2025, '나'에 대해 생각해봤던 시기
지난해는 "개발자로서 어떻게 학습해야 하는가"에 대해 끊임없이 질문을 던졌던 시기였다. 시중에는 수많은 학습 수단이 존재하지만, 결국 핵심은 나에게 맞는 공부 방법을 찾는 것이라고 판단했기 때문이다. 이를 위해 나는 내가 어떤 사람인지, 어떤 환경에서 몰입도가 극대화되는지, 그리고 보완해야 할 점은 무엇인지에 대해 깊이 있게 생각해보는 시간을 가졌다.
가장 먼저 내가 집중할 수 있는 환경을 객관화해보았다. 과거를 복기해보면, 나는 집보다는 외부 환경을 선호하며, 폐쇄적인 독서실 형태보다는 타인의 시선이 느껴지는 탁 트인 개방형 공간에서 학습 효율이 훨씬 높았다.
하지만 이러한 환경에서 몰입하다가도, 귀가 후에는 편안함에 취해 시간을 허비하곤 했다. 문득 《아주 작은 습관의 힘(Atomic Habits)》에서 읽었던 "유혹은 인내하는 것이 아니라 환경에서 차단하는 것"이며, "새로운 행동을 정착시키려면 기존의 필수적인 루틴과 결합해야 한다"는 내용이 떠올랐다. 이를 적용해 귀가하자마자 휴대폰을 시야에서 보이지 않는 곳에 두는 규칙을 세웠다. 또한 근처의 모든 학습 공간을 직접 경험해본 끝에 나에게 가장 잘 맞는 장소를 찾아냈다. 이렇게 집중할 수 있는 '환경'과 그 환경으로 나갈 수밖에 없는 '루틴'을 결합하자, 생산성은 이전과 비교할 수 없을 정도로 향상되었다. 단순히 효율이 좋아진 것을 넘어, 스스로 부족함을 인지하고 이를 개선할 시스템을 설계할 수 있다는 자신감을 얻었다.
학습 수단을 결정하는 과정에서도 나만의 기준을 세웠다. 부트캠프는 커뮤니티와 협업 경험, 체계적인 커리큘럼이라는 분명한 장점이 있다. 하지만 나는 모르는 개념을 대충 넘기지 못하고 끝까지 파고들어야 직성이 풀리는 성향이기에, 정해진 일정에 맞춰 방대한 지식을 습득해야 하는 방식은 나에게 맞지 않는다고 느꼈다. 대기업 주관의 우수한 프로그램도 존재하지만, 이를 준비하는 시간보다 직접 프로젝트를 수행하며 부딪히는 과정이 실력 향상에 더 효율적일 것이라 판단했다. 스스로 강제성을 부여하고 학습을 지속할 수 있다는 확신이 있었기에, 외부의 틀에 의존하기보다 독학을 통한 깊이 있는 학습을 선택했다.
또한 나는 흥미로운 주제를 발견하면 다른 일에 한눈팔지 않고 해당 분야를 끝까지 파고드는 성향이 있다. 이러한 몰입의 에너지를 꾸준한 열정으로 치환하기 위해서는 내가 진심으로 좋아하는 도메인을 다뤄야 한다고 생각했다. 고민 끝에, 나의 관심사와 맞닿아 있는 주제를 선정해 프로젝트를 진행하기로 했다.
ClassicHub
https://classic-hub.vercel.app/
1) 배경
나는 클래식 음악을 좋아하고, 공연을 보러 다니는 것을 좋아한다. 인터파크, 티켓링크와 같은 대형 예매 사이트에서는 다양한 장르를 한눈에 볼 수 있다는 장점이 있지만, 클래식 공연 정보만을 정교하게 필터링해서 확인하기에는 한계가 있었다. 특히 클래식 공연의 경우 기획사에 따라 예매처가 여러 곳으로 나뉘어 있는 경우가 많아, 특정 공연의 정보를 얻기 위해 여러 사이트를 전전해야 하는 문제가 있었다.
무엇보다 클래식 애호가들에게 가장 중요한 정보는 '누가 연주하는가'만큼이나 '어떤 곡을 연주하는가'이다. 기존 플랫폼들은 공연명이나 아티스트명 기반의 검색만 지원할 뿐, 특정 작품명으로 공연을 검색하는 기능은 부재했다.
