Abstract
- retrieval-augmented encoder-decoder langauage model의 in-context learning ability 를 조사한다.
- ATLAS 모델을 탐구하면서 in-context learning 프롬프트와 pretrain method의 mismatch를 해결하기 위하여 prefix modeling으로 다시 pretrain 하였고,
- 또한 Fusion-in-Context Learning 으로 더 많은 fewshot example을 넣을 수 있게 함
- RAVEN 이 ATLAS 보다 좋은 성능을 보이는 것을 확인하였음
1. Introduction
- 연구 배경
- LLM이 등장하면서 task-specific fine-tuning을 안 해도 되는 시대가 왔다.
- 그리고 in-context learning이 특히 디코더 계열 모델(GPT)에서 각광받아왔지만, stronger representation을 만들어내는 인코더-디코더 계열 모델 (T5) 에서는 연구가 덜 되어 왔다.
- 또한 LLM이 Hallucination 문제나 recent knowledge를 반영하지 못한다는 것에서 기인하여 Retrieval-augmented language model이 나왔다.
- 해결하고자 하는 문제
- SOTA인 ATLAS의 in-context learning 성능이 좋지 못했고, 이는 pretrain과 testing 상황에서의 토큰 길이 차이 / 텍스트 Input-output 차이 등 때문이었다.
- 문제 해결 방식
-
따라서 retrieval-augmented masked language modeling을 prefix modeling과 함께 사용하여 in-context learning의 성능을 높일 수 있는 방법론을 제시하였고
-
또한 Fusion-in-Context Learning을 제시해서 더 많은 example을 few-shot에 넣어줄 수 있게 하였다.
-
그리고 retriever를 relevant in-context examples 을 찾는 데에 사용하여 성능을 더 높일 수 있었다.
→ 이를 통해서 ATLAS를 능가하는 성능은 물론, 디코더 계열의 훨씬 더 큰 모델들의 성능을 넘는 것을 확인할 수 있었다.
-
- main contribution
- SOTA retrieval-augmented model인 ATLAS에 대한 comprehensive analysis를 제공하면서, improvement할 수 있는 부분에 대하여 논의한다.
- RAVEN : retrieval-augmented masked and prefix language modeling 모델을 제시한다.
- Fusion-in-Context Learning 과 In-Context Example Retrieval을 제시해서 few-shot 성능을 높였다.
- 실험을 통하여, RAVEN이 ATLAS 뿐 아니라 다른 큰 디코더 모델들의 성능을 능가하는 것을 보였다.
2. Background and Related Work
- In-Context Learning
- decoder 모델에서 주로 연구되어 왔지만, bi-direction으로 학습하는 BERT나 T5 같은 모델에서도 도움이 되는 것을 확인하였다.
- 또한 similar scale에서는 bidirectional model들이 decoder-only LM 을 outperform하는 incontext learning ability를 보여준 바도 있다. (그러나 크기가 큰 모델들로 갈수록, decoder 계열 모델이 성능이 좋아진다는 것을 확인할 수 있다.)
- Retrieval-Augmented Language Models
- incorporating external knowledge
- encoder-decoder 계열 모델 / decoder 계열 모델들이 등장하였으나, multiple retrieved passage를 넣어주는 것에는 encoder-decoder 계열 모델이 효율적이기 때문에, 이를 바탕으로 논문을 전개할 것이다.
3. In-Context Learning with ATLAS
- ATLAS는 general-purpose dense retriever와 sequence-to-sequence reader (Fusion in Decoder 방식을 사용한) 로 이루어진 SOTA 모델이다.
- retriever : contriever로, wikipedia와 같은 곳에서 relevant document를 가져온다.
- reader: retrieved passages가 들어와서, masked span을 생성하게 한다.
- 그러나 ATLAS는 few-shot example로 finetuning을 해야 한다는 단점이 있다.
