 이렇게 Copy를 반복할 이유가 없다.
⇒ 즉, Control Stack에 PCB Pointer를 저장하는 것이다. PCB에는 Save & Restore 할 정보값이 들어 있다.
정보는 Control Stack 한군데에 Pointer로 저장되어 있다.
Control Stack은 MainMemory(RAM) 에 위치한다.
Q. User Mode와 Kernel Mode에 대하여 설명하시오.
User Mode
현재 CPU가 User Program 명령을 1줄을 실행하는 모드.
권한에 제한이 많다.
Kernel Mode
= System Mode
= Control Mode
= Supervisor Mode
현재 CPU가 OS 프로그램 명령을 1줄 실행하는 모드.
권한에 제한이 적다.
⇒ User Process 가 Kernel mode 에서 Kernel Stack 을 쌓아가면서,Kernel Code 를 Kernel running 상태에서 실행중이다.
Q. 프로세스 안에서 실행한다?
⇒ 프로세스의 실행이 무엇이냐? 프로세스가 실행할 때, 프로그램의 코드와 데이터(전역 변수, static 변수의 개수, 공간의 변화)는 변화가 없다.
⇒ 즉, 공간이 계속 변하는 것은 Stack 밖에 없다.
⇒ 즉, 실행은 Stack이 쌓였다가 내려갔다가 값이 바뀌는 것을 말한다.
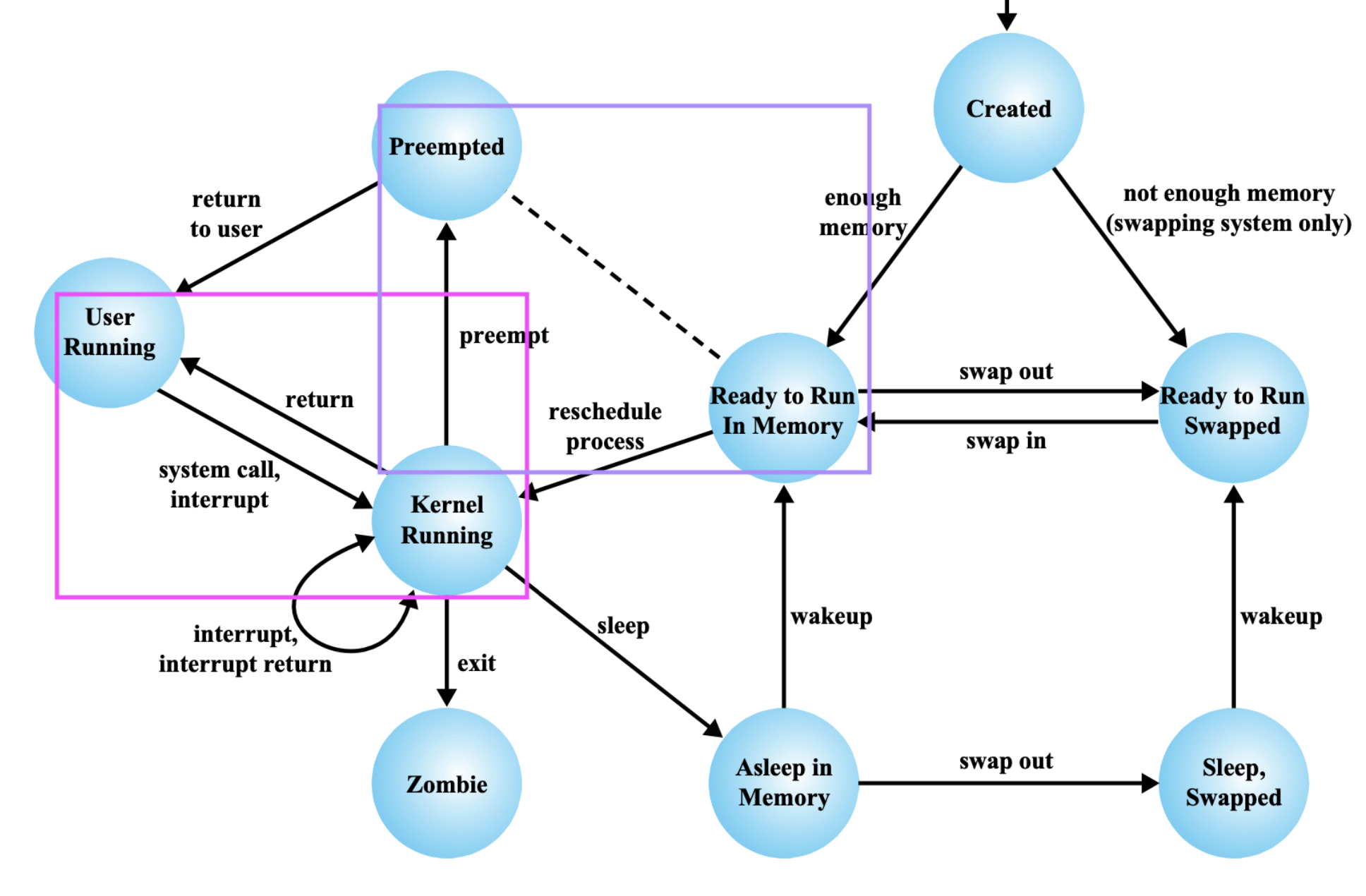
Q. Preemted → User Running 이런 화살표가 존재하는 이유? (unix)
원래는 이런 화살표가 존재할 수가 없다. User 프로그램이 실행이 되려면, 당연히 OS가 뭔가 작업을 해주어야 User Program이 실행이 된다. OS의 작업 없이 User Program이 갑자기 실행을 시작할 수는 없다.
모든 프로그램은 실행을 시작하려면 Kernel Running 상태를 거쳐야 한다. Preemted에서 User Running 로 갈때도 당연히 Kernel Running 상태를 거쳐야 한다.
근데 이 모델은 시스템 전체가 아닌, 하나의 프로세스에 대한 모델로, 하나의 프로세스가 어떻게 변화하는지 나타낸 그림이다.
