StyleGAN2 : Analyzing and Improving the Image Quality of StyleGAN
이번에 리뷰할 논문은 2020 CVPR에 발표된 "Analyzing and Improving the Image Quality of StyleGAN"입니다. 2019년 CVPR에 나온 StyleGAN의 후속 논문으로, StyleGAN2라고 불립니다. StyleGAN의 문제점을 해결하고, 생성되는 이미지의 quality와 model의 training performance를 높인 모델입니다.
StyleGAN의 한계
본 논문에서는 Synthesis network의 latent space인 intermediate latent space 에 초점을 맞추어 진행됩니다.
기존 StyleGAN에서 생성한 이미지들의 두가지 문제점을 지적합니다.
- water droplet artifact
- phase artifact
Removing normalization artifacts
StyleGAN의 문제점 중 하나는 "water droplet artifact"를 만들어 낸다는 것이었습니다.
water droplet이란 생성된 이미지에 나타나는 물방울모양의 노이즈를 말합니다.

위에 사진에서 볼 수 있듯 결과적으로 생성된 이미지에서는 두드러지지 않지만, featuremap을 보시면 이상한 노이즈를 발견할 수 있습니다. 이는 중간 featuremap에서부터 나타나는데, 64x64 resolution layer에서 부터 high resolution이 될수록 두드러집니다.
원인은 synthesis network에서 의 style을 입히는 과정인 AdaIN에 있습니다. AdaIN에서 각 featuremap을 자신의 mean,variance로 normalization하게 됩니다. 이는 featuremap간의 상대적인 차이를 고려하지 못하는 문제가 생기게 됩니다.
