
다음은 사내에서 진행 되었던 '성능 좋은 쿼리 작성 교육 - 초급 과정'을 듣고 정리한 내용입니다.
<교육 목차>
- 교육과정 목표
- 교육과정 개요
- 과정 소개 및 기본 고려사항
- 쿼리 금기사항
- 더 좋은 쿼리 작성하기
- 모듈 작성시 고려사항
1. 목표
- 성능 좋은 쿼리 작성을 위한 기본 규칙들과 금기 사항들에 대해서
- 품질 좋은 쿼리 작성을 위한 기본 지식들에 대해서
- 실무 사례들의 간접적 경험을 통해 활용
2. 개요
A) 과정 소개
- 공통적인 성능/관리 이슈의 요소, DB 성능 관리 주기, 쿼리 튜닝 수준별 접근
B) 기본 고려사항
- WHERE절, FROM절, 날짜시간 상수, Char vs Varchar, 데이터 형식, 조인조건 vs 검색조건
C) 쿼리 금기사항
- Non-SARG : SARG, Non-SARG 사례분석
- 조건절 상수화 이슈
D) 더 좋은 쿼리 작성하기 (T-SQL, Join, SubQuery, CTE)
- IN vs. BETWEEN, TOP(N), 집계함수와 NULL, 불필요한 GROUP BY열, UNION vs. UNION ALL
- Nested Loop JOIN이해, 불필요한 OUTER JOIN, SubQuery 이해/적용 예, 파생테이블, CTE, APLLY 활용
- 차집합-NOT IN 사용주의, CTE 재귀쿼리 활용
E) 모듈 작성시 고려사항
- Cursor, 뷰 고려사항과 사용자 정의 함수 및 만능 View 주의
- 과정 소개 및 기본 고려사항
과정 소개에선 1) 공통적인 성능/관리 이슈의 요소 2) DB 성능 관리 주기 3) 쿼리 튜닝 수준별 접근에 대해서 살펴보겠습니다.
A) 과정 소개
1) 공통적인 성능/관리 이슈의 요소들
- 비표준 구문 사용
- SARG 위반
- 불필요한 I/O 유발, 임시테이블과 변수, Cursur/Loop 사용
- 부적절한 함수와 뷰, 만능 조회 사용
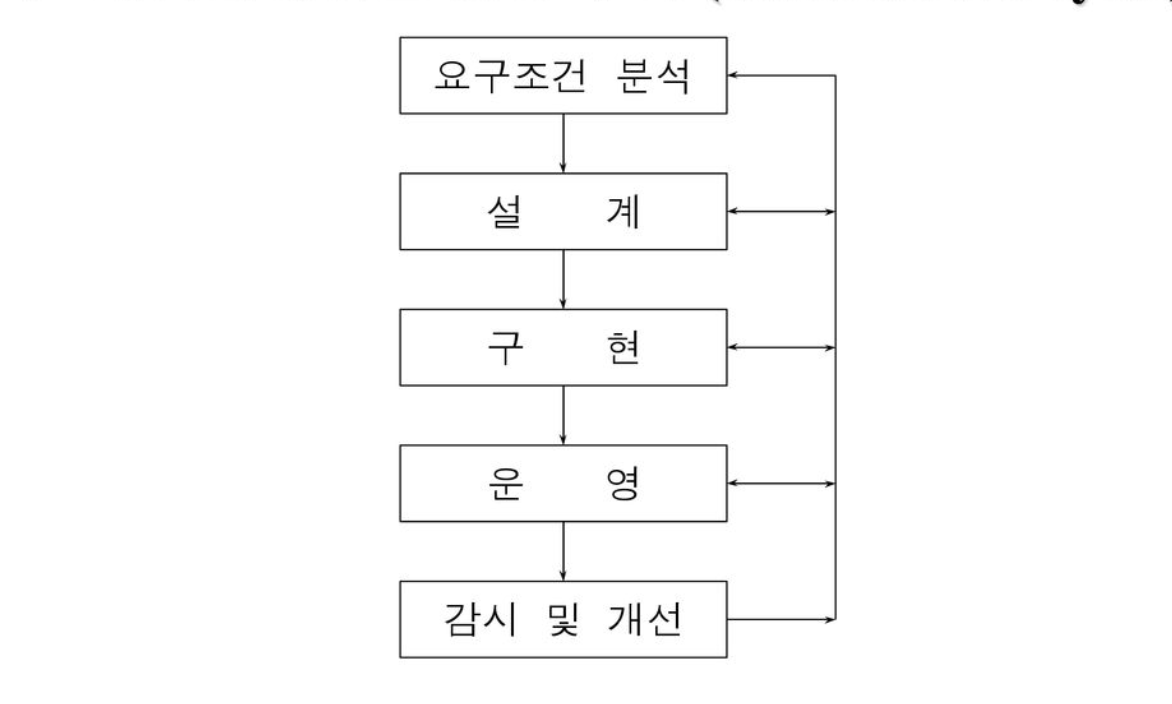
2) DB 성능 관리 주기
- DB의 성능 관리 주기는 설계>구현>운영의 단계로 이어진다.
