
[Java] 자바 기초(7)
1. CQRS
1-1. CQRS란
CQRS는 Command and Query Responsibility Segregation(명령과 조회의 책임 분리)를 나타낸다.
CQRS는 시스템에서 명령을 처리하는 책임과 조회를 처리하는 책임을 분리하는 것이 핵심이다.
- 명령은 시스템의 상태를 변경하는 작업을 의미
- 조회는 시스템의 상태를 반환하는 작업을 의미
정리하면, CQRS는 시스템의 상태를 변경하는 작업과 시스템의 상태를 반환하는 작업의 책임을 분리하는 것이다.
일반적인 애플리케이션은 쿼리와 업데이트에 동일한 데이터 모델을 사용한다.
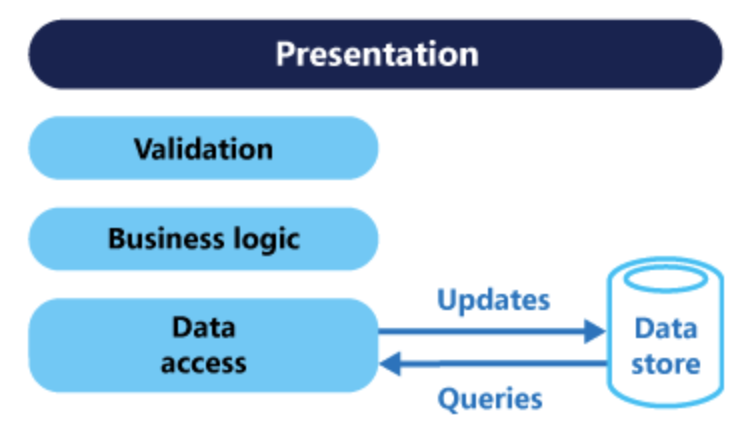
간단한 애플리케이션에는 이것이 적합하지만 애플리케이션이 복잡해질수록 위 방법은 어려워진다. 왜냐하면 애플리케이션은 읽기 쪽에서 다른 쿼리를 실행할 수 있고, 그러면 모양이 다른 DTO를 반환하기 때문에 개체 매핑이 복잡해지기 때문이다. 또한 동일한 데이터 집합에서 작업을 병렬로 수행할 때 데이터 경합이 발생할 수 있으며, 데이터 저장소 및 데이터 액세스 계층에 대한 로드 및 정보를 검색하는데 필요한 쿼리의 복잡성으로 성능에 부정적인 영향을 미칠 수 있다. 그리고 각 엔터티는 읽기 및 쓰기 작업의 대상이 되므로 잘못된 컨텍스트에서 데이터를 노출할 수 있으므로 보안 및 사용 권한 관리가 복잡해질 수 있다.
반면 CQRS는 명령 및 쿼리의 책임을 분리하는 패턴으로, CQRS를 구현하면 성능, 확장성 보안을 극대화할 수 있다.
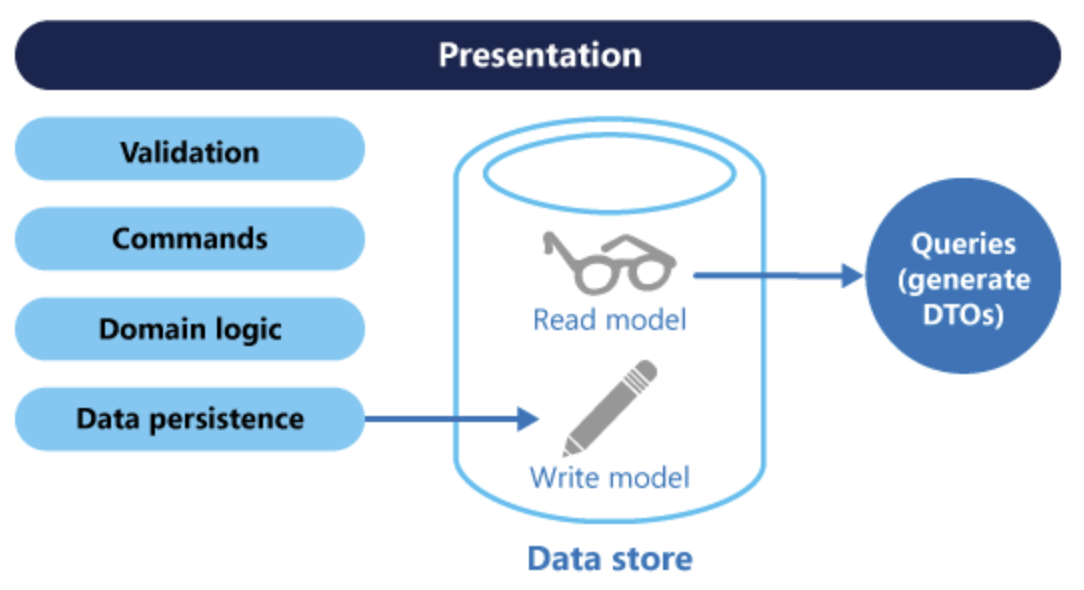
이 패턴에서 명령은 데이터 중심이 아닌 작업을 기반으로 해야하며, 비동기 처리를 위해 큐에 배치될 수도 있다. 또한 쿼리는 데이터베이스를 수정하지 않으며, 쿼리는 도메인 정보를 캡슐화지 않는 DTO를 반환한다.
