내용 정리 목적으로 노션에 적은 내용입니다. 내용이 부족하기 때문에 항시 수정할 예정이고 틀린 내용이 있으면 댓글 부탁드립니다.
Node Level Features
기존 머신러닝은 적정한 features를 디자인 해야했다. (ML pipeline)
따라서 노드, 링크, 그래프 수준으로 features를 확인할 것임.
Node degree
노드에 연결된 간선의 수
- 그들의 중요성을 고려하지 않는 문제점이 있다. →
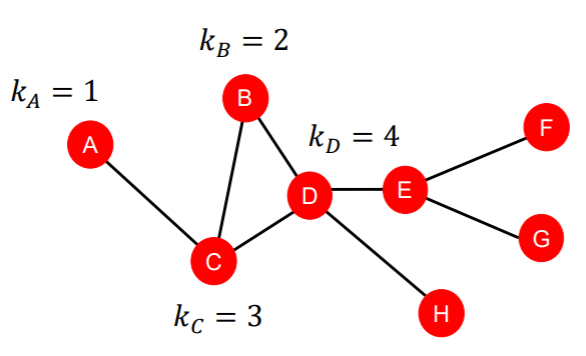
Node centrality (중요도를 고려, 어떤 중요도인지에 따라 다른 정의)
Eigenvector centrality 고유 중심성
로 표현
A: 인접 행렬
: 고유값 (고유벡터의 제곱합에 루트)
노드 v가 다른 중요한 노드에 둘러쌓여있으면 중요하다고 봄(페북 친구 중 연예인이 있으면 중요도가 올라감)
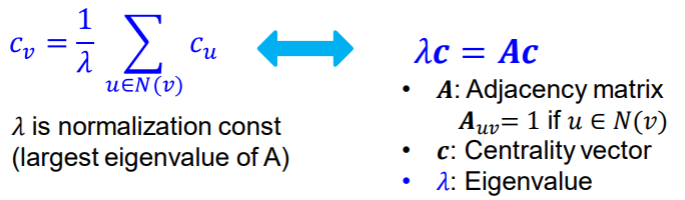
eigenvector centrality:
https://www.youtube.com/watch?v=AjacGClQ56o&t=503s
Betweenness centrality 중간 중심성
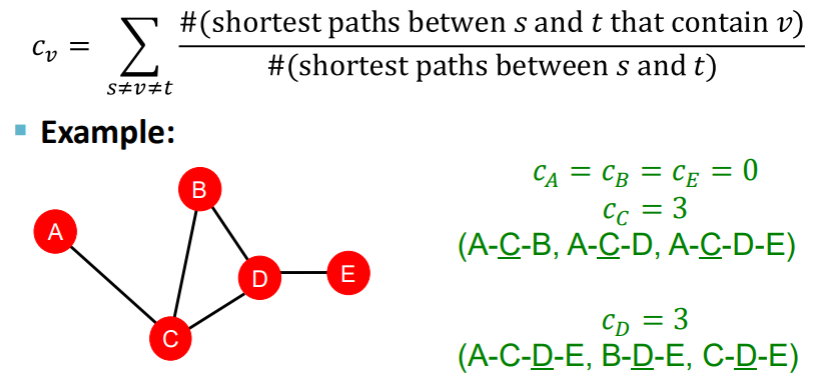