- 설계 단계에서 DB모델링과 아키텍처를 구현 단계에선 application과 T-SQL 마지막 운영단계에선 안정화와 성능 관리로 이어집니다. 본 교육 과정에서 다룰 성능 고려를 위한 단계는 구현 단계입니다.
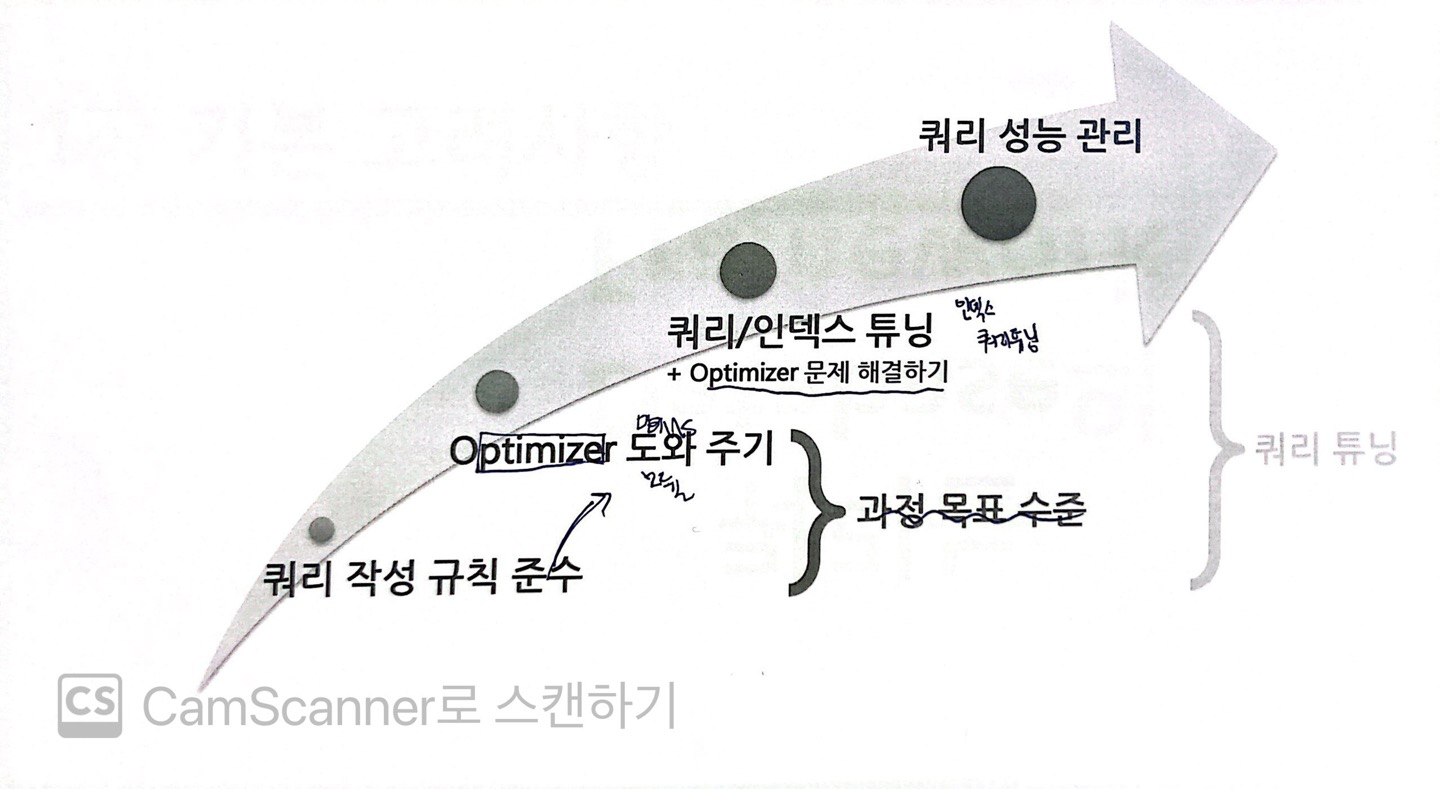
3) 쿼리 튜닝 수준별 접근
- 본 과정인 쿼리 튜닝의 첫번째 단계에선 쿼리 작성 규칙을 준수함으로서 SQL을 가장 빠르고 효율적으로 수행할 최적의 처리경로를 생성해주는 옵티마이저를 도와야한다.
