브라우저의 핵심 기능은 필요한 리소스(HTML, CSS, 자바스크립트, 이미지, 폰트 등의 정적 파일 또는 서버가 동적으로 생성한 데이터)를 서버에 요청하고 서버로부터 응답받은 후 파싱하여 브라우저에 시각적으로 렌더링하는 것이다.
서버에 요청을 전송하기 위해 브라우저는 주소창을 제공한다.
주소창에 naver.com 같은 주소를 입력하게 되면, 브라우저는 이를 다음과 같은 URL로 변환하여 서버에 접속하게 된다.

🔎 URL의 구성
1. scheme(protocol)
URL의 맨 앞에 위치하며, 자원에 어떻게 접근할지를 정의하는 프로토콜 체계이다. 종류로는 http, https 등이 있다. 스킴과 나머지를 구분하기 위하여 :// 구분자를 사용한다.
2. host(FQDN)
host 혹은 FQDN(Fully Qualified Domain Name)은 서브도메인과 Domain Name, 탑레벨 도메인을 포함한 도메인 이름의 전체 경로를 정확히 명시한 것이다.
가장 상위 개념인 탑레인 도메인부터 살펴보자.
1) 탑레벨 도메인(TLD, Top Level Domain)
탑레벨 도메인(최상위 도메인)은 FQDN에서 오른쪽 가장자리 마지막 점 다음에 위치해 있다. 도메인 확장자라고도 알려져 있는 TLD는 웹사이트의 목적, 소유자 또는 지리적 위치와 같은 웹 사이트의 특정 요소를 인식하는 역할을 한다.
예를 들어, .edu라는 최상위 도메인을 사용할 경우 방문자는 해당 웹사이트를 고등 교육 기관의 일종이라고 인식하게 된다. 주소창에 도메인 주소를 입력해 서버에 접속할 때에도, 가장 먼저 해당 도메인 주소의 탑레벨 도메인을 담당하는 DNS 서버를 찾는 과정을 먼저 거치게 된다.
2) 2차 도메인
2차 도메인은 TLD의 바로 왼쪽에 위치하며, naver, google 등 인터넷 상에서 특정 조직, 개인, 회사 등을 대표하는 고유한 이름이다. 탑 레벨 도메인과 2차 도메인을 합친 부분을 도메인 네임(Domain Name)이라고 한다.
3) 서브도메인(Sub Domain)
서브도메인은 호스트명(Host Name)이라고도 불리며, www.naver.com의 www, en.wikipedia.org의 en 등이 이에 해당한다. 예를 들어 홈 네트워크에서 en.wikipedia.org로 접속하고자 할 때, 도메인 네임 부분(wikipedia.org)이 위키피디아 네트워크로 안내해주고, 서브도메인이(en) 정확한 지점으로 안내해주는 역할을 한다.
❓ 서브도메인은 왜 존재하는가?
URL 구성에 대해 알아보면서 의문이 생겼던 부분이 있다. mail.naver.com의 mail, en.wikipedia.org의 en 등은 도메인 네임 뒤쪽의 경로(path)에 있어도 될 것 같은데, 왜 앞쪽에 도메인으로서 함께 위치하는 것일까? 찾으면서 알게 된 내용들은 다음과 같다.
1. 서비스 분리가 용이하다.
mail.example.com은 DNS 설정으로 아예 다른 서버에 연결할 수 있지만, example.com/mail은 항상 같은 서버에 요청이 들어오고, 내부 로직에서 라우팅해야 한다.
2. 쿠키와 보안 정책 분리가 용이하다.
서브도메인별로 쿠키, CSP, HSTS, 인증서 등을 따로 적용할 수 있다. 하지만 /mail과 /user처럼 같은 도메인에서는 쿠키나 보안 설정을 분리하기가 어렵다.
3. 독립적인 배포가 가능하다.
서브도메인이 다르면 독립 배포, 독립 개발, 독립 서버 관리가 가능하지만, 경로만 다른 경우에는 기존 서버에 통합 개발/배포해야 한다.
이 도메인을 통해 DNS 서버에서 IP 주소와 포트 번호를 받아 서버에 접속할 수 있다.
3. Port
포트는 컴퓨터 내에서 네트워크 통신을 구분하는 논리적 구획 번호이다. 즉, 하나의 IP 주소 안에서 여러 개의 서비스를 구분하기 위해 사용된다.
회사로 비유하자면, 어떤 회사 건물(IP 주소)에
80번 방에서는 웹 서버 (http)
22번 방에서는 SSH 서버 (터미널 접속)
443번 방에서는 보안 웹 서버 (https)
이렇게 다양한 업무를 하고 있는 것이다.