가장 짧은 경로에서 해당 노드가 있으면 +1
Closeness centrality
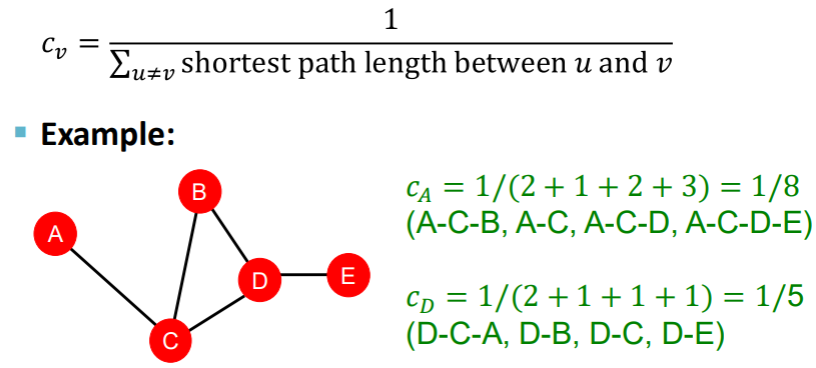
중심에 있을 수록 중요도가 높다
Clustering Coefficient
idea: 해당 노드의 이웃들이 이웃끼리 얼마나 연결되어 있는가
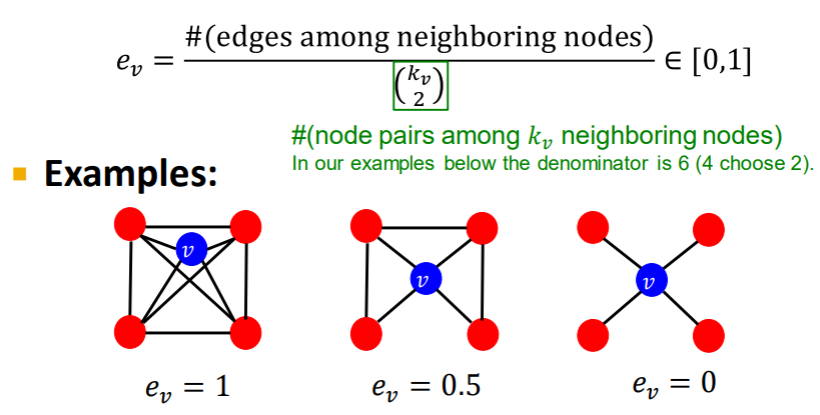
- 클러스터링 계수는 삼각형을 얼마나 생성하는 가를 관찰하기도 한다.
- 2번째 도형의 경우 네트워크에서 3개의 삼각형을 가진다.
(친구의 친구)
Graplet
동형이 아닌 루트 연결 서브 그래프
노드 주변에 어떤 위치에 몇개의 노드가 있는지를 그래플랫으로 확인한다.
노드의 지역적 위상을 측정해주는 척도. (https://jxnjxn.tistory.com/64)
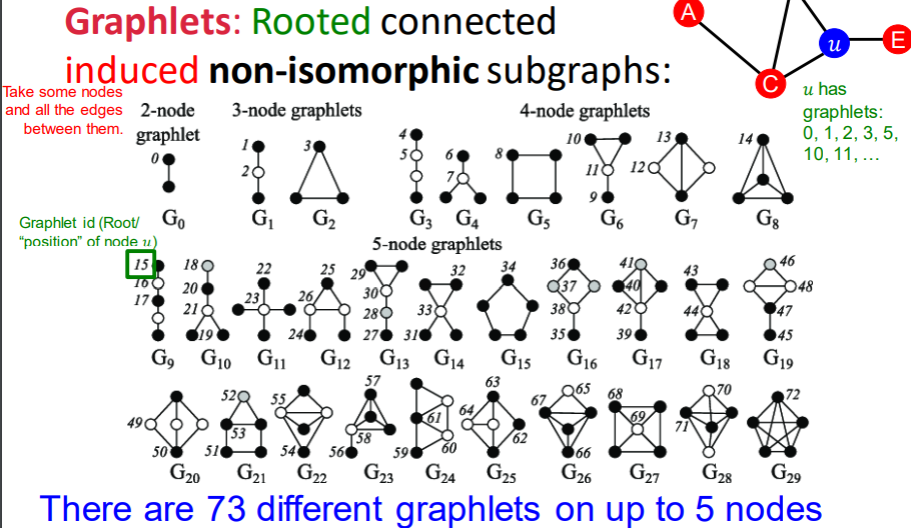
Graphlet degree vector (GDV): 주어진 노드를 루트로한 그래플랫의 수
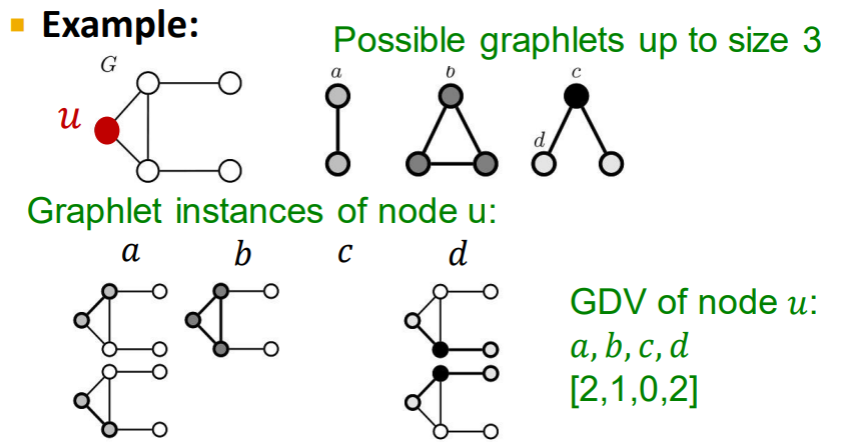
각기 다른 토폴로지를 개수로 벡터화한다.
Link level prediction
링크에 점수를 부여해서
-
links missing at random
무작위로 연결을 제거. 그리고 예측
정적 네트워크에 유리
