
"이 글은 골든래빗 코딩 테스트 합격자 되기 파이썬 편 11장의 써머리입니다."
11. 그래프(Graph)
1) 그래프의 개념
그래프 : 노드(Vertex)와 간선(Edge)을 이용한 비선형 데이터 구조
데이터 간의 관계를 표현하는 데 사용
데이터 = 노드(vertex)
노드 간 관계/흐름 = 간선(edge) → 유방향/무방향
가중치 : 관계/흐름의 정도
그래프 용어 정리
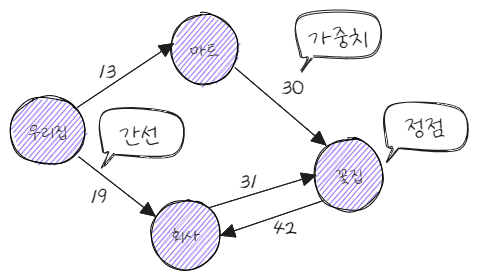
그래프의 특징과 종류
그래프는 방향성, 가중치, 순환 특성에 따라 종류 구분 가능
흐름을 표현하는 방향성
방향 그래프(Directed Graph) : 방향이 있는 간선을 포함하는 그래프
무방향 그래프(Undirected Graph) : 방향이 없는 간선을 포함하는 그래프
흐름의 정도를 표현하는 가중치
어떤 데이터는 흐름의 방향 뿐 아니라 양도 중요할 수 있어서 그런 정도를 간선에 표현할 때 가중치를 사용
시작과 끝의 연결 여부를 보는 순환
순환은 특정 노드에서 시작해 간선을 따라 다시 돌아오는 경로가 있는 것을 의미
순환 그래프(Cycle Graph) : 순환이 존재하는 그래프
비순환 그래프(Acycle Graph) : 순환이 존재하지 않는 그래프
그래프 구현
인접 행렬 그래프 표현
인접 행렬은 배열을 활용하여 구현하는 경우 多
배열의 인덱스 = 노드, 배열의 값 = 노드의 가중치
인덱스의 세로 방향 = 출발 노드, 인덱스의 가로 방향 = 도착 노드
인접 행렬의 세로 방향 인덱스 = 출발, 가로 방향 인덱스 = 도착
‘-’로 표현한 가중치는 실제 코드에서는 굉장히 큰 값을 넣거나 -1로 정함
인접 리스트 그래프 표현
적절한 노드 정의
값=정점(v), 가중치(w), 다음 노드(next)를 묶어 관리
동작 과정
-
우선은 노드 개수만큼 배열 준비
-
배열의 인덱스는 각 시작 노드를 의미하여 배열의 값에는 다음 노드 연결
2) 그래프 탐색
깊이 우선 탐색(Depth-First Search, DFS)
⭐깊이 우선 탐색 : 깊게 탐색 후 되돌아오는 특성
시작 노드부터 탐색을 시작하여 간선을 따라 최대 깊이 노드까지 이동하며 차례대로 방문
최대 깊이 노드까지 방문 후 이전 방문한 노드를 거슬러 올라가며 해당 노드와 연결된 노드 중 방문하지 않은 노드로 다시 최대 깊이까지 차례대로 방문
탐색 시작 시 시작 노드 정하고, 스택에 시작 노드 push.
깊이 우선 탐색의 핵심 : 가장 깊은 노드까지 방문한 후에 더 이상 방문할 노드가 없으면 최근 방문한 노드로 돌아온 다음, 해당 노드에서 방문할 노드가 있는지 확인
스택을 활용한 깊이 우선 탐색
선입후출의 특성을 가진 스택으로 가장 최근에 방문한 노드 확인 가능
재귀 함수를 활용한 깊이 우선 탐색
스택을 직접 사용하지 않고도 깊이 우선 탐색 구현 가능 → 재귀 함수 활용
재귀 함수를 호출 시 호출한 함수는 시스템 스택이라는 곳에 쌓이므로 깊이 우선 탐색에 활용 가능
dfs(N) : N번 노드를 방문 처리하고 N번 노드와 인접한 노드 중 아직 방문하지 않은 노드를 탐색
너비 우선 탐색(Breadth First Search, BFS)
⭐너비 우선 탐색 : 가중치가 없는 그래프에서 최단 경로 보장
시작 노드와 거리가 가장 가까운 노드를 우선하여 방문하는 방식의 알고리즘
→ 여기서 말하는 거리 : 시작 노드와 목표 노드까지의 차수
너비 우선 탐색 방식을 보면 시작 노드부터 인접한 노드를 모두 방문 후 그 다음 단계의 인접 노드 방문 즉, 먼저 발견한 노드 방문.
