
🤷레디스?? 그게 뭔데??
사전적 정의로는 Remote Dictionary Server 이다.
- Remote -> 외부
- dictionary -> HashMap (Key - Value),
- server -> 서버
오픈 소스 DBMS이다.
In-memory 데이터 저장소이며, Key-Value 기반의 NoSQL DBMS이다.
보통 DB,Cache,메세지 브로커 등의 용도로 사용한다.
In-memory란, 데이터를 저장하려면 컴퓨터가 꺼져도 저장될 수 있는 SSD, HDD 등에 저장해야 하지만, 메모리에 저장하고 쉽게 접근해서 처리할 수 있게되는 것을 의미한다.
그럼 Cache는 또 뭐야??
- 💡 Cache란 나중에 요청할 결과를 미리 저장해둔 후 빠르게 서비스 해주는 것을 의미합니다.
즉, 미리 결과를 저장하고 나중에 요청이 오면 그 요청에 대해 DB 또는 API를 참조하지 않고 캐시를 접근하여 처리하게 된다.
이러한 cache가 동작 할 수 있는 철학에는 파레토 법칙이 있다.
파레토 법칙이란 80퍼센트의 결과는 20퍼센트의 원인으로 인해 발생한다는 말이다.
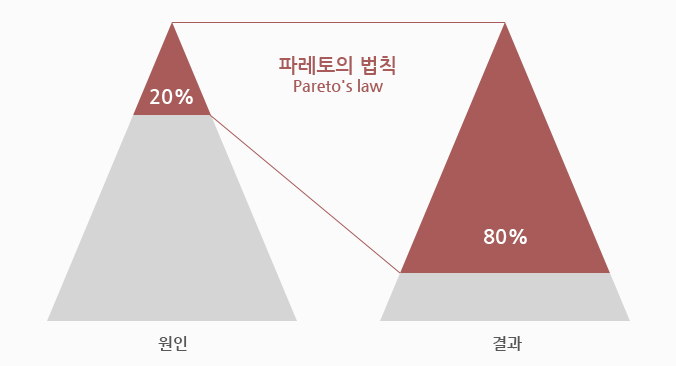
이는 캐시가 효율적일 수 있는 이유가 된다. 모든 결과를 캐싱할 필요는 없으며, 서비스할 때 많이 사용되는 20%의 데이터를 캐싱하면 전체적으로 영향을 주어 효율을 극대화 할 수 있다.
그럼 이 Cache를 어디에 저장하는게 가장 빠를까?
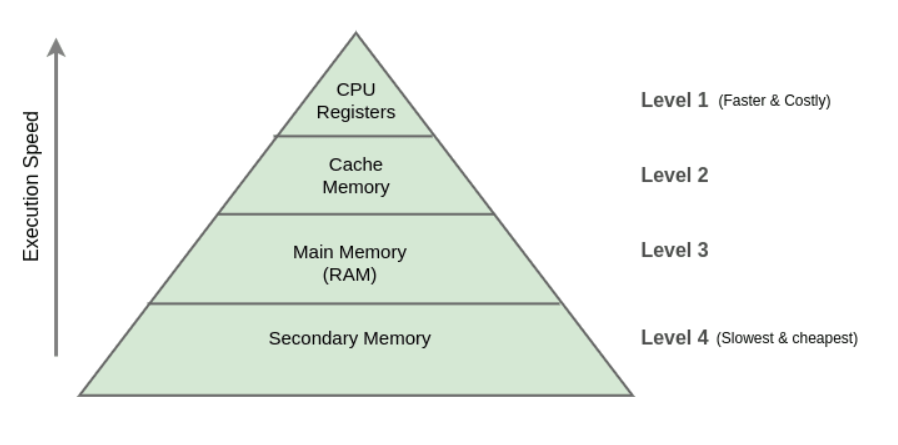
상층 구조로 갈수록 비싸고 빠르고 밑으로 갈수록 느리고 저렴한 저장소이다.