- 특히 요즘과 같이 dynamic 하고 diverse한 real-time query를 GPT에 넣어서 쓰는 시대에는, in-context learning 만으로 어떤 성능을 낼 수 있는지 확인을 하는 것이 필요하다.
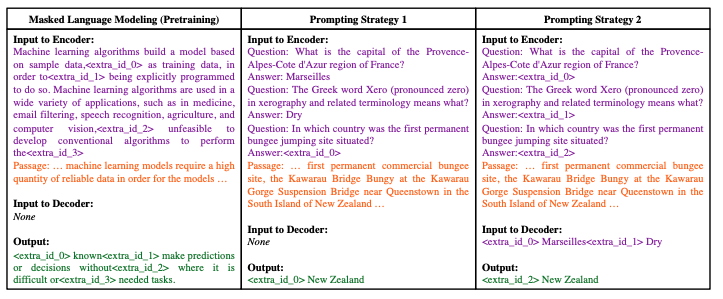
3.1. Prompting Strategies
- in-context learning 에서는 effective prompting 을 사용하는 것이 무엇보다 중요하다.
- Strategy 1. 마지막에 target question을 encoder에 넣고, output으로 그 대답을 생성하게 하는 것
- Strategy 2. few-shot example에 대한 정답을 decoder input에 넣고 output으로 target question에 대한 정답을 생성하게 하는 것
- 성능은 Strategy1이 더 좋았음. 그리고 atlas의 pretrain 된 method나 방식이 in-context leanirng으로 사용하기에 align이 맞지 않아서, 이를 개선할 필요가 있다는 것을 알게 됨.
3.2. Experimental Setup
- Natural Questions와 TriviaQA를 사용하였음. (index가 조금 시기가 다르긴 하다만, 둘다 위키피디아 소스를 사용한다.)
- EM metric으로 얼마나 맞추는지 확인하였을 때,
- 실험해본 결과, S1이 성능이 더 좋았기 때문에 S1을 가지고 프롬프팅을 진행하게 됨
3.3. Results & Analysis
3.3.1. Effect of prompting strategies
- Strategy 2 가 pretrain에서 본 것과는 많이 다른 형식이라서 성능이 더 떨어지는 것으로 보았음
3.3.2. Effect of number of in-context examples
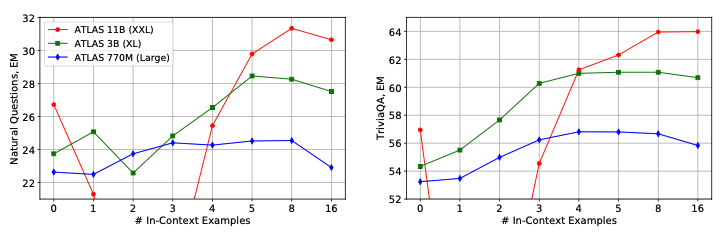
- 몇 개의 example을 넣을 것인지는 in-contextlearning에서 중요한 하이퍼 파라미터이다.
- 그러나 pretrain 과정에서의 token limit이 512였기 때문에, 넣을 수 있는 few-shot examples 의 개수의 한계가 있다.
- 각 모델에 대하여 최적의 exapmle의 수는 다른 듯 하다. 예를 들어, TriviaQA는 PaLM에서 1-shot이 더 많은 example보다도 더 좋은 성능을 나타냈다. (GPT 에서는 그렇지 않았다.)
- ATLAS에서 분석했을 때는, 4나 5shot 부터 성능이 좋아지기 시작했고, low-shot setting에서는 토큰을 더 많이 생성하는 경향때문에 성능이 더 떨어지는 것으로 볼 수 있었다.
3.3.3. Effect of position
- Position에 관해서는 target question이 가장 마지막에 있는 것이 성능이 가장 좋았다.
