데이터 모델링
데이터 모델링이란?
- 논리적 모델링: 개념적 구조를 정하는 것
- 물리적 모델링: 데이터베이스 구축에 필요한 것을 정하는 것
데이터 모델
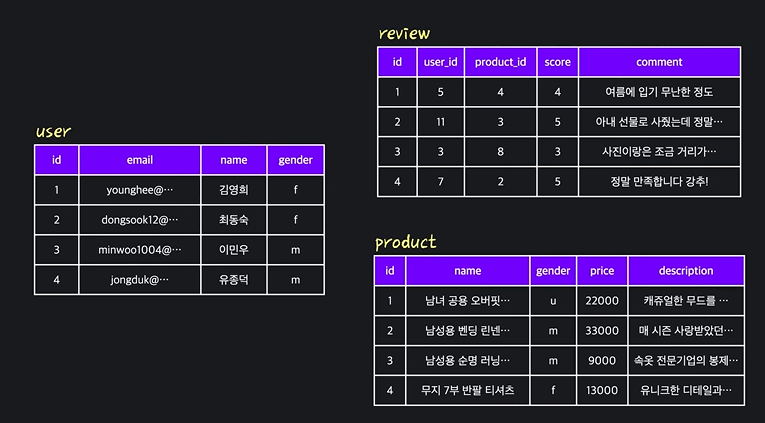
- Entity (개체) : 저장하고 싶은 데이터의 대상.
예: 학생, 수업, 교수... - Attribute (속성) : 엔티티에 대해서 저장하려는 내용.
예: 학생의 학번, 이름, 성별, 전공 ... - Relationship (관계) : 엔터티 사이의 연결점
예: 학생이 수업을 수강한다, 교수가 수업을 가르친다 ... - Constraint (제약조건)
예: 학생의 학번은 겹쳐서는 안됨, 하나의 수업에 적어도 하나의 교수가 배정되어야 함 ...
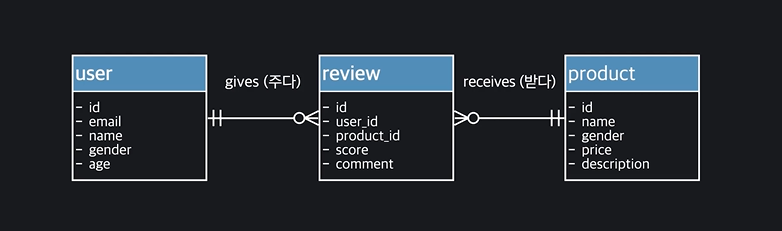
Relational 모델
- Relation = 테이블 (not 관계)
- Relationship = 테이블 사이에 맺어지는 관계
→ FK를 사용해서 표현함
Entity-Relationship Model (ERM)
↓
데이터 모델 스펙트럼
✓ 데이터 모델의 종류: 개념모델, 논리모델, 물리모델 → 순서대로 점점 더 정확해짐
논리적 모델링
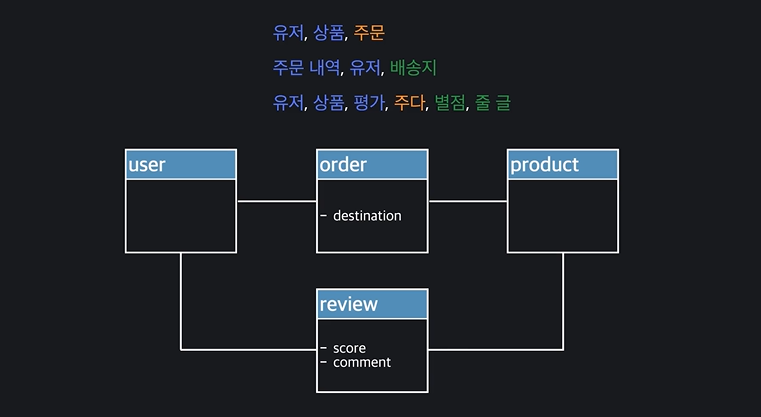
Entity, Attribute, Relationship 후보 찾기
- 모든 명사는 entity 후보이다
- 모든 동사는 relationship 후보이다
- 하나의 값으로 표현할 수 있는 명사는 attribute 후보이다
→ 예외? attribute의 값이 여러개일 때
▶ 이유: 구조적으로 null이 여러개 발생할 가능성이 있고, row가 추가됨에 따라 테이블의 구조가 변화해야 함

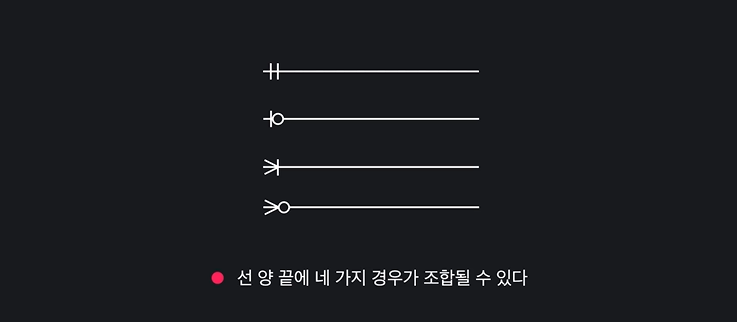
카디널리티