기본적으로 데이터는 컴퓨터가 꺼져도 저장이 되어야 해서, SSD,HDD 등에 저장이 되는데, 기술이 발달하고 하드웨어들이 커지다 보니 Main Memory에 저장하고 쉽게 접근하면 어떨까? 하는 개념으로 나온게 Redis이다.
Redis는 기존 MYSQL같은 관계형 데베보다 훨씬 빠른데 그 이유는 메모리 접근이 디스크 접근보다 빠르기 떄문이다.
💡즉, DataBase 보다 더빠른 Memory에 더 자주 접근하고, 덜 자주 바뀌는 데이터를 저장할 때 적합하다.
아니 그러면 다른 In-Memory 데이터베이스도 있잖아 개네들도 똑같이 빠르다는 장점이 있는데 그거 말고 다른 장점은 없어??
-> 있습니다.
Redis의 장점
레디스는 Single Thread로 동작하며, 파이프라이닝 기능을 제공한다.
Single Thread로 동작하면서도 높은 성능을 유지하기 위해, 다수의 명령어를 줄 세우고 한번에 처리하는 파이프라이닝 기능을 활용할 수 있다.
이를 통해 네트워크 지연시간을 최소화하면서 처리량을 높여 효율성을 극대화할 수 있다.
다른 In-Memory DB와의 차별점으로는,
레디스는 데이터의 지속성을 보장하며, 데이터를 디스크에 저장하는 것이 가능하다.
이를 통해 메모리의 데이터가 유실되지 않고 영속성을 확보할 수 있다.
또한 레디스 클러스터를 활용하면, 높은 가용성과 스케일링이 가능해진다.
레디스 클러스터를 구축하게 되면, 레디스 노드간의 자동 복제와 파티셔닝 처리가 가능하여, 데이터의 신뢰성을 향상시키고, 많은 데이터를 처리할 수 있게 된다.
요약하면, 레디스의 장점으로는 다음과 같은 것들이 있다.
- 다양한 자료구조를 지원
- 높은 성능과 파이프라이닝 기능
- 데이터의 영속성 보장
- 레디스 클러스터를 통한 스케일링과 높은 가용성
레디스는 또 다른 장점으로는 다양한 자료구조를 지원한다.
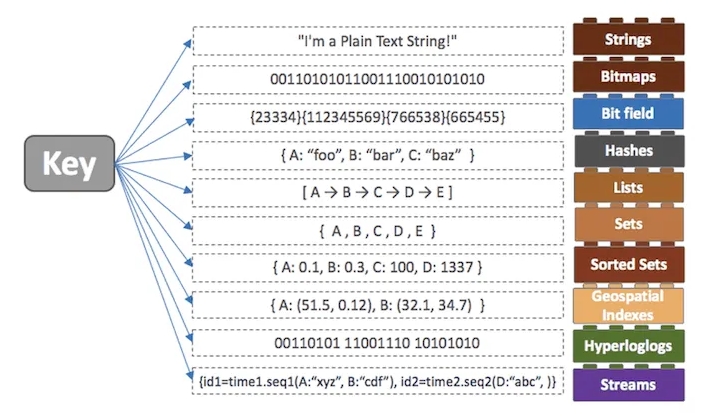
String, Hash, List, Set,Sorted Set, Bitmap을 제공했고, 버전이 올라가면서
현재는 Stream 등의 자료형도 지원하고 있다.
이렇게 다양한 자료구조를 제공함으로써 개발자들이 필요에 따라 더욱 적절한 자료구조를 선택하여 사용할 수 있다.
근데 이렇게 자료형이 많은게 뭐가 좋은데??
for 개발 편의성 && 난이도
예를 들어, 포트폴그램에서 가장 많이 사용되는 기능 중 하나는 팔로우한 사용자의 포트폴리오를 조회하는 기능이다.
이를 관계형 데이터베이스로 구현한다면, DB에 저장된 포트폴리오를 조회하기 위해 많은 조인과 정렬 작업이 필요합니다.
