[Spring] Scheduler 중복 실행 방지 : @ShedLock 적용
Spring의 @Scheduled를 활용하면 정기적인 작업을 손쉽게 수행할 수 있습니다.
하지만 서버가 여러 대일 경우, 동일한 스케줄러가 중복 실행되어 문제가 될 수 있습니다.
이를 해결하기 위해 ShedLock이라는 라이브러리를 도입했고,
이번 글에서는 ShedLock의 개념부터 실전 적용까지의 과정을 공유합니다.
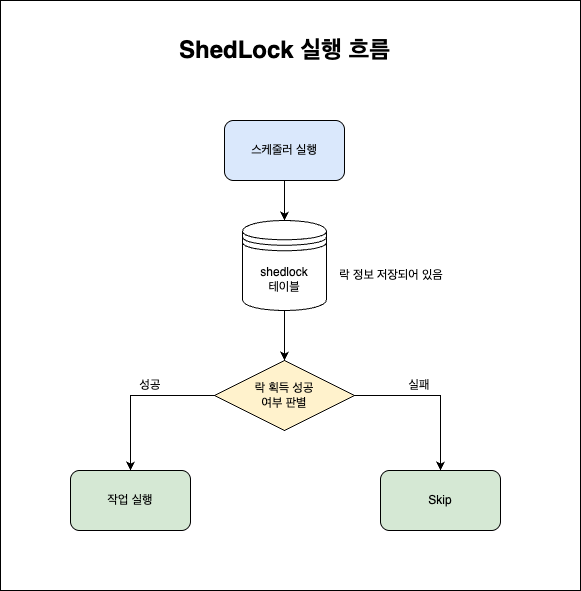
💫 왜 ShedLock이 필요한가?
기존 구조에서는 서버 인스턴스가 여러 개일 경우 @Scheduled가 모든 인스턴스에서 동시에 실행됨.
→ 중복 작업, DB 충돌, 예외 발생 등의 문제로 이어질 수 있음.
✅ 한 번에 하나의 인스턴스만 실행되도록 하려면 "스케줄 락"이 필요 ‼️
🌀 스케줄러가 8080, 8081 서버 양쪽에서 동시에 실행됨
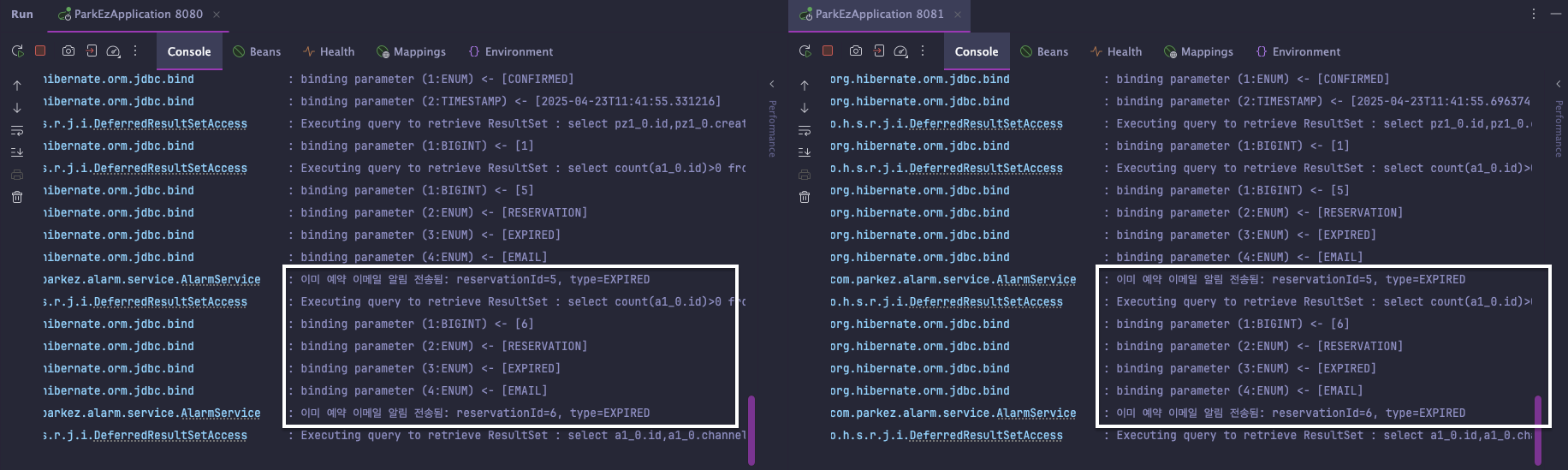
실제로 우리 프로젝트에서의 배포 서버는 2개를 띄우기 때문에
스케줄러 작업이 불필요하게 계속 반복되는 것을 방지해야한다!