- 이후 쿼리/인덱스 튜닝 단계에 들어가면 옵티마이저 문제를 직접 해결하며 쿼리 성능을 관리하는 단계로 이어진다.
참고) 옵티마이저란?
- SQL을 가장 빠르고 효율적으로 수행할 최적의 처리경로를 생성해 주는 DBMS 내부의 핵심 엔진이다.
옵티마이저 순서
1) 사용자가 구조화된 질의어(SQL)로 결과 집합을 요구하면 이를 생성하는데 필요한 처리경로를 DBMS에 내장된 옵티마이저가 자동으로 생성
2) 옵티마이저가 생성한 SQL 처리경로, 실행계획(Execution Plan, 쿼리문을 어떻게 실행시킬지에 대한 계획)을 세운다.
3) 시스템 통계정보를 활용해 각 실행계획의 예상 비용을 산정한 후 각 실행계획을 비교해서 최고의 효율을 가지고 있는 실행계획을 판별한다.
4) 그 실행계획에 따라 쿼리를 수행한다.
[출처: https://code-lab1.tistory.com/137]
B) 기본 고려사항
기본 고려사항에선 1) 쿼리 성능 측정을 위한 도구들 2) 개발 및 관리 도구 사용 주의 3) ANSI 표준 사용하기에 대해서 살펴보고 4) WHERE, FROM 절 작성 순서와 성능 연관성 5) 스키마 이름 지정 6)날짜시간 상수 7) Char vs Varchar 8) 데이터 형식 9) 조인조건 vs 검색조건 10) 임의/매개변수 쿼리의 호출 식별자 달기 마지막으로 11) 의미 오류 이해 순서으로 살펴보겠습니다.
1) 쿼리 성능 측정을 위한 도구들(참고)
- SSMS '실제 실행 계획 포함' 기능 (Ctrl+M)을 통해 인덱스 사용 여부 판단
- 세현옵션인 'SET STATISTICS IO'을 통해 테이블 단위의 Page IO량 확인
- 그 외에 방법들엔 세션 옵션인 'SET STATISTICS TIME', 'SQL server 프로파일러(추적)', '확장 이벤트', '추적 플래스', 'DBCC 명령' 등도 있다.
- 첫 번째, 실제 실행 계획을 통한 인덱스 사용 여부 판단하기
[출처:https://m.blog.naver.com/dktmrorl/222306507699]
- 실행 계획을 살펴보면 정상 사용하지 못하는 경우엔 1) 'clustered Index Scan', '인덱스 스캔'이라는 키워드가
인덱스를 정상적으로 사용한다면 2,3,4)'Index Seek', '클러스터형 인덱스 검색'이라는 키워드를 볼 수 있다.
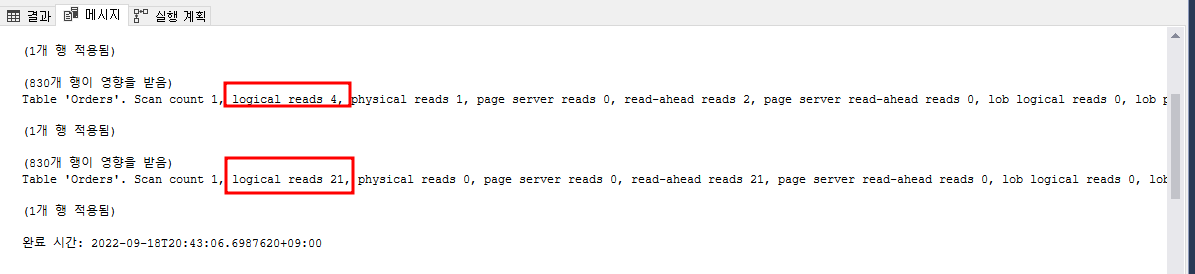
- 두 번째, 세션 옵션 'SET STATISTICS IO'을 통해 IO 발생량 확인하기
- 세션 옵션인 SET STATISTICS IO을 통해 쿼리에서 읽은 Data/Index의 page(8KB) 즉, 논리적 읽기(=데이터베이스 엔진이 버퍼 캐시에서 페이지를 요청할 때마다 발생하며 데이터 캐시에서 읽은 페이지 수)IO을 확인을 할 수 있다.
