이번에 진행하는 프로젝트에서 검색 기능이 필요한데, 데이터 셋이 약 300만개 정도되다보니 MySQL에서 문자열 LIKE연산으로 처리하는것에 한계가 느껴졌다.
그래서 엘라스틱 서치를 도입하기로 했는데, 2024년 기준 최신버전은 정보가 너무 없어서 진행하면서 알게된 내용을 정리하고자한다.
스펙
Elastic Search : 8.13.4
Kibana : 8.13.4
Spring Boot : 3.3.2
Spring Data Elasticsearch : Spring Boot Starter 제공
엘라스틱서치와 스프링 데이터 엘라스틱 서치는 버전에 따라서 사용할 수 있는 메서드, 함수가 확확 변하며 특히 7.x버전과 8.x버전은 차이가 크니 아래 표에서 자신에 맞는 버전을 선택하도록 하자.
https://docs.spring.io/spring-data/elasticsearch/reference/elasticsearch/versions.html
여기서 필자는 Spring Boot Starter를 사용하여 아래처럼 build.gradle에 dependencies를 구성했다.
implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch'
만일 위의 표를 참조하여 직접 Spring Data Elasticsearch의 버전을 맞춰주고자 한다면 아래처럼 구성하면된다.
implementation 'org.springframework.data:spring-data-elasticsearch:5.3.3'
엘라스틱서치 & 키바나 구성
윈도우 환경에서 엘라스틱 서치를 설치할 때의 불편함과 추후 CI / CD를 위한 gitHub workflow 구축시에 docker-compose 파일을 사용할 것을 고려하여 docker에 엘라스틱 서치와 키바나를 컨테이너로 올려서 사용할 것이다.
Docker가 설치되어 있다면 아래의 명령어를 통해 엘라스틱 서치와 키바나 이미지를 pull하고 컨테이너로 실행한다
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.13.4
docker pull docker.elastic.co/kibana/kibana:8.13.4
docker run --name elastic -p 9200:9200 -p 9300:9300 --restart=unless-stopped -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:8.13.4
docker run -p 5601:5601 --name kibana docker.elastic.co/kibana/kibana:8.13.4
이렇게하면 기본적으로 pc가 켜지고 docker daemon이 실행되면 elastic search가 자동으로 실행되지만 키바나는 엘라스틱서치가 실행되어야지만 실행할 수 있기 때문에 수동으로 실행시킨다. 해당 부분은 추후 docker-compose를 통해 elasticsearch가 실행되면 kibana가 실행되도록 설정할 수 있다.
이제 아래 명령어를 통해 도커가 잘 실행 되었는지 확인할 수 있다.
docker ps
만일 프로세스가 보이지 않는다면 컨테이너가 실행되지않은 것이다.
이제 아래의 명령어를 사용하여 elastic search 컨테이너 인스턴스에 접속한다
docker exec -it elasticTest /bin/bash
접속한 인스턴스에서 해당 명령어를 실행하여 비밀번호를 변경한다.
cd bin
elasticsearch-reset-password -u elastic
그 후 kibana에 접속하기 위한 token을 발급받는다.