3.3.4. Effect of number of retrieved passages
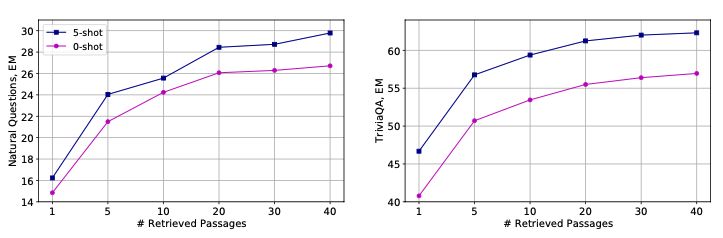
- FiD 덕분인지, retrieved passages가 더 많을 수록 성능이 올라가는 것을 확인할 수 있었다.
- 이걸 보면, decoder 계열과는 또 다르게, Encoder-decoder에서는 recall만 높게 나오고, 관련있는 것이 많이 들어갈 수록 성능이 또 높아진다고 생각할 수 있음. 그러나 NQ, TriviaQA가 성능이 높게 나오는 것에 관하여는 얘네가 위키백과에서 가져오는 거니까 거기에는 워낙 relevant한 것들이 많아서 다 나름 관련있는 것들이 들어와서 그럴 수도 있다고 생각함.
3.3.5. Summary
- low shot setting에서의 성능이 unstable하다는 것, More in-context example이 consistent한 성능을 보장하지는 않았다는 것
- FiD의 장점으로 인하여 많은 passage를 retrieved한 것이 성능 향상에 도움이 되었다는 점
4. Methodology
4.1. RAVEN : Combining Retrieval-Augmented Masked and Prefix Language Modeling

- ATLAS에 continually pretrain을 prefix language modeling으로 진행함. (in-context로 테스팅 하는 과정과 align을 맞추기 위하여)
- 10% 뒤쪽을 잘려서 <extra_id_0> 으로 묶는다.
- 이를 통해 pretraining objective나 prompting strategy와 비슷해졌기 때문에, 성능이 향상될 수 있다.
- 이것을 additional prefix language modeling 이라고 부른다.
- ATLAS의 checkpoint에서 시작하여, 추가적으로 pretrain을 한 것인데, UL2와 다른 점은
- 1) UL2는 training obejctive를 한 번에 함에 있어서 섞어서 사용한 데에 비해, 이미 train 되어 있는 것에 추가적으로 2개의 objective를 sequential order로 학습했다는 것이 다르다.
- 2) 또한 UL2는 retrieval없이 train 했다는 것이 다르다.
- 학습을 한 번 더 하면서, MLM의 장점을 가져가면서도 in-context learning을 가능하게 했다.
- 여기서 학습할 때는 retriever는 그대로 두고, reader만 파라미터 업데이트를 했다.
4.2. Fusion-in-Context Learning
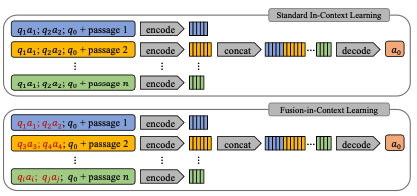
- pretrain length 때문에 long sequences가 Testing에서 잘 작동하지 않는 경향이 있다.
- 따라서 모델이 더 많은 In-context learning example을 볼 수 있도록, FiCL을 제시했다.
- FiD는 passage를 여러개 섞어서 넣어주는 방식이었다면, FiCL은 few-shot example 들을 많이 넣어준다는 점에서 다르다.
- [k shot, m-fusion] 으로 앞으로 논문에서 표현할 것
4.3. In-Context Example Retrieval
- 학습된 Retriever를 in-context example을 찾아오는 데에 사용했다.
- 1) automatic하게 DB에서 Example을 찾아오기 때문에 in-context example을 Manually 하게 넣어주지 않아도 된다는 장점이 있고, 2) in-context example의 selection을 optimization하였기 때문에 overall performance를 향상시킬 수 있다는 장점이 있다.
