
🐥 들어가며
프로젝트를 하면서 다대일 관계 테이블에 있어 만나는 에러들이 어느정도 정해져있는 것 같은데.. 매번 순간에는 다 이해했다고 생각해도 그게 아니더라 .. 그래서 이렇게 적어두려고 한다.. ㅎㅎ
순환참조부터 시작해 n+1 문제, jpa의 lazy loading, 마지막으로는 fetch join까지 정리합시다 !
0️⃣ 구조 설명
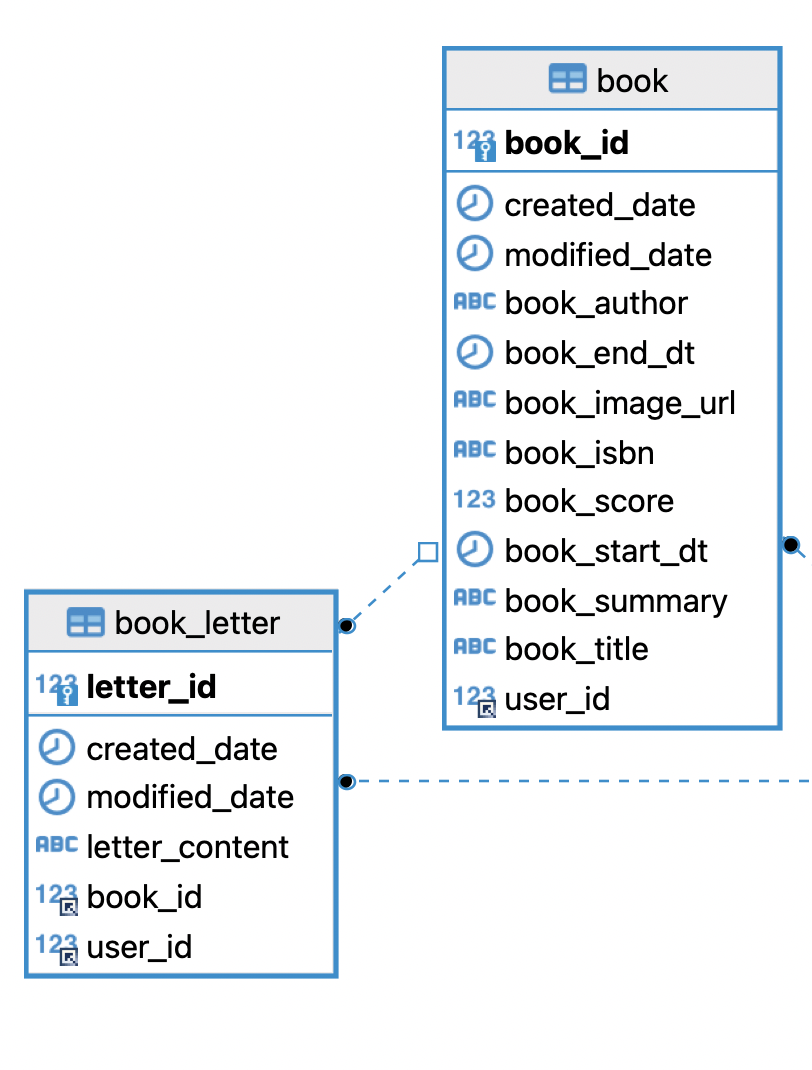
(1) 테이블 관계도
살펴볼 엔티티들의 테이블 관계는 아래와 같다.
book(1)book_letter(n)
두 테이블이 있으며, 다대일 관계를 맺는다.
코드로는 다음과 같다.
Book
class Book {
,,, //나머지 컬럼 생략
@OneToMany(mappedBy = "book")
private List<BookLetter> bookLetterList=new ArrayList<>(); //fk - 글귀
,,,
}BookLetter
class BookLetter {
,,, //나머지 컬럼 생략
@JoinColumn(name = "bookId")
@ManyToOne
@OnDelete(action = OnDeleteAction.CASCADE)
private Book book;
,,,
}(2) 호출 구조
이제 book 과 book_letter 테이블에 대해 조회 쿼리를 요청해보려고 한다.