- 참고로 검색 수는 실행된 검색 수이며 물리적 읽기 수는 디스크에서 읽은 페이지 수 그리고 미리 읽기 수는 쿼리에 대해 캐시에 넣어진 페이지 수다.
2) 개발 및 관리 도구 사용주의(주의사항)
1) SSMS Intellisense 사용 주의
- 다른 세션 차단 유발 가능하므로 운영시에 Intellisense off 권장
2) SQL Server Profile 사용 주의
- 잘못 사용 시 서버에 큰 부하 유발하므로 권한 관리를 통해 DB 관리자만 허용하도록 사용 제약을 줄 것을 권장
3) 서드 파티 도구 사용 시 부하 주의
- 잘못 사용시 대용량 테이블 전체 읽기 발생하므로 주의
3) ANSI 표준 사용하기
- 성능과 유지 관리 고려하는데 있어 ANSI/IOS 표준 SQL 문을 사용하고 사라지는 구문들은 사용 배제할 것
- STANDARD JOIN 기능들 (CROSS, OUTER JOIN 등 새로운 FROM 절 JOIN 기능들)
- SCALAR SUBQUERY, TOP-N QUERY 등의 새로운 SUBQUERY 기능들
- ROLLUP, CUBE, GROUPING SETS 등의 새로운 리포팅 기능
- WINDOW FUNCTION 같은 새로운 개념의 분석 기능들
4 ) WHERE, FROM 절 작성 순서와 성능과의 연관성
- 이는 교환/결합법칙 성립과 동일하다. AB=BA 처럼 WHERE, FROM 절 모두 작성순서와 성능은 연관성이 없다.(INNER JOIN 한정)
- 옵티마이저가 해당 SQL문을 모두 뒤집어서 순서를 결정하기에 실행 순서를 보장할 수 없다.
5) 스키마 이름 지정(권장사항)
- 개체 이름 해석
- 개체 유일성을 유지, 즉 스키마 이름은 현재 데이터베이스에서 유일해야 함
- 식별자 이름은 db.schema.object, two part name 사용을 권장
- schema 생략시엔 ID를 사용하자
EX) 잘못된 예시 - SELECT FROM dbo.A / SELECT FROM dbo.up_Orders
6) 날짜시간 상수 이해
- 상수 유형
- 2021/10/10 구분자
- 00:00:00.000
- GETDATE()+1
- 20211011 23:59:59:997 YYMMDD ANSI 표준
- 시간 생략 시엔 정시, 날짜 생략시엔 19900101이 기본 값
- 주의할 건 밀리초의 최대 시간은 997이라는 점- 검색 조건 유형
-BETWEEN '20211010' AND '20211010 23:59:59:99?'에 밀리초 마지막 부분에 7,8,9에 따라 범위가 달라지는데 999인 경우 20211011 다음 날로 넘어간다.
->='20211010' AND < '20211011'와 같이 자정으로 조건을 지정하는 것 권장
7) Char vs Varchar 이해

- Varchar는 유니코드가 아닌 가변 길이의 문자형, Char는 유니코드가 아닌 고정 길이의 문자형
- nVarchar와 nChar는 유니코드인 가변, 고정 길이 문자형으로 DBMS 종류에 따라 약간의 차이가 존재한다.
DECLARE @varchar varchar(8), @char char(8) SELECT @varchar = 'sql ', @char = 'sql ' IF ( @varchar = 'sql' ) PRINT '같다' IF ( @char = 'sql' ) PRINT '같다' IF ( @varchar = @char ) PRINT '같다'
- 다음 문구를 찍어보면 모두 '같다'라는 결과가 나온다.
WHERE varchar_col = RTRIM(@char)따라서 다음과 같은 조건 절에서 RTRIM을 통해 오른쪽 공백을 제거할 필요가 없다.
8) 조건절의 명확한 () 괄호 사용하기
WHERE A = ? AND (B = ? OR (C = ? OR (D = ? OR E = ? )) )
- 다음과 같이 조건 절 () 사용 시 짝이 맞지 않는 경우도 왕왕있으니 주의 해야한다.
