
1. Task Description
LLM이 작성한 science exam multiple choice 문제를 푸는 것 (5개 중에서 정답은 1개)
2. 문제 해결 접근 방법
- [read model만 사용하기] 약 300M 이하의 인코더 / 혹은 인코더-디코더 모델을 fine-tuning 하여 성능 향상하기 (training 용 데이터셋 필요)
- 여기서 디코더 모델을 제외한 이유는, 그동안 연구해보았을 때 작은 모델의 경우 디코더 보다는 인코더-디코더에서 성능이 더 좋게 나오는 것을 경험하였기 때문
- [retrieval-augmented model 사용하기] open-book 시험의 상황을 만들어 주는 것! external knowledge (wikipedia 등) 에서 관련있는 문서를 찾아와서 그걸 기반으로 문제를 풀 수 있도록 하는 것
3. 베이스라인 올려보기
1) flan-t5-base model (인코더-디코더)
- 참고한 베이스라인 노트북: Science Exam Simple Approach w/ Model Hub
- 해당 노트북은 flan-t5-base에서 따로 튜닝을 하지 않고 in-context learning (prompt engineering) 으로 답안을 제출하며 성능을 확인하고 있음
- 47.4% 달성 → 따로 튜닝을 전혀 하지 않았고, 랜덤으로 top3를 정한 것에 비해서는 성능이 잘 나옴. 이 모델을 read model의 backbone으로 사용하면 성능향상이 이루어질 여지가 있음
- 개선 방향성
- fine-tuning
- top3의 정답을 넣어주는 것이 아닌, 1개의 정답을 뽑은 다음에, 나머지는 랜덤으로 넣어주는 방식
- 디코딩 전략 : 알파벳 bias 없애기 / 모델 앙상블 majority vote
2) BERT (인코더)
- 참고한 베이스라인 토느북 Starter Notebook: Ranked Predictions with BERT
- 해당 노트북은 bert-uncased-base에서 400개의 주어진 example로 튜닝을 하여 성능을 확인하고 있음
- AutoModelForMultipleChoice 를 통해서 구현하고 있음 (입력 값이 [CLS] Q [SEP] A1 / [CLS] Q [SEP] A2 …로 쌓은 다음에 정답이 무엇인지 라벨값의 인덱스를 넣어서 튜닝하는 방법
- bert뿐 아니라 모든 인코더 노트북에 활용할 수 있는 기본 알고리즘으로 보임
- logit 값을 사용해서 가장 possible 한 answer top 3를 뽑아냄
- 49.8% 달성 → 더 큰 모델, 성능이 좋다고 알려진 인코더 모델을 가져왔을 때 성능 향상의 여지가 있음
- 개선 방향성
- fine-tuning
- 디코딩 전략 : 알파벳 bias 없애기 / 모델 앙상블 majority vote
- Sequential classification 으로 lineary layer 한 개만 쌓아서 돌리면 또 다를까?
3) Retrieval-augmented model
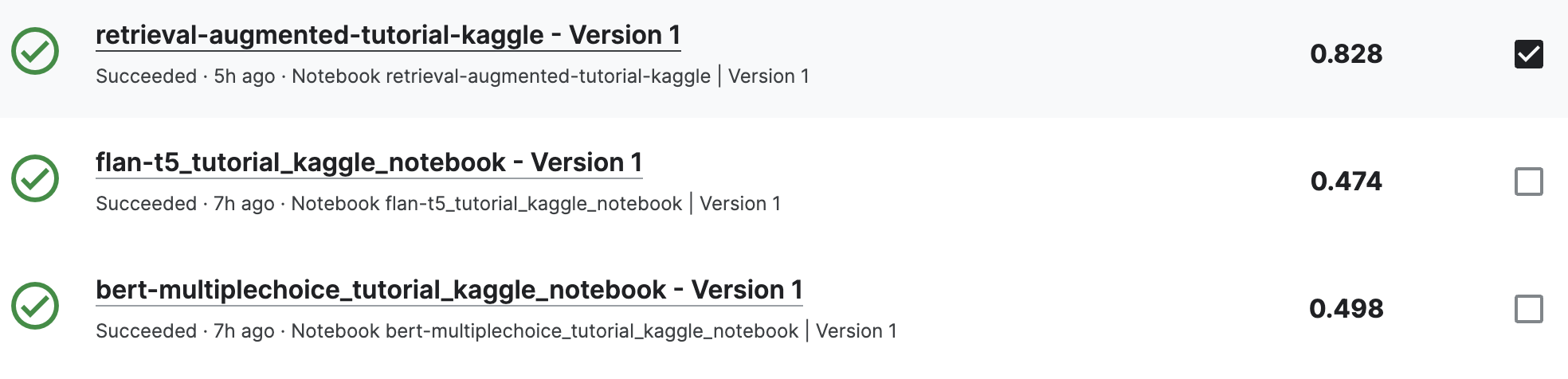
- 참고한 베이스라인 노트북1 (80.6) → 제출했을 때는 82.8이 나왔음 (튜토리얼로 조금 고쳤는데, passage 더 넣어준 것이 성능 향상을 가져온 것 같기도 하다.) LLM Science Exam-Fork of Fork of Fork of [0.806]
- 참고한 베이스라인 노트북2 (83.1) LLm Science(cut fragment length)
- 참고한 베이스라인 노트북3 (82.8) 📚Science Exam Prediction.ipynb 🧪
- 해당 노트북은 Faiss의 wiki index를 이용하여 open book으로 external knoweldge를 가져오고 그 context를 가지고 read model이 정답을 산출하도록 하고 있다.
- read model은 인코더 계열 모델들로 사용하고 있으며, 학습 데이터도 context를 같이 넣어준 다음에 finetuning 하는 방식으로 이루어지고 있다.
- external knowledge를 사용하는 것은 현재로써는 900등 안에 들기 위해서는 거의 다 이 방식을 사용하고 있는 것으로 보임.
- 개선 방향
- 현재 query를 question과 all answer를 다 가지고 하고 있어서 OOM 에러가 나거나, 성능이 떨어지는 문제가 있을 것으로 보인다. → query를 잘 작성한 다음에 다시 임베딩 하는 방식을 시도할 수 있다.
- sentence transformer를 다른 걸 가져다 쓰는 것으로 생각해볼 수 있다.
- context를 얼마나 넣을지, 하이퍼파라미터의 튜닝도 들어가는 것이 필요할 것으로 보임.
4. 제출 결과

NLP 엔지니어,,,,? 가 될 수,,,? 나도,,,,?