Preemted에 존재하는 프로세스는 이미 Ready to Run In Memory에서 Kernel Running을 거쳐 User Running 상태에서 실행이 되다가 Time Interrupt를 거쳐 Preemted 상태로 오게 된 애들이다. 따라서 다시 실행될 때 문제가 없다면, Kernel을 거치지 않아도 바로 실행될 수 있는 것이다.
Chapter 4
Q. 하나의 Program이 하나의 Process인가?
→ X
하나의 Program은 n개의 Process를 가질 수 있다.
Q. 하나의 Process는 하나의 Program에 속하는가?
→ X
하나의 Process는 A, B, C, ... Program을 바꿔가면서 실행시킬 수 있다.
⇒ Process : Program = n : n
Q. 여러개의 child Process로도 동시 작업할 수 있는데 왜 Multi Thread 로 동시작업을 할까?
Process 생성 시간 > Thread 생성 시간
이유?
프로세스 생성 → 모든 것을 copy 해야한다. 프로세스는 별개의 독립된 구조체이다.
즉, 프로세스는 복사하게 되면 많은 양의 정보들을 복사해야하기 때문에 생성시간이 길어진다.
⇒ 생성시간도 길어지게 되고, 없앨 때도 메모리, 자원, 스위칭 시간 등등을 할당된 자원을 다시 반납해야 하기 때문에 소요시간이 길어지게 된다.
↔ 하지만, Thread는 프로그램 코드와 데이터를 Share 를 할 수 있기 때문에 모든 것을 copy할 필요가 없다.
⇒ 생성시간이 줄어들게 되고, 없앨 때도 소요시간이 줄어든다.
Q. 왜 Multi Thread는 7개의 State Model로 나타낼 수 없을까?
→ X
MultiThread는 3장의 상태도(5개의 모델)과 같지만, 7개의 모델 상태도로는 그릴 수 없다.
7개의 상태에서는 Swapping 에 의한 Suspend 상태가 존재한다.
이 Suspend 가 일어나는 여러 이유 중 가장 큰 이유가 Swapping 이다.
하지만 Thread 는 Swapping 이 불가능 하다.