읽기 저장소는 쓰기 저장소의 읽기 전용 복제본이거나 읽기 및 쓰기 저장소가 전혀 다른 구조일 수도 있다. 여러 일긱 전용 복제본을 사용하며 쿼리의 성능이 당연히 향상될 수 있으며, 부하를 감안하여 각 저장소를 적절하게 확장할 수도 있다.
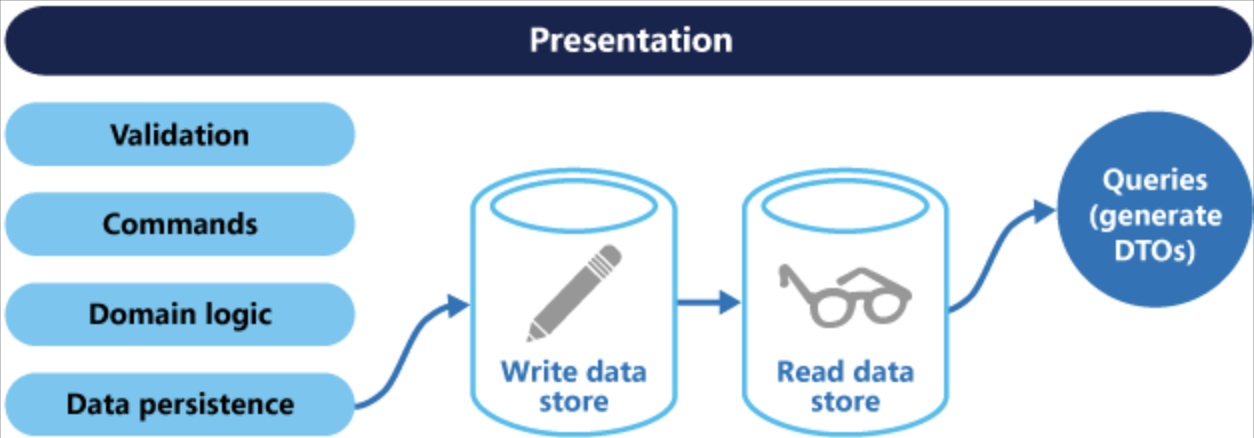
메모리 내 모델은 동일한 데이터베이스를 공유할 수 있으며, 이 경우 데이터베이스는 두 모델 간의 통신 역할을 한다. 위와 같이 여러 형태로 변형을 하여 CQRS를 적용할 수 있다. 별도의 데이터베이스를 허용하며 쿼리측 데이터베이스를 실시간 리포팅 데이터베이스(Reporting Database)로 만들 수도 있다. 이 경우 두 모델 또는 데이터베이스 간에 통신 매커니즘이 추가되어야 한다.
1-2. CQRS의 사용
CQRS를 사용해야 하는 경우는 아래와 같다.
