
➕ INSERT문
테이블에 행을 삽입
전체 데이터 삽입(전체 컬럼 명시시)
INSERT INTO emp (empno,ename,job,mgr,hiredate,sal,comm,deptno) VALUES (8000,'DENNIS','SALESMAN',7698,'99/01/22',1700,200,30)
SELECT * FROM emp;전체 데이터 삽입할 때는 컬럼명 생략 가능
INSERT INTO emp VALUES (8001, 'SUNNY','SALESMAN', 7698, '99/03/01',1000,300,30);
SELECT * FROM emp; NULL 삽입 방법
값이 입력되지 않는 컬럼은 제외
INSERT INTO emp(empno,ename,job, mgr,hiredate,sal,deptno) VALUES (8003,'PETER','CLERK',7698,'22/11/06',1700,20);
SELECT * FROM emp;값이 입력되지 않는 칼럼을 제외하지 않았을 경우
INSERT INTO emp(empno,ename,job, mgr,hiredate,sal,comm,deptno) VALUES(8004, 'ANNIE','CLERK', 7698, '22/11/06',1800,NULL,30);날짜의 삽입
INSERT INTO emp(empno,ename,job, mgr,hiredate,sal,comm,deptno) VALUES (8005,'MICHAEL','CLERK', 7698, TO_DATE('22/11/06', 'YY/MM/DD'), 1800,NULL,30);🌀 UPDATE문
행 단위로 데이터 갱신
UPDATE emp SET mgr = 7900 WHERE empno = 8000;
UPDATE emp SET ename = 'MARIA' , sal=2500, comm =500 WHERE empno=8000;WHERE 절을 명시하지 않으면 전체 행의 데이터를 수정한다.
UPDATE emp SET ename='KINGKONG';
ROLLBACK; -- 되돌리기와 비슷한 개념🗑️ DELETE 문
행 삭제
DELETE FROM emp WHERE empno=7369;WHERE 절을 명시하지 않으면 모든 행이 삭제된다.
DELETE FROM emp;데이터베이스 트랜잭션
- 트랜잭션은 데이터 처리의 한 단위이다.
- 오라클 서버에서 발생하는 SQL문들을 하나의 논리적인 작업단위로써 성공하거나 실패하는 일련의 SQL문을 트랜잭션이라고 할 수 있다.
- 트랜잭션은 데이터를 일관되게 변경하는 DML문장으로 구성됨
1) 트랜잭션의 시작
실행 가능한 SQL문장이 제일 처음 실행될 때
2) 트랜잭션의 종료
COMMIT 이나 ROLLBACK
DDL이나 DCL문장의 실행(자동 COMMIT)
기계 장애 또는 시스템 충돌(crash)
deadlock 발생
사용자가 정상 종료
3) 자동 COMMIT 은 다음의 경우 발생
DDL, DCL 문장이 완료 될 때
명시적인 COMMIT이나 ROLLBACK 없이 SQL*Plus를 정상 종료 했을 경우
4) 자동 ROLLBACK은 다음의 경우 발생
SQL*Plus를 비정상 종료 했을 경우
비정상적인 종료
system failure
데이터베이스 객체
- 테이블 : 기본 저장 단위로 행과 열로 구성
테이블은 기본적인 데이터 저장 단위
레코드와 컬럼으로 구성 된다.- 레코드(record, row) : 테이블의 데이터는 행에 저장
- 컬럼(column) : 테이블의 각 컬럼은 데이터를 구별할 수 있는 속성을 표현
- 이름 지정 규칙
- 문자로 시작해야 한다.
- 1자부터 30자까지 가능하다.
- A-Z, a-z, 0-9, _, $, #만 포함해야 한다.
- 동일한 사용자가 소유한 다른 객체의 이름과 중복되지 않아야 한다.
- Oracle server의 예약어가 아니어야 한다.
사용자가 소유한 테이블의 이름
SELECT table_name FROM user_tables;사용자가 소유한 개별 객체 유형
SELECT DISTINCT object_type FROM user_objects;사용자가 소유한 테이블, 뷰, 동의어 및 시퀀스
SELECT * FROM user_catalog; - 오라클 데이터베이스의 테이블
- 사용자 테이블
사용자가 생성 및 유지 관리하는 테이블의 collection 사용자 정보를 포함 - 데이터 딕셔너리
Oracle Server가 생성 및 유지 관리하는 테이블의 collection 데이터베이스 정보를 포함
- 사용자 테이블

테이블의 생성
- 테이블 이름 : 만들어질 테이블의 이름
- 열 이름 : 테이블 내에 만들어질 열의 이름
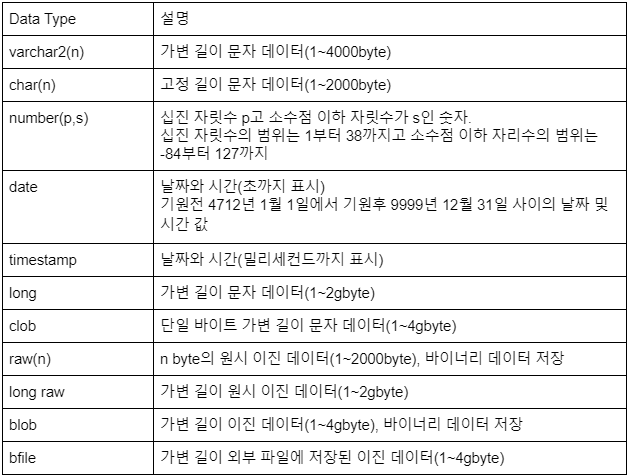
열의 이름은 같은 테이블 내에서는 유일해야 하지만, 서로 다른 테이블 간에는 같은 이름을 사용할 수 있다. - 데이터 타입 : 각각의 열은 자신의 데이터 타입을 가진다.