정확히는 book_letter 테이블을 조회해 book_letter 리스트를 반환받고자 한다.
코드상의 호출 구조는 다음과 같다. ( controller -> service )
- BookLetterController
 서비스단의
서비스단의 getBookLettersByUser()를 호출, List< BookLetter > 를 반환받는다.
- BookLetterService
 서비스단에서는 간단히 SpringDataJpa 가 제공하는 쿼리를 이용해
서비스단에서는 간단히 SpringDataJpa 가 제공하는 쿼리를 이용해 findBookLettersByUser()를 호출하도록 했다.
이제 기본적인 리스트 조회 결과부터 하나씩 확인해보자.
1️⃣ 단순 조회 : 순환 참조 문제
위에서 설명한 코드의 변경 없이 그대로 api 를 요청해보자.
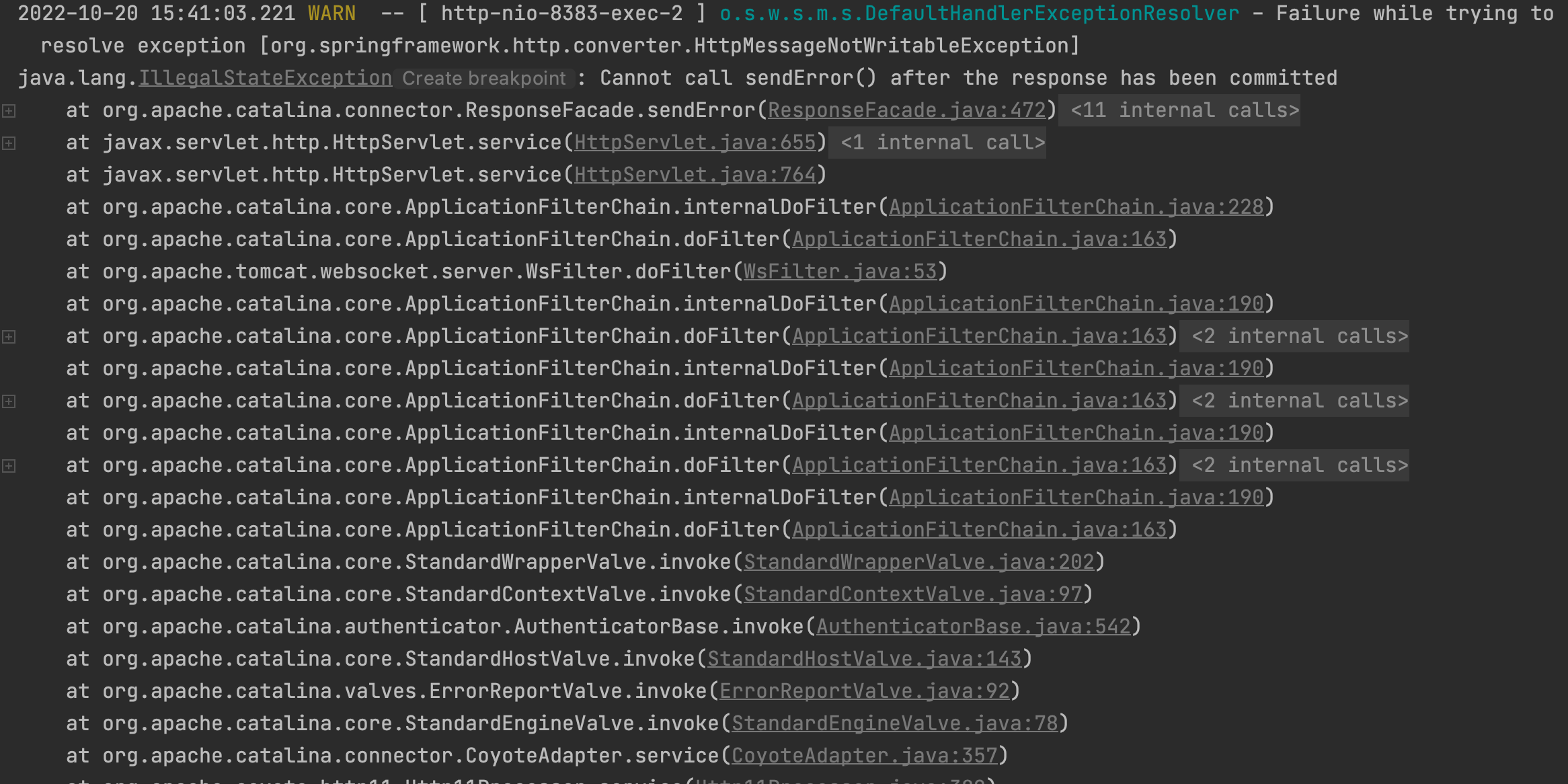
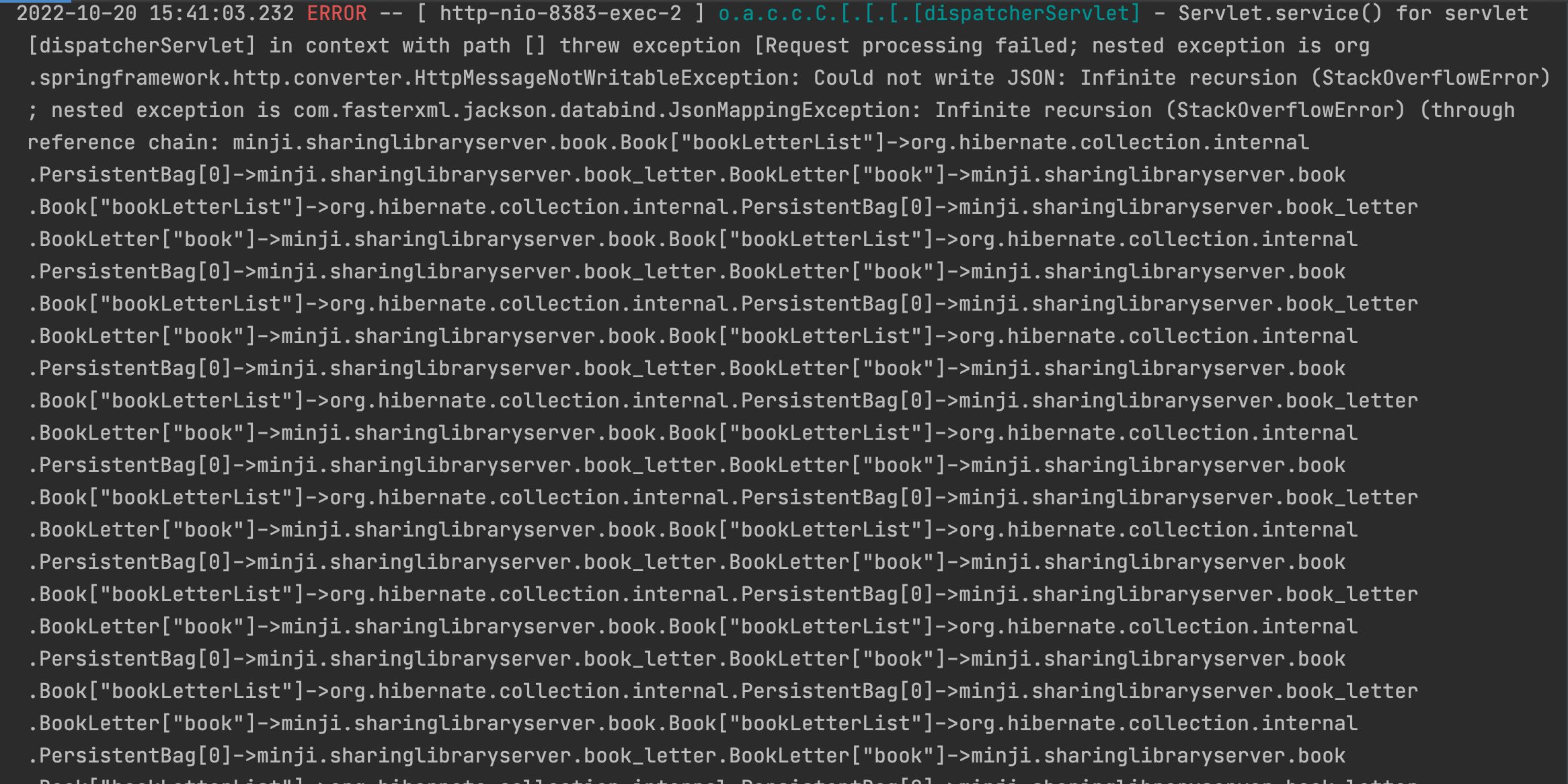
이렇게 ApplicationFilterChain.XXX 와 함께 끊임없이 호출구조가 이어지는 에러를 볼 수 있다..