하지만 레디스를 사용하면 Set 자료구조를 활용하여 간단하게 팔로우한 사용자의 포트폴리오를 조회할 수 있습니다
관계형 DBMS를 이용하여 조회했을 경우
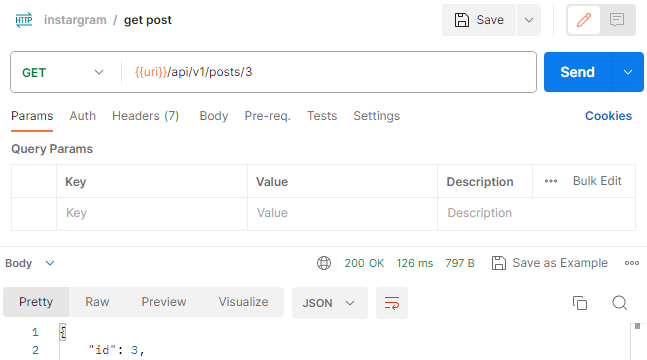
Redis를 이용하여 조회했을경우
둘의 속도를 비교해보면 126ms -> 16ms로 확연히 줄어든 것을 볼 수 있다.
또한, 레디스는 트랜잭션 문제도 해결할 수 있다. 레디스는 싱글 스레드로 동작하는 자료구조이므로 atomic한 작업을 보장한다.
Redis의 원리
레디스의 원리 중 하나는 "lazy loading"입니다. 이는 필요한 데이터만 캐시에 로드하는 캐싱 전략입니다.
캐시는 데이터베이스와 어플리케이션 사이에 위치하여 단순한 key-value 형태의 데이터를 저장한다.
데이터를 가져올 때에는 먼저 레디스에 요청하여 데이터를 반환하고, 캐시에 없는 데이터일 경우에만 데이터베이스에 요청하고 어플리케이션은 이 데이터를 다시 레디스에 저장한다.
이를 통해 실제로 사용되는 데이터만 캐시할 수 있으며, 레디스의 빠른 속도를 활용할 수 있습니다.
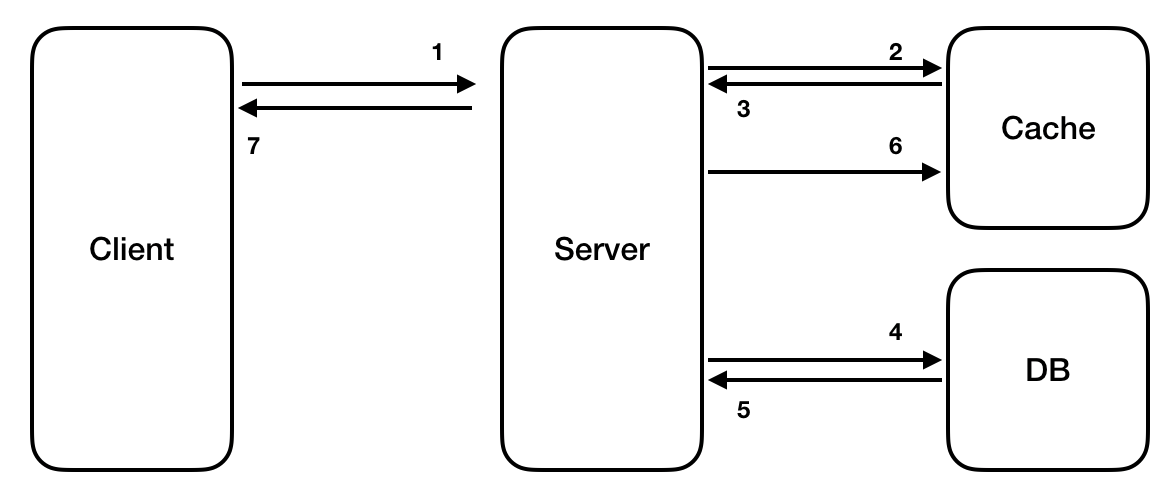
캐시에 데이터가 있을 경우 (만료 X)
- 클라이언트가 서버에 데이터를 요청합니다.
