
영속성 컨텍스트란?
엔티티를 영구저장하는 환경을 의미
EntityManager.persist(entity) 명령어를 통해서 entity를 영속성 컨텍스트에 집어 넣을 수 있습니다.
영속성 컨텍스트는 논리적인 개념입니다. 따라서 눈에 보이지않고 엔티티 매니저를 통해서 접근할 수 있습니다.
J2SE 환경에서는 엔티티 매니저를 생성하면 영속성 컨텍스트가 1:1로 매핑되어 생성됩니다.
엔티티의 생명주기
엔티티의 생명주기에는 크게 4가지가 존재합니다.
비영속
영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
영속
영속성 컨텍스트에 관리되는 상태
준영속
영속성 컨텍스트에 저장되었다가 분리된 상태
삭제
삭제된 상태
비영속

비영속 상태란?
JPA와 관계없이 객체만 생성한 상태입니다.
1 2 3 | Member member = new Member(); member.setId("member1"); member.setUsername("회원1"); | cs |
영속

영속 상태란?
영속성 컨텍스트 안에 객체가 들어가 있는 상태입니다.
1 2 3 4 5 6 7 8 | Member member = new Member(); member.setId("member1"); member.setUsername("회원1"); EntityManager em = emf.createEntityManager(); em.getTransaction().begin(); em.persist(member); | cs |
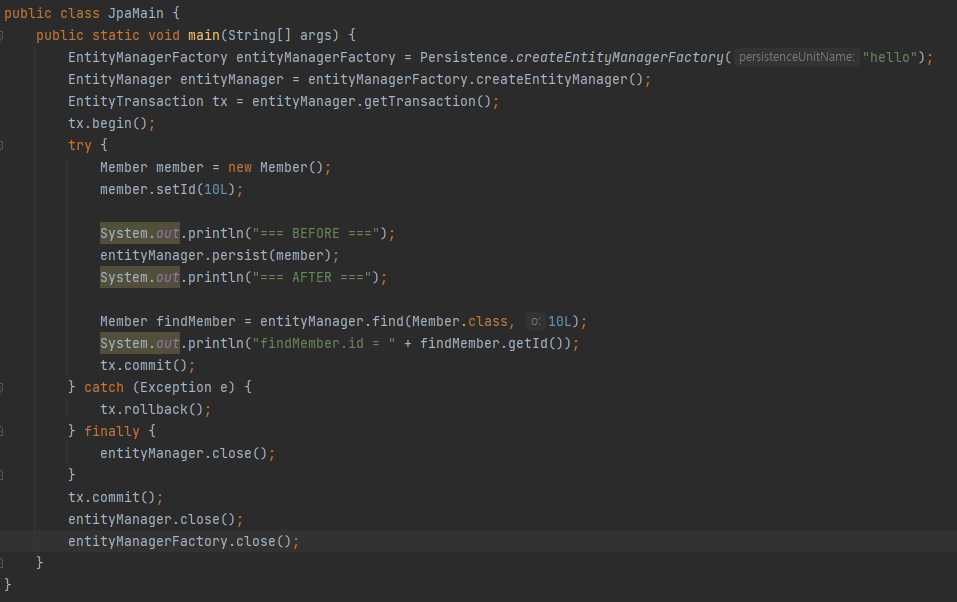
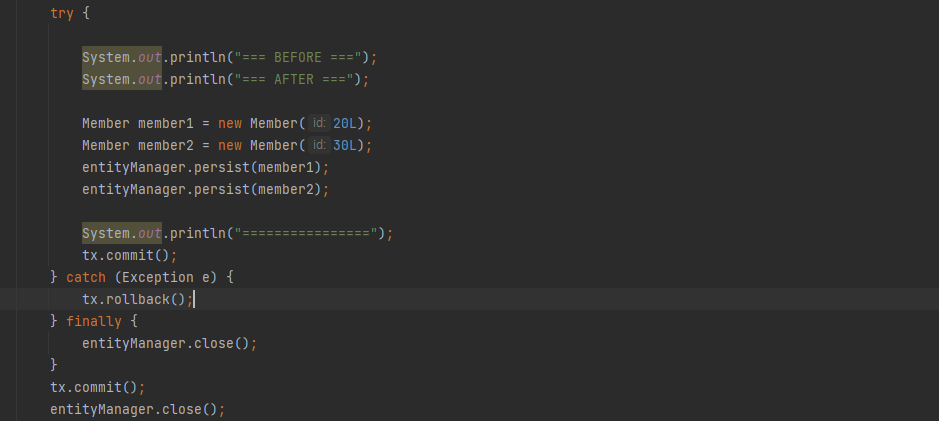
실제 코드를 실행시켜서 확인해보겠습니다
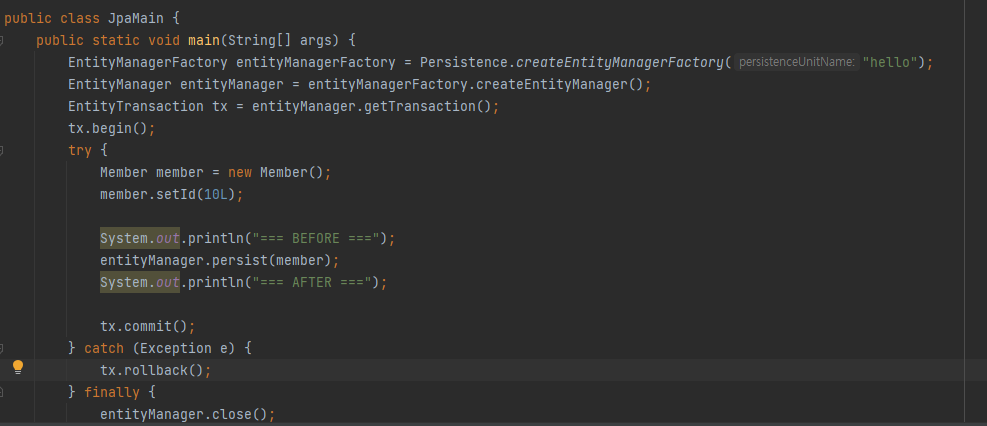
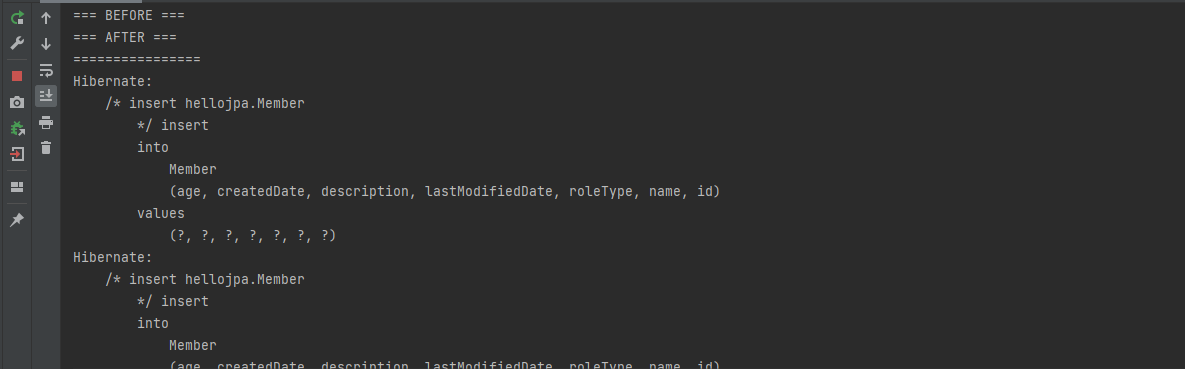
BEFORE와 AFTER 사이에 아무 쿼리문이 동작 안하는걸 확인할 수 있습니다
준영속
맴버 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
em.detach(member);
객체를 삭제한 상태
em.remove(member);
영속성 컨텍스트의 이점
영속성 컨텍스트에 대해서 러프하게 알아봤는데, 그러면 DB로 커밋하기전에 영속성 컨텍스트라는 개념을 하나 추가해서 복잡해진 메커니즘을 통해 얻을 수 있는 것이 무엇일까요?
바로 아래와 같습니다.