elasticsearch-create-enrollment-token --scope kibana
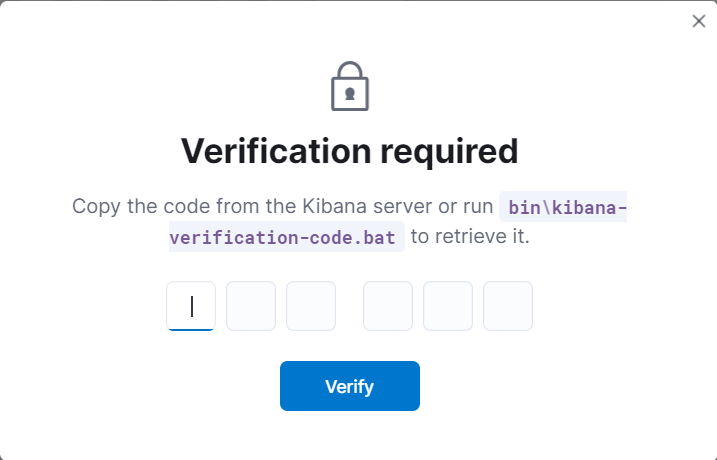
이후 보안코드를 받기 위한 명령어
docker exec -it -u 0 kibana /bin/bash
cd bin
kibana-verification-code
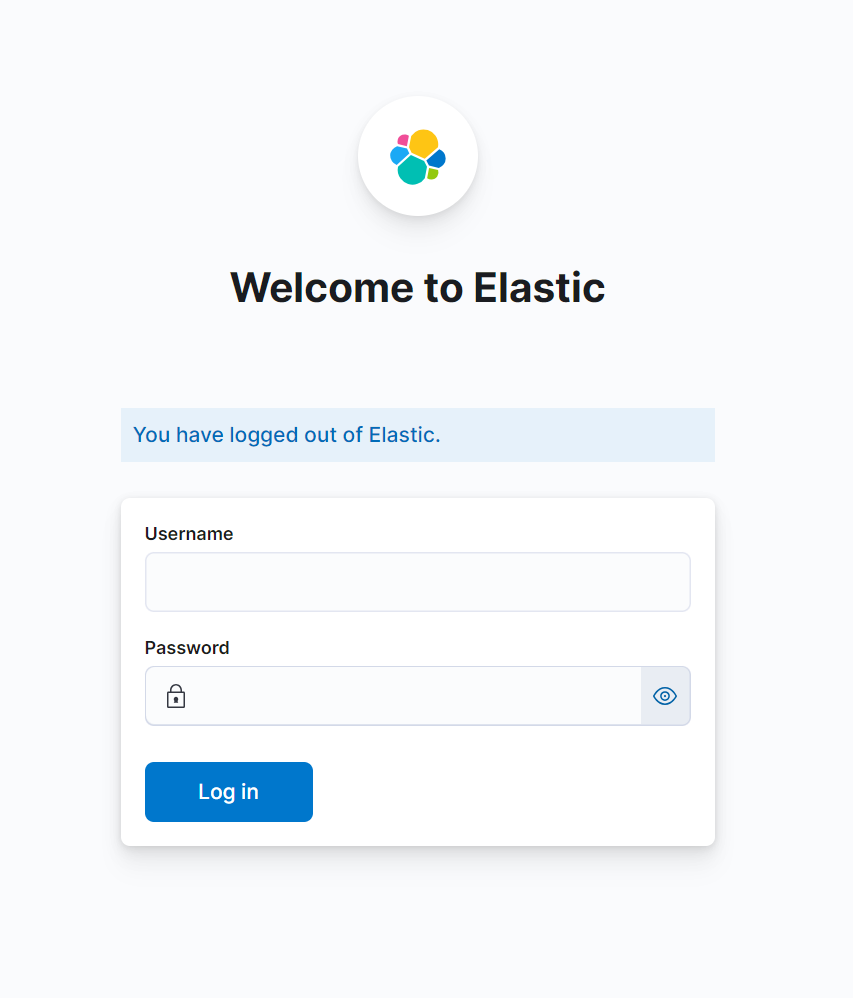
토큰 입력까지 완료후 키바나에 접속하면 아래와 같은 화면이 나오니 elastic과 설정한 비밀번호로 로그인을 해주면 키바나 설정은 완료된다.