5. Experiments
5.1. Experimental Setup
- Datasets
- Natural Questions
- TriviaQA
- long-form questio에 대한 성능 측정을 위하여 ELI5 dataset
- language understanding 문제를 해결하기 위하여 MMLU benchmark
- baselines
- ATLAS
- GPT-3
- PaLM (closed book)
- REPLUG (contriever, codex)
- RETRO (transformer encoder, GPT)
- RETRO++ (RETRO에 추가적인 finetuning)
- Implementation Details
- 3B와 11B checkpoint를 가져와서 추가적으로 학습을 진행하였고
- retriever는 업데이트하지 않고 reader만 학습을 시켰다.
- reader는 wikipedia corpora 2021 12월, 아틀라스와 동일하게 사용하였고,
- 20개의 passage를 가져와서 학습을 했고, 5000step을 더 학습했다.
5.2. Open-Domain Question Answering
- ATLAS와 RAVEN의 성능 비교

- baseline과의 성능 비교, FiCL을 사용하였을 때의 성능 비교
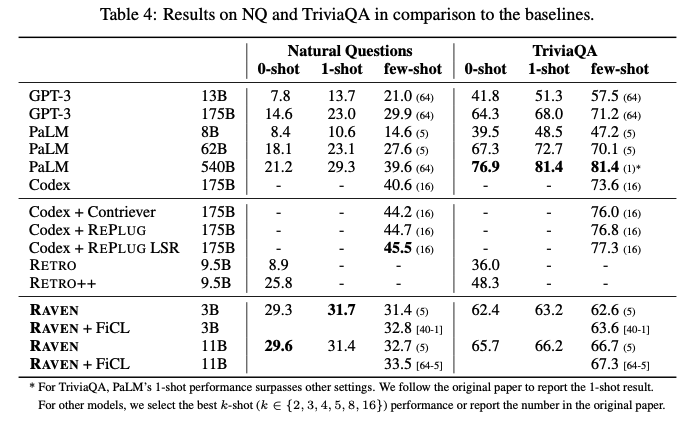
- ablation study
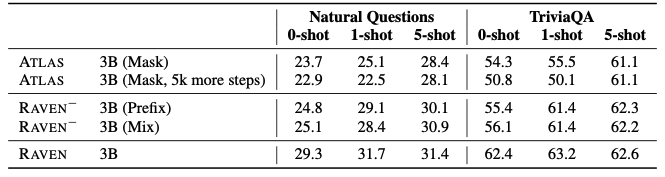
→ RAVEN의 성능 향상이 단지 더 step을 많이 학습시켰기 떄문이 아니라는 것을 보여줌.
- In-Context Example Retrieval
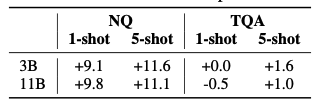
5.3. Massive Multitask Language Understanding
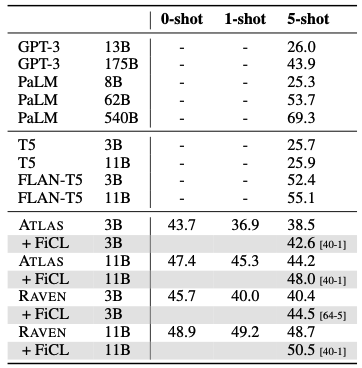
- FLAN-T5의 Instruction finetuning이 성능이 더 향상되는 것을 볼 수 있음 → 앞으로 연구에서 t5대신 flan-t5를 사용하여서 더 좋은 성능을 보일 수 있을 것으로 보임.
6. Conclusion
- retrieval-augmented encoder-decoder language model에 대한 in-context learning ability를 측정하였다.
- ATLAS에 대한 분석을 진행한 것을 바탕으로 성능 향상을 위한 방법론을 제안했고,
- additional prefix-modeling / FiCL / few-shot example retriever로 성능이 향상되었다.
- 이런 발견은 retrieval-augmented encoder-decoder모델이 in-context learning도 가능하다는 것을 보여줬다는 데에 의의가 있으며, 향후 연구를 통하여 더 권장되기를 바란다.

NLP 엔지니어,,,,? 가 될 수,,,? 나도,,,,?