📌 Base64란?
8비트의 Binary data를 6비트의 text data로 바꾸는 인코딩 방식이다.
📌 왜 Base64를 사용하는가?
예시를 통해 Base64의 등장 배경에 대해 알아보자.
컴퓨터 네트워크 초기에는 대부분의 시스템이 인쇄 가능한 ASCII 문자만 처리할 수 있었다. ASCII 인코딩은 7비트 이진 데이터를 사용하여 총 128개의 문자를 나타낸다. 영어 텍스트를 처리하는 데에는 충분하지만, 이미지나 오디오 같은 이진 데이터를 전송할 때는 문제가 발생한다.
각 시스템이 특정 제어 문자를 다르게 해석할 수 있어, 전송 중 데이터가 손상될 가능성이 있었다. 예를 들어, 일부 시스템은 줄바꿈을 LF(Line Feed)에서 CR(Carriage Return) + LF로 변경할 수 있는데, 이런 동작은 이진 데이터에는 치명적일 수 있다.
- 유닉스/리눅스 시스템: 줄바꿈을 LF(
\n) 하나로 표현 - 윈도우 시스템: 줄바꿈을 CR(
\r) + LF(\n) 두 개로 표현
초기 시스템들은 바이너리 데이터를 인코딩 없이 그대로 전송하려고 했다. 그러나 중간 시스템이 텍스트 전송용으로 설계되어 있었기 때문에, 유닉스 서버에서 윈도우 PC로 파일을 보낼 때, 바이트 값 10(LF)을 발견하면 이를 “줄바꿈”으로 인식하고 자동으로 CR을 붙여 CRLF(\r\n)로 바꾸어 버렸다.
결과적으로 원본 이미지 데이터가
[... 55, 120, 10, 34 ...]전송 중에
[... 55, 120, 13, 10, 34 ...]처럼 변형되어 파일 내용과 크기가 바뀌고, 더 이상 열리지 않거나 깨져 보이게 된다.
즉, 바이트 값 10은 픽셀 값으로 사용되어야 하지만, 시스템은 이를 텍스트로 오인하여 수정해버린 것이다. 이를 방지하기 위해, 데이터를 제어문자가 아닌 안전한 텍스트로 미리 변환하는 방법이 필요했고, 이것이 바로 Base64 인코딩의 등장 배경이다. Base64를 사용하면 임의의 이진 데이터를 안전하게 전송할 수 있다.
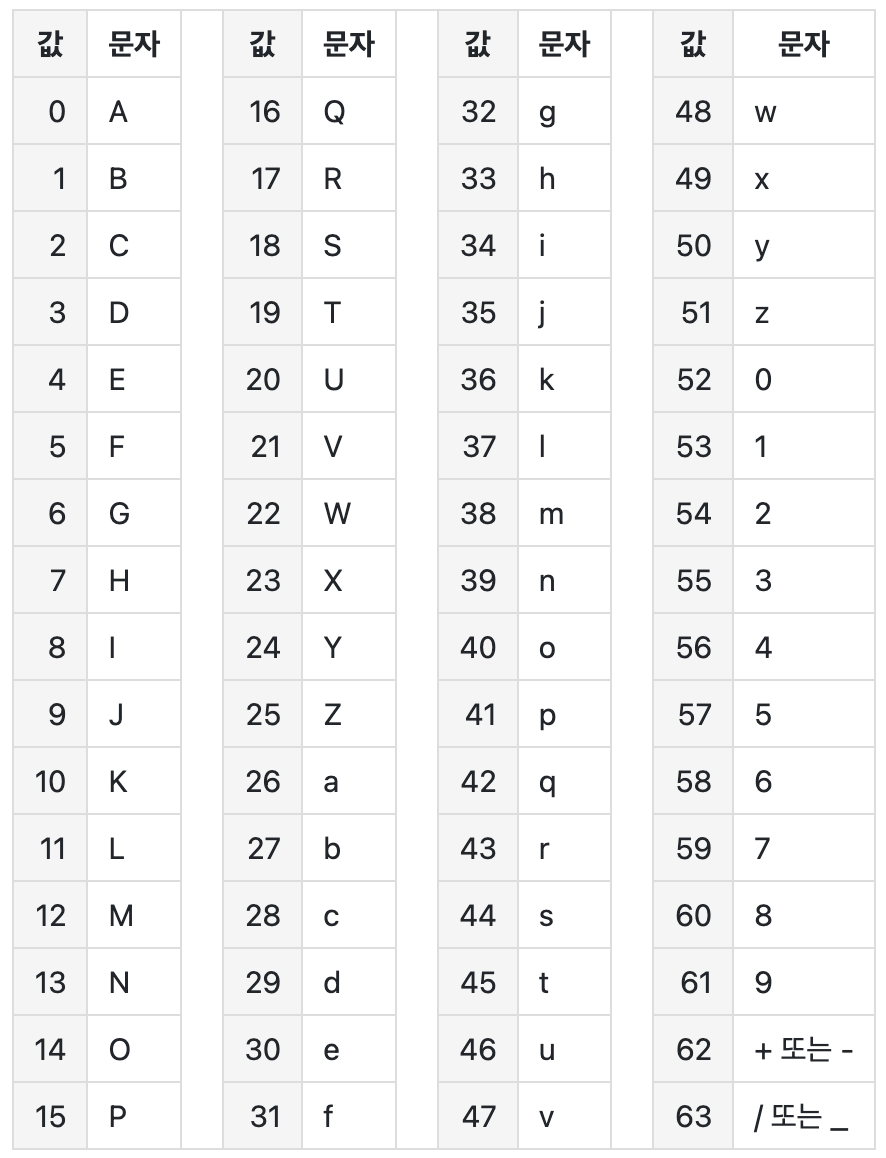
🔎 Base64 변환 표
📌 인코딩 원리
이해를 돕기 위해 텍스트 "Man"을 Base64로 인코딩하는 상황을 예시로 들겠다.
M은 아스키 코드표에서 77에 해당하고, 이는 바이너리 데이터로 01001101이다. 같은 방식으로 a는 97(01100001), n은 110(01101110)이다.
변환 과정은 다음과 같다.
-
우선 일렬로 그대로 나열한다.
010011010110000101101110 -
6비트씩 끊는다. 만일 부족하다면 뒤에 0을 채워 6의 배수를 맞춰준다.
010011 / 010110 / 000101 / 101110 -
이를 Base64 문자표를 활용하여 변환한다. 만일 문자의 개수가 4의 배수가 되지 않는 경우 "="을 채워준다.
-> "TWFu"
"Man"을 Base64를 활용해 인코딩하면 "TWFu"가 된다.
🔎 왜 "="을 채워줘야 할까?
Base64의 핵심 원리는 원본 3바이트(Byte)를 4개의 문자(Character)로 변환하는 것이다. (3 bytes = 24 bits, 4 chars * 6 bits = 24 bits)
디코더(해독기)는 이 4:3 비율을 전제로 설계되어 있기 때문에 문자열의 길이는 4의 배수로 맞춰줘야 한다.