그 후 키바나에 접속하면 아래와 같은 화면이 나오는데
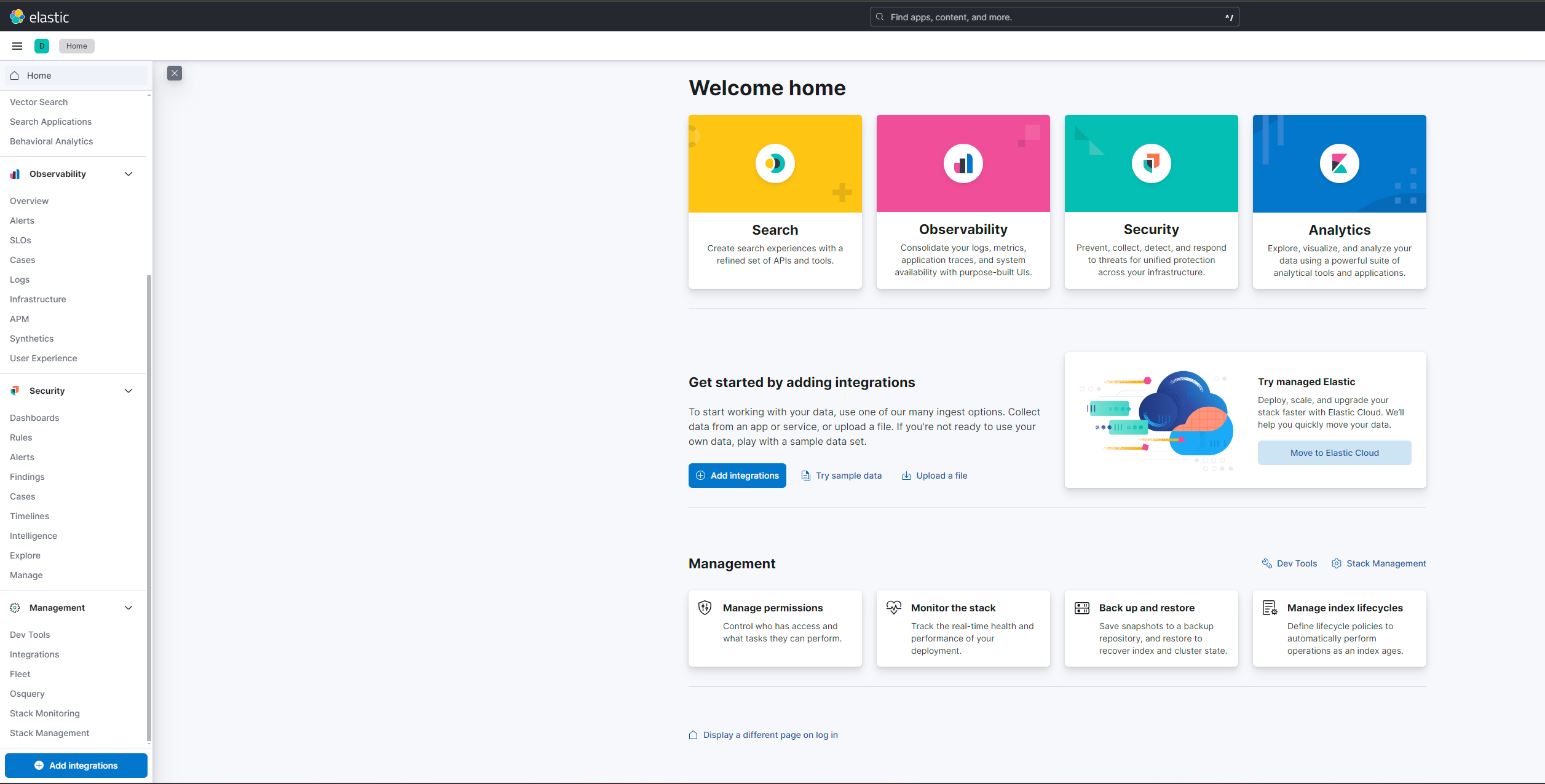
좌측하단 Dev Tools에서 elasticsearch 쿼리 테스트를 할 수 있다.
아래 명령어를 사용하여 index가 잘 조회 된다면 엘라스틱 서치와 키바나 연결은 끝이다.