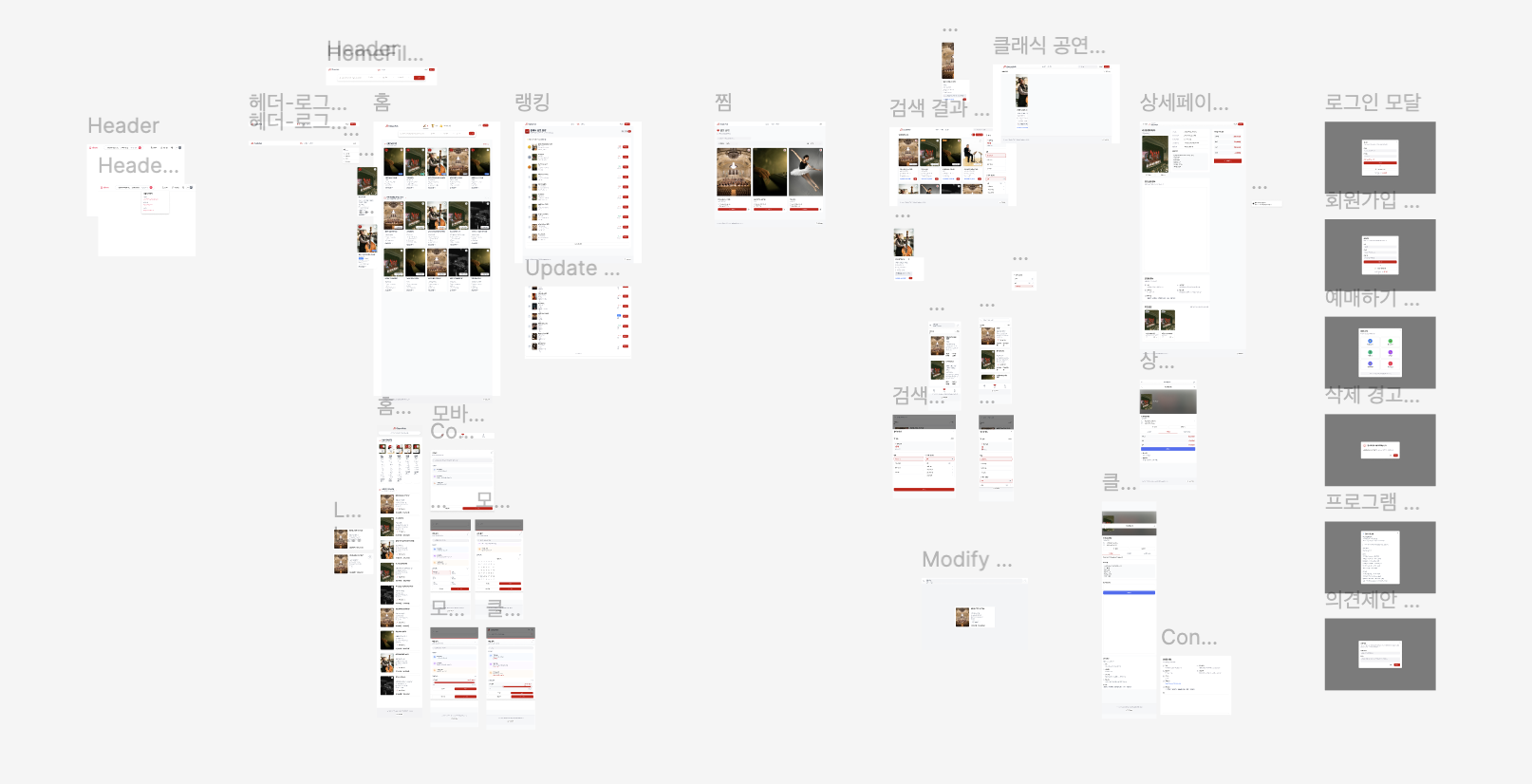
기획, 개발, 배포의 전 과정을 스스로 수행해 본 경험은 결코 쉽지 않았지만, 개발 프로세스의 전체 메커니즘을 이해하는 유익한 시간이었다.
2) 기획 & 디자인
기획 단계에서는 세부 사양을 명확히 확정하지 않은 채 구현에 들어갔던 점이 가장 큰 학습 포인트였다. 개발 도중 다시 기획 단계로 돌아가 설계를 수정해야 하는 상황이 반복되면서, 기획의 난도를 실감했다. 물론 모든 것을 완벽히 정의하고 시작할 수는 없겠지만, 개발 효율을 높이기 위해서는 가능한 세밀한 부분까지 사전에 설계하는 과정이 필수적이라는 것을 체감했다.