→ Thread Suspend 가 일어나 Thread Swapping out 이 일어나는 것은 불가능 하다.
스레드가 실행하고 있었는데, 얘(스레드의 stack)만 딱 띄어서 스와핑 area로 보내는 것은 의미가 없다.
⇒ Process 를 Swapping out 해야 한다.
→ Process 가 스와핑의 단위 이다. → Suspension은 Process 단위로 이루어진다.
Q. 스레딩 관리를 한다?
→ 유저 레벨의 스레드 라이브러리에서 스레드를 관리한다.
스레드 관리 = 스레드를 만들고 종료하고 스케쥴링하고 스위칭하는 것.
Q. 왜 이렇게 커널레벨과 유저레벨 스레드 두 가지를 다 사용하는가?
간단히 말하면, 커널레벨의 스레드의 장점과 유저 레벨 스레드의 장점을 둘 다 얻고 싶은 것이다.
커널레벨의 스레드의 장점 (여러개의 CPU를 갖고 있는 시스템에서 한 프로그램 안에 있는 여러 스레드를 진짜로 동시에 실행시킬 수 있다.)
유저 레벨 스레드의 장점 (스위칭을 할 때, 소요시간이 적게 걸린다.)
Combined Approached for Thread 을 사용하는 찐 이유?
멀티스레딩 → 스레드가 항상 동시에 실행되진 않음 User가 불필요하게 너무 많은 스레드를 만들 수 있는데, 이를 OS가 관리할 수 있다.
⇒ 불필요하게 많은 스레드를 만드는 것을 막기 위하여 이렇게 두 단계로 진행하는 것이다.
Q.thread가 실행 단위이므로 thread가 우선순위를 가져야 하는데, Process는 실행도 안하는게 왜 우선 순위를 갖는가?
→ Base Priority 는 해당 프로세스에 속한 스레드들의 우선순위 minimun 값이다.
Q. 왜 이 기능이 스레드 단위가 아니라 프로세스 단위로 존재할까?
Default Processor affinity
교수님이 제일 재밌다고 한 기능
내가 좋아하는 CPU라는 뜻이다.
→ 시스템 안에 CPU가 하나만 있는 경우는 의미가 없고,
CPU가 여러개 있는 프로세스가 있다고 할 때, 이 프로세스가 좋아하는 CPU는 1번, 3번, 5번 이라고 할 때,
이 프로세스에 속한 스레드들은 1번, 3, 5번에서 가능하다면 실행을 시키라는 의미이다.
→ 이 경우는 프로세스 단위로 관리되는 것이 맞다. 스레드 단위로 관리되는 정보가 아니다.
왜냐하면, Default Processor affinity 이 정보와 연관된 것은 Cache이다.
프로그램 → 스레드가 여러개 → 스레드 한 개를 CPU1에서 실행
↳ 이 프로그램의 code, data가 CPU1의 cache에 존재한다는 의미
→ 이 프로세스의 다른 스레드를 CPU3에서 실행
↳ 다시 이 프로그램의 code, data를 CPU3의 cache로 Copy 해야한다.⇒ 위의 상황의 경우, 계속 code, data(공유 데이터) Copy 해야하는 상황이 반복된다.
↔ 그게 아니라, 내가 이 프로세스의 다른 스레드를 CPU1에서 실행시키면, CPU1에 내 code, data가 이미 존재할 것이다. ⇒ 그럼 다시 caching 할 필요가 없다.
이 프로세스가 실행은 스레드 단위로 하지만,
실행한다는 말은 코드와 데이터를 읽는다는 뜻이므로 몇 번 CPU Cache 안에 내 code와 data가 있느냐에 따라서 가급적이면 그 CPU에서 다시 copy하지 않고 내 스레드가 실행 됐으면 좋겠다 라고 하는 것이 Default Processor affinity 정보들이다.