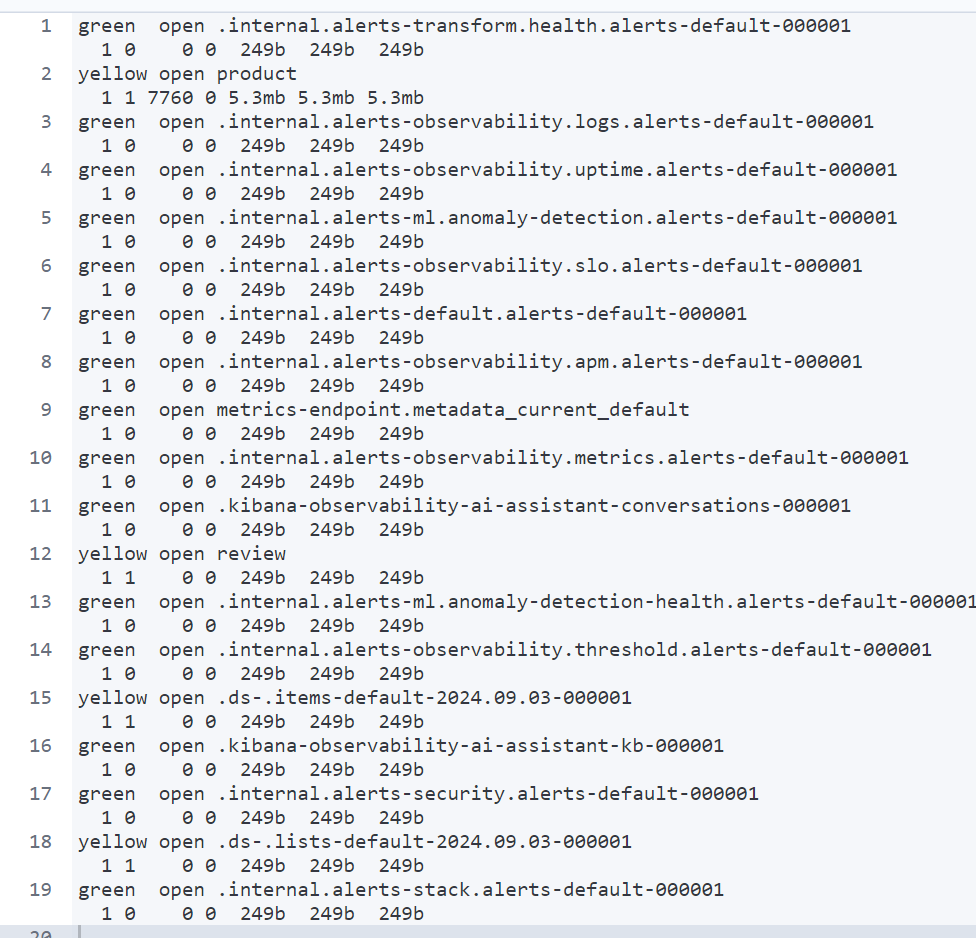
스프링부트 엘라스틱 서치 연결
그럼 이제 스프링 부트에서 엘라스틱 서치를 연결할 차례이다.
팀원이 서버PC를 가지고 있어서 엘라스틱 서치와 키바나를 원격 리눅스 서버의 도커에 올려서 사용했다. 엘라스틱 서치 8.x 버전부터는 https 요청이 필수적이라 server pc를 관리하는 팀원에게 요청하여 개발 ssl인증서 (.p12 확장자 형태의 파일)을 받아서 resource 디렉터리에 저장해두었다. 로컬 pc에서 키바나, 엘라스틱서치, 스프링부트를 모두 가동하는 경우에는 엘라스틱 서치 자체적으로 생성하는 ssl 인증서를 resource 폴더에 저장해야한다. 배포과정에서 보안적인 측면으로는 신뢰도가 높아지는 것은 사실이나 개발과정에서도 이런저런 신경쓸 것이 많아지기 때문에 여러모로 8.x 버전부터는 여러모로 정말 귀찮아졌다. 로컬에서 elasticsearch ssl 인증서를 발급 받는 방법은 아래에 참고에서 설명한다.
이제 엘라스틱 서치와 연결을 위한 설정 클래스를 구성해야한다.