이를 순환 참조 문제 라고 하는데, Book과 BookLetter 테이블이 서로를 참조하기 때문에 발생하는 문제이다.
제일 먼저 JPA 는 결과값인 BookLetter 를 반환해주기 위해 해당 테이블 멤버를 하나씩 확인한다
-> 멤버 중 Book 이 존재하므로 Book 을 확인한다
-> 또 BookLetter가 존재하므로 BookLetter를 확인한다
-> 또 Book이 존재
,,, 이런 체인이 생성되는 것이다.
해결법 ?
순환참조만을 해결하기위한 단순한 방법은 바로 @JsonIgnore를 이용하는 것이다.
두 테이블 중 한군데에 이 어노테이션을 선언하면 반환값에서 해당 컬럼은 제외하겠다는 의미이다.
class Book {
,,,
@OneToMany(mappedBy = "book")
private List<BookLetter> bookLetterList=new ArrayList<>(); //fk - 글귀
,,,
}기존의 위 코드를 아래와 같이 변경한다.
class Book {
,,,
@JsonIgnore // 어노테이션 추가!
@OneToMany(mappedBy = "book")
private List<BookLetter> bookLetterList=new ArrayList<>(); //fk - 글귀
,,,
}이제 순환참조문제는 발생하지 않는다. 생성된 쿼리를 확인해보자.
book_letter조회
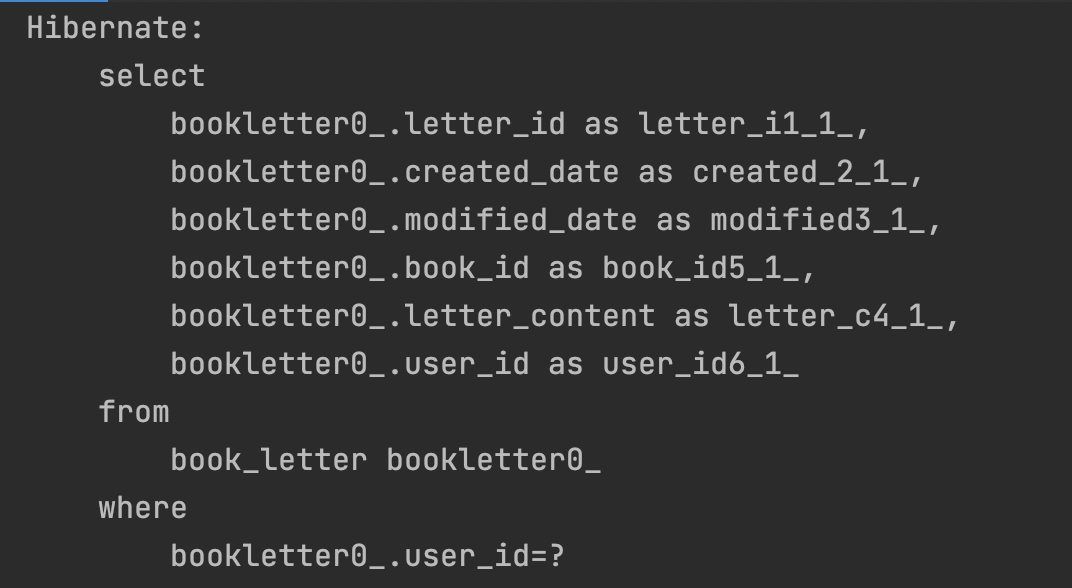 가장 먼저 book_letter 테이블에 조회 쿼리가 나간것을 볼 수 있다.