🔧 ShedLock이란?
ShedLock은 스케줄러 실행 시점에 DB 등의 외부 저장소를 통해 락을 획득하고,
오직 한 인스턴스만 작업을 수행하도록 제어해주는 경량 라이브러리
- 다양한 저장소 지원: RDB(MySQL), Redis, MongoDB 등
- 락 선점 → 작업 실행 → 자동 락 해제
⚙️ Gradle 의존성 추가
✅ 개발 환경
| 항목 | 버전 |
|---|---|
Spring Boot | 3.4.4 |
Java | 17 |
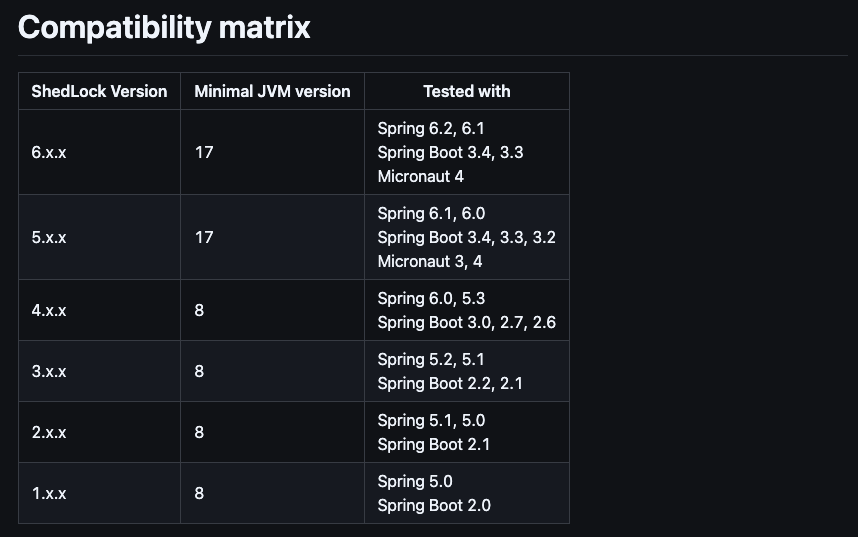
출처 : ShedLock Github
spring boot 혹은 java 버전에 따라 추가해야하는 shedlock 의존성의 버전이 다르다.
나는 아래와 같이 추가해주었다.
// shed lock
implementation 'net.javacrumbs.shedlock:shedlock-spring:5.12.0'
implementation 'net.javacrumbs.shedlock:shedlock-provider-jdbc-template:5.12
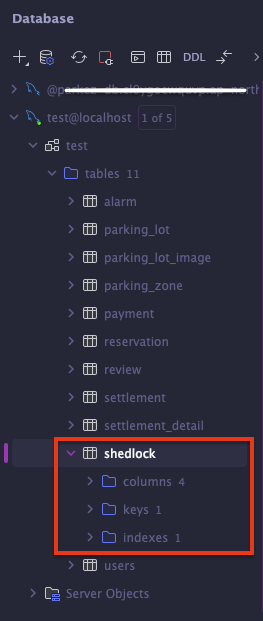
.0'🗃️ ShedLock 테이블 생성 (MySQL)
CREATE TABLE shedlock (
name VARCHAR(64) NOT NULL COMMENT '이름',
lock_until TIMESTAMP(3) NOT NULL COMMENT '잠금 일시',
locked_at TIMESTAMP(3) NOT NULL COMMENT '잠금 시간',
locked_by VARCHAR(255) NOT NULL COMMENT '잠금 인스턴스',
PRIMARY KEY (name)
);comment '---'은 필수 아님! 개인적으로 작성하고 싶어서 추가했다.
