문제
세 개의 단어가 주어졌을때, 꿍은 첫 번째 단어와 두 번째 단어를 섞어서 세 번째 단어를 만들 수 있는지 궁금해졌다. 첫 번째와 두 번째 단어는 마음대로 섞어도 되지만 원래의 순서는 섞여서는 안 된다. 다음과 같은 경우를 생각해보자.
첫 번째 단어 : cat
두 번째 단어 : tree
세 번째 단어 : tcraete
보면 알 수 있듯이, 첫 번째 단어와 두 번째 단어를 서로 섞어서 세 번째 단어를 만들 수 있다. 아래와 같이 두 번째 예를 들어보자.
첫 번째 단어 : cat
두 번째 단어 : tree
세 번째 단어 : catrtee
이 경우 역시 가능하다. 그렇다면 "cat"과 "tree"로 "cttaree"를 형성하는건 불가능하다는걸 눈치챘을 것이다.입력
입력의 첫 번째 줄에는 1부터 1000까지의 양의 정수 하나가 주어지며 데이터 집합의 개수를 뜻한다. 각 데이터집합의 처리과정은 동일하다고 하자. 각 데이터집합에 대해, 세 개의 단어로 이루어져 있으며 공백으로 구분된다. 모든 단어는 대문자 또는 소문자로만 구성되어 있다. 세 번째 단어의 길이는 항상 첫 번째 단어와 두 번째 단어의 길이의 합이며 첫 번째 단어와 두 번째 단어의 길이는 1~200이다.출력
각 데이터집합에 대해 다음과 같이 출력하라.
만약 첫 번째 단어와 두 번째 단어로 세 번째 단어를 형성할 수 있다면
Data set n: yes
과 같이 출력하고 만약 아니라면
Data set n: no
과 같이 출력하라. 물론 n은 데이터집합의 순번으로 바뀌어야 한다. 아래의 예제 출력을 참고하라.정답 코드
import sys
from collections import deque
input = sys.stdin.readline
def bfs(words):
w1, w2, w3 = words
dp = [[0] * (len(w2) + 1) for _ in range(len(w1) + 1)]
dq = deque([(len(w1), len(w2), len(w3))])
while dq:
w1_idx, w2_idx, w3_idx = dq.popleft()
if w1_idx == w2_idx == w3_idx == 0:
return True
elif w3_idx == 0:
return False
if w1_idx > 0 and w1[w1_idx - 1] == w3[w3_idx - 1] and dp[w1_idx - 1][w2_idx] == 0:
dp[w1_idx - 1][w2_idx] = 1
dq.append((w1_idx - 1, w2_idx, w3_idx - 1))
if w2_idx > 0 and w2[w2_idx - 1] == w3[w3_idx - 1] and dp[w1_idx][w2_idx - 1] == 0:
dp[w1_idx][w2_idx - 1] = 1
dq.append((w1_idx, w2_idx - 1, w3_idx - 1))
else:
return False
n = int(input().strip())
for i in range(n):
words = (input().strip().split())
if bfs(words):
print(f"Data set {i+1}: yes")
else:
print(f"Data set {i+1}: no")
문제 해결 접근
잘못된 접근
- 처음에는 세 번째 단어를 확인해가면서 첫번째 단어와 두번째 단어의 글자와 일치하는 순간 인덱스를 늘려가는 방식으로 문제를 풀고자 했다.
- 그러나 위 방식은 첫 번째 단어와 두 번째 단어의 현재 인덱스에서의 글자값이 똑같은 경우를 고려하지 못하게 된다.
문자열 DP로 접근하기
- 이를 해결하기 위해서는 '문자열 수정 dp'를 생각해보면 좋다.
- 즉 첫 번째 단어 'cat'과 두 번째 단어 'tree'가 있어서 세 번째 단어 'catrtee'가 완성되었다고 하면 아래 그럼처럼 그릴 수 있다.