1. 1차 캐시
2. 동일성 보장
3. 트랙잭션을 지원하는 쓰기 지연
4. 더티 체킹
5. 지연 로딩
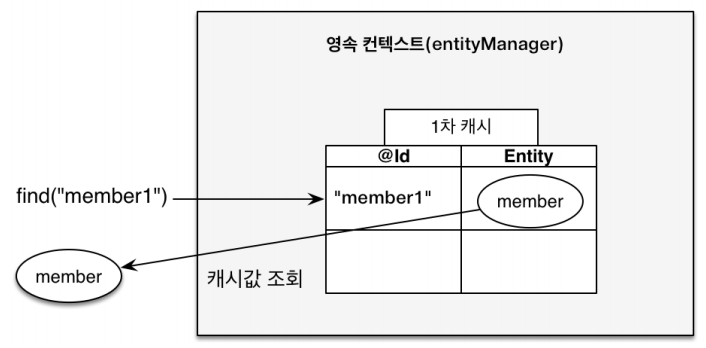
1차 캐시
크게 봤을 때 1차 캐시를 영속성 컨텍스트로 이해해도 될 것 같습니다.
1 2 3 4 5 6 7 | Member member = new Member(); member.setId("member1"); member.setUsername("회원1"); //1차 캐시에 저장됨 em.persist(member); //1차 캐시에서 조회 Member findMember = em.find(Member.class, "member1"); | cs |
member1을 영속성 컨텍스트에 넣고 다시 find하면 db에 쿼리문을 날리는게 아니라 1차 캐시에서 가져오게 됩니다.
하지만 1차 캐시에 존재하지 않는다면 아래와 같이 DB에서 조회하게 됩니다.
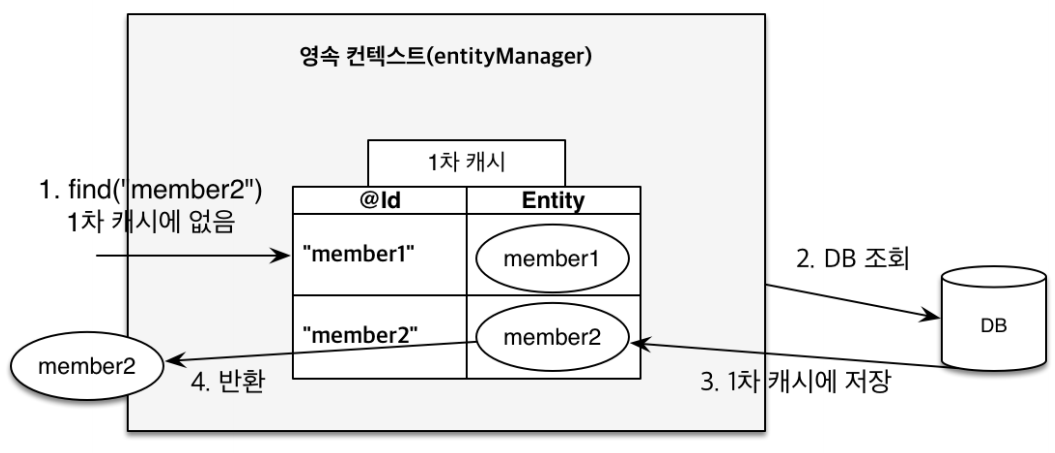
하지만 사실 트렌젝션이 종료되면서 엔티티 메니저도 같이 종료되기 때문에 트렌젝션 내부에서 member를 다시 찾을때만 성능상의 이점을 나타낼 수 있습니다.
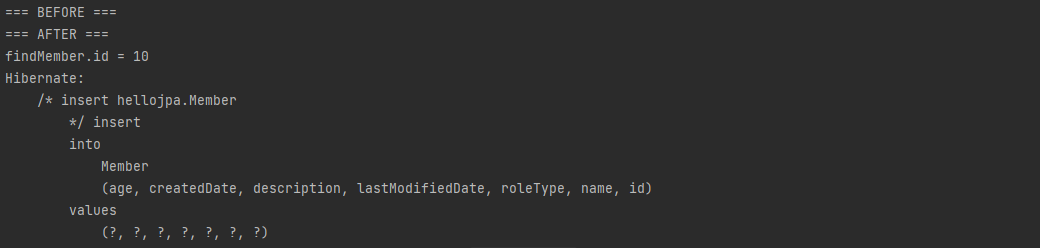
AFTER 이후에 find 메소드를 호출했음에도 불구하고 디비로 쿼리문이 안날라가는것을 확인할 수 있는데, 1차 캐시에서 가져오기 때문입니다.