학업과 병행하며 컴포넌트 구현에만 약 두 달에 가까운 시간을 투자했다. 주변 동기들에 비해 시작이 늦었다는 생각에 마음 한편에는 늘 조급함이 있었고, UI 구현보다는 더 깊이 있는 기술적 난제들을 빠르게 해결하고 싶다는 욕심이 컸다. 하지만 지금 돌이켜보면, 복잡한 UX 요구사항과 컴포넌트들을 라이브러리 없이 밑바닥부터 직접 구현하는 과정을 통해 어떤 컴포넌트가 좋은 컴포넌트인지에 대해 깊이있게 생각해볼 수 있었고, 모든 코드를 이해하고 있었기 때문에 추후 리팩토링도 빠르게 할 수 있었다.
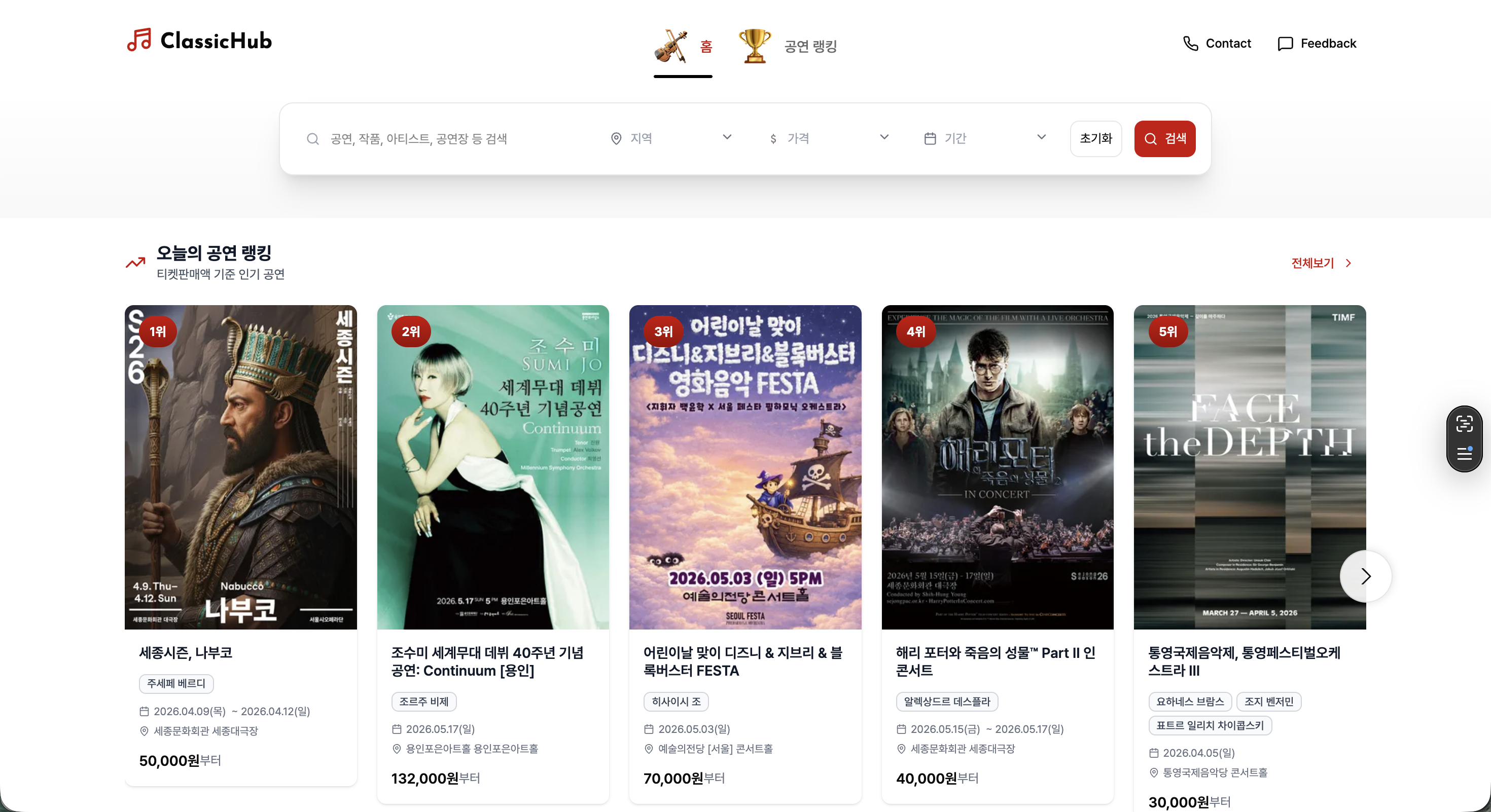
심미적으로 훌륭하면서도 사용자 중심적인 디자인을 구현하고 싶어 고민이 많았지만, 스스로의 디자인적 한계를 마주하기도 했다. 특히 필터 UI를 구현할 때 에어비앤비(Airbnb)의 사례를 벤치마킹했는데, 단순히 모방하기보다 나만의 방식을 고집하며 AI와 씨름하기도 했다. 결과적으로는 본질적인 디자인 원리, 즉 레퍼런스의 마진과 패딩 값을 정교하게 분석하여 적용했을 때 비로소 완성도 있는 결과물이 나왔다. 이를 통해 디자인 퀄리티를 유지하면서도 개발자의 정신건강(?)과 생산성을 챙기기 위해서는, 검증된 레퍼런스를 적극 활용하고 개발자는 본연의 기술적 문제 해결에 집중력을 쏟는 것이 더 현명한 전략임을 깨달았다.