- 서버는 Cache에 해당 데이터가 있는지 확인합니다.
- 캐시에 데이터가 있으므로 바로 반환합니다
장점
이 구조를 사용하게 된다면
- 실제로 사용되는 데이터만 캐시 가능
- 레디스의 장애 => 애플리케이션에 치명적인 영향 주지않음
왜냐하면 차선책으로 실제 데이터에 접근하여 최신의 데이터 가져오기 때문이다. 그 후 데이터 접근에 대해서는 다시 캐시가 적용된다.
단점
- But 캐시에 없는 데이터를 쿼리할 때 더 오랜 시간 걸림
- 캐시가 항상 최신 데이터를 가지고 있다는 것을 보장하지 못함
- 캐시에 해당 key갑이 존재하지 않을 때만 캐시에 대한 업데이트가 일어나서 -> 데이터베이스에서 데이터가 변경될 경우 -> 해당 값을 캐시가 알지 못한다.
Write-Through
write-through 전략은 데이터를 추가하거나 업데이트할 때 캐시에 동시에 업데이트하는 전략
아래의 이미지와 같습니다.
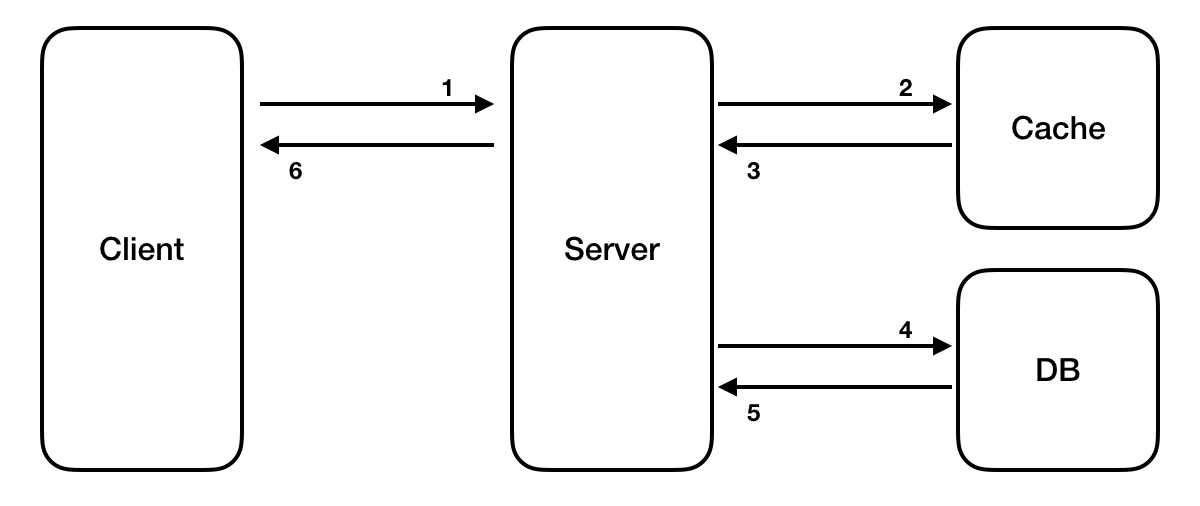
Write-through 구조
- 데이터베이스에 데이터를 작성할 때마다 캐시에 데이터를 추가하거나 업데이트한다
-> 캐시의 데이터를 항상 최신 상태로 유지 할 수 있지만 데이터 입력 시 두번의 과정을 거침
-> 지연 시간 증가
사용되지않을수도있는데이터
-> 캐시에 저장 = 리소스낭비
그래서 이떄, 데이터 입력시 TTL을 사용하여 사용되지 않는 데이터 삭제 권장한다.
그리고 읽을때는 아래와 같이 실제 DB를 볼 필요 없이 cache만 읽으면 된다.