하지만 아래와 같이 20L ID를 가지고 있는, 영속성 컨텍스트에 존재하지 않는 엔티티를 찾으려고하면 디비에 select 쿼리문을 날리게 됩니다.
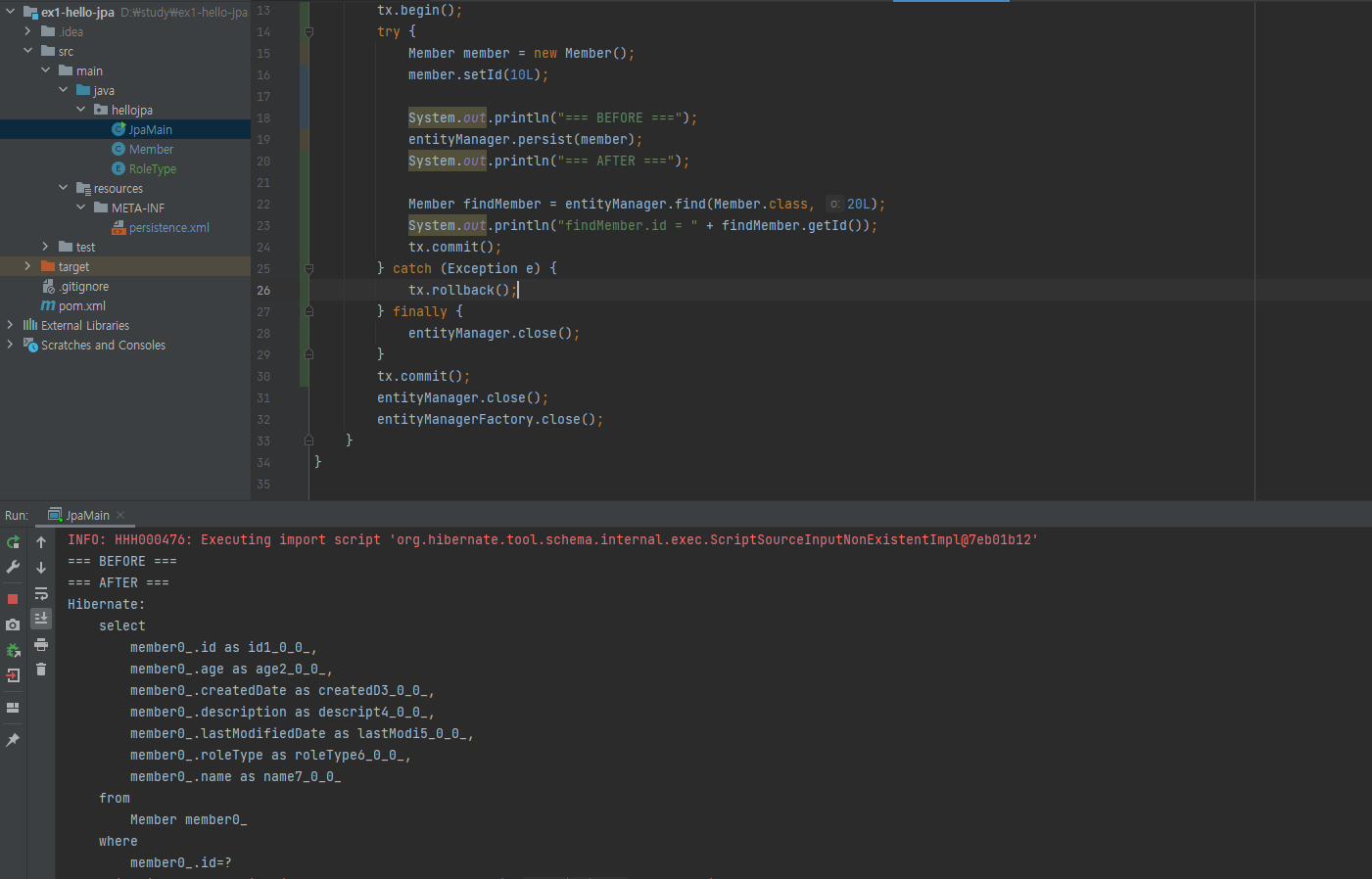
동일성 보장
1차 캐시로 부터 조금이지만 성능상의 이점을 가져올 수 있다는 이점도 존재하지만, 동일성 보장의 이점도 생깁니다.