- 많은 사용자가 동일한 데이터에 병렬로 액세스하는 공동작업 도메인일 경우
- 개발자 중 한 팀은 쓰기 모델에 포함되는 복잡한 도메인 모델에 집중하고 다른 한 팀은 읽기 모델과 사용자 인터페이스에 집중할 수 있는 경우
- 시스템이 시간이 지나면서 진화할 것으로 예상되어 여러 버전의 모델을 포함할 수 있거나 비즈니스 규칙이 저기적으로 변하는 경우
- 가장 가치있는 시스템의 제한된 구역에 CQRS 적용을 고려해야 한다.
-> 도메인 또는 비즈니스 규칙이 간단하거나 간단한 CRUD 스타일의 사용자 인터페이스와 데이터 액세스 작업만으로 충분하다면 CQRS는 어울리지 않는다. 모든 상황에서 최상단에 패턴으로 CQRS를 위치하는 건 어디에서도 추천하지 않는 방법이다.
-> DDD 용어에서 말하는 시스템 전체가 아닌 시스템의 특정 부분(Bounded Context)에서만 사용해야한다. - CQRS는 이벤트 기간 프로그래밍 모델에 적합하다.
-> CQRS 시스템이 이벤트 콜라보레이션(Event Collaboration)과 통신하는 별도의 서비스로 분리되는 것이 일반적이며, 이를 통해 이벤트 소싱(Event Sourcing)을 쉽게 이용할 수 있다.
이벤트 소싱(Event Sourcing)
: 이벤트 전체를 하나의 데이터로 저장하는 방식
2. 디미터 법칙
2-1. 디미터 법칙이란
디미터 법칙은 협력하는 객체의 내부 구조에 대한 결합으로 인해 발생하는 설계 문제를 해결하기 위해 제안된 법칙이다.
디미터 법칙은 객체 간 관계를 설정할 때 객체 간의 결합도를 효과적으로 낮출 수 있는 유용한 지침 중 하나로 꼽히며 객체 지향 생활 체조 원칙 중 "한 줄에 점을 하나만 찍는다."로 요약되기도 한다.
디미터 법칙의 핵심은 객체 구조의 경로를 따라 멀리 떨어져 있는 낯선 객체에 메시지를 보내는 설계를 피하라는 것이다.
다시 말해, 객체는 내부적으로 보유하고 있거나 메시지를 통해 확보한 정보만 가지고 의사 결정을 내려야 하고 다른 객체를 탐색해 뭔가를 일어나게 해서는 안된다.
이 때문에 디미터 법칙은 Don't Tallk to Strangers(낯선 이에게 말하지 마라)라고 불리기도 하고, 한 객체가 알아야 하는 다른 객체를 최소한으로 유지하라는 의미로 Principle of least knowledge(최소 지식 원칙)라고도 불린다.
2-2. 디미터 법칙의 적용
모든 클래스 C와 C에 구현된 모든 메소드 M에 대해서, M이 메시지를 전송할 수 있는 모든 객체는
M의 인자로 전달된 클래스(C자체를 포함)
->M에 의해 생성된 객체, 호출하는 메소드에 의해 생성된 객체 모두C의 인스턴스 변수의 클래스
쉽게 말하자면,
this객체- 메소드의 매개변수
this의 속성this의 속성인 컬렉션의 요소- 메소드 내에서 생성된 지역 객체
이다.
3. 일급 컬렉션
3-1. 일급 컬렉션이란
일급 컬렉션이란, 컬렉션(Collection)을 래핑(Wrapping)하면서, 그 외 다른 멤버 변수가 없는 상태이다.
래핑을 함으로써 다음과 같은 이점을 가지게 된다.
- 비지니스에 종속적인 자료구조
- 컬렉션의 불변성을 보장
- 상태와 행위를 한 곳에서 관리
- 이름이 있는 컬렉션
3-2. 비지니스에 종속적인 자료구조
public class LottoService {
private static final int LOTTO_NUMBERS_SIZE = 6;
public void createLottoNumber() {
List<Long> lottoNumbers = createNonDuplicationNumbers();
validateSize(lottoNumbers);
validateDuplicate(lottoNumbers);
}
}위 코드를 통해 로또 서비스에서 로또번호를 생성할 때마다 필요한 모든 장소에서 검증로직이 들어가야한다. 따라서 불필요한 코드가 중복적으로 실행된다.