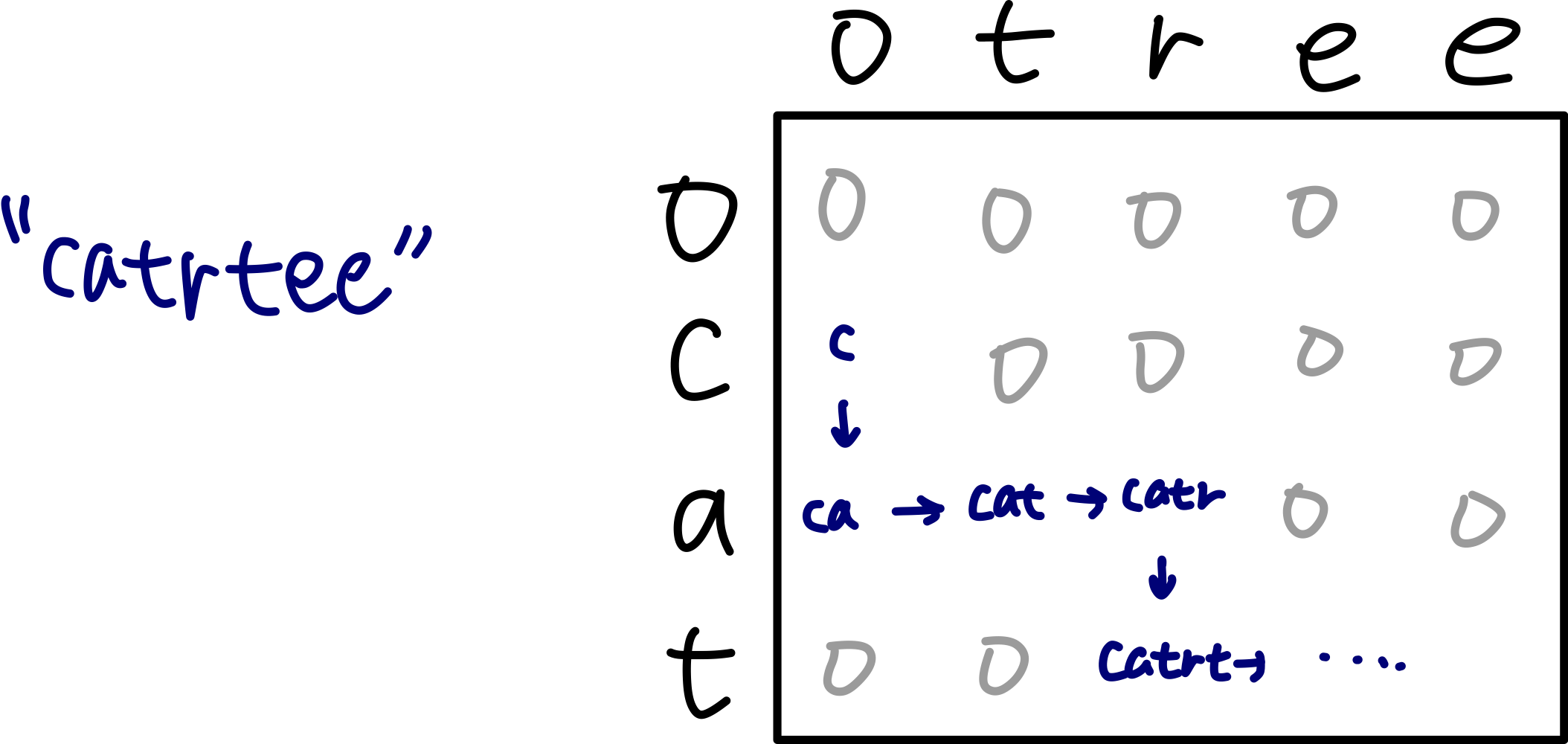
- 우리는 위의 표를 dp테이블이라고 생각하고, 첫 번째 글자를 가져올 경우 위에서 아래로 내려오고, 두 번째 글자를 가져올 경우 왼쪽에서 오른쪽으로 간다고 생각할 것이다. dp 테이블은 dfs/bfs에서의 일종의 visited 테이블과 같기 때문에, 방문하였다면 1로 표시할 것이다.