1차 캐시로부터 가져오기 때문에 true가 반환된 것을 볼 수 있습니다.
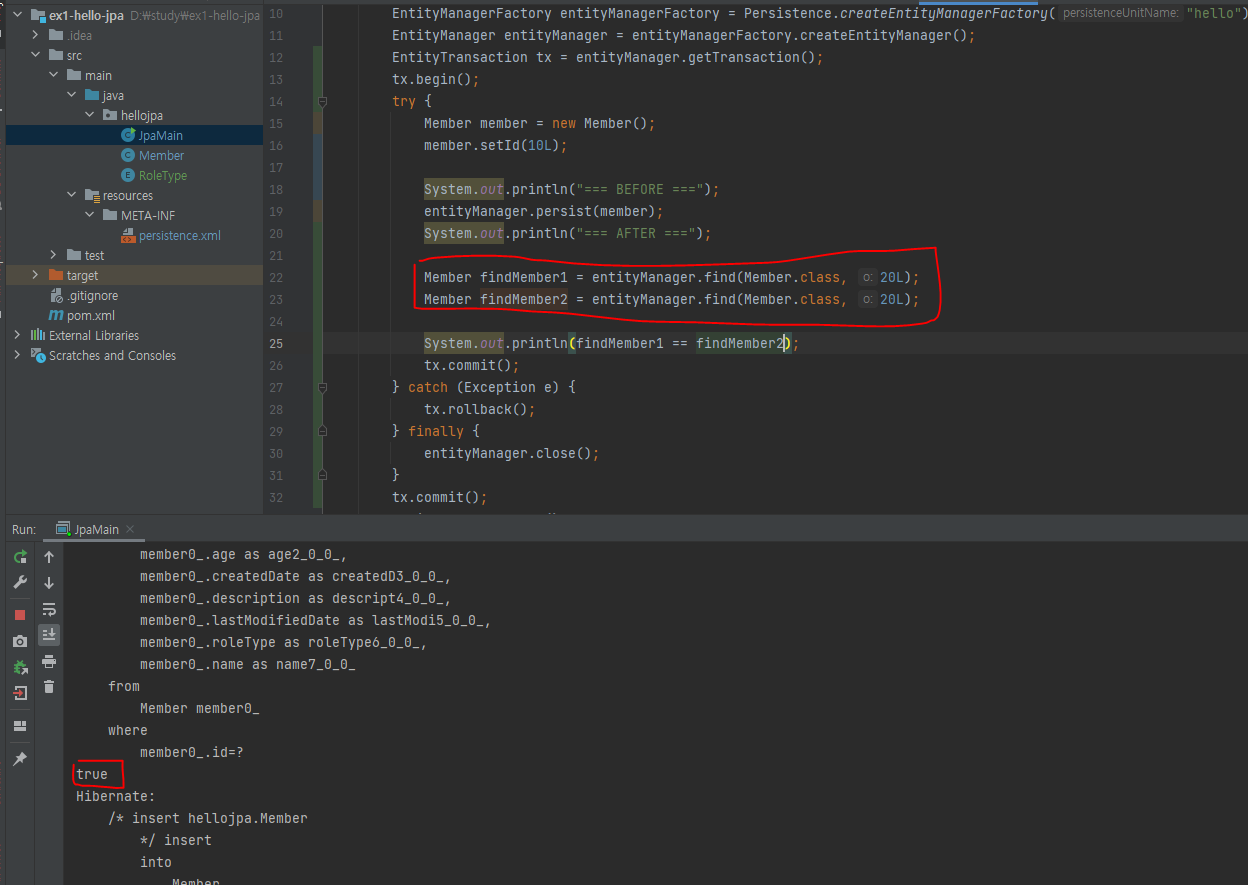
쓰기 지연
마찬가지로 1차 캐시로부터 생기는 메커니즘의 이점으로 쓰기 지연이라는 기능을 활용할 수 있습니다. 쓰기 지연은 em.persist(memberA)라는 메소드를 호출했을 때 바로 insert 쿼리문을 날리는게 아니라, 영속성 컨텍스트에 집어넣고 쓰기 지연 SQL 저장소에 insert 쿼리문을 쌓아둡니다.