DB에 shedlock 테이블이 잘 생성된 것을 볼 수 있다.
🧩 SchedulerConfig 설정
@Configuration
@EnableScheduling
@EnableSchedulerLock(defaultLockAtMostFor = "PT30S")
public class SchedulerConfig {
@Bean
public LockProvider lockProvider(DataSource dataSource) {
return new JdbcTemplateLockProvider(
JdbcTemplateLockProvider.Configuration.builder()
.withJdbcTemplate(new JdbcTemplate(dataSource))
.usingDbTime()
.build()
);
}
}config 설정은 ShedLock Github를 참고하였다.
🔍 @EnableSchedulerLock 속성 설명
| 속성 | 설명 |
|---|---|
defaultLockAtMostFor | 락이 강제로 해제되기까지의 최대 시간 (예: PT30S → 30초) |
defaultLockAtLeastFor | (선택) 락을 최소한 유지해야 하는 시간 (지정하지 않으면 바로 해제됨) |
✅ 실제 적용 예시 – @SchedulerLock
우리 프로젝트에는 현재 총 5개의 스케줄러가 적용되어있다.
그 중, 공공데이터 불러오는 스케줄러에는 AWS Lambda를
정산 확정 스케줄러에는 스프링 배치를 적용하기로 하였다.
따라서 나는
-
이메일 전송 스케줄러
: 예약 만료 10분 전 & 예약 만료 시 이메일 전송 스케줄러 -
예약 만료 처리 (timeout)
: 예약 생성 후 10분 이내로 결제 생성이 되지 않았을 때
예약 상태를 취소로 변경하는 스케줄러 -
결제 만료 처리 (timeout)
: 결제 생성 후 10분 이내로 결제 승인 처리가 되지 않았을 때
결제 상태를 취소로 변경하는 스케줄러
이 세 가지 스케줄러에 락을 적용하면 된다!
공교롭게도.. 세 가지 모두 실시간으로 60초마다 실행되기 때문에 스케줄 락 설정에 많은 고민이 필요하지는 않았다.
@Scheduled(initialDelay = 1000, fixedRate = 60000)