이를 해결하기 위해 해당 조건으로만 생성할 수 있는 자료구조를 만들게 되면 해결할 수 있다.
public class LottoTicket {
private static final int LOTTO_NUMBERS_SIZE = 6;
private final List<Long> lottoNumbers;
public LottoTicket(List<Long> lottoNumbers) {
validateSize(lottoNumbers);
validateDuplicate(lottoNumbers);
this.lottoNumbers = lottoNumbers;
}
}
public class LottoService {
public void createLottoNumbers() {
LottoTicket lottoTicket = new LottoTicket(createNonDuplicateNumbers());
}
}위처럼 일급 컬렉션을 사용해 비즈니스에 종속적인 자료 구조를 만들어주면 좀 더 깔끔한 코드를 만들 수 있게 된다.
3-3. 불변
일급 컬렉션은 컬렉션의 불변을 보장한다.
이때 final을 사용하면 안되나 의문점이 생긴다.
final은 불변을 만들어주는 것이 아니라, 재할당만 금지한다.
즉, final은 new를 통한 재할당은 막아주지만 set을 통한 내부값 변경은 막지 못한다.
따라서 일급 컬렉션을 사용해 이를 막아준다.(set을 포함하지 않는 일급 컬렉션)
3-4. 상태와 행위를 한 곳에서 관리
일급 컬렉션의 세 번째 장점은 값과 로직이 함께 존재한다는 것이다.
-> 이 부분은 Enum 클래스의 장점과 동일하다.
List<Pay> pays = Arrays.asList(
new Pay(NAVER_PAY, 10000),
new Pay(NAVER_PAY, 15000);
new Pay(KAKAO_PAY, 20000);
new Pay(TOSS, 30000L);
}
Long naverPaySum = pays.stream()
.filter(pay -> pay.getPayType().equals(NAVER_PAY))
.mapToLong(Pay::getAmount)
.sum();이 코드의 경우 List에 데이터를 담고, Service 혹은 Util 클래스에서 필요한 로직을 수행한다.
이때 컬렉션과 계산 로직은 서로 관계가 있지만 위 코드에서는 표현이 안되어있다.
Pay타입의 상태에 따라 지정된 메소드에서만 계산되길 원하는데, 현재 상태로는 강제할 수 있는 수단이 없다.
또한, 위 코드는 똑같은 기능을 하는 메소드를 중복 생성할 수 있을 뿐만 아니라 계산 메소드를 누락할 수 있다.
결국 이를 해결하기 위해 계산식을 컬렉션과 함께 두 번 나누어야 한다.
public class PayGroups {
private List<Pay> pays;
public PayGroups(List<Pay> pays) {
this.pays = pays;
}
public Long getNaverPaySum() {
return getFilteredPays(pay -> PayType.isNaverPay(pay.getPayType()));
}
public Long getKakaoPaySum() {
return getFilteredPays(pay -> PayType.isKakaoPay(pay.getPayType()));
}
}이렇게 PayGroups라는 일급 컬렉션이 생김으로써 상태와 로직이 한 곳에서 관리된다.
3-5. 이름이 있는 컬렉션
마지막으로 일급 컬렉션에는 컬렉션에 이름을 붙일 수 있다는 장점이 있다.
같은 Pay들의 모임이지만 네이버페이의 List와 카카오페이의 List는 다르다.
그렇다면 이 둘을 구분하려면 어떻게 해야할까?
가장 흔한 방법은 변수명을 다르게 하는 것이다.
List<Pay> naverPays = createNaverPays();
List<Pay> kakaoPays = createKakaoPays();위 코드의 단점은 검색이 어렵고, 명확한 표현이 불가능하다는 것이다.
이러한 문제 역시 일급 컬렉션으로 쉽게 해결할 수 있다.
네이버페이 그룹과 카카오페이 그룹 각각의 일급 컬렉션을 만들면 이 컬렉션을 기반으로 용어사용과 검색이 가능하다.
NaverPays naverPays = new NaverPays(createNaverPays());
KakaoPays kakaoPays = new KakaoPays(createKakaoPays());