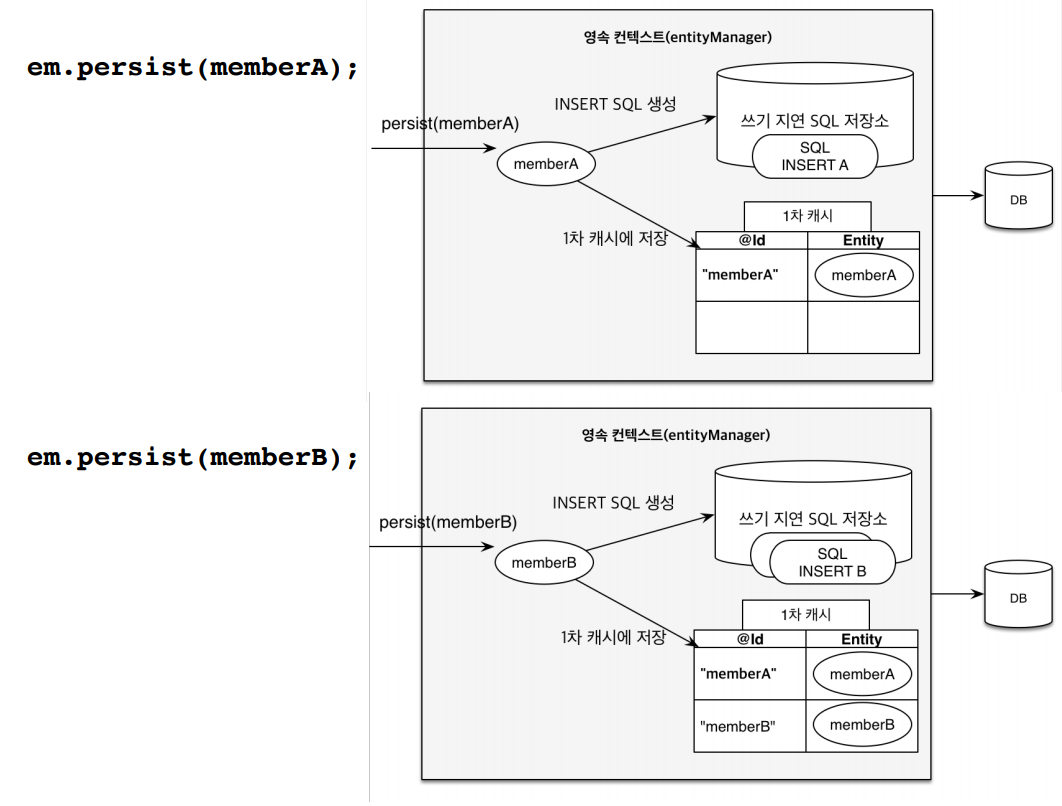
그리고 나서 commit을 실행할 때 쓰기 지연 저장소에 저장된 쿼리들을 한번에 날리게됩니다.