-
links over time: 시간이 지남에따라 연결을 예측
t 시간의 link를 가지고 t+1 시간의 link를
Link feature
distance-based features
두 노드사이의 최단 경로 길이
그러나 중첩을 고려하지 않는다는 점이 한계
(BH, BE 경로에서는 BD 경로를 공유하지만 이것을 고려하지 않음)
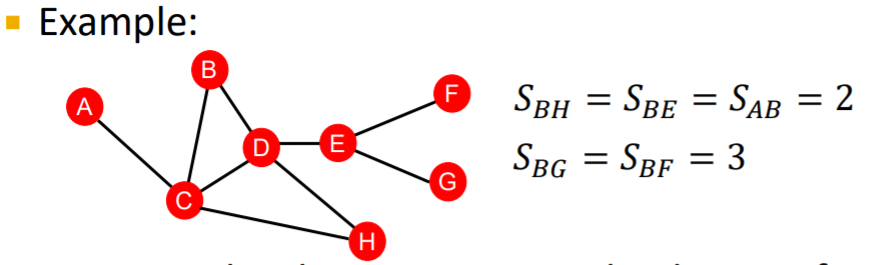
local neighborhood overlap (지역 중첩을 포착하는 방법들)
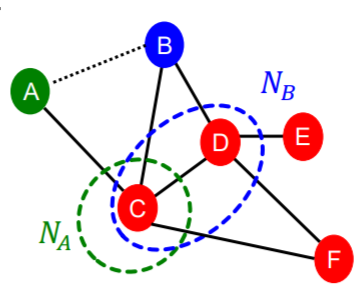
- Common Neighbors: ||
|N(A) N(B)| = |{C}| = 1
- Jaccard’s coefficient:
- adamic-adar index:
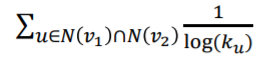
(왜 연결이 많을 수록 작을까: 겹친 노드가 원래 다른 노드에도 연결이 많이 되어 있다면 A와 B가 C에 겹친다는 것이 특별하게 받아들이지 않는다고 생각하기 때문)
그러나 A와 E의 경우 겹치는 노드가 없다. 그들은 이후에 잠재적으로 연결될 수 있기 때문에 global neighborhood overlap 이 전체 그래프를 고려함으로써 해결한다.