@SchedulerLock(name = "alarmScheduler_scheduleAlarmsInOrder", lockAtLeastFor = "55s", lockAtMostFor = "2m")
public void scheduleAlarmsInOrder() {
reservationAlarmService.checkReservations();
alarmSender.processAlarms();
}
🔍 @SchedulerLock 속성 설명
| 속성 | 설명 |
|---|---|
name | 락을 구분하는 고유 이름 (shedlock.name 컬럼에 저장됨) |
lockAtLeastFor | 최소 락 유지 시간 → 메소드간의 시간차이 정함. PT5M 은 최소 5분간 이 락을 홀드하겠다는 의미 잠금을 유지해야 하는 기간을 지정하는 속성 |
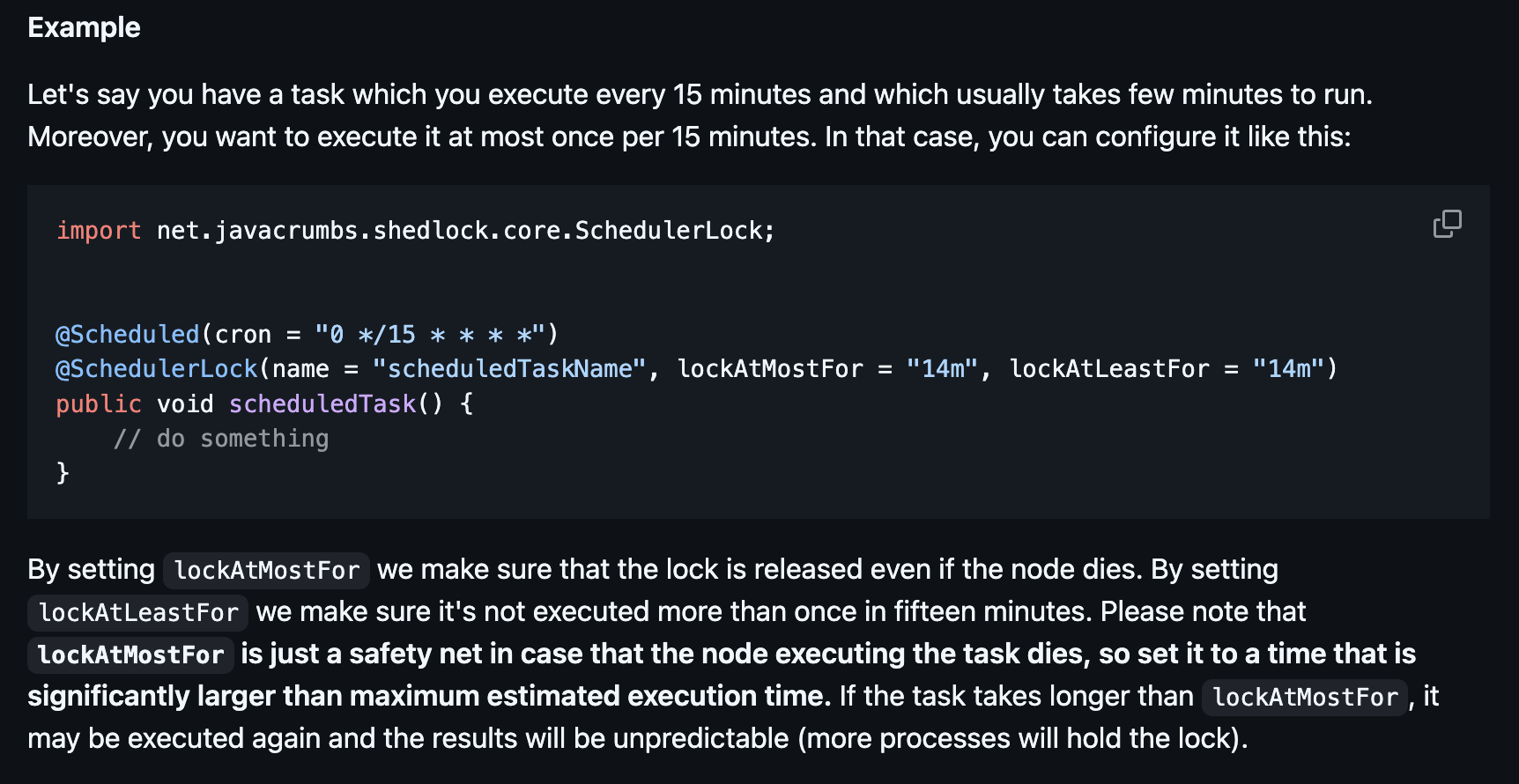
lockAtMostFor | 최대 락 유지 시간 → 실행 노드가 죽었을 때 이 락이 얼마나 길게 유지되어야 하는지를 특정함 잠금을 유지해야 하는 최소 시간을 지정하는 속성 |
처음 스케줄러가 시작되면 lockAtMostFor로 시간이 잡히고,
-
이상태에서 lockAtLeastFor값이 없다면
-> lock_until = 해당 스케줄러의 종료시간이 됨 -
lockAtLeastFor이 있다면
-> lock_until은 해당 스케줄러의 시작시간 + lockAtLeastFor가 됨
즉 lockAtMostFor는 모종의 이유로 스케줄러에서 에러가 나거나 시간이 오래걸릴때 다른 스케줄러가 기다려주는 시간이고
lockAtLeastFor는 해당 스케줄러가 시작되고 난후 최소한 기다려주는 시간이다.
‼️ 만약 lockAtMostFor값이 lockAtLeastFor보다 작다면 에러가 발생한다 ‼️
이에 대한 설명도 ShedLock Github에 자세히 나와으니 참고하길 바란다.
➡️ 현재 프로젝트의 스케줄러들은 1분(60초)마다 실행되므로,
최소 락 유지 시간은 55초로 설정해주었다. (겹치지 않도록)
최대 락 유지 시간은 작업 시간보다 넉넉하게 2분으로 설정하여 예외나 장애가 있어도 최대 2분 후 락이 해제되도록 설정해두었다.