→ 이런 특성 때문에 너비 우선 탐색 시 큐를 활용
방문 처리 시점이 다른 이유
깊이 우선 탐색은 스택에서 pop하며 방문 처리를 했고, 너비 우선 탐색은 큐에서 push하며 방문 처리 → 탐색 방식이 다르기 때문
깊이 우선 탐색 과정에서는 스택에 다음에 방문할 인접한 노드를 push. 즉, 스택에 push할 노드는 방문 예정인 노드이므로 pop하며 방문 처리해야 함
너비 우선 탐색 과정에서는 지금 방문할 노드를 push. 그래야 인접한 노드부터 탐색 가능
3) 그래프 최단 경로(Shortest Path) 구하기
- 가중치가 없는 그래프에서는 간선 개수가 가장 적은 경로가 최단 경로
- 가중치가 있는 그래프에서는 일반적으로 시작 노드에서 끝 노드까지 이동할 때 거치는 간선의 가중치의 총합이 최소가 되는 것이 최단 경로
다익스트라(Dijkstra) 알고리즘 = 데이크스트라 알고리즘
가중치가 있는 그래프의 최단 경로를 구하는 문제는 대부분 다익스트라 알고리즘을 사용
음의 가중치가 있는 그래프일 때
다익스트라 알고리즘은 양의 가중치만 있는 그래프에서만 동작하므로 음의 가중치가 있는 그래프에서 제대로 동작 X
다익스트라 알고리즘은 시작 노드에서 각 노드까지 최소 비용을 갱신하는 과정 반복, 현재까지 구한 각 노드의 최소 비용 중 가장 작은 노드를 선택하여 움직임 = 그리디 알고리즘
** 그리디 알고리즘 : 각 단계에서 가장 좋은 것을 선택하는 전략을 가짐
벨만-포드(Bellman-Ford) 알고리즘
노드에서 노드까지 최소 비용을 구한다는 점에선 다익스트라 알고리즘과 같음
But, 벨만-포드 알고리즘은 매 단계마다 모든 간선의 가중치를 다시 확인하여 최소 비용을 갱신하므로 음의 가중치를 가지는 그래프에서도 최단 경로를 구할 수 있음
한 번 더 연산을 반복하는 이유? 음의 순환을 찾기 위해!
노드 N의 최단 경로를 구성하는 간선 개수가 N개 이상이면 최단 경로의 간선 개수는 최대 N-1이어야 함 → 음의 순환이 있다는 의미
음의 순환인 N → (N -1) 구간을 반복하면 계속해서 최소 비용(가중치의 합)은 점점 줄어듦
| 목적 | 장단점 및 특징 | 시간 복도 | |
|---|---|---|---|
| 다익스트라 알고리즘 | 출발 노드로부터 도착 노드들까지의 최단 경로 찾기 | 음의 가중치를 가지는 그래프에서 최단 경로 구할 수 없음(그리디 방식) | , 우선 순위 큐로 개선하면 |
| 벨만-포드 알고리즘 | 출발 노드로부터 도착 노드들까지의 최단 경로 찾기 | 음의 가중치를 가지는 그래프에서 최단 경로를 구할 수 있고, 음의 순환도 감지 가능 |
4) 몸 풀기 문제
문제 38) 깊이 우선 탐색 순회
깊이 우선 탐색으로 모든 그래프의 노드를 순회하는 함수 solution() 작성.
start = 시작 노드, graph = [출발 노드, 도착 노드] 쌍들이 들어 있는 리스트
반환 값 = 그래프의 시작 노드부터 모든 노드를 깊이 우선 탐색으로 진행한 순서대로 노드가 저장된 리스트def solution(graph, start):
res = []
nodes_list = {}
visited = []
for node in graph:
if node[0] not in nodes_list:
nodes_list[node[0]] = [node[1]]
else:
nodes_list[node[0]].append(node[1])
def dfs(node):
if node not in visited:
visited.append(node)
res.append(node)
if node in nodes_list:
for neighbor in nodes_list[node]:
dfs(neighbor)
dfs(start)
return res
assert solution([['A', 'B'], ['B', 'C'], ['C', 'D'], ['D', 'E']], 'A') == ['A', 'B', 'C', 'D', 'E']
assert solution([['A', 'B'], ['A', 'C'], ['B', 'D'], ['B', 'E'], ['C', 'F'], ['E', 'F']], 'A') == ['A', 'B', 'D', 'E', 'F', 'C']문제 39) 너비 우선 탐색 순회
너비 우선 탐색으로 모든 노드를 순회하는 함수 solution()을 작성
시작 노드 = start, (출발 노드, 도착 노드) 리스트 = graph
반환값 = 시작 노드부터 모든 노드를 너비 우선 탐색으로 진행한 순서대로 노드가 저장된 리스트from collections import defaultdict
def solution(graph, start):
nodes_dict = defaultdict(list)
for n, m in graph:
nodes_dict[n].append(m)
return bfs(nodes_dict, start)
def bfs(dicts, node):
visited = []
qu = []
for nodes in dicts:
if nodes == node and node not in visited:
qu.append(node)
visited.append(node)
if node in visited: qu.pop()
for n in dicts[nodes]:
if n not in visited:
qu.append(n)
visited.append(n)
if n in visited: qu.pop()
return visited
assert solution([(1, 2), (1, 3), (2, 4), (2, 5), (3, 6), (3, 7), (4, 8), (5, 8), (6, 9), (7, 9)], 1) == [1, 2, 3, 4, 5, 6, 7, 8, 9]
assert solution([(0, 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, 0)], 1) == [1, 2, 3, 4, 5, 0]문제 40) 다익스트라 알고리즘