9) 조인조건 vs 검색조건
SELECT o.OrderID, o.CustomerID, * FROM dbo.Customers AS c LEFT JOIN dbo.Orders AS o ON c.CustomerID = o.CustomerID WHERE c.CustomerID IN ('FISSA', 'PARIS', 'ANTON') AND o.CustomerID IS NULL/* 이 조건의 위치를 어디에 둘 것인가? */
- 조인 조건과 검색 조건은 의미에 맞게 명확하게 구분해서 지정해야한다. 이는 성능 차원에 구분이 아니라 조건에 대한 의미차원에 결정된다.
- 조인 집합 결정 조건을 걸 땐, 조인 조건을 사용해야한다.
- 결과 집합 결정 조건을 걸 땐, 검색 조건을 사용해야한다.
10) 임의/매개변수 쿼리의 호출 식별자 달기(권장)
- DB단에서 쿼리가 실행될 땐 어느 모듈에서 호출되는 쿼리인지 추적이 어렵다. 특히 분산 쿼리의 경우
- 따라서 쿼리에 주석을 달아 어떤 모듈/라이브러리/함수에서 호출이되는지 설명을 달 것
- 이는 SQL Server 프로파일러/추적/확장이벤트 등에서 추적에 도움을 준다.
11. 의미 오류(Semantic Error)이해
- 데이터 일관성(무결성) 이슈와 잠재적인 성능 이슈에 대해
1) 의미 오류 유형 - 불필요한 조건이 달려있는 예
- PK는 null일 수 없음
SELECT ... FROM dto.Orders WHERE PK_col IS NULL; SELECT ... FROM dto.Orders WHERE ISNULL(PK_col, 0) = 10250;
- 모두 참인 경우
SELECT ... FROM dto.Orders WHERE Quntity < 0'; SELECT ... FROM dto.Orders WHERE ShipVia > 4 OR ShipVia >2;
- 중복 발생할 수 없는 경우
SELECT DISTINCT CustomerID,CompanyName FROM dto.Orders
2) 의미 오류 유형
- LIKE문 불 필요 => LIKE = EQUAL과 동일
SELECT ... FROM dto.Orders WHERE CusㅁtomerID LIKE 'QUICK';
- 의미없는 셀렉트 > EXSITS는 조건을 만족하면 바로 리턴하므로 서브 쿼리 내 셀렉트 절에는 관심이 없음
IF EXISTS (SELECT DISTINCT OrderDate FROM dto.Orders ...)
- 불필요하게 많은 정렬 조건 > PK(OrdeID, ProductID)이므로 UnitPrice 불필요, 특히 SORT는 부하를 일으키 주요 원인
SELECT ... FROM dto.[Orders Detail] ORDER BY OrdeID, ProductID, UnitPrice
- 만능 조회 쿼리
SELECT ... WHERE ProductName LIKE % 또는 ProductName IS NOT NULL
- WHERE 절에 사용해야할 조건을 HAVING 절에 쓰는 경우
SELECT ... GROUP BY ShipCountry HAVING ShipCountry IN ('USA', 'Switzerland')
3)의미오류 샘플 사례
- 서브쿼리로 자기 자신 ID 모두 조회한 경우
- 서브쿼리는 문법적으로 서크쿼리에 없는 절도 참조 가능하기에 주의SELECT ... FROM dto.Orders WHERE OrdeID IN(SELECT OrderID FROM dto.Customers);
- 별칭을 생략한 경우
SELECT 50 OrdeID FROM dto.Orders WHERE OrdeID = 'QUICK' ORDER BY OrderDate
- 불필요한 OUTER JOIN
- 조인의 의미가 WHERE 절의 의미와 맞지 않는 상황실제 실행 시 OUTER는 INNER로 바뀜SELECT m.EmployeeID As RptstTo, m.LastName ... FROM dto.Employees AS m LETF JOIN dbo.Employees AS e ON m.EmployeeID = e.RptstTo WHERE e.Title = 'Sales Manager';
*💡핵심요약
SQL Server와 T-SQL 기초에 대한 이해 필요
- SQL Server에 적합한 코드 구현
- 성능, 운영 혹은 업데이트 시 영향을 미친다
- 타 DBMS에서 마이그레이션 시 고려
- 이기종 호환성 코드 작업 시도시 고려- 의미 오류는 잠재적인 성능 이슈를 내포
- 많은 경우 Query optimizer가 자동으로 성능 문제 해결해주나 오류 없도록 쿼리 작성해야함