본 논문에서는 이러한 점이 water droplet의 원인이라고 가정하고, normalization과정을 없애고 water droplet이 사라지는것을 확인함으로써 본 가설이 맞음을 확인했습니다.
1. Generator architecture reviseited
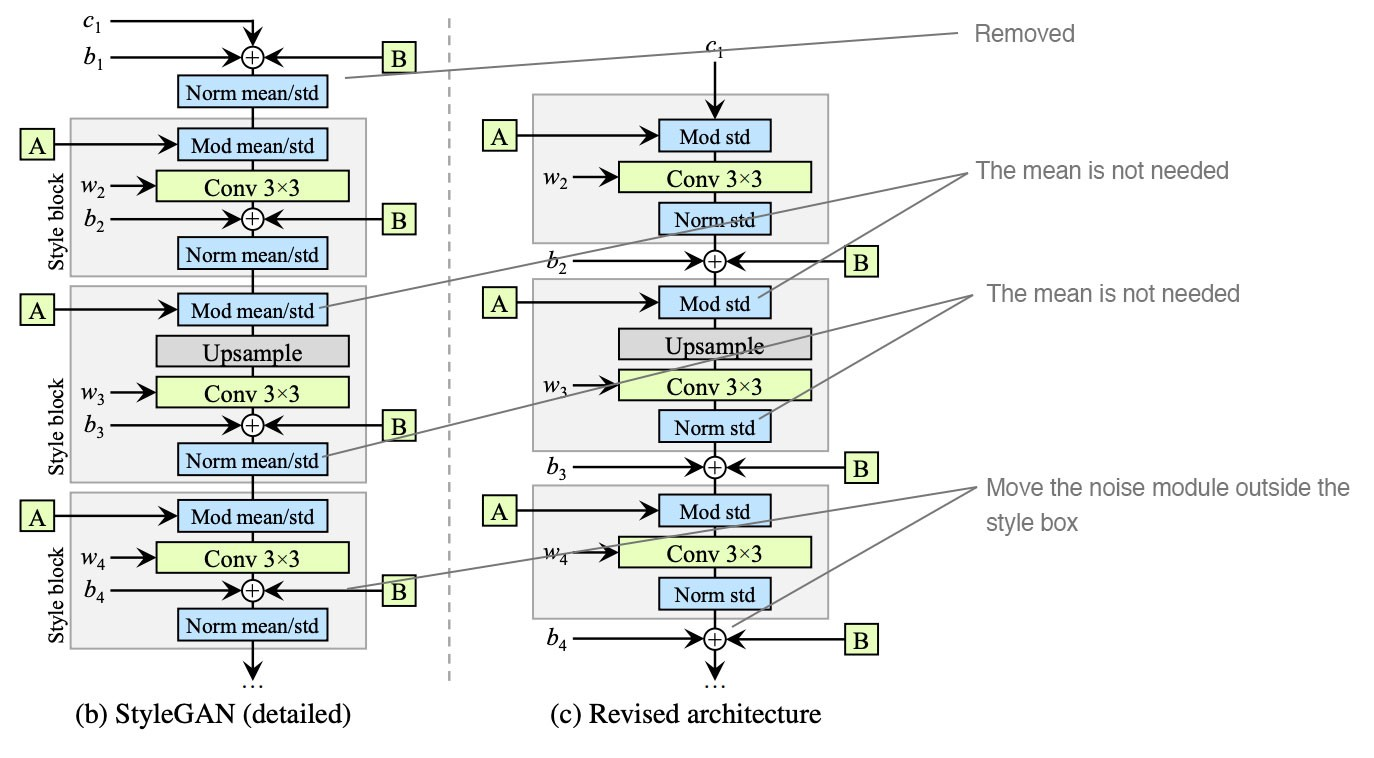
기존 StyleGAN의 synthesis network를 보면 (b)같은 그림입니다. AdaIN의 과정은 다음과 같습니다. 전 featuremap이 자신의 mean,variance로 normalization되고, A에서는 에서 learnable affine transform으로 scaling factor와 bias를 뽑아 normalize된 featuremap에 각각 곱해지고 더해져 (AdaIN modulation) style을 입힙니다. Stochastic variation을 의한 Noise (B block)와 convolution의 bias는 style block안에서 더해지게 됩니다.
StyleGAN2에서는 (c) featuremap을 mean과 variance로 normalize하지 않고, variance로 나누기만 해도 충분하다고 말합니다. 또한, bias와 Noise는 style magnitue와 반비례하게 영향을 주기 때문에, bias와 Noise를 style block밖으로 빼버립니다.
We observe that more predictable results are obtained by moving these operations outside the style block, where they operate on normalized data.
2. Instance normalization revisited