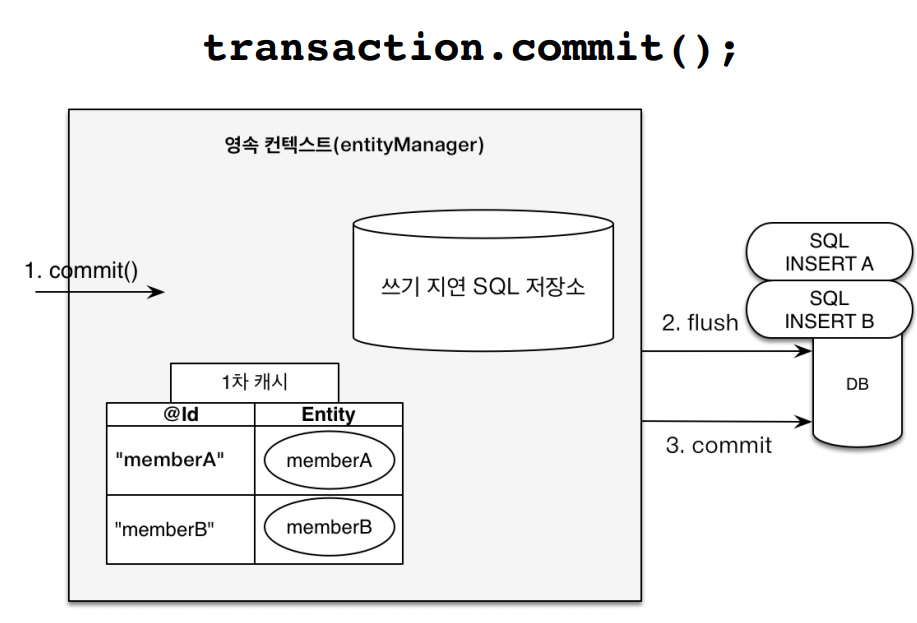
아래 사진에서 확인해보면, =============== 밑으로 쿼리문들이 발생하는것을 볼 수 있습니다.
persist 할 때 쿼리문을 날리지않고 저장소에 보관하다가 한번에 날리게 됩니다.
배치 사이즈를 hibernate 설정으로 몇개씩 담아서 날려줄지 정해줄 수 있습니다.
더티 체킹
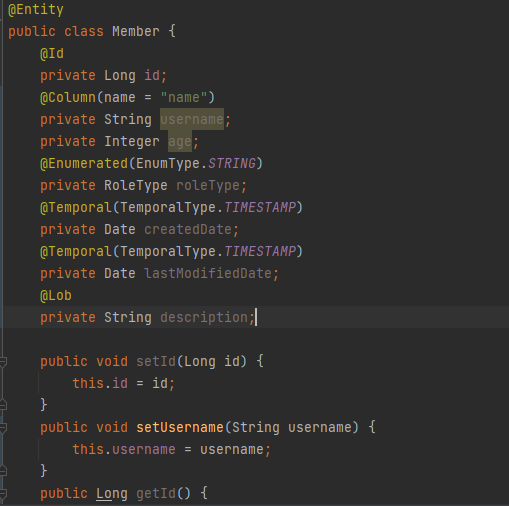
맴버 엔티티에 name을 설정해주고 DB를 확인해보면
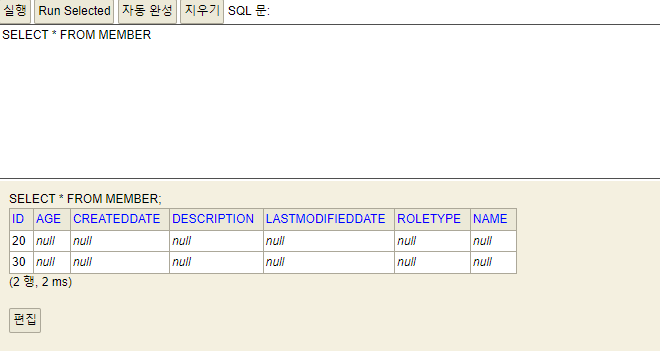
NULL로 들어가있는것을 볼 수 있습니다.
여기에서 ID 20의 엔티티를 꺼내서 객체의 값만 바꿔주고 커밋을 날려보면 아래의 그림처럼 update 쿼리문이 날라가는것을 볼 수 있습니다.