3) ETL 파이프라인 구축
이미지로부터 구조화된 데이터 추출하기
서비스의 근간이 되는 데이터를 저장하기 위한 파이프라인을 구축하는 게 가장 힘들었다. 공연예술통합전산망(KOPIS)의 api를 활용하는데, 연주곡에 대한 데이터는 대부분의 공연이 상세 이미지로만 제공하며 정형화된 텍스트 데이터로 제공하지 않는다. 결국 사용자가 작품명을 통해 검색 및 필터링을 하기 위해서는 이미지에 있는 데이터를 구조화된 정적 데이터로 바꿔주는 작업이 필요했다.
초기에는 Gemini API의 멀티모달 능력을 활용해 이미지를 직접 인식시키는 방식을 시도했다. 하지만 프롬프트를 아무리 정교하게 수정해도 이미지에 없는 내용을 지어내거나 데이터가 누락되는 할루시네이션(Hallucination)을 완전히 배제하기 어려웠다.
원인을 분석해본 결과, 멀티모달 모델이 이미지 인식과 데이터 추론을 동시에 수행할 때 정확도가 분산될 수 있다는 점에 주목했다. 따라서 전용 OCR 엔진을 통해 이미지 속 텍스트를 먼저 추출하고, 정제된 텍스트를 Gemini API에 입력하여 모델이 '데이터 구조화'라는 추론 작업에만 집중하게 한다면 정확도를 높일 수 있을 것이라 판단했다.
이를 검증하기 위해 Tesseract, GLM-OCR, Google Cloud Vision API 등 다양한 도구를 벤치마킹했다. 그 중 Google Cloud Vision API가 방대한 학습 데이터를 바탕으로 이미지 내 텍스트를 압도적인 정확도로 복원해냈고, 이를 Gemini API와 연동함으로써 최종적으로 의도했던 정교한 구조적 데이터를 얻을 수 있었다.
에러 처리
KOPIS 데이터 페칭부터 Google Cloud Vision API, Gemini API, 그리고 Supabase 저장에 이르기까지 여러 단계의 데이터 파이프라인을 거치기 때문에, 각 접점에서의 예외 처리를 견고하게 설계하는 것이 중요했고, 가장 힘든 부분이기도 했다.
일례로 Google Cloud Vision API의 경우, 입력 이미지의 해상도가 특정 임계치를 초과하면 Bad Image Data 에러가 발생한다. 공연 상세 페이지는 아래와 같이 세로로 매우 긴 원본 이미지가 많아 API 제한 사항을 초과하게 된다.