다음 단계로는 normalization을 제거하여 water droplet의 문제를 해결하고 FID를 향상시킬 수 있습니다. (하지만, 다음 과정처럼 normalization을 제거한다면 Style mixing을 할 때는 scale-specific하게 control한다는 장점은 사라집니다.)
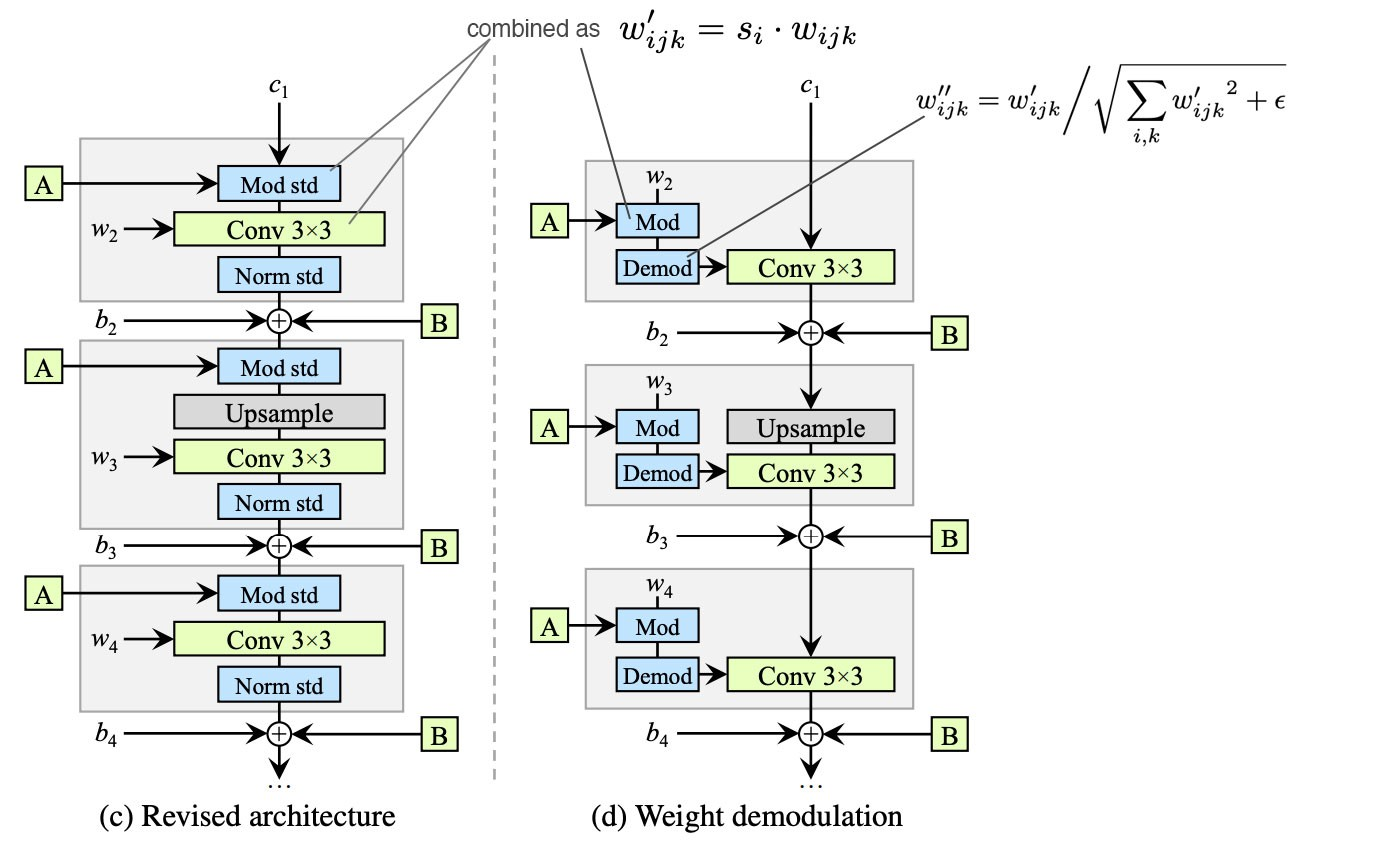
바로 전 단계 (c)에서는 modulation(std로 나누고, scaling factor 곱&bias더하기),convolution, normalization(std로 나누기)과정을 거쳤습니다.
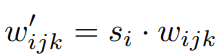
modulation : 이제 std로 나누지 않습니다! 즉 normalization을 하지 않습니다. 대신 A에서 넘어온 scaling factor를 convolution weight에 곱하여 scaling을 진행합니다. (: i번째 input featuremap의 scaling factor, j : out featuremap, k : spatial footpring of convolution =receptive field)
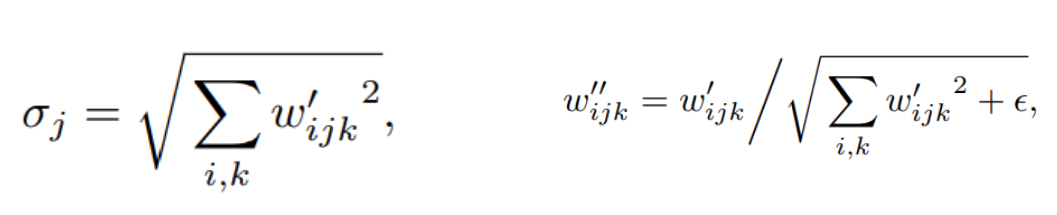
demodulation : 다음으로 weight를 L2norm으로 scaling하고(std), 각 출력 featuremap j를 1/(j의 표준편차)로 scaling해줍니다.
s를 이용하여 단일 convloutional layer의 가중치를 수정해주는 방향으로 style block을 구성하였습니다. featuremap을 normalization하는 것이 아니라 convolution weight를 normalization하는 것 입니다. 결과적으로 waterdroplet을 제거하면서 완전한 controllabillity를 갖추게 되었습니다.