🪄 락이 적용되어 한 인스턴스만 스케줄링 작업하는 모습
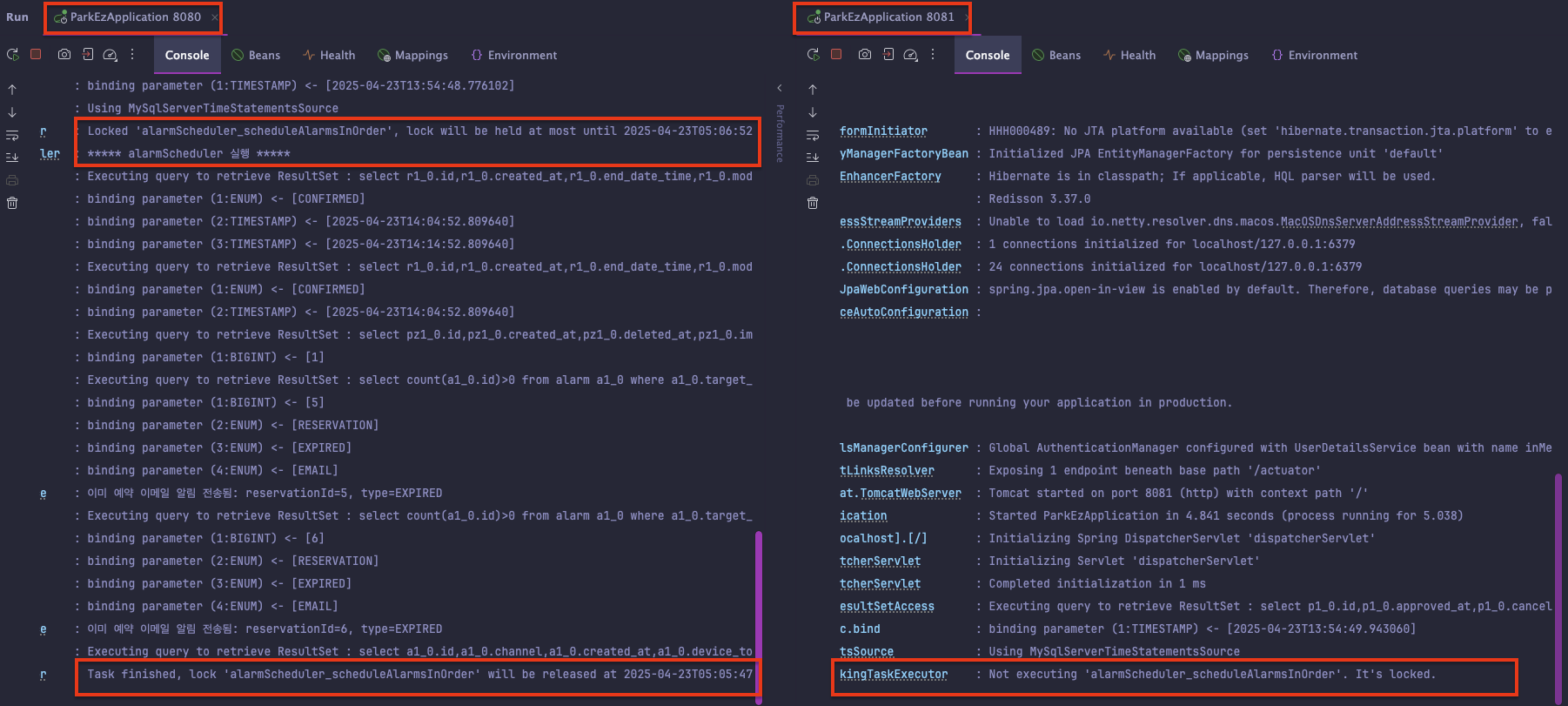
🪄 나머지 스케줄러에도 차례로 적용하면‼️
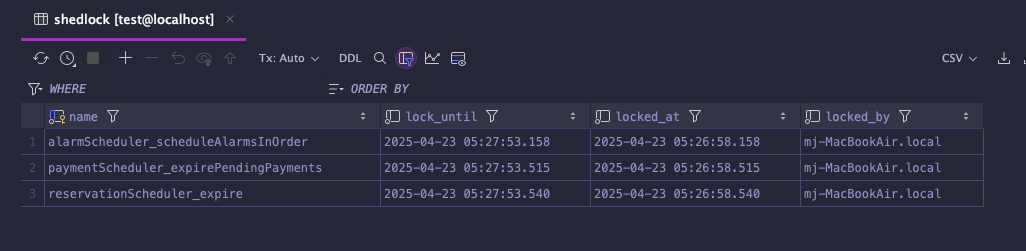
🪄 shedlock 테이블에 name과 timestamp가 기록되는 모습
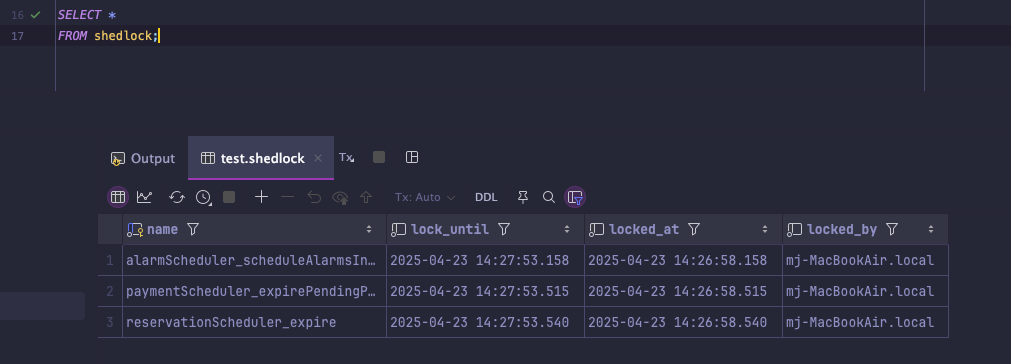
🪄 만약 락이 선점되어 있는 서버를 종료시켜 본다면?
현재 8080 서버가 락을 선점하여 계속 8080 서버에서 스케줄러가 돌아가고 있다.
예기치 못한 에러를 가정하고 8080 서버를 종료시켜 본다면
➡️ 2분 뒤, 최대 락 유지 시간이 끝나서 락이 해제되고
8081 서버가 스케줄링 작업을 이어받아 진행하게 된다!
참고사항
로그에 락 선점 및 스케줄러 실행 내역을 확인하고 싶다면?
logging: level: net.javacrumbs.shedlock: DEBUGapplication.yml파일에 다음과 같이 추가하면 된다.
📁 내 프로젝트에 적용한 스케줄러 목록
| 스케줄러 이름 | 락 이름 | 주기 | 최소 락 시간 | 최대 락 시간 |
|---|---|---|---|---|