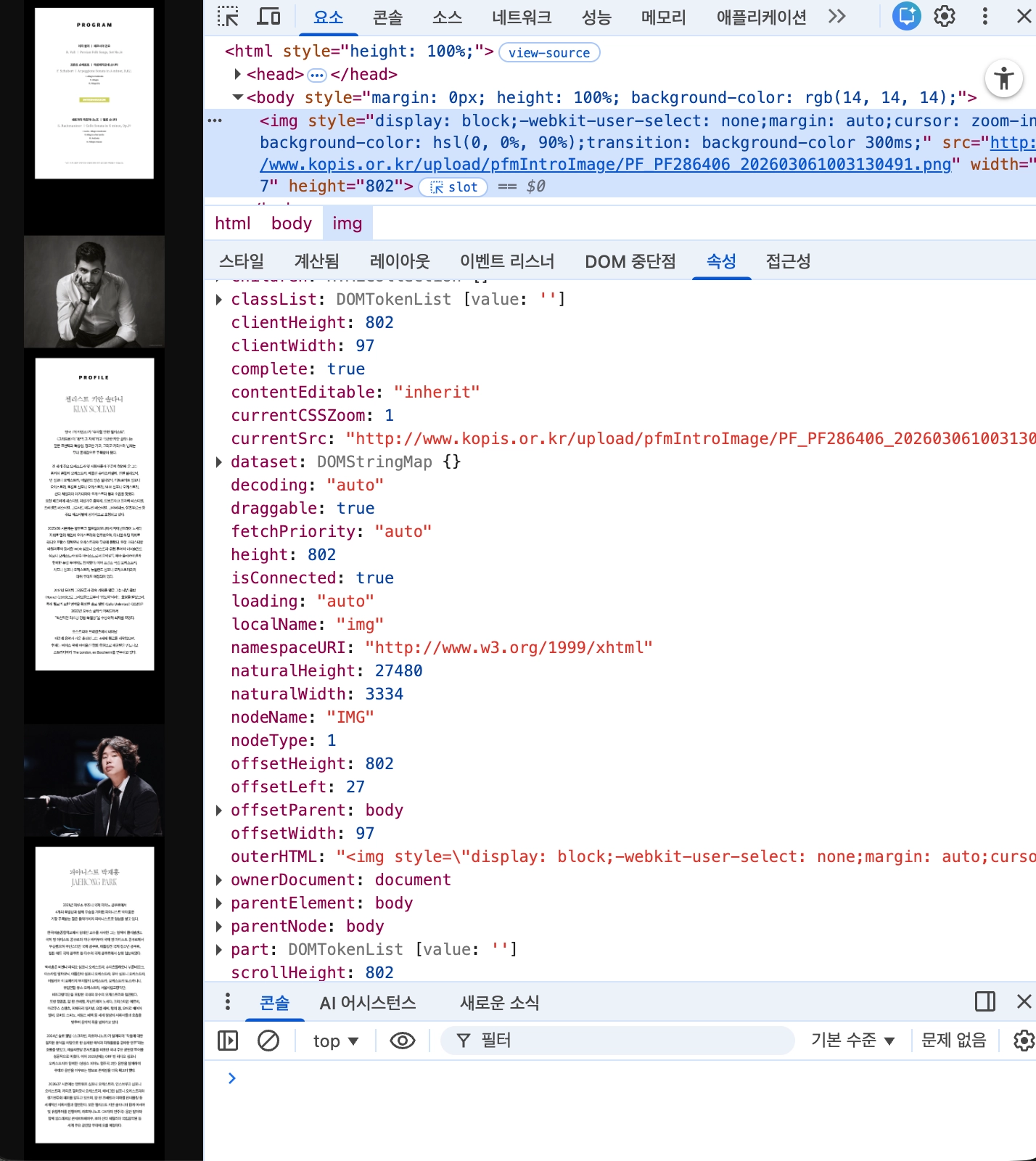
이를 해결하기 위해 sharp 라이브러리를 활용해 이미지를 적절한 크기로 분할하여 입력하는 로직을 구현했다. 이때 단순히 등분하는 것이 아니라, 분할 지점에서 글자가 잘려 인식률이 저하되는 것을 방지하기 위해 일정 수준의 overlap 구간을 설정하는 세밀한 처리가 필요했다.
import { withErrorHandling } from "@/shared/utils/error";
import sharp from "sharp";
/**
* 이미지가 70M 픽셀을 초과하면 세로로 자른다.