Our method offers excellent controllability by mixing styles at different scales, similar to StyleGAN. Due to weight demodulation, the effects of each style are well localized in the generator
Image quality and generator smoothness
GAN의 metric으로 FID와 precision&recall이 있습니다. 하지만, 아래 그림과 같이 FID와 P&R의 값으로 생성이미지를 평가하기에 한계가 있습니다.
precision : 생성된 이미지 중 실제 이미지 분포에 들어가는 이미지들/생성된 이미지들 (fidelity와 연관)
recall : 실제 이미지 중 생성된 이미지 분포에 들어가는 이미지들/실제 이미지들 (diversity와 연관)

이 지표들은 shape보다는 texture에 더 focusing하기 때문에, 아래와 같이 FID와 P&R값이 같다고 하여 동일한 생성성능을 보여주지 않습니다.
StyleGAN에서 제안된 Perceptual Path Length(PPL)이 적합한데, 단순히 PPL을 낮추는 방향으로 학습을 하는 것은 zero-recall이 될 수 있으므로 smoother generator mapping을 위해 새로운 regularizer를 도입합니다.
1. Lazy regularization
이는 단순히 regularization term을 main loss(WGAN아니고 BCE썼네... non saturating logistic loss(GAN loss) with R1)보다 드물게 학습에 사용하는 것을 의미합니다. 논문의 C는 16minibatch마다 한번 regularization term을 고려한 경우입니다.
2. Path length regularization
PPL은 intermediate latent space의 perceptual smothness를 나타내는 것이었고, 이는 이미지 품질에 관련있다는 것을 알아냈었습니다. 이 PPL을 generator loss의 regularization term으로 추가합니다.
a
space에서의 고정된 사이즈의 변화가 이미지에서 고정된 변화로 나타나야 합니다. PPL이 intermediate latent space에서의 disentanglement를 측정하는 metric이었습니다. image space에서 변화와 intermediate latent space에서의 변화량을 관찰하여 VGG16의 embedding값으로 비교하였습니다.
Progressive growing revisited
기존 StyleGAN의 progressive growing 구조는 각 resolution이 독립적이기 때문에 다음 그림과 같은 문제를 발생시킵니다.
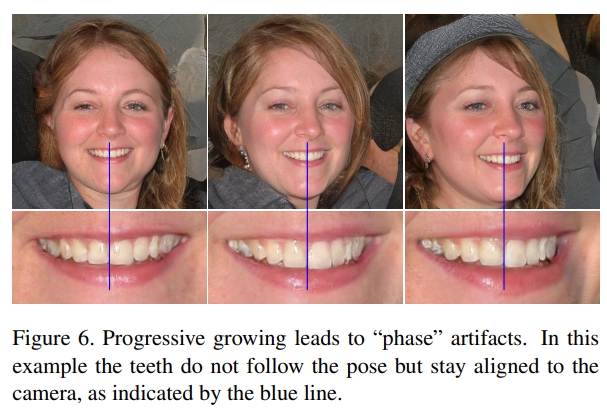
사진설명
Progressive의 장점은 살리면서 Phase artifact를 해결하기 위해 세가지 구조로 실험을 해보았습니다.
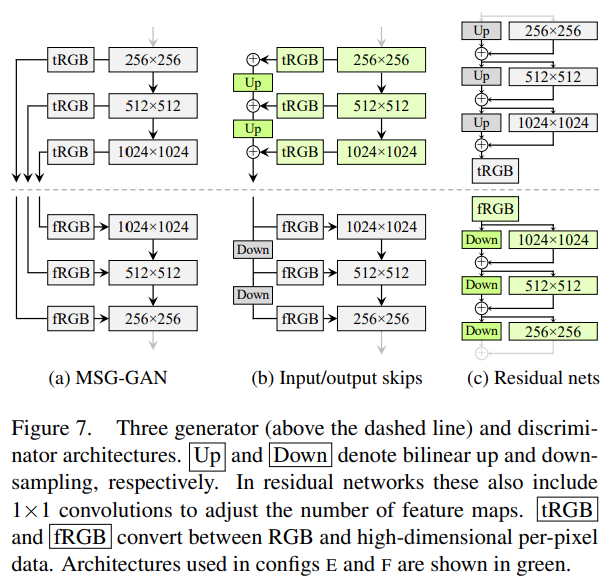