고객이 회사를 찾아와도
몇 번 방(=포트)으로 갈 건지 알려줘야
각 부서가 제대로 응답할 수 있다.
사용할 수 있는 0 ~ 65,535의 포트 중 0 ~ 1023번까지의 포트 번호는 주요 통신을 위한 규약에 따라 이미 정해져 있다. 이를 잘 알려진 포트(well-known port)라고 한다.
대표적인 well-known port들은 다음과 같다.
- 포트 22: SSH 접속을 위한 포트
- 포트 80: HTTP 프로토콜을 사용하는 웹 서비스
- 포트 443: HTTPS 프로토콜을 사용하는 웹 서비스
4. Path
서버 내에서 특정 리소스(파일, 페이지, API 등)를 가리키는 위치 정보이다. 일반적으로 포트 번호 다음부터 파일 이름까지를 Path로 본다.
path에 파일명을 쓰지 않으면 어느 파일에 액세스해야 할지 모른다.
이럴 경우 보통, 대부분의 서버가 /dir/index.html, /dir/default.html로 설정해둔다
5. Query(Query String)
경로 다음에 위치하는 쿼리는 서버에 추가 정보를 전달하는 역할을 한다. 경로와 ?문자로 구분되며, 같은 쿼리 내에서 파라미터 사이는 &로 구분한다.
6. Fragment
Fragment는 URL에서 마지막에 위치하며, # 기호 뒤에 오는 부분을 말한다.
페이지 내에서 특정 위치(섹션, 앵커)를 가리키기 위한 식별자이다. html 태그의 id가 Fragment로 사용된다.
🔎 URL, URN, URI
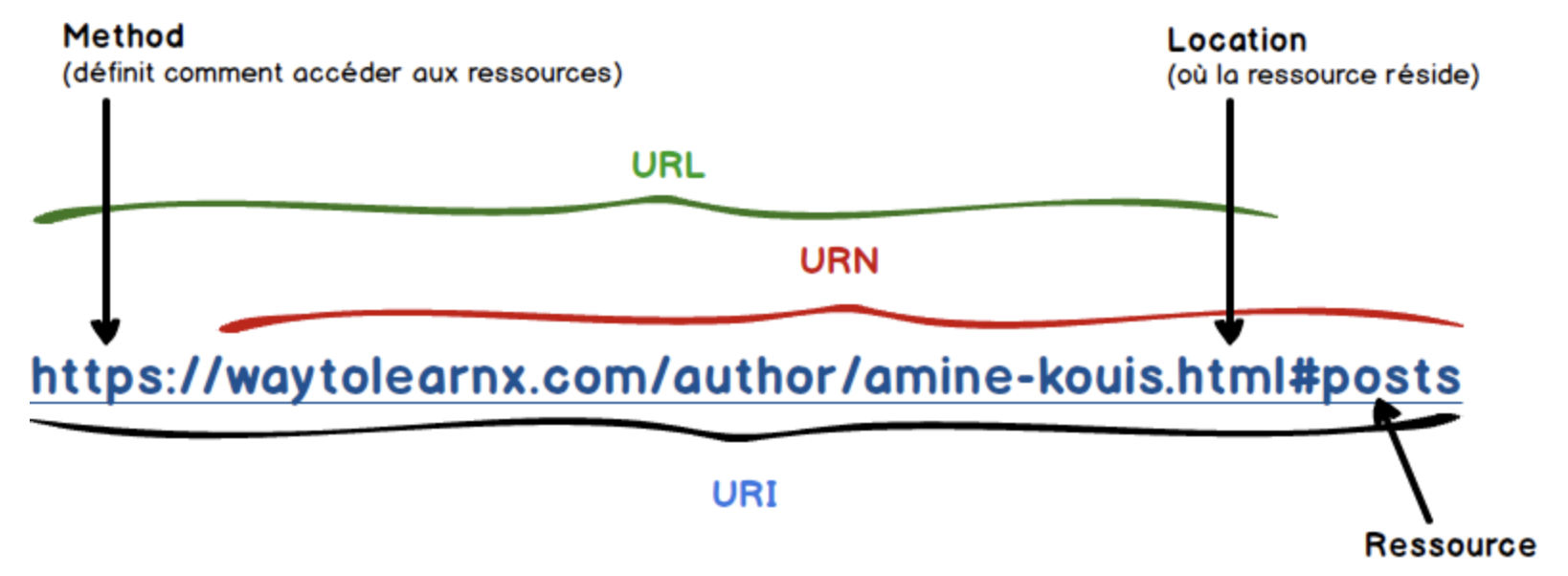
1. URL(Uniform Resource Locator)
자원의 위치를 식별하기 위한 방법이다.