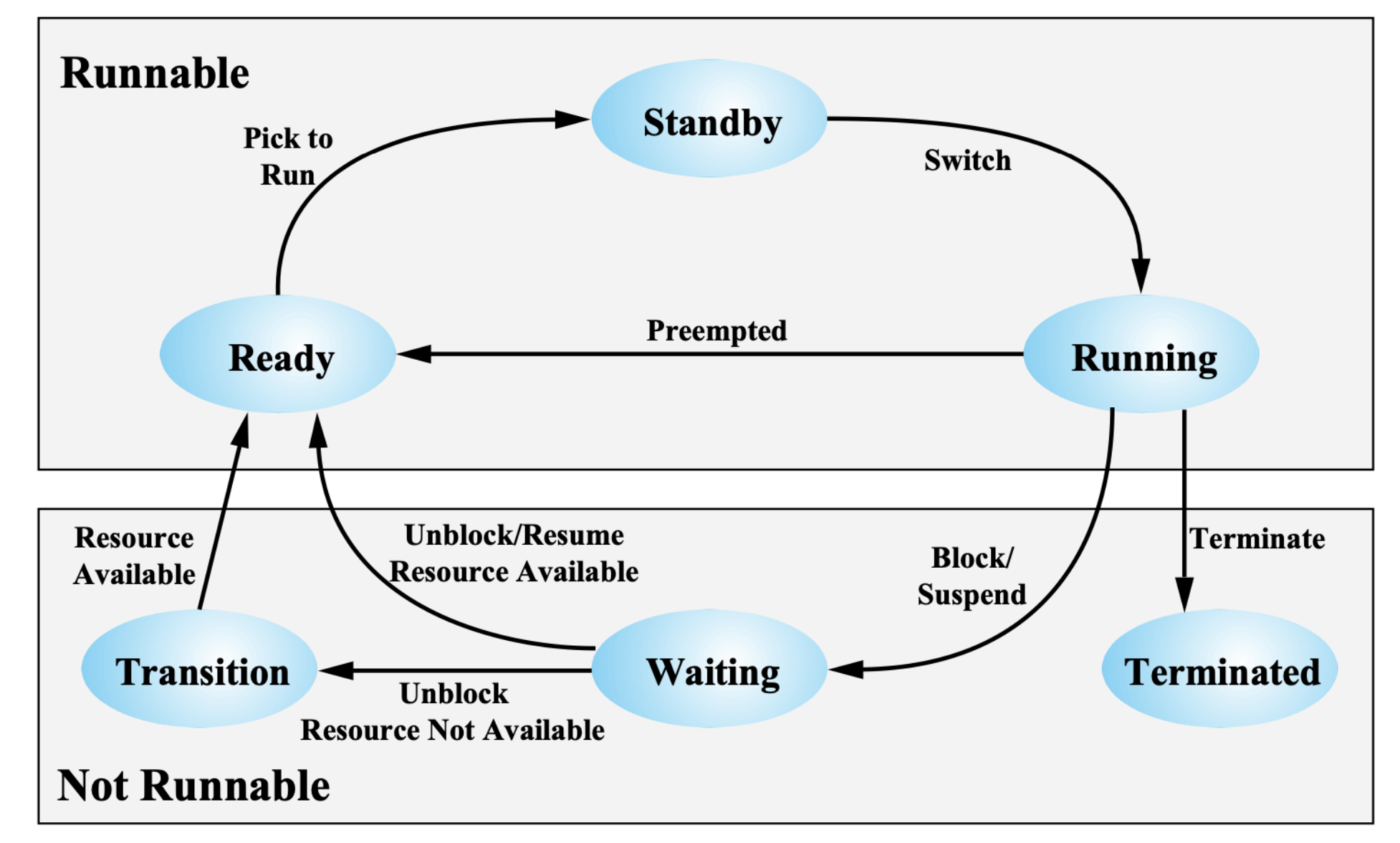
Q. Waiting → Ready Vs. Waiting → Trasition 차이? (Windows)
Resource ? 스레드가 suspend나 blcok으로 waiting에 있는데, 이 스레드를 포함하는 프로세스가 스레드를 3개 가지고 있었는데, 이 프로세스가 가진 스레드들이 모두 Block이나 Suspend되어 Waiting 상태에 가있게 되면 더 이상 실행할 스레드가 없게 된다. 이럴 때, MidTerm Scheduler 가 이 프로세스는 실행할 스레드가 하나도 없으니까 Swapping Area 로 옮겨야 되겠다 결정을 하게 된다.