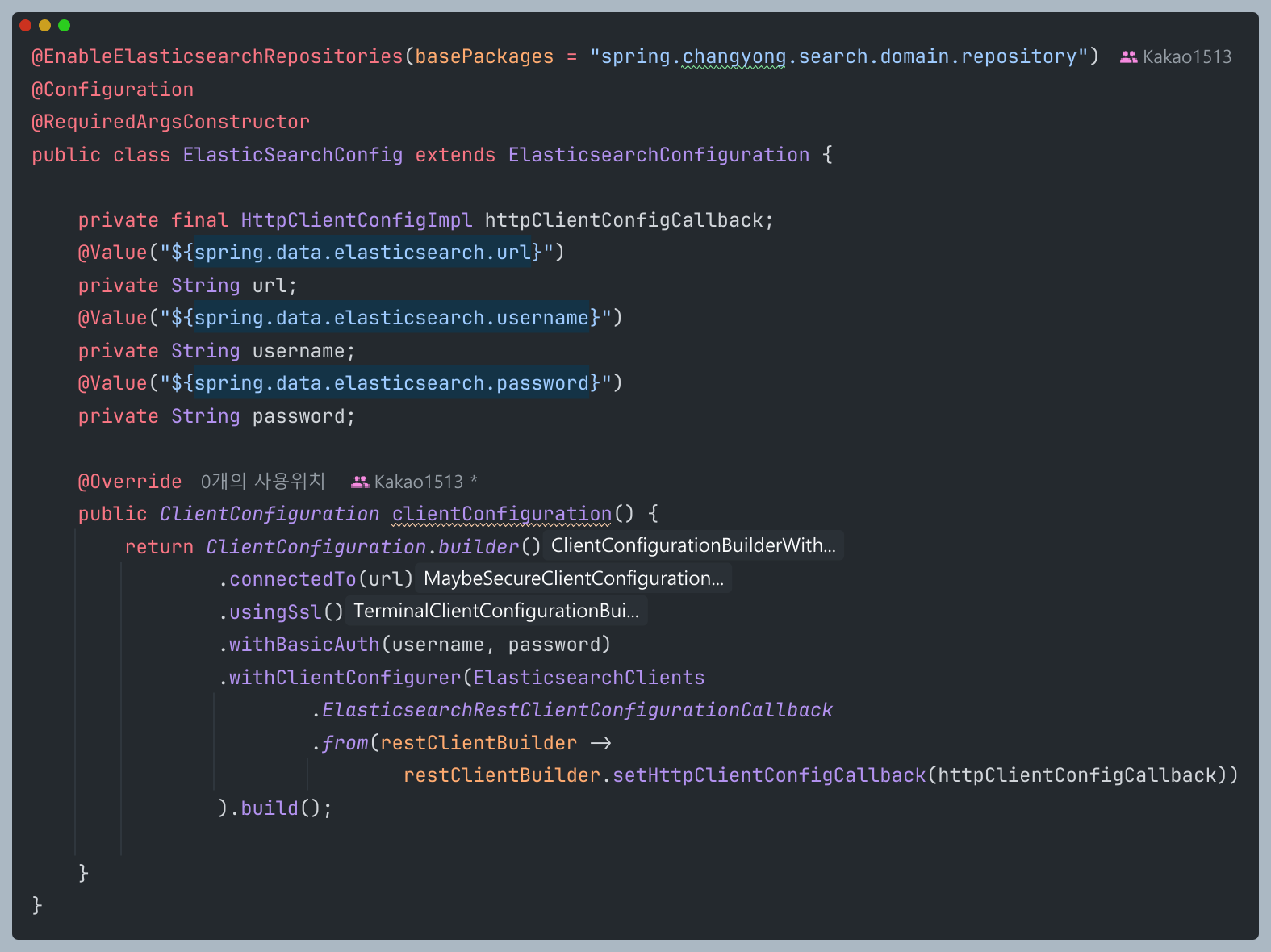
basePackages 부분은 ElasticSearchRepository<Document, ID>인터페이스를 상속받는 ElasticSearchRepository 인터페이스가 모여있는 패키지로 설정해주면된다.
여기서 ClientConfiguration은 Spring Data Elasticsearch에서 고수준으로 추상화된 인터페이스이다. 해당 인터페이스를 설정해준다면 RestClient, ElasticSearchOperations등의 저수준으로 추상화된 인터페이스의 구현체들을 스프링 빈으로 등록하여 의존성 주입을 받을 수 있게 된다.