*/
export const splitLongImage = async (buffer: Buffer): Promise<Buffer[]> => {
return withErrorHandling(
async () => {
const image = sharp(buffer);
const { width, height } = await image.metadata();
// 이미지 파일이 잘못된 형식일 경우 metadata()는 width와 height를 undefined로 반환
// 이 경우 buffer를 그대로 반환
if (!width || !height) return [buffer];
// Google Cloud Vision API의 제한 픽셀 수
const MAX_PIXELS = 70_000_000;
const totalPixels = width * height;
if (totalPixels <= MAX_PIXELS) {
return [buffer];
}
// 한 청크당 최대 높이 계산
const maxChunkHeight = Math.floor(MAX_PIXELS / width);
// 글자가 잘리는 것을 고려하여 중첩될 높이 (글자 크기를 고려해 400~500px)
const OVERLAP_HEIGHT = Math.min(500, Math.floor(maxChunkHeight * 0.2));
const chunks: Buffer[] = [];
let currentTop = 0; // 현재 자를 조각의 시작점
while (currentTop < height) {
// 1. 남은 높이가 한 조각 크기보다 작으면 마지막 조각 처리
let chunkHeight = Math.min(maxChunkHeight, height - currentTop);
const chunkBuffer = await image
.extract({
left: 0,
top: currentTop,
width: width,
height: chunkHeight,
})
.toBuffer();
chunks.push(chunkBuffer);
// 2. 다음 시작 지점 계산
currentTop += chunkHeight;
// 마지막 조각이 아니었다면, 중첩을 위해 OVERLAP_HEIGHT만큼 뒤로 후퇴
if (currentTop < height) {
currentTop -= OVERLAP_HEIGHT;
}
}
return chunks;
},
null,
"sharp",
);
};이외에도 EXIF 회전 정보에 따른 메타데이터 불일치, Gemini API의 모델 과부하(Rate Limit) 및 할루시네이션으로 인한 스키마 위반, 그리고 단계별 네트워크 통신 등 수많은 잠재적 에러 요소가 존재한다. 이런 환경에서 어떻게 에러를 정의하고 관리할 것인가에 대해 깊이 고민하게 되었다.
기존에는 다음과 같이 try catch 문에서 에러를 console.log로만 기록하고 null을 반환하여 에러가 묵살되는 패턴을 반복했었다.
catch (error) {
console.log("KOPIS API로 공연 데이터 받아오기 실패", error);
return null; // 에러 상황인데도 실행이 계속됨
}하지만 수만 개의 로그가 쏟아지는 서버 환경에서 console.log는 묻히기 쉽고, 보통의 에러 모니터링 도구가 예외를 감지하지 못해 실제로 문제가 발생했을 때 에러를 추적하거나 대응하기가 어려워질 수 있다.
이를 개선하기 위해 다음과 같은 중앙화된 에러 핸들러를 활용하여, 에러 전파와 로깅 구조를 표준화했다.
async function withErrorHandling<T>(
operation: () => Promise<T>,
fallback?: T
): Promise<T> {
try {
return await operation();
} catch (error) {
logger.error('Operation failed', { error, stack: error.stack });
if (fallback !== undefined) {
return fallback;
}
throw error;
}
}이제 도메인 로직상 일부 데이터가 없더라도 프로세스가 유지되어야 하는 지점에는 fallback을 명시하고, 정확한 데이터가 필수적인 핵심 구간에서는 에러를 throw 하여 상위에서 명확히 인지하도록 설계함으로써 디버깅 비용을 획기적으로 줄일 수 있었다.
크론잡 런타임 개선 여지
현재는 매일 자정 크론잡을 통해 데이터를 수집·가공하여 DB에 적재하는 방식을 사용하고 있다. 하지만 데이터 양이 늘어남에 따라 전체 실행 시간을 어떻게 단축할 것인가에 대한 고민이 깊어졌다. 특히 외부 API의 호출 간격 제한이 존재하기 때문에, 단순히 하드웨어 리소스를 늘리거나 네트워크 속도를 높이는 것보다 파이프라인 로직 자체를 최적화하는 것이 본질적인 해결책이라고 판단했다.
현재 구조는 processPerformance라는 가공(Transform) 함수 내부에서 개별 공연의 상세 데이터를 하나씩 가져오며 이를 하나의 트랜잭션으로 처리하고 있다. 이 구조를 개선하여 상세 데이터 페칭 로직을 추출(Extract) 단계로 전진 배치하고, ETL(Extract, Transform, Load) 과정을 각각 독립적인 프로세스로 분리한다면, 가공(Transform) 단계에서 Google Cloud Vision과 Gemini API의 배치 처리 기능을 적극적으로 활용할 수 있게 된다. 결과적으로 순차 처리 방식에서 발생하는 오버헤드를 줄여 크론잡 런타임을 획기적으로 단축할 수 있을 것 같다.
export const processPerformance = async (
id: string,
): Promise<ProcessResult> => {
logger.info("Fetching Performance...");
// 상세 데이터를 가져오는 작업을 트랜잭션에 포함시킴
const performanceDetail = await getPerformanceDetail(id);
if (!performanceDetail) {
logger.error("[FETCH_FAIL] Performance fetch failed");
return {
id,
error: "PerformanceFetchError",
data: null,
};
}모니터링
에러를 인지하는 것만큼이나, "실패한 데이터를 어떻게 복구할 것인가"에 대한 전략도 중요했다. 외부 API(KOPIS, Vision, Gemini) 의존도가 높은 프로젝트 특성상, 일시적인 네트워크 불안정이나 서버 과부하로 인한 실패는 단순 재시도만으로도 해결될 수 있기 때문이다.