Global neighbohood overlap
- Katz index (모든 노드와 연결된 모든 길이의 경로를 카운트)
인접행렬의 곱을 사용하면 쉽게 경로의 수를 알 수 있다.
- = u 와 v 사이 K길이의 경로 수.
- 임을 보여야한다.
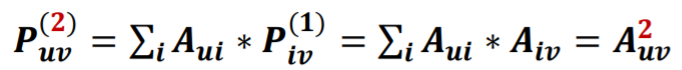
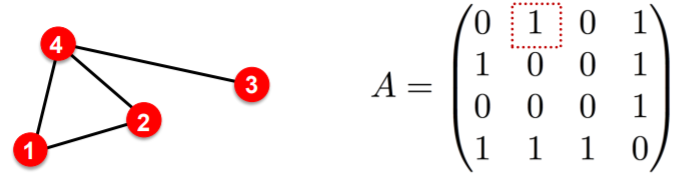
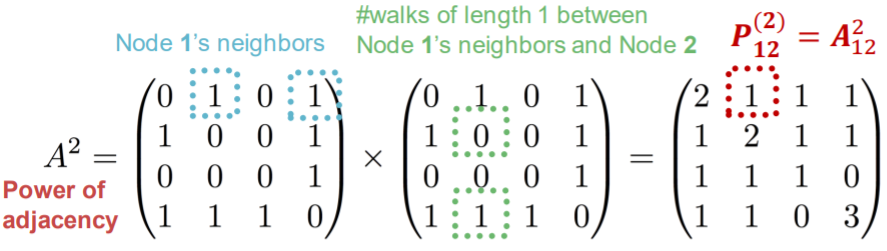
계속 제곱하면 더 긴 경로의 수를 알 수 있다.
하지만 숫자가 너무 커져버리는 문제 때문에 discount factor 를 사용
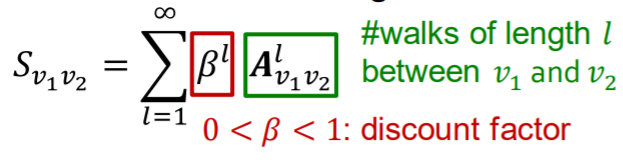
-in closed-form
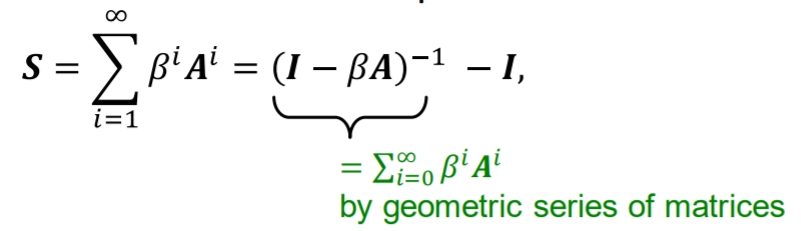
Graph features
kernel methods
기존 ML에서 그래프 레벨의 예측에서 많이 사용되었음.
아이디어: 벡터 대신에 커널을 디자인
- 커널이란?
- 두 그래프 간, 두 데이터 포인트 간 유사성 측정 (graph → feature)
- 커널 행렬: 모든 그래프의 데이터 포인트 쌍의 유사성을 측정하는 행렬
- : K(G, G’) 은 이다. (두 그래프의 벡터의 내적
- Key idea : bag of words
- bag of words : 문서에서 단어의 빈도를 Bag으로 정리하고 bag으로 문서를 정의. (우리는 단어를 노드로 보고 로 정의)
그래프는 서로 다른 구조를 가질 수 있지만 동일한 노드 수 내에서는 동일한 표현을 가질 수 있다.
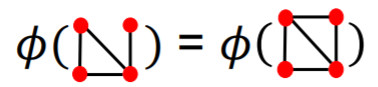
...