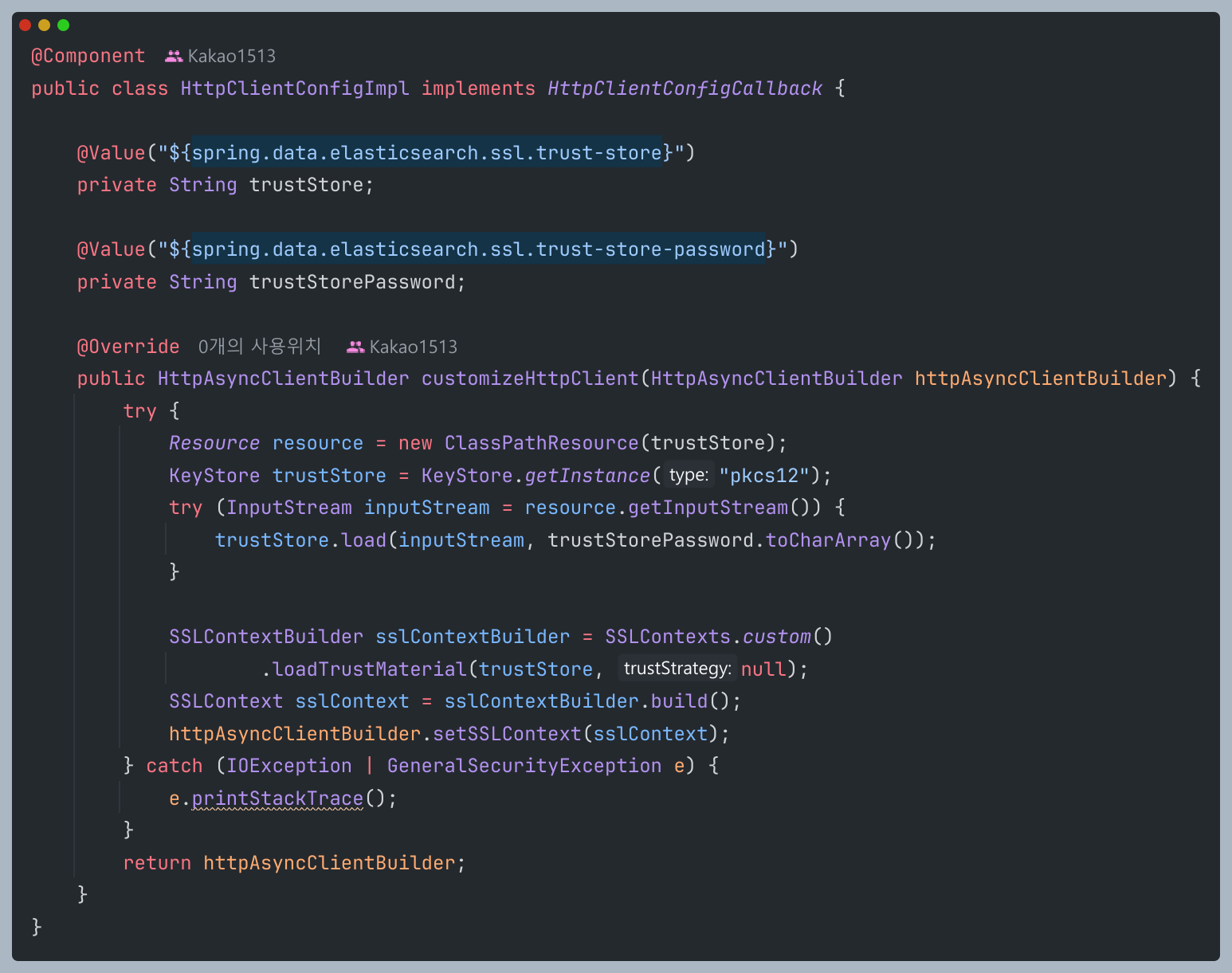
다음은 HttpClientConfigImpl 클래스이다. ssl인증서 정보를 가져오는 역할을 한다.
해당 클래스는 clientConfigration 초기화 과정에서 구성해도 상관은 없지만 코드가 지저분해져서 따로 컴포넌트로 분리시켰다.