주어진 그래프와 시작 노드를 이용하여 다익스트라 알고리즘을 구현하는 solution() 구현
인수 : graph - 딕셔너리, 노드의 연결 정보와 가중치 저장 / start - 문자열, 출발 노드
반환값 : 시작 노드부터 각 노드까지 최소 비용과 최단 경로를 포함한 리스트import heapq
def solution(graph, start):
dist = {node: float("INF") for node in graph}
dist[start] = 0
priority_qu = []
path = {node: [] for node in graph}
# 시작 노드를 우선순위 큐에 삽입
heapq.heappush(priority_qu, [dist[start], start])
# 다익스트라 알고리즘 수행
while priority_qu:
distance, node = heapq.heappop(priority_qu)
if dist[node] < distance:
continue
# 이웃 노드를 탐색하고 거리를 업데이트
for v, w in graph[node].items():
node_dist = distance + w
# 더 짧은 경로가 발견되면 거리와 경로를 업데이트
if node_dist < dist[v]:
dist[v] = node_dist
heapq.heappush(priority_qu, [node_dist, v])
path[v] = path[node] + [node]
result = {node: float("INF") for node in graph}
for node, shortest_path in path.items():
result[node] = shortest_path + [node]
return [dist, result]
assert solution({
'A': {'B':9, 'C':3},
'B': {'A':5},
'C': {'B':1}
}, 'A') == [
{'A':0, 'B':4, 'C':3},
{
'A': ['A'],
'B': ['A', 'C', 'B'],
'C': ['A', 'C']
}
]
assert solution({ \
'A': {'B':1}, \
'B': {'C':5}, \
'C': {'D':1}, \
'D': {}
}, 'A') == [
{'A':0, 'B':1, 'C':6, 'D':7}, \
{
'A': ['A'], \
'B': ['A', 'B'], \
'C': ['A', 'B', 'C'], \
'D': ['A', 'B', 'C', 'D']
}
]5) 합격자가 되는 모의 테스트
문제 42) 게임 맵 최단 거리
ROR 게임은 두 팀으로 나눠 진행하며 상대 팀 진영을 먼저 파과하면 이기는 게임. 각 팀은 상대 팀 진영에 최대한 빨리 도착해야 게임을 유리하게 이끌 수 있음
5 x 5 크기의 맵, 검은색 = 벽, 흰색 = 길, 캐릭터 이동은 동, 서, 남, 북 방향으로 한 칸씩 이동
게임 맵이 maps로 주어질 때 우리 팀 캐릭터가 상대 팀 진형에 도착하기 위해 지나가야 하는 길의 최소 개수를 반환하는 solution() 완성from collections import deque
def solution(maps):
n, m = len(maps), len(maps[0])
deq = deque([((0, 0), 1)])
visited = {(0, 0)}
while deq:
loc, dist = deq.popleft()
for x, y in [[-1, 0], [0, -1], [1, 0], [0, 1]]:
row = loc[0] + x
col = loc[1] + y
# 이동한 위치 범위 안에서 동작
if row < 0 or row >= n or col < 0 or col >= m:
continue
# 이동한 위치에 벽(= 0)이 있는 경우
if maps[row][col] == 0:
continue
next_loc = (row, col)
if next_loc not in visited:
deq.append((next_loc, dist + 1))
visited.add(next_loc)
# 종료지점
if next_loc == (n - 1, m - 1):
return dist + 1
return -1
assert solution([[1, 0, 1, 1, 1], [1, 0, 1, 0, 1], [1, 0, 1, 1, 1], [1, 1, 1, 0, 1], [0, 0, 0, 0, 1]]) == 11
assert solution([[1, 0, 1, 1, 1], [1, 0, 1, 0, 1], [1, 0, 1, 1, 1], [1, 1, 1, 0, 0], [0, 0, 0, 0, 1]]) == -1문제 43) 네트워크
컴퓨터 A, B가 직접 연결되어 있고 컴퓨터 B, C가 직접 연결되어 있을 때 컴퓨터 A, C는 간접 연결되어 있어 정보 교환 가능해서 A, B, C는 모두 같은 네트워크 상에 있다고 할 수 있음. 컴퓨터 개수가 n, 연결 정보가 담긴 2차원 배열 computers가 주어질 때 네트워크 개수를 반환하는 solution() 작성def solution(n, computers):
visited = [False] * n
net = 0 # 네트워크 개수
for i in range(n):
if not visited[i]:
dfs(computers, visited, i)
net += 1
return net
def dfs(computers, visited, cur):
visited[cur] = True
for next_node, connected in enumerate(computers[cur]):
if connected and not visited[next_node]:
dfs(computers, visited, next_node)
assert solution(3, [[1, 1, 0], [1, 1, 0], [0, 0, 1]]) == 2
assert solution(3, [[1, 1, 0], [1, 1, 1], [0, 1, 1]]) == 1