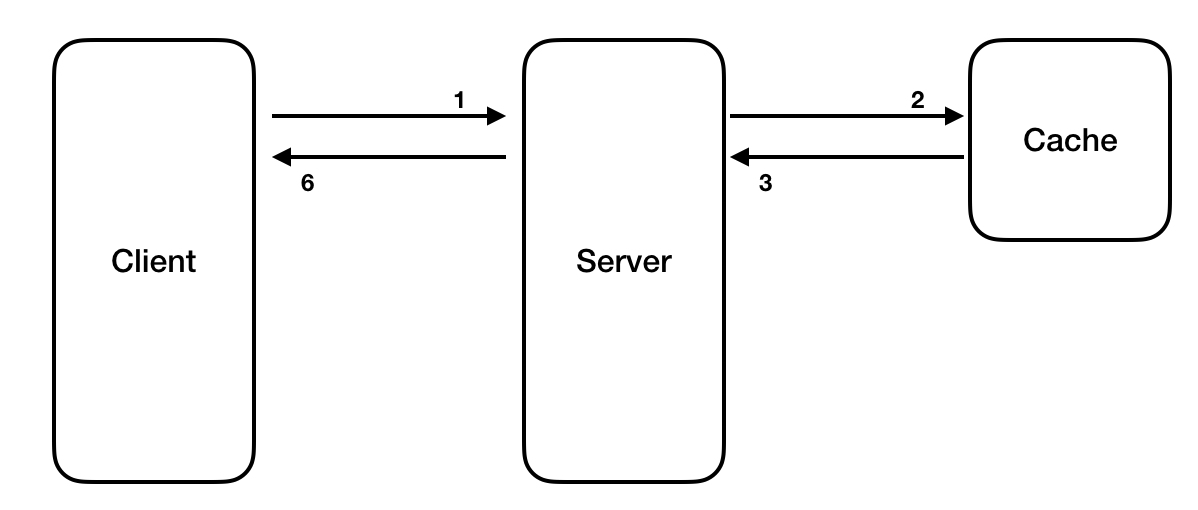
Redis의 단점
하지만 캐시에 없는 데이터를 쿼리할 때는 더 오랜 시간이 소요될 수 있고, 항상 최신 데이터를 가지고 있다는 보장이 없다.
또한, 데이터베이스에서 데이터가 변경되면 캐시가 해당 값을 알지 못하므로 캐시와 데이터베이스의 일관성을 유지하는 작업이 필요하다.
PorfoGram에 Redis 도입한 이유
레디스를 포트폴그램에 도입한 이유는 데이터를 캐시로 저장하여 트랜잭션과 비교할 때 매우 빠르기 때문이다.
예를 들어, 포트폴그램 좋아요를 처리할 때 사용자 ID와 포트폴리오 ID를 키로하여 레디스의 Set 자료구조를 사용하면 중복 좋아요를 방지할 수 있다.
또한, 레디스의 Sorted Set을 사용하여 사용자별 좋아요 수를 기록하고 랭킹을 확인할 수도 있다.
또 다른 예는 팔로우한 유저의 포트폴리오 불러오기 api 이다.
- 사용자가 팔로우한 유저의 포트폴리오를 레디스에 캐싱하여, 빠르게 불러올 수 있다.
팔로우 관계를 표현하기 위해 레디스의 Set 자료구조를 사용할 수 있다. - 예를 들어, 각 사용자의 팔로우 목록을 Set에 저장하고 해당 Set에 속한 포트폴리오 ID를 레디스의 List 나 Sorted Set에 저장하여 최신 포트폴리
내가 레디스를 이용해 구현한 과정 및 방법
그래서 팔로우한 유저의 포트폴리오 불러오기 코드 구현을 하였다.