ClassPathResource로 생성하여 들고와야지만 추후 .jar 파일로 빌드할때 오류가 생기지않는다.
trustStore에는 발급받은 ssl 인증서 경로를 적고
인증서 비밀번호를 함께 등록한다.
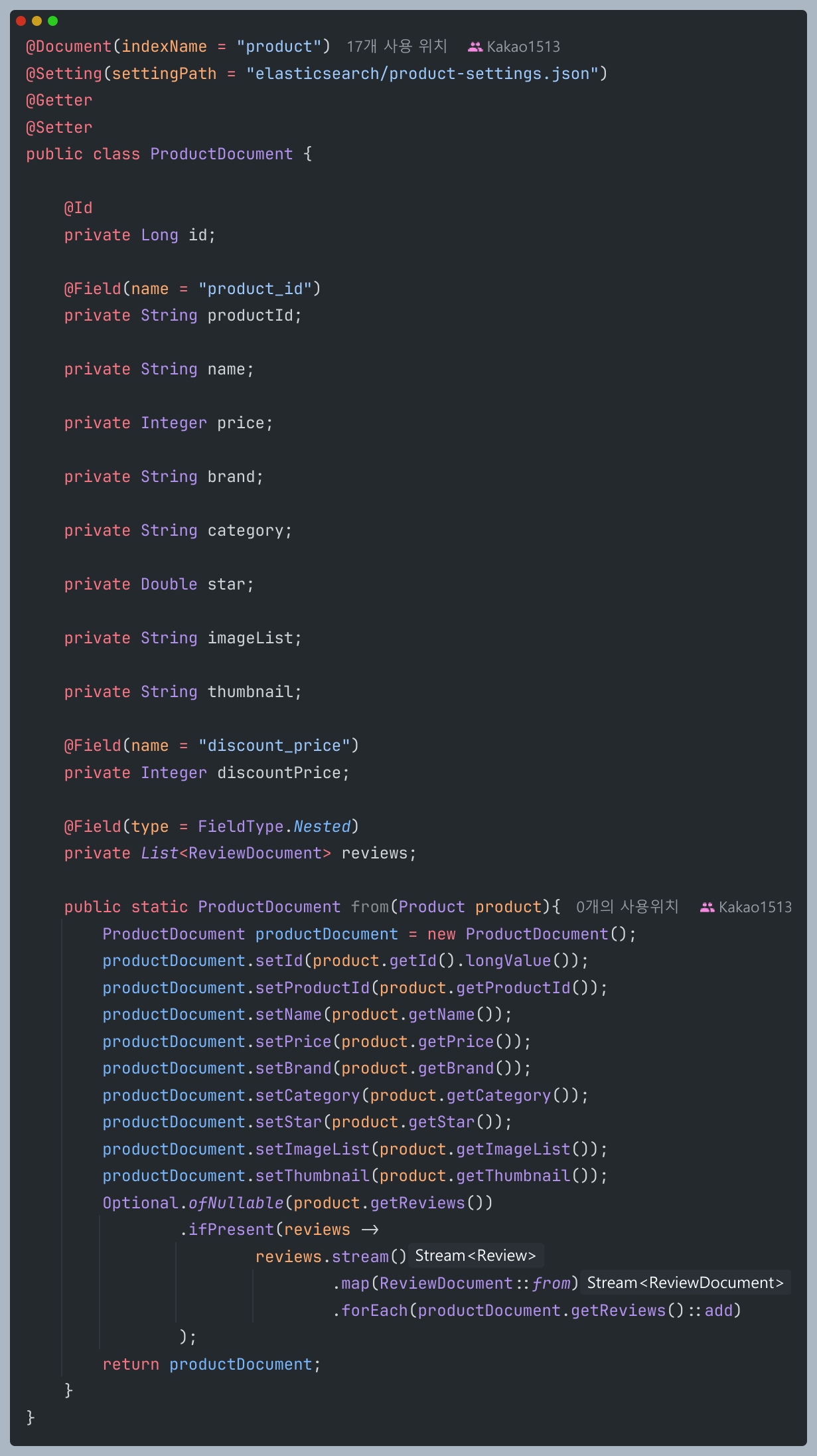
여기까지 완료하면 이제 CrudRepository를 상속하는 ElasticSearchRepository를 사용할 수 있게된다.