⇒ 스레드들은 Block이나 Suspend된 채로 프로세스에 담겨 Swapping Area로 이동하게 된다.
⇒ Process 상태가 Swap out 되어서, 프로세스가 Suspend 상태 가 되게 된다.
이 상황에서 Waiting 상태에 있던 프로세스에 I/O 작업이나 동기화 작업이 끝 났는데 프로세스가 Swapping Area에 있어서 코드가 존재하지 않게 된다. 이 스레드는 메모리에 올라와 있지 않은 상태이다.
이럴 때 Resource Not Available 하다고 한다.
그렇지 않고, 해당하는 스레드를 포함하는 프로세스가 계속 메모리에 잘 있으면,
즉, 스레드가 한 두개 suspend나 block이 되어 있지만 나머지 스레드들이 계속 실행을 하고 있는 경우 ,
또는 OS가 메모리가 넉넉하다고 판단해 굳이 Swap out 하지 않은 경우 Resource Available 상태라고 한다.
즉, Resource Available 과 Resource Not Available 상태의 차이는,
해당하는 스레드를 포함하는 프로세스가 메모리에 있는지 아니면 Swapping Area(하드디스크)에 존재하는지?
→ 좀 더 정확히, 프로그램 데이터와 코드가 리소스이므로 이 프로그램 데이터와 코드를 사용할 수 있는지? (메모리에 있으면 사용 가능, 하드디스크에 있으면 사용 불가능)
Chapter 5
Q. Mutual-Exclusion 증명하는 방법?
Q. 안쪽 돌다가 → 바깥쪽 도는 경우 생기는지?
상대편이 어떻게 하면 이런 상황이 발생하는지?
Q. 바깥쪽 돌다가 → 안쪽 도는 경우 생기는지?
상대편이 어떻게 하면 이런 상황이 발생하는지?
Q. 언제 무한대로 진입이 안되는 상황이 생기는가?
공통적으로 내가 Critical Section을 진행하고 나면, 상대편이 진입할 수 있게 양보를 해준다.
이 알고리즘은 Critical Section에 p1이 들어갔다가 나와서 다시 또 Critical Section에 진입할 수 있다. 여러번,,! 어떤 상황에서 계속 진입을 할 수 있는지? 그러나 무한대로 진입은 안됨 언제 무한대로 진입이 안되는 상황이 생기는가?
Q. 위의 접근 방법을 다 알아야하는 이유?
하드웨어 instruction, Semaphore, ... 내가 사용하는 프로그램 OS 가 모든 방법을 제공하지 않을 수 있기 때문이다.
⇒ 즉, 시스템 상황이 어떻게 될 지 알 수 없기 때문이다.
Q. 코드 순서를 변경할 때, 문제가 발생할 수 있다.
Q. Count 변수를 사용할 수 있는 이유?
↳ monitor안의 local 변수 count를 사용했기 때문이다.
이 monitor 자체가 Critical Section이기 때문이다.
Count는 monitor 안에 있기 때문에 연산이 가능한 것이고, Count를 사용해서 코드가 간단해졌다.
Semaphore에서는 count와 같은 변수를 사용할 수 없다.
Q. Monitor에서 Deadlock이 발생하지 않을까?
Semaphore로 Buffer 문제 해결했을 때는 코드 위치를 변경했을 때 Deadlock이 발생했다.
- semWait(e) ↔ semWait(s) : Critical Section에 먼저 들어간 뒤, 버퍼가 찼는지 확인
- semWait(n) ↔ semWait(s) : Critical Section에 먼저 들어간 뒤, 버퍼가 비었는지 확인
↔ monitor의 경우, Critical Section에 원래 먼저 들어간 뒤, 버퍼가 비었는지 꽉 찼는지를 확인한다. ⇒ Deadlock이 발생하지 않는다.
⇒ 왜 순서를 바꿨을 때, Semaphore는 Deadlock이 발생하고 왜 Monitor에서는 Deadlock이 발생하지 않을까?