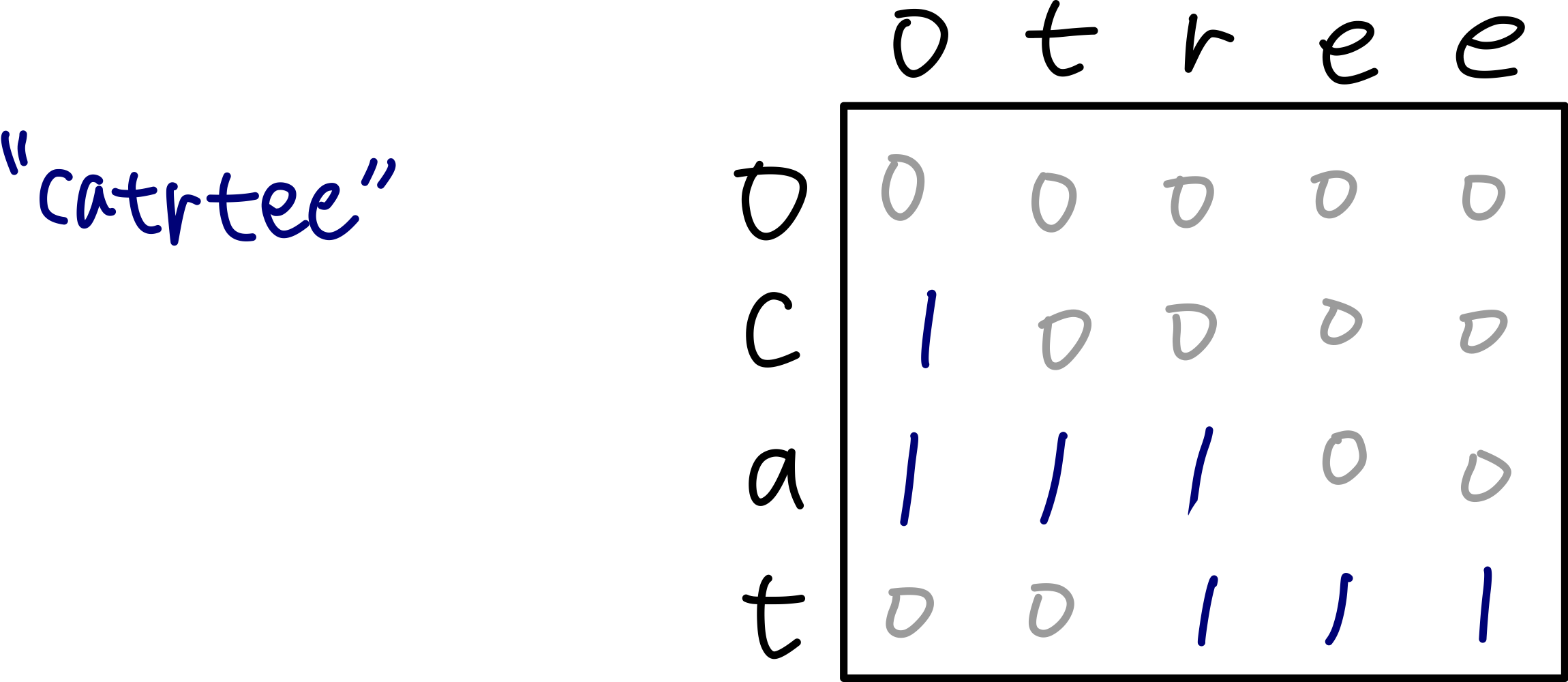
- 이는 그래프 알고리즘에서 bfs로 볼 수도 있다. 왜냐하면 하나의 단어의 순서가 섞이면 안 되기 때문에, 표 안에서 아래쪽 혹은 오른쪽으로만 가게끔 구현되어 있기 때문이다.
소스 코드 구현하기
- 큐에다가 w1, w2, w3의 인덱스를 거꾸로 넣어서 확인한다. 거꾸로 하는 이유는 종료 조건이 모두 다 0일 때 한꺼번에 확인하기 편리하기 때문이다.
- w1나 w2와 w3이 같을 때 각 인덱스를 하나씩 줄여서 큐에 다시 넣는다.
- w1, w2, w3 인덱스가 모두 0이 되거나, w3 인덱스가 0이 되거나 큐가 비어있으면 종료한다.

NLP 엔지니어,,,,? 가 될 수,,,? 나도,,,,?