가장 먼저 book_letter 테이블에 조회 쿼리가 나간것을 볼 수 있다.
이제 다음으로 각각의 book_letter 내의 book 을 보고, 이를 조회할 것이다.
book조회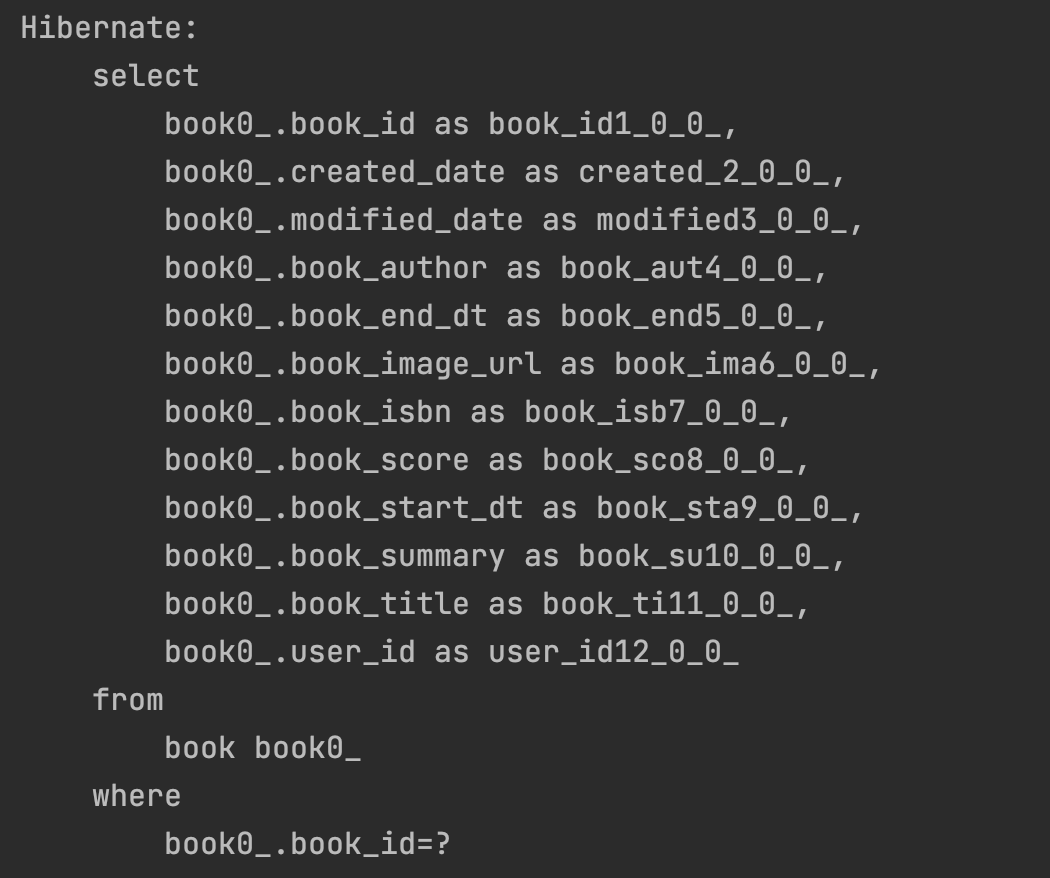 위와 같이 book 테이블에도 정상적으로 조회 쿼리가 나갔다.
위와 같이 book 테이블에도 정상적으로 조회 쿼리가 나갔다.
그런데 이 때, book 테이블에 쿼리가 나간 횟수를 보면 결과값의 수와 동일하다.