| 알람 처리 | alarmScheduler_scheduleAlarmsInOrder | 매 60초 | 55초 | 2분 |
| 예약 만료 처리 | reservationScheduler_expire | 매 60초 | 55초 | 2분 |
| 결제 만료 처리 | paymentScheduler_expirePendingPayments | 매 60초 | 55초 | 2분 |
💡 트러블슈팅: 락 선점 실패 이슈
처음에는 initialDelay = 1000으로 설정해두었으나,
멀티 인스턴스 환경에서 두 서버가 거의 동시에 실행을 시도하며
두 서버 모두 락 선점에 실패하고 스케줄링 작업을 진행하는 현상이 발생했습니다.
이를 해결하기 위해 initialDelay = 5000으로 조정하여
한 인스턴스가 먼저 락을 선점할 수 있도록 여유를 두었습니다.
@Scheduled(initialDelay = 5000, fixedRate = 60000)
@SchedulerLock(name = "...", lockAtLeastFor = "55s", lockAtMostFor = "2m")이후엔 문제없이 한 인스턴스만 스케줄러를 실행하게 되었고,
shedlock 테이블에도 정상적으로 락 정보가 기록되었습니다.

🙋♀️ 궁금했던 점
❓ 1. shedlock 테이블의 시간이 왜 9시간 느리게 찍히는지?