이를 위해 지수적 백오프(Exponential Backoff) 로직을 구현했다. 실패가 발생하면 즉시 재시도하는 것이 아니라 2 -> 4 -> 8 -> 16분으로 간격을 점진적으로 늘려가며 재시도하도록 설계했다. 이는 실패한 대상 서버에 가해지는 부담을 줄이면서도, 복구 가능성이 높은 시점에 다시 요청을 보낼 수 있게 하여 파이프라인의 회복 탄력성을 높여주었다.
또한, 모니터링 시스템의 효율성도 개선했다. 기존에는 작업의 성공 여부와 상관없이 모든 로그를 슬랙(Slack)으로 전송했는데, 다음과 같은 문제점이 있었다.
- 로그 노이즈: 성공 로그가 쏟아지면서 정작 중요한 에러 로그를 놓치게 됨
- 채널 가독성 저하: 불필요한 메시지로 에러 추적 효율이 떨어짐
이를 해결하기 위해 성공 로그는 내부 DB나 로그 파일에만 기록하고, 설정한 재시도 횟수가 모두 소진되었음에도 최종적으로 실패한 데이터에 대해서만 슬랙 알림을 보내도록 시스템을 구축했다.
테스트
새로운 기능을 배포하기 전, 운영 DB가 아닌 로컬 환경에서 테스트하는 것은 안전한 개발을 위한 필수 과정이다. 하지만 이 과정에서 클라우드와 로컬 환경의 데이터 스키마가 동기화되지 않아 발생하는 수많은 시행착오를 겪으며, '환경 간 정합성'의 중요성을 깨닫게 되었다.
1. 환경 격차(Environmental Drift)의 위험성
- 로컬에서 성공적으로 동작하던 RPC나 쿼리가 클라우드 환경에서 실패하는 원인은 대부분 스키마의 불일치에 있었다. 로컬에서만 수정하고 클라우드에 반영하지 않거나, 반대로 클라우드 설정을 로컬에 가져오지 않을 때 발생하는 환경 격차는 디버깅 시간을 불필요하게 늘리는 주범이었다.
2. 마이그레이션 파일의 중앙 관리 (Single Source of Truth)
- 이 문제를 해결하기 위해서는 마이그레이션 파일을 파편화된 상태로 두지 않고, 로컬 한 곳에서 체계적으로 관리하는 시스템이 반드시 필요함을 알게 되었다.
- 모든 스키마 변경 사항을 마이그레이션 파일로 기록하고 버전 관리를 수행함으로써, 어떤 환경에서도 동일한 DB 상태를 재현할 수 있는 기반을 마련했다.
3. 동일한 테스트 환경 구축의 필요성
- 가장 중요한 깨달음은 테스트는 클라우드와 완전히 동일한(Mirroring) 로컬 환경에서 이루어져야 한다는 점이었다. 마이그레이션을 통해 로컬 환경을 프로덕션과 100% 동기화한 후 테스트를 진행했을 때 비로소 배포 시의 불확실성을 제거할 수 있었다. 이는 단순히 코드를 잘 짜는 것을 넘어, 안정적인 서비스를 운영하기 위한 인프라 관리 역량의 핵심임을 배웠다.
프론트엔드 친화적인 데이터 저장 방식
데이터 가공의 전체 파이프라인을 직접 구축해 보며, 백엔드에서 전달하는 데이터의 형태가 프론트엔드의 개발 편의성과 성능에 큰 영향을 미친다는 것을 알게 되었다.
1. 데이터 구조의 평탄화
- 객체가 지나치게 깊게 중첩된 구조는 지양해야 함을 깨달았다. 계층 구조가 깊어질수록 특정 데이터에 접근하기 위한 코드가 복잡해지며, 상태 관리 도구(Zustand, React Query 등)에서 데이터 변경을 감지할 때 불필요한 리렌더링을 유발할 가능성이 커진다. 따라서 가능한 평탄한 구조로 데이터를 설계하여 접근성을 높이고, 렌더링 성능을 최적화해야 한다.