보통 맨 처음 protocol부터 path까지를 URL로 정의한다.
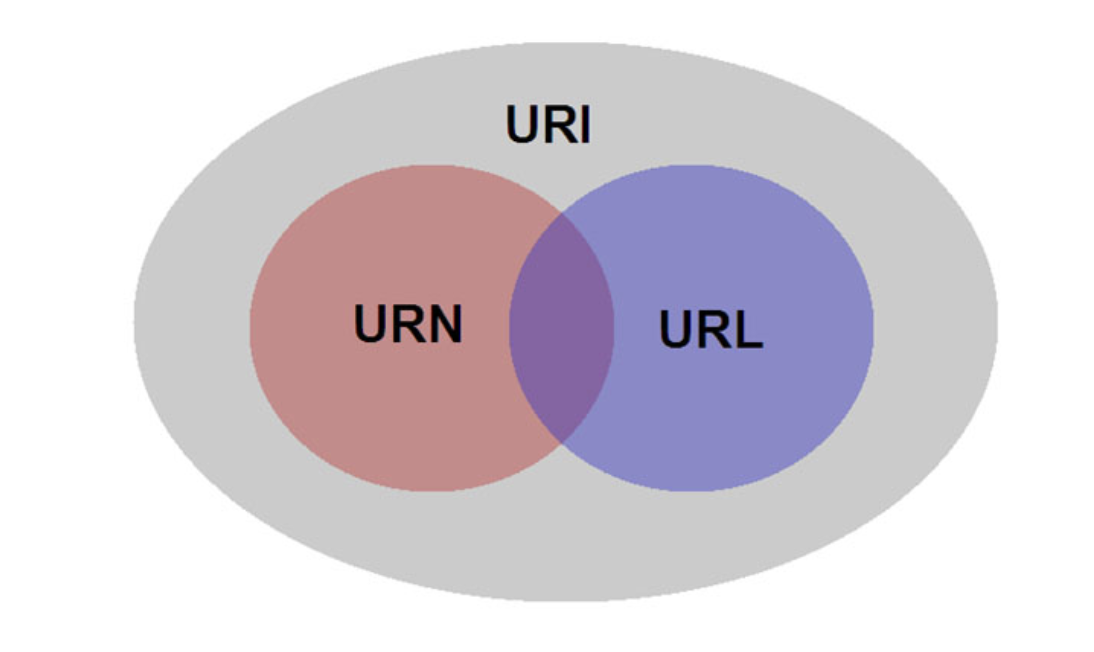
2. URI(Uniform Resource Identifier)
자원 그 자체를 식별하기 위한 방법이다. URL에 쿼리를 포함한 식별자가 더해지면 URI가 된다.
예를들어 다음과 같은 홈페이지 링크가 있다고 하자.
http://www.naver.com/index.html?page=1232950&id=776
http://www.naver.com/서버에 위치한index.html페이지는 query string인page의 값에 따라 여러가지 화면 결과를 나타나게 된다.
이때 여기서 URL은index.html의 위치를 표기한http://www.naver.com/index.html까지이다.
하지만 사용자가 원하는 정보에 도달 하기위해서는?page=1232950&id=776라는 식별자(Identifier)가 필요한 것이다.
따라서 엄격히 구분하자면 위의http://www.naver.com/index.html?page=1232950&id=776주소는 URI이고
, 식별자가 빠진http://www.naver.com/index.html를 URL이라고 하는 것이다.
이유는 URL은 자원의 위치를 나타내 주는 것이고 URI는 자원의 식별자인데,?page=1232950&id=776이 부분은 위치를 나타내는 것이 아니라 page값이 1232950이고 id가 776인 것을 나타내는 식별하는 부분이기 때문이다.
물론 통상적으로 대충 URL이라고 얘기를 하지만 엄격하게는 URI라고 하는 것이 맞다.
3. URN(Uniform Resource Name)
자원에 이름(Name)을 부여하기 위한 URI의 한 종류이다.
urn:isbn:9783161484100의 형태이며,
영속적이고 위치에 독립적인 자원을 위한 지시자로 사용하기 위해 1997년도 RFC 2141 문서에서 정의되었다.
하지만 리소스가 이름에 매핑되어 있어야 하기 때문에 이름으로 부여하면 거의 찾기가 힘들다. 그래서 대부분 URL만 쓴다.
URN도 자원 그 자체를 식별하기 위한 식별자이기 때문에 URI에 포함된다.
출처
https://inpa.tistory.com/entry/WEB-%F0%9F%8C%90-URL-URI-%EC%B0%A8%EC%9D%B4
https://blog.logto.io/ko/unveiling-uri-url-and-urn