열의 데이터 타입이 결정되면 어떤 데이터 타입이 지정되는지에 따라 데이터의 길이나 정확도와 스케일이 지정되어야 한다. - default <표현식> : 각각의 열에는 insert 구문에 열의 값이 지정되지 않은 경우에 이용될 디폴트 값을 지정한다.
<표현식> 부분에는 정적인 값이나 대부분의 SQL 함수를 지정 가능하다. - 제약조건 : 만들어질 각 열에 선택적으로 제약조건을 정의할 수 있다.
제약조건은 각 열의 값이 올바른 것이 되기 위해 지켜져야 할 규칙이다.
제약 조건
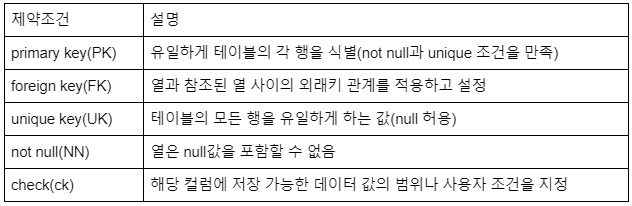
Oracle 데이터 타입
테이블의 생성
CREATE TABLE employee (
empno NUMBER(6) ,
name VARCHAR2(30) NOT NULL,
salary NUMBER(8,2),
hire_date DATE DEFAULT SYSDATE,
CONSTRAINT employee_pk_empno PRIMARY KEY(empno)
);테이블에 데이터 입력
INSERT INTO employee(empno,name,salary) VALUES(100,'홍길동',1000.23);
COMMIT;테이블 생성시 PRIMARY KEY 및 FOREIGN KEY 제약 조건 추가하기
CREATE TABLE SUSER (
id VARCHAR2(20),
name VARCHAR2(30),
CONSTRAINT suser_pk PRIMARY KEY (id)
);
CREATE TABLE SBOARD (
num NUMBER,
id VARCHAR2(20) NOT NULL,
content VARCHAR2(4000) NOT NULL,
CONSTRAINT sboard_pk PRIMARY KEY(num),
CONSTRAINT sboard_fk FOREIGN KEY (id) REFERENCES suser (id)
);
INSERT INTO suser (id,name) VALUES ('dragon', '홍길동');
INSERT INTO suser (id,name) VALUES ('sky', '박문수');
INSERT INTO sboard (num, id, content) VALUES (1,'sky', '오늘은 금요일');
INSERT INTO sboard (num, id, content) VALUES (2,'dragon', '내일은 토요일');
INSERT INTO sboard (num, id, content) VALUES (3,'blue','모레는 일요일'); -- 부모키에 blue가 없기 때문에 데이터 삽입이 불가능하다.