@Transactional
public List<Portfolio> getFollowedPortfolios(Long userId) {
String redisKey = "user:" + userId + ":followedPortfolios";
Set<String> followedPortfolioIds = redisTemplate.opsForSet().members(redisKey);
if (followedPortfolioIds != null && !followedPortfolioIds.isEmpty()) {
List<Long> portfolioIds = followedPortfolioIds.stream()
.map(Long::parseLong)
.collect(Collectors.toList());
List<PortfolioEntity> followedPortfolioEntities = portfolioRepository.findAllById(portfolioIds);
return followedPortfolioEntities.stream()
.map(Portfolio::fromEntity)
.collect(Collectors.toList());
}
List<PortfolioEntity> followedPortfolioEntities = portfolioRepository.findFollowedPortfolios(userId);
List<Portfolio> followedPortfolios = followedPortfolioEntities.stream()
.map(Portfolio::fromEntity)
.collect(Collectors.toList());
if (!followedPortfolios.isEmpty()) {
updateFollowedPortfoliosInRedis(userId, followedPortfolios, redisKey);
}
return followedPortfolios;
}
//TODO: 팔로우 추가 및 언팔로우 기능 구현 -> 이 메소드 호출하여 캐시 업데이트하기
public void updateFollowedPortfoliosInRedis(Long userId, List<Portfolio> followedPortfolios, String redisKey) {
Set<String> updatedPortfolioIds = followedPortfolios.stream()
.map(portfolioDto -> String.valueOf(portfolioDto.getId()))
.collect(Collectors.toSet());
redisTemplate.opsForSet().add(redisKey, updatedPortfolioIds.toArray(new String[0]));
}
그렇다면 왜 이렇게 구현했을까??
캐시를 사용함으로써 데이터베이스에 대한 읽기 부하를 줄이고 결과적으로 응답 속도를 개선하기 위함이다.
내가 구현한 과정에서 발생할 수 있는 문제점
-
데이터 동기화 문제: 데이터베이스와 Redis 캐시 사이의 데이터 동기화 문제가 발생할 수 있다.
코드에서는 팔로우 상태가 변경될 때마다 updateFollowedPortfoliosInRedis 메서드를 호출하여 Redis 캐시를 업데이트하도록 구현되어 있다.
그러나 팔로우 상태가 변경되는 과정에서 이 메서드를 호출하지 않거나, 메서드 호출이 실패할 경우, 데이터 동기화 문제가 발생할 수 있다. -
Redis 연결 실패: Redis 서버에 문제가 발생하여 연결되지 않거나 데이터를 제대로 저장/읽기하지 못하는 경우에 대비하는 로직이 없다. 이런 경우를 대비하여 Redis 연결 및 데이터 처리에 대한 예외 처리를 구현하거나 영구 저장소에 대한 대안 방법을 고려해야 한다.
-
예외 처리 및 에러 핸들링: 코드에서 예외 처리 및 에러 핸들링이 구체적으로 작성되지 않았습니다. 예외 처리 및 로깅을 통해 시스템 작동에 문제가 발생했을 경우 쉽게 파악하고 해결할 수 있도록 구현해야 한다.
-
코드 유지 보수성: 팔로우 상태가 변경되는 모든 기능에서 updateFollowedPortfoliosInRedis 메서드를 호출해야 한다는 점에서 코드 유지 보수성이 떨어질 수 있다. 이를 개선하려면 팔로우 상태 변경과 관련된 로직을 중앙화하거나 AOP 위에 처리해야 한다.
더 나아가야 할 방향
-
더 세밀한 동기화: 매일 자정에 실행되는 동기화 작업을 더 세밀하게 조정하여 일관성 유지를 개선할 수 있다. 예를 들어, 비동기 이벤트 발행 및 구독을 통한 즉시 동기화를 고려할 수 있다.
-
캐시 전략 개선: TTL 설정을 포함한 캐시 전략을 개선하여 사용자 경험을 더욱 향상시킬 수 있다. 예를 들어, 유휴시간에 데이터를 미리 캐싱하는 전략을 적용하거나, Least Recently Used (LRU) 알고리즘과 같은 캐시 교체 전략을 도입할 수 있다.
-
Redis의 다양한 기능 활용: Redis의 다양한 기능을 활용하여 애플리케이션 성능을 더욱 향상시킬 수 있습. 예를 들어, GeoHash를 활용하여 위치 기반 기능을 구현하거나, Stream 자료구조를 사용하여 비동기 통신을 구현하는 등의 활용 방안을 고려할 수 있다.