나의 경우 5번의 쿼리가 나갔다. (사진상의 동일한 쿼리가 실제로는 5번 쓰여진것을 확인 가능)
즉 , 결과에 해당하는 BookLetter 가 DB 상에 5개 존재하므로 각각의 Book 또한 한번씩 조회되기 때문이다.
이를 바로 또 다른 문제인 N+1 문제 라고 한다.
2️⃣ N+1 문제
위의 경우 결과값이 5개라는 적은 결과여서 성능상 큰 문제가 되지 않겠지만, 만약 10000개의 결과가 존재한다고 해보자.
그러면 findBookLettersByUser() 하나의 요청에 대해 10000번의 쿼리 ( = Book 테이블 조회 쿼리 ) 가 추가로 나가게 될 것이다.
즉 결과적으로, 최초의 쿼리에 대해 N 번의 추가 쿼리가 발생한다고 하여, 이러한 상황을 N+1 문제라고 한다.
N+1 문제는 결과값의 수가 많아질수록 성능상에 큰 영향을 줄 수 있기 때문에 해결을 해주어야하는데, 이 문제가 발생한 근본적인 원인은 바로 fetchType 때문이다.
BookLetter 테이블을 다시 한 번 보자.
class BookLetter {
,,,
@JoinColumn(name = "bookId")
@ManyToOne
@OnDelete(action = OnDeleteAction.CASCADE)
private Book book;
,,,
}BookLetter 에서는 Book 테이블과 @ManyToOne 관계를 맺고 있는데, 이 연관관계 어노테이션은 페치 타입을 갖는다. ManyToOne 이 정의된 인터페이스에 가보면, fetch() 에 위와 같이 기본 페치 타입이
ManyToOne 이 정의된 인터페이스에 가보면, fetch() 에 위와 같이 기본 페치 타입이 default EAGER 로 선언되어있는 것을 볼 수 있다.
( XToOne 은 default EAGER, XToMany 는 default LAZY 이다. )
이는 관련된 엔티티에 대해 즉시 이를 DB에서 조회한다는 의미이다.
즉, BookLetter에 대해 Book이 EAGER 로 선언되어 있었기 때문에, 연관된 Book들을 바로 조회했고, 추가 쿼리들이 나간 것이다.
따라서 EAGER 로 페치 타입을 설정하는 것은 위험한 방법이며, 대신 이와 반대되는 LAZY 페치 를 사용하는 것이 안전하다.
3️⃣ Lazy Loading
JPA 가 제공하는 페치 타입 fetch = LAZY 를 사용해 데이터에 접근하는 것을 Lazy loading 이라고 한다.
이를 사용하면 JPA 는 관련 데이터를 바로 DB에서 가져오지 않고, 대신 proxy 객체를 임시로 가져온다.
실제 데이터를 가져오는 것(즉, DB에 쿼리를 날리는 것)은 그 데이터가 실제로 사용되는 시점이고, 따라서 lazy loading이라고 하는 것이다.
class BookLetter {
,,,
@JoinColumn(name = "bookId")
@ManyToOne(fetch=LAZY) // 변경!!!
@OnDelete(action = OnDeleteAction.CASCADE)
private Book book;
,,,
}다음과 같이 Book 컬럼을 @ManyToOne(fetch=LAZY) 로 변경해줌으로써 lazy loading을 이용할 수 있다.
- cf)
이 때, 그대로 List < BookLetter > 를 반환하려고 하면 문제가 발생한다.
왜냐하면 반환값에 Book 이 여전히 존재하고 있으므로 JPA는 어찌됐건 Book 에 대한 정보를 파싱해 내보내야한다.
즉, 위에서 말한실제로 데이터가 사용되는 시점이 바로 발생하는 것이고, 이 때 해당 데이터는 실제 값이 아닌 proxy 값이기 때문에 정상적으로 값을 가져올 수 없다.