ProductDocument 클래스
ProductSearchRepository 인터페이스

이후 사용법은 Spring Data JPA와 유사하며, ElasticSearchOperations를 사용한 customRepository를 만들어서 사용하면된다.
참고1)
이번 프로젝트에서는 팀원이 크롤링해온 올리브영의 상품 및 리뷰 데이터를 MySQL에 저장해두었다. 엘라스틱 서치를 도입함에 따라 해당 테이블과 로우를 엘라스틱 서치의 도큐먼트와 인덱스로 마이그레이션을 시켜야한다. 실시간으로 데이터를 크롤링해오거나 주기적으로 DB가 업데이트 된다면 로그스테시를 사용해야하겠지만, 이번 프로젝트는 저장해둔 데이터를 기반으로 NLP 모델 학습 및 검색 엔진 구현이 목표이므로 데이터를 마이그레이션 시키는 1회용 파이썬 코드를 작성했다. 동적으로 데이터를 동기화 시켜야한다면 로그스테시로 파이프라인을 구축하는 것을 추천한다. 파이썬는 elasticsearch와 연결할 때 verify를 False로 설정하면 인증서를 무시하고 요청을 보낼 수 있다. 그러나 Spring에서는 HttpClientCallback의 구현체에서 검증을 하는것인지는 확실하지않지만 verify설정을 false로하면 Exception이 발생하면서 프로세스가 죽어버린다.
import requests
from requests.auth import HTTPBasicAuth
import pandas as pd
from sqlalchemy import create_engine
import orjson
# MySQL 데이터베이스 연결
db = mysql.connector.connect(
host=#호스트정보,
user=#DB유저,
password=#비밀번호,
database=#스키마
)
# 벌크 API 호출
username = #엘라스틱 서치 유저네임
password = #엘라스틱 서치 비밀번호
# Elasticsearch URL
es_url = #엘라스틱 서치 URL
# SQLAlchemy 엔진 생성
engine = create_engine(f"mysql+pymysql://{db['user']}:{db['password']}@{db['host']}/{db['database']}")
# SQL 쿼리 작성
query = "SELECT * FROM <테이블 명>"
# 데이터프레임으로 쿼리 결과 가져오기
print("데이터 가져오기 시작")
df = pd.read_sql(query, engine)
print(f"가져온 데이터 수: {len(df)}")
def process_batch(batch):
bulk_data = []
for _, row in batch.iterrows():
bulk_data.append(orjson.dumps({"index": {"_index": "review", "_id": row['id']}}).decode('utf-8'))
bulk_data.append(orjson.dumps(row.to_dict()).decode('utf-8'))
bulk_data = '\n'.join(bulk_data) + '\n'
response = requests.post(es_url,
data=bulk_data,
headers={"Content-Type": "application/json"},
verify=False,
auth=HTTPBasicAuth(username, password))
if response.status_code != 200:
print(f"Error: {response.status_code}, {response.text}")
else:
print(f"Batch processed successfully")
# 배치 크기 설정
BATCH_SIZE = 10000
# 데이터를 배치로 나누어 처리
for i in range(0, len(df), BATCH_SIZE):
print(f"Processing batch {i // BATCH_SIZE + 1}")
batch = df[i:i + BATCH_SIZE]
process_batch(batch)
print("데이터 저장 완료")
참고2) 로컬 docker에서 엘라스틱서치의 ssl인증서를 가져오는 방법
아래 명령어를 사용하면 http_ca.crt 파일을 가져올 수 있다.
docker cp <엘라스틱서치컨테이너 명>:/usr/share/elasticsearch/config/certs/http_ca.crt /<저장할 폴더>
이후 openSSL을 사용하여 .p12 파일로 변환한다.
openssl pkcs12 -export -in http_ca.crt -inkey ssl.key -out truststore.p12
키파일 비밀번호를 입력하고
truststore.p12파일의 보호 비밀번호를 입력한 후 resource폴더에 추가하면된다.