- 카디널리티(Cardinality)란? entity A와 B 사이에서 A 한개가 B 몇개와 연결될 수 있고, B 몇개가 A 몇개와 연결될 수 있는지를 나타냄
- 종류: 1:1, 1:N, N:M
카티널리티 ERM에서 표현하기
- 카디널리티의 개수

- 필수 여부

- 총 종류
일대일, 일대다 관계, 다대다 관계 모델링
정규화
데이터베이스 이상현상 (anomaly)
- 데이터베이스에서 삽입, 업데이트, 삭제가 정상적으로 이루어지지 않는 경우
- 삽입 이상: 컬럼의 값들을 모두 채우지 않으면 삽입이 되지 않는 경우
- 업데이트 이상: 데이터를 업데이트했을때 불일치가 발생하는 경우
- 삭제이상: 원하는 데이터만 자연스럽게 삭제가 불가하고, 원하지 않는 데이터까지 연쇄적으로 삭제되어버리는 현상
정규화 (Normalization)
-
정규화: 데이터베이스의 테이블이 잘 만들어졌는지를 평가하고, 잘 만들지 못한 테이블을 고쳐나가는 과정
데이터 모델을 만들고, 데이터베이스에 구현하기 전에 적용하는 것이 바람직함 -
정규형: 1NF, 2NF, 3NF
-
prime attribute: 테이블 안 하나의 로우를 특정짓는 데 사용될 수 있는 컬럼
1NF
- 규칙: 테이블 안 모든 row의 모든 컬럼값들은 쪼갤 수 없는 단일값이어야 함
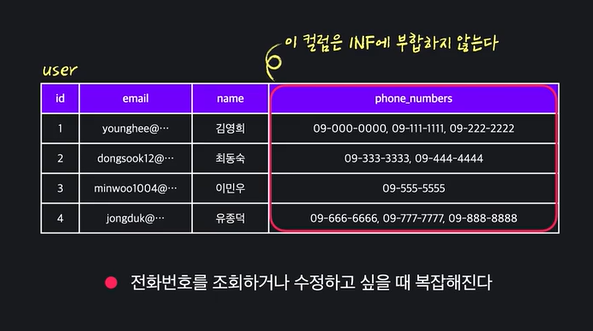
- https://www.codeit.kr/topics/database-modeling-and-normalization/lessons/4448
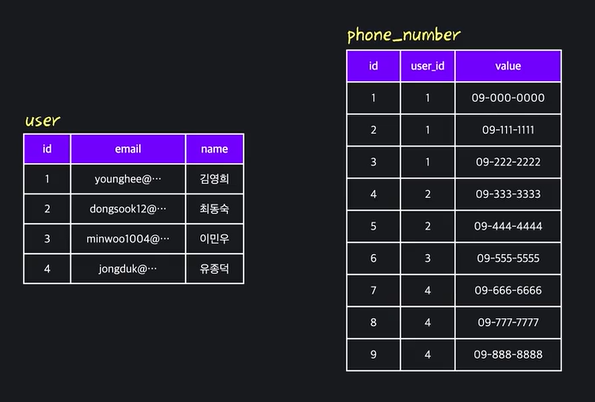
- 만약 단일값이 아니라면, 해당 컬럼을 별도의 테이블로 분리한 후,
(1) 두 테이블 사이의 관계가 다대다(M:N) 관계일 경우: 연결 테이블을 사용해서 기존 테이블과 새로운 테이블 간의 관계를 모델링함
(2) 두 테이블 사이의 관계가 일대다(1:N) 관계일 경우 "다"에 해당하는 테이블에 foreign key를 만들어서 두 테이블 사이 관계를 모델링합니다.