DELETE FROM suser WHERE id = 'sky'; -- 자식 데이터가 존재하기 때문에 삭제가 불가능하다
두개의 테이블 join 작업
SELECT * FROM suser JOIN sboard USING(id);테이블의 관리
- ADD 연산자 : 테이블에 새로운 컬럼을 추가
ALTER TABLE employee ADD (addr VARCHAR(2));- 제약 조건 추가
ALTER TABLE employee ADD CONSTRAINT employee_pk PRIMARY KEY (id);- MODIFY 연산자 : 테이블의 컬럼을 수정 하거나 not null 컬럼으로 변경 할 수 있음
ALTER TABLE employee MODIFY (salary NUMBER(10, 2) NOT NULL);- 컬럼명 변경
ALTER TABLE employee RENAME COLUMN salary TO sal;- 테이블명 변경
RENAME employee TO emplyee2;- 테이블 삭제
DROP TABLE employee2;- ON DELETE CASCADE : 부모 테이블의 컬럼을 삭제하면서 자식 테이블의 자식 데이터를 모두 삭제
CREATE TABLE s_member (
id VARCHAR2(20) PRIMARY KEY,
name VARCHAR2(30)
);
CREATE TABLE s_member_detail(
num NUMBER PRIMARY KEY,
content VARCHAR2(4000) NOT NULL,
id VARCHAR2(20) NOT NULL REFERENCES s_member (id) ON DELETE CASCADE
);
INSERT INTO s_member (id, name) VALUES('dragon','홍길동');
INSERT INTO s_member (id,name) VALUES ('sky', '박문수');
INSERT INTO s_member_detail(num,content,id) VALUES (1,'오늘은 금요일','sky');
INSERT INTO s_member_detail(num,content,id) VALUES (2,'내일은 토요일','sky');
INSERT INTO s_member_detail(num,content,id) VALUES (3,'모레는 일요일','sky');
DELETE FROM s_member WHERE id = 'sky';
COMMIT;
실습 문제 1
- student 라는 이름으로 테이블 생성
컬럼명 id , name , age , score
데이터 타입 VARCHAR2(10), VARCHAR2(30), NUMBER(3), NUMBER(3)
제약 조건 PRIMARY KEY ,NOT NULL , NOT NULL , NOT NULL
CREATE TABLE STUDENT (
id VARCHAR2(10) PRIMARY KEY,
name VARCHAR2(30) NOT NULL,
age NUMBER(3) NOT NULL,
score NUMBER(3) NOT NULL
);
COMMIT;- 데이터를 아래와 같이 입력하세요
id name age score
dragon 홍길동 21 100
sky 장영실 21 99
blue 박문수 34 88
INSERT INTO student VALUES('dragon','홍길동',21,100);
INSERT INTO student VALUES('sky','장영실',21,99);
INSERT INTO student VALUES('blue','박문수',34,88);
COMMIT;- 데이터 읽기 STUDENT TABLE 에서 성적 합계를 구하세요.
SELECT SUM(score) FROM student;뷰(VIEW)
논리적으로 하나 이상의 테이블에 있는 데이터의 부분 집합
- 데이터 액세스를 제한하기 위해
- 복잡한 질의를 쉽게 작성하기 위해
- 데이터 독립성을 제공하기 위해
- 동일한 데이터로부터 다양한 결과를 얻기 위해
- 뷰는 가상으로 만들어진 칼럼(Virtual Column)을 제외하면 수정이 가능하고 삭제도 가능하다.
수정, 삭제하면 원래 테이블에 반영, 삽입은 여러 제약 조건과 virtual column 사용으로 제약이 많다.
VIEW 생성
CREATE OR REPLACE VIew emp10_view
AS SELECT empno id_number, ename name, sal *12 ann_salary FROM emp WHERE deptno =10;
SELECT * FROM emp10_view;
CREATE OR REPLACE VIEW emp_info_view
AS SELECT e.empno, e.ename, d.deptno, d.loc, d.dname FROM emp e, dept d WHERE e.deptno = d.deptno;
SELECT * FROM emp_info_view;VIEW를 통한 데이터 변경하기
일반적으로 View는 조회용으로 많이 사용되지만 아래와 같이 데이터를 변경할 수 있음
UPDATE emp10_view SET name ='SCOTT' WHERE id_number = 7839;
SELECT * FROM emp10_view;가상열 때문에 등록이 제한
INSERT INTO emp10_view(id_number,name,ann_salary) VALUES(8000,'JOHN',19000);- WITH READ ONLY : 읽기 전용 뷰를 생성하는 옵션
CREATE OR REPLACE VIEW emp20_view
AS SELECT empno id_number , ename name, sal * 12 ann_salary FROM emp WHERE deptno = 20 WITH READ ONLY;
UPDATE emp20_view SET NAME='DAVID' WHERE id_number = 7902;VIEW 수정하기
CREATE OR REPLACE VIEW emp10_view
(id_number, name, sal, department_id)
AS SELECT empno, ename, sal, deptno FROM emp WHERE deptno = 10;
SELECT * FROM emp10_view;VIEW의 삭제
DROP VIEW emp10_view;SEQUENCE
- 유일한 값을 생성해주는 오라클 객체
- 시퀀스를 생성하면 기본키와 같이 순차적으로 증가하는 컬럼을 자동적으로 생성할 수 있음
- 보통 primary key 값을 생성하기 위해 사용
SEQUENCE 생성
시작 값이 1 이고 1씩 증가하고 최대값이 100000이 되는 시퀀스
CREATE SEQUENCE test_seq
START WITH 1
INCREMENT BY 1
MAXVALUE 100000; - CURRVAL : 현재 값 반환
- NEXTVAL : 현재 시퀀스 값의 다음 값 반환
SELECT test_seq.NEXTVAL FROM dual;
SELECT test_seq.CURRVAL FROM dual;sboard 테이블에 데이터를 삽입할 때 시퀀스 활용
INSERT INTO sboard(num,id,content)
VALUES (test_seq.NEXTVAL , 'sky','강남');
SELECT * FROM sboard; 시퀀스 수정
START WITH 수정 불가능
ALTER SEQUENCE test_seq INCREMENT BY 5;시퀀스 삭제
DROP SEQUENCE test_seq;