🗂️index
⚡️시간복잡도와 메모리 관점에서의 배열
👉시간 복잡도
👉시간복잡도를 표기하는 방법
👉메모리 관점에서의 배열
⚡️배열이란
👉배열
👉배열에서 나오는 용어
👉배열의 한계
⚡️Read
⚡️Search
⚡️Add
⚡️Delete⚡️ 시간복잡도와 메모리 관점에서의 배열
👉 시간 복잡도(Time complexity)
데이터 구조의 오퍼레이션 혹은 알고리즘이 얼마나 빠르고 느린지 측정하는 방법.
실제시간을 측정하는 것이 아니며, 얼마나 많은 steps가 있는가로 측정한다.
🙋시간 복잡도를 고려한다는 것의 의미는 무엇인가?
알고리즘의 로직을 코드로 구현할 때, 시간 복잡도를 고려한다는 것은 '입력값의 변화에 따라 연산을 실행할 때, 연산횟수에 비해 시간이 얼마만큼 걸리는가?'라는 의미이다.이는 위에서 언급한 steps를 좀 더 상세하게 표현한 것이다.효율적인 알고리즘을 구현한다는 것은 입력값이 커짐에 따라 증가하는 시간의 비율을 최소화한 알고리즘을 구성했다는 이야기이다.
시간 복잡도는 주로 빅-오 표기법을 사용해 나타낸다.
👉 시간 복잡도를 표기하는 방법
- Big-O ⇒ 상한 점근(시간 복잡도를 최악의 경우에 대하여 나타내는 방법)
- Big-Ω ⇒ 하한 점근(시간 복잡도를 최선의 경우에 대하여 나타내는 방법)
- Big-θ ⇒ 그 둘의 평균(시간 복잡도를 중간(평균)의 경우에 대하여 나타내는 방법)
이 중 가장 자주 사용되는 표기법은 빅오 표기법인데, 이는 최악의 시간을 고려하기 때문이다. "최소한 특정 시간 이상이 걸린다(Big-Ω)" "이 정도 시간이 걸린다(Big-θ)"를 고려하는 것 보다 "이 정도 시간까지 걸릴 수 있다"를 고려하는 편이 그에 맞는 대응을 가능하게하기 때문이다.
이 보다 더 다루게 되면 이 글의 메인 주제가 시간 복잡도가 되기 때문에 이 정도로 간단히 설명하도록 한다. 자세한 내용은 아래의 링클르 참고하자.
시간복잡도와 Big-O표기법에 대한 자세한 설명
👉 메모리 관점에서의 배열
메모리는 volatile(휘발성)와 non-volatile(비휘발성)으로 나뉜다. 이 둘의 예는 각각 HDD와 RAM(Random Access Memory)가 있다.
배열을 만들 때, 메모리에게 배열이 얼마나 긴지 설명해야한다. 그 공간을 미리 예약/할당해야 하기 때문이다.(Python, JS같은 unmanaged language에서는 이 역할을 자동으로 해주는데 이는 프로그램 속도 저하의 이유가 될 수 있다.)
⚡️배열이란?
👉배열
배열이란 연관된 데이터를 하나의 변수에 그룹핑해서 관리하기 위한 방법이다. 배열을 이용할 시, 하나의 변수에 여러 정보를 담을 수 있고, 반복문과 결합할 경우에는 많은 정보도 효율적으로 처리할 수 있다.
배열의 정보는 많은 정보를 효율적으로 처리하는 것 같다.
👉배열에서 나오는 용어
student = new Array();
student[0] = '최진혁';
student[1] = '한이람';
student[2] = '최유빈';- value는 코드에서 '최진혁'같은 것을 말한다.
- index는 []안에 입력되는 숫자를 말한다.
index는 전체 집단에서 그 데이터를 식별하는 역할을 한다.
또한, index를 통해서 어떤 데이터를 저장 및 가져올 수 있다. - element는 value와 index를 묶어서 말한다고 보면 된다.