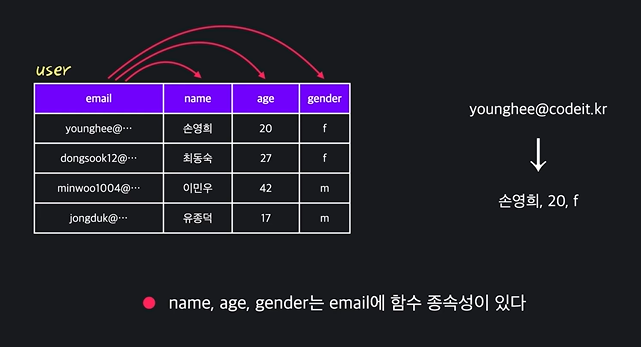
함수 종속성
- x의 값에 따라서 y의 값이 결정될 때, y는 x에 함수 종속성이 있음
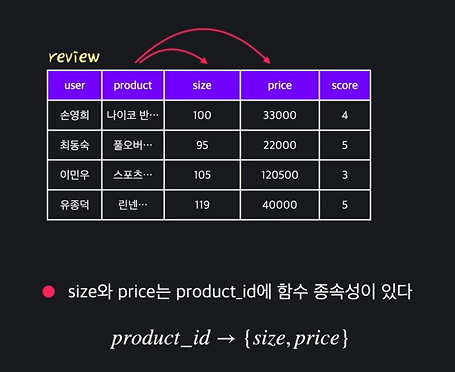
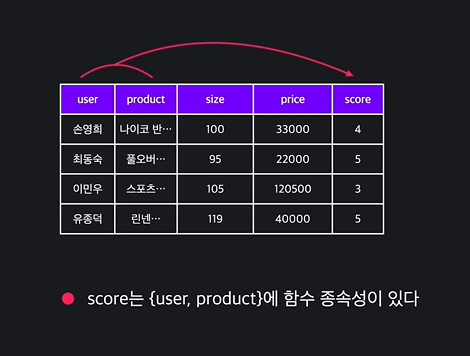
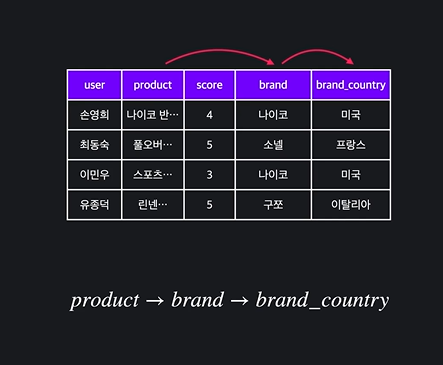
- 이행적 함수 종속성: 하나 이상의 attribute를 건너서 함수 종속성이 있는 경우에 함수 종속성이 이행된다고 함
Candidate Key (후보키)
- Candidate Key: 하나의 row를 특정지을 수 있는 attribute들의 최소집합
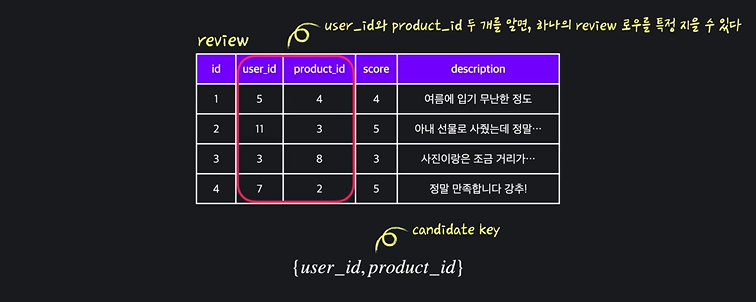
- id 단독으로도 candidate key가 될 수 있음
2NF
- 규칙
- 테이블 안 모든 row의 모든 컬럼값들은 쪼갤 수 없는 단일값이어야 함
- 테이블에 candidate key의 일부분에 대해서만 함수종속성이 존재하는 non-prime attribute가 없어야 함
3NF
- 규칙
- 테이블 안 모든 row의 모든 컬럼값들은 쪼갤 수 없는 단일값이어야 함
- 테이블에 candidate key의 일부분에 대해서만 함수종속성이 존재하는 non-prime attribute가 없어야 함
- 테이블 안에 있는 모든 attribute들은 오직 primary key에 대해서만 함수 종속성이 있어야 함 (이 때, 이행적 함수종속성은 해당하지 않음)
물리적 모델링
네이밍
테이블 이름 작명 시,
- 단수/복수를 통일해야 함
- 대문자/띄어쓰기방식 정하기 (camal case 등)
- 줄임말을 통일해야 함
데이터타입
- 각 컬럼에 어떤 타입의 테이터를 저장할 지 정하는 것
선형 vs 이진 탐색
-
선형탐색: 리스트에서 맨 앞부터 순서대로 하나씩 확인해보는 방식
특히 정렬되지 않은 리스트의 경우, 선형탐색이 가장 빠른 방식임 → O(n) -
이진탐색: 리스트에서 가장 가운데의 원소를 확인하고, 해당 원소와 찾고자 하는 원소의 크기를 비교한 후 대소관계에 따라 반씩 버려가며 다시 가운데 값을 비교하는 것을 반복함
정렬된 리스트의 경우 무척 효율적 → O(logn)
Clustered vs Non-Clustered 인덱스
-
Clustered: 조회속도가 아주 빠르고 인덱스를 하나밖에 못 만듦 (사전식)
-
Non-Clustered: 테이블 자체는 수정하지 않은 채, 새로운 테이블을 생성해서 순서 저장
-
이 때, 자주 삽입, 업데이트, 삭제되는 테이블의 컬럼에 인덱스를 추가하는 것은 오히려 역효과!!
-
인덱스 추가 코드: https://www.codeit.kr/topics/database-modeling-and-normalization/lessons/4446