2. 데이터가 없는 경우에 대한 명확한 컨벤션 확립
- 특정 필드에 값이 없을 때 처리하는 방식은 코드의 안정성과 직결된다는 것을 깨달았다. 백엔드에서 null을 보낼지, 아예 키(Key)를 제외하여 undefined로 처리할지에 대한 명확한 규칙이 없으면, 프론트엔드 곳곳에 '방어용 조건문'이 남발되어 가독성이 떨어지고 런타임 에러의 위험이 커진다. 일관된 데이터 규약을 확립하는 것이 필수적이다.
- 상황에 따라 다르겠지만 에러 발생 가능성을 줄이기 위해 null보다는 빈 배열(
[])이나 빈 문자열("")처럼 해당 데이터의 타입을 유지한 채로 전달하는 것이 프론트엔드 로직을 훨씬 간결하게 만든다는 점을 배웠다.
느낀점
-
프론트엔드 개발자라는 명확한 목표가 있었기에, DB 스키마와 마이그레이션, ETL 파이프라인 같은 백엔드 인프라 영역에서 겪는 시행착오들이 때로는 돌아가는 길처럼 느껴지기도 했고, "지금 내가 왜 이걸 붙잡고 있지?"라는 의구심이 들 때도 있었다. 하지만 데이터 가공의 시작점부터 최종 렌더링에 이르는 전체 파이프라인을 직접 설계하고 구현해 본 경험은 분명 나에게 도움이 되었다. 데이터가 어떤 고통을 거쳐 프론트엔드로 전달되는지 이해하게 되었고, 각 계층에서의 좋은 선택인지 무엇인지 판단할 수 있는 시야가 생긴 것 같다.
-
빠른 실행의 중요성을 깨닫게 되었다. "Make it work, make it right, make it fast"라는 말도 있더라. 내 단점이 구현 단계부터 너무 많은 예외사항들을 생각하다보니 생각의 흐름이 멈추고 일이 진전이 잘 안된다는 것이었는데, 아무리 더러운(?) 코드라도 우선은 죽이되든 밥이되든 최소한 돌아가는 형태로 구현부터 해보고 개선하는 게 훨씬 생산적이고 효율적인 방법이라는 것을 깨달았다.
-
이러한 변화는 프로젝트 범위 설정에도 영향을 미쳤다. 초기에는 로그인부터 찜하기 기능까지 모든 기능을 담으려고 욕심을 냈지만 역부족이었다. 결국 서비스의 본질에 집중한 MVP형태로 우선 배포하기로 결정했다. 완벽하게 준비해서 출시하기보다, 일단 세상에 내놓고 운영하며 배우는 과정이 성장에 더 도움이 되는 방향이 아닐까?
목표
-
기능을 구현하다 의문이 생기면 위와 같이 노션에 별도로 기록하며 트래킹하곤 한다. 이전에는 이러한 의문점이나 모호했던 개념들을 해결하기 위해 학습하는 날을 따로 정해두곤 했는데, 내가 스스로 정한 데드라인에 임박해서는 구현에 급급했던 것 같다. 여기 적혀 있는 것들을 해결하는 것이 목표이다.

-
의문점을 해결하는 과정에서 가장 중요하게 생각하는 것은 스스로 이해한 바를 명확한 언어로 인출하는 것이다. 향후 현업에서 누군가를 설득하거나, 기술적 배경이 없는 이들에게 복잡한 개념을 설명해야 할 때 커뮤니케이션 역량은 필수적이라고 생각한다. 모호한 개념을 뭉뚱그려 넘기지 않고, 명확하게 말로 표현할 수 있을 때까지 논리를 다듬는 연습을 지속하려 한다.
-
명확한 언어로의 표현하기 위해서는, 그 기술에 대한 명확한 이해가 필요하다고 생각한다. 사실 지금까지는 궁금한 부분에 대해 구글링을 하거나 ai한테 물어보는 방식으로 지식을 얻곤 했었는데, 뭔가 마음속 깊이 와닿지 않은 느낌이 항상 있어서 극단적인 방법이 필요하다고 생각했다. 이번에는 궁금하거나 이해하고 싶은 기술에 대해 전체는 아니더라도 핵심 로직을 바닐라 자바스크립트를 통해 직접 구현해보며 기술에 대한 깊이와 이해도를 높이는 것이 목표이다.