실제 에러를 통해 확인해보자. 다음과 같은 로그를 볼 수 있는데, BookLetter["book"] 멤버가 proxy 객체 라는 의미이다. 실제로 찍힌 Book 의 타입 역시
다음과 같은 로그를 볼 수 있는데, BookLetter["book"] 멤버가 proxy 객체 라는 의미이다. 실제로 찍힌 Book 의 타입 역시 book.Book$HibernateProxy$,,, 임을 볼 수 있다.
** 따라서 우선은 BookLetter 테이블의 book 컬럼에도 @JsonIgnore를 선언해주고, 추가로 쿼리가 나가지 않는다는 사실만 확인해보자.
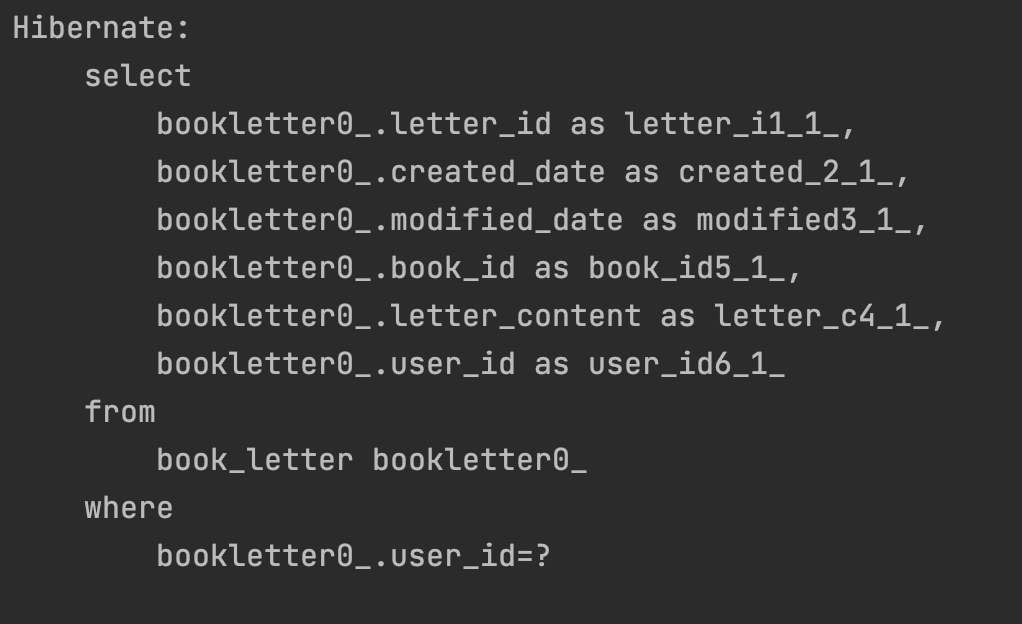 이렇게 이전과 동일하게
이렇게 이전과 동일하게 book_letter 테이블에 조회 쿼리가 가장 먼저 나갔으며, 그 다음으로 나간 쿼리는 없다.
즉, book 테이블의 조회 시점이 미뤄진것을 확인할 수 있다.
** 하지만 이경우 당연히 반환값에 Book 정보는 포함되지 않는다.
즉 정리하자면,
BookLetter 를 조회할 때, Book에 대한 정보를 가져올 필요가 없다면 위와 같이 Lazy Loading 과 함께 @JsonIgnore를 사용한다고 생각하자.
반대로 만약 반환값에서 Book 정보가 필요하다면, 뒤에서 알아볼 fetch join 을 사용해야한다. (이 경우에도 Lazy Loading을 사용해야하는 것은 변함 없음!)
4️⃣-1. Fetch Join
BookLetter 의 리스트 결과값에서 Book에 대한 정보도 함께 필요하다면 어떻게해야할까?
바로 ** Fetch Join ** 을 사용해야한다!
우리는 기존에 SpringDataJpa 가 제공하는 기본 네임드쿼리를 사용했다. 이를 아래와 같이 변경, 직접 쿼리를 지정해주자. ( + 책 정보를 가져와야하므로 @JsonIgnore은 삭제해준다. )
이를 아래와 같이 변경, 직접 쿼리를 지정해주자. ( + 책 정보를 가져와야하므로 @JsonIgnore은 삭제해준다. )
select bl from BookLetter bl join fetch bl.book where bl.user=:user여기서 주목해야하는 부분은 join fetch bl.book 이다.