👉배열의 한계
예를 들어, 학급을 프로그래밍적으로 배열을 이용해서 표현한다고 해보자, 이는 배열로 표현하기 매우 좋다. 학생은 배열에서 하나의 엘리먼트로 표현가능하다. 학생의 이름은 value, 학생의 index는 학번으로 기능할 수 있다.
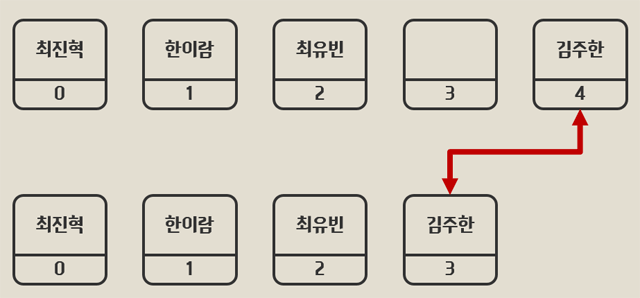
하지만 여기에서 한 학생(인덱스가 3인)이 전학을 갔다고 생각해보자.
이러면, index값이 3인 element는 null값으로 처리된다. 이는 반복문을 이용한 배열의 값을 출력하는 실행결과에 Null값이 포함된다는 의미이며 이는 조건문으로 제거 가능하다. 하지만 이러한 반복문이 수없이 많아지게 된다면, 조건문 또한 많아질 것이다. 또한 배열에서는 index에 따라서 값을 유지하기에 element가 삭제되어도 그대로 남게 된다. 이렇게 존재하지 않는 데이터는 삭제한 자리를 뒤에 위치한 element로 메꿈으로서 처리가능하지만(이렇게 데이터가 순서에 따라서 빈틈없이 연속적으로 위치하는 자료구조를 list라고 한다.) element를 옮기면서 인덱스의 값이 달라진다는 문제가 발생한다.
⚡️Read
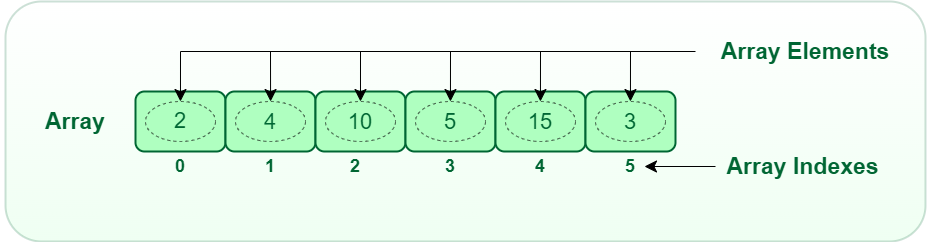
- 배열은 0부터 인덱싱한다.
- 위의 배열에서 10이라는 요소를 얻고 싶다면 컴퓨터에게 인덱스 2번 값을 달라고 하면 된다.
배열에서 읽어내는 건 엄청빠르다. 따라서 많은 자료를 읽어내야 한다면 배열을 이용하면 좋다!
⚡️Search
원하는 값이 배열에 있는지 없는지 모를 때, 검색을 하는 경우 다 뒤지는 수 밖에 없다.
이러한 경우, 검색을 하게 되고 순서대로 0부터 끝까지 차근차근 찾는 걸 선형검색(Linear search)라 한다.
⚡️Insert(Add)
이 챕터는 예를 들어 설명하겠다.