기본적으로 shedlock은 UTC 기준 시간으로 TIMESTAMP를 저장함
한국 시간(KST)과 9시간 차이가 나며, 이를 해결해보고자 여러 방법을 시도해봄
# application.yml
spring:
datasource:
url: jdbc:mysql://localhost:3306/<db이름>?serverTimezone=Asia/Seoul
또는 MySQL에서 직접 세션 타임존 설정:
SELECT @@time_zone; -- 현재 타임존 확인
SET time_zone = 'Asia/Seoul'; -- 변경
하지만.. 둘 다 소용이 없었고 찾아보니!
| 항목 | 설명 |
|---|---|
| shedlock 테이블 컬럼 | TIMESTAMP → MySQL 내부적으로 UTC로 저장 |
| DATETIME 컬럼일 경우 | JVM 타임존 기준 그대로 저장됨 |
| JDBC serverTimezone 옵션 | Java ↔ MySQL 간 시간 파싱/포맷에만 적용, DB 내부 저장 포맷은 그대로일 수 있음 |
라고 한다.
즉, TIMESTAMP는 MySQL이 강제로 UTC로 변환해서 저장함.
🎯 진짜로 "한국 시간대로 저장"되게 하려면?
🔄 방법 1: TIMESTAMP → DATETIME으로 변경
ALTER TABLE shedlock
MODIFY lock_until DATETIME(3) NOT NULL,
MODIFY locked_at DATETIME(3) NOT NULL;
✅ DATETIME은 JVM 타임존 그대로 저장되므로 Asia/Seoul이면 그 값 그대로 DB에 들어감🔄 방법 2: 그냥 UTC 저장은 허용하고 조회 시 변환
사실 테이블에 저장은 UTC로 되지만,
실제 SELECT 문으로 조회를 해보면
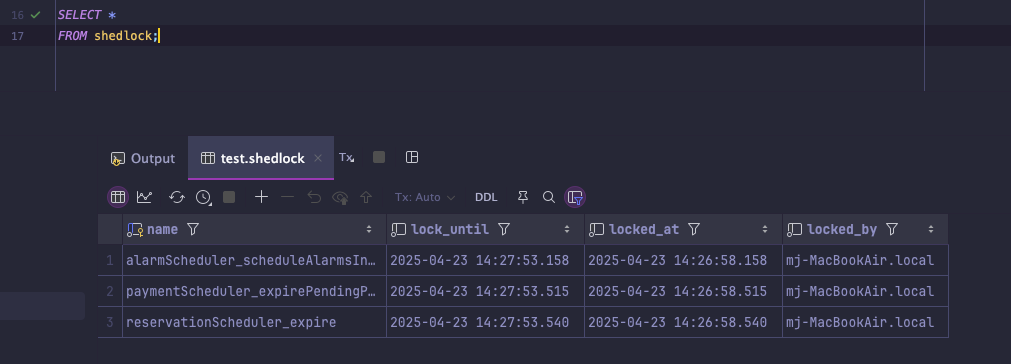
한국 시간으로 잘 조회되는 것을 볼 수 있다‼️
그래서 나는 별도의 설정 없이 두기로 결정하였다.
❓ 2. shedlock 테이블의 row는 시간이 지나면 삭제되는지?
삭제되지 않는다.
shedlock 테이블은 락 이름(name)을 기준으로 row를 1개만 유지됨
실행 시마다 lock_until, locked_at 값만 업데이트된다.
❓ 3. locked_by 값은 어디서 오는지?
locked_by는 락을 획득한 인스턴스의 호스트 이름 또는 IP이다.
나도 로컬 환경에서 테스트해보았기 때문에 아래와 같이 뜨는 것을 볼 수 있다.
운영 환경에서는 EC2의 내부 hostname이 될 수 있다.
❓ 4. 개발 서버에서도 shedlock 테이블을 따로 만들어야 하나?
DB가 분리되어 있다면 정답이다!
운영과 개발 DB를 따로 쓴다면 개발 DB에도 shedlock 테이블을 생성해줘야 한다.
테이블 생성은 위에 작성한 명령어와 동일하게 작성해주면 된다.