이것이 바로 페치조인 인데,
BookLetter 테이블을 조회하면서 Book 테이블을 함께 join 해서 가져오라는 의미이다.
이전에 N+1 문제가 발생한 쿼리에서는 두 테이블간에 join이 발생하지 않았었다.
반면 fetch join을 하게 되면 두 테이블간 join이 발생, 이미 조인 정보를 모두 끌어 왔으므로 ** 추가적인 쿼리가 필요 없어진다!!
결과를 통해 확인해보자.
select
bookletter0_.letter_id as letter_i1_1_0_,
book1_.book_id as book_id1_0_1_,
bookletter0_.created_date as created_2_1_0_,
bookletter0_.modified_date as modified3_1_0_,
bookletter0_.book_id as book_id5_1_0_,
bookletter0_.letter_content as letter_c4_1_0_,
bookletter0_.user_id as user_id6_1_0_,
book1_.created_date as created_2_0_1_,
book1_.modified_date as modified3_0_1_,
book1_.book_author as book_aut4_0_1_,
book1_.book_end_dt as book_end5_0_1_,
book1_.book_image_url as book_ima6_0_1_,
book1_.book_isbn as book_isb7_0_1_,
book1_.book_score as book_sco8_0_1_,
book1_.book_start_dt as book_sta9_0_1_,
book1_.book_summary as book_su10_0_1_,
book1_.book_title as book_ti11_0_1_,
book1_.user_id as user_id12_0_1_
from
book_letter bookletter0_
inner join
book book1_
on bookletter0_.book_id=book1_.book_id
where
bookletter0_.user_id=?
로그에 찍힌 쿼리이다. 위와 같이 딱 1개의 쿼리만이 발생한 것을 확인할 수 있다.
그리고 결과값으로는 5개의 책정보가 함께 조회되는 것을 볼 수 있다.
즉, Fetch Join 은 LAZY 로딩은 그대로 이용해 성능상 낭비는 하지 않으면서, 원하는 결과값을 모두 함께 가져올 수 있는 효율적인 방식이다.
4️⃣-2. EntityGraph
페치 조인과 같은 역할을 하는 또 다른 방식으로 EntityGraph 가 있다. 엔티티 그래프는 따로 쿼리를 작성해줄 필요는 없으며,
엔티티 그래프는 따로 쿼리를 작성해줄 필요는 없으며,
위와 같이 기존의 네임드 쿼리 위에 @EntityGraph(attributePaths = {조인할 테이블 리스트}) 를 옵션으로 적어주면 된다.
만약 book 테이블과 user 테이블 모두와 조인하고 싶다면 어떻게 해야할까?
-
EntityGraph
@EntityGraph(attributePaths = {"book","user"}) -
Fetch Join
@Query(value = "select bl from BookLetter bl join fetch bl.book join fetch bl.user")
두가지 방법을 사용할 수 있다.
두 경우, 발생하는 쿼리는 동일하지만, 조인 방식에서만 차이가 있다.
- Fetch Join : inner join 사용,
- EntityGraph : left outer join 사용
(이 예시에서는 book_letter 가 전체 참여이므로 둘 중 어느것을 써도 동일하다.)
5️⃣ 마무리
-
성능 최적화에는 Fetch Join 또는 EntityGraph 를 사용할 수 있다.
-
실무에서 JPA를 사용하는 경우 대부분 lazy loading 으로 설정하는 것을 권장한다고 한다.
즉, 디폴트를 LAZY 로 두고, 성능최적화가 필요한 곳에서 위의 두가지를 사용하는 습관을 들이자. -
추가로, 예시에서는 모두 BookLetter 엔티티를 그대로 반환시켰지만, 실제로는 각각의 상황에 맞는 DTO 클래스를 만들어 이를 반환시키는 것이 좋은 방법이다.