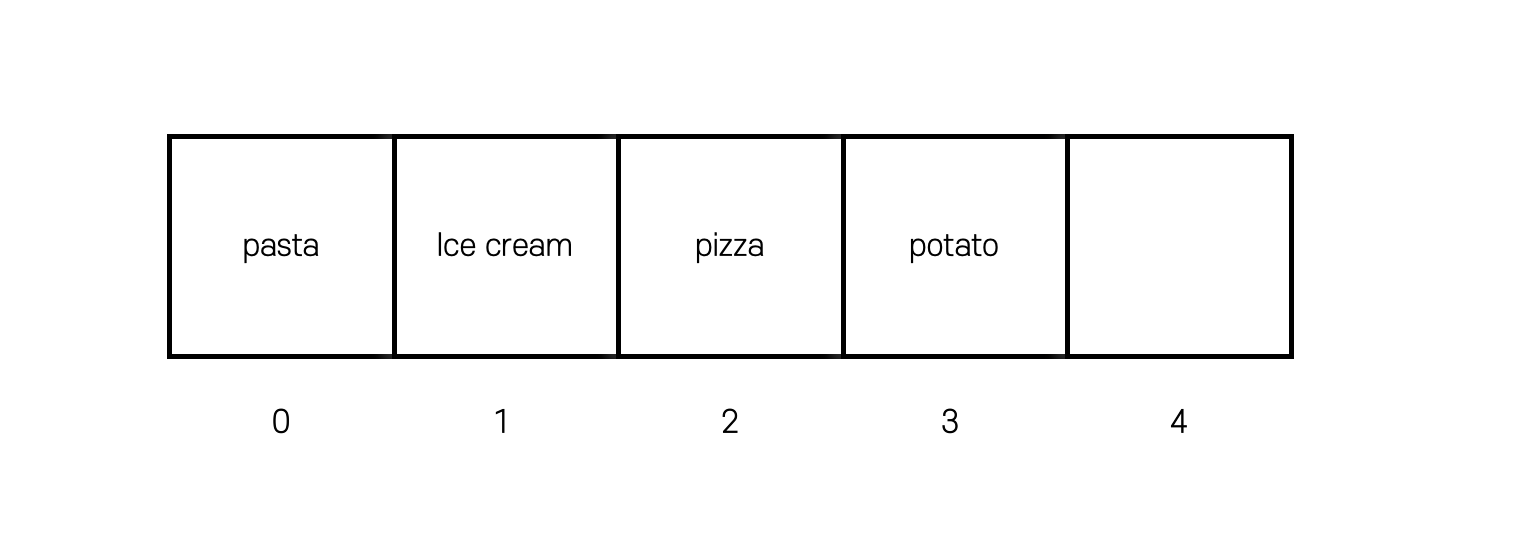
다음과 같은 배열을 생성하고 4개의 요소를 채워넣었다.
이 배열에 tomato라는 요소를 추가하고 싶다면, 어디에 추가할 수 있을까? 경우는 3가지로 나뉜다.
- 최고의 시나리오
"tomato" 배열 맨 끝에 추가하는 경우에는 그냥 끝에 요소를 추가하면 끝난다. - 보통의 시나리오
"tomato"를 중간 위치에 추가하는 경우에는 다른 요소를 움직이는 과정이 추가되고 움직임으로써 생긴 공간에 요소를 추가하면 끝난다. - 최악의 시나리오
"tomato"를 배열 맨 끝에 추가하는 경우에는 모든 요소를 한 번씩은 움직여야하고, 끝 공간에 요소를 추가하는 과정이 생기므로 가장 오래걸리게 된다. 또한, 공간이 다 차있는데 추가해야하는 경우는 공간이 하나 더 있는 배열을 추가로 생성 후, 기존의 배열을 복사하고 다시 요소를 움직여 추가하므로 시간이 오래걸리게 된다.
⚡️Delete
Add랑 상당히 흡사하다.
맨 끝 요소를 지울 경우 지우는 과정으로 끝나지만, 중간 혹은 앞에 있는 요소 제거시 공백을 매꾸기 위해 요소를 앞으로 움직이는 과정이 추가된다.
⚡️결론
배열은 데이터를 읽을 때는 정말 빠르다.
단, 검색/추가/삭제할 때에는 느리다.
🙇참고자료
(youtube)노마드코더-Array 배열 기초개념? 10분안에 정리해줌!
https://hanamon.kr/알고리즘-time-complexity-시간-복잡도/
opentutorials-자료구조-배열