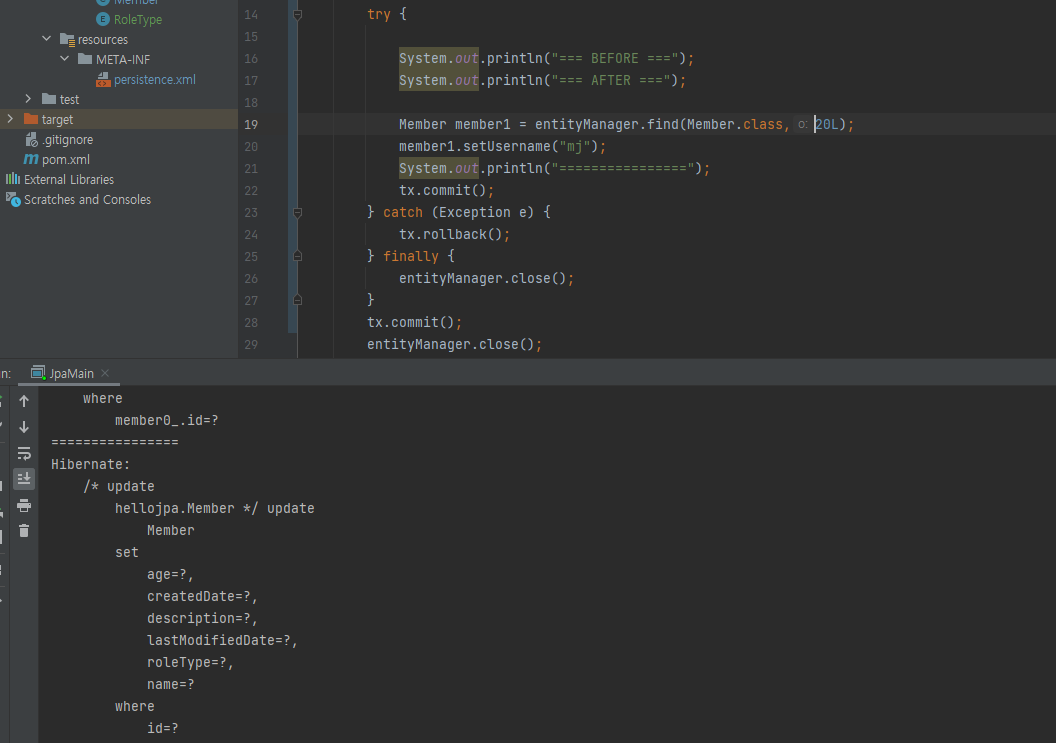
DB안의 값도 바뀐것을 확인할 수 있습니다.

em.update()과 같은 메소드를 실행하지 않아도 JPA가 이를 실행해줍니다.
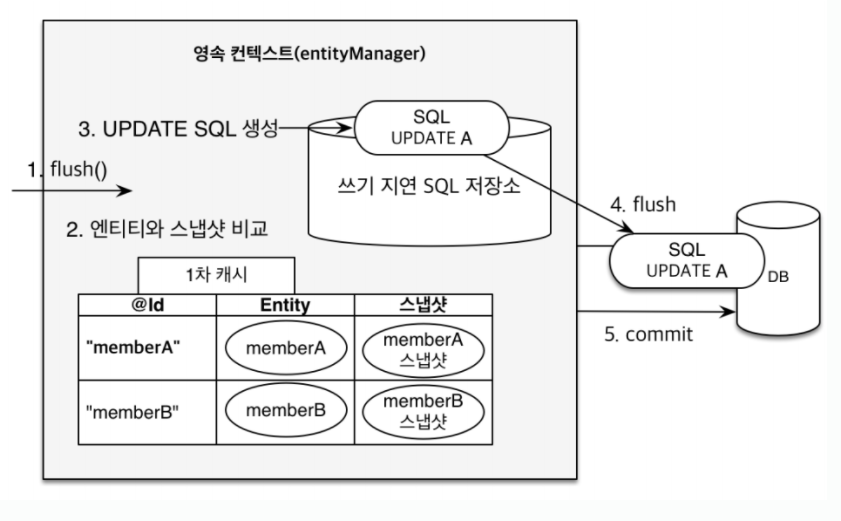
스냅샷이란 값을 DB에서 처음 select했을 때 찍어두는 모습입니다.
setUsername을 통해 이름을 바꾸고 커밋 했을 때 내부적으로 플러시라는게 호출이 됩니다. 그러면 스냅샷과 엔티티의 값을 비교하는데 내부적으로 다르다면 update 쿼리를 만들어서 쓰기 저장소에 저장합니다. 그 뒤에 다시 업데이트 내역을 플러시로 디비에 반영하고 커밋을 날리게됩니다.
https://www.inflearn.com/course/ORM-JPA-Basic
김영한님의 강의를 토대로 작성한 글입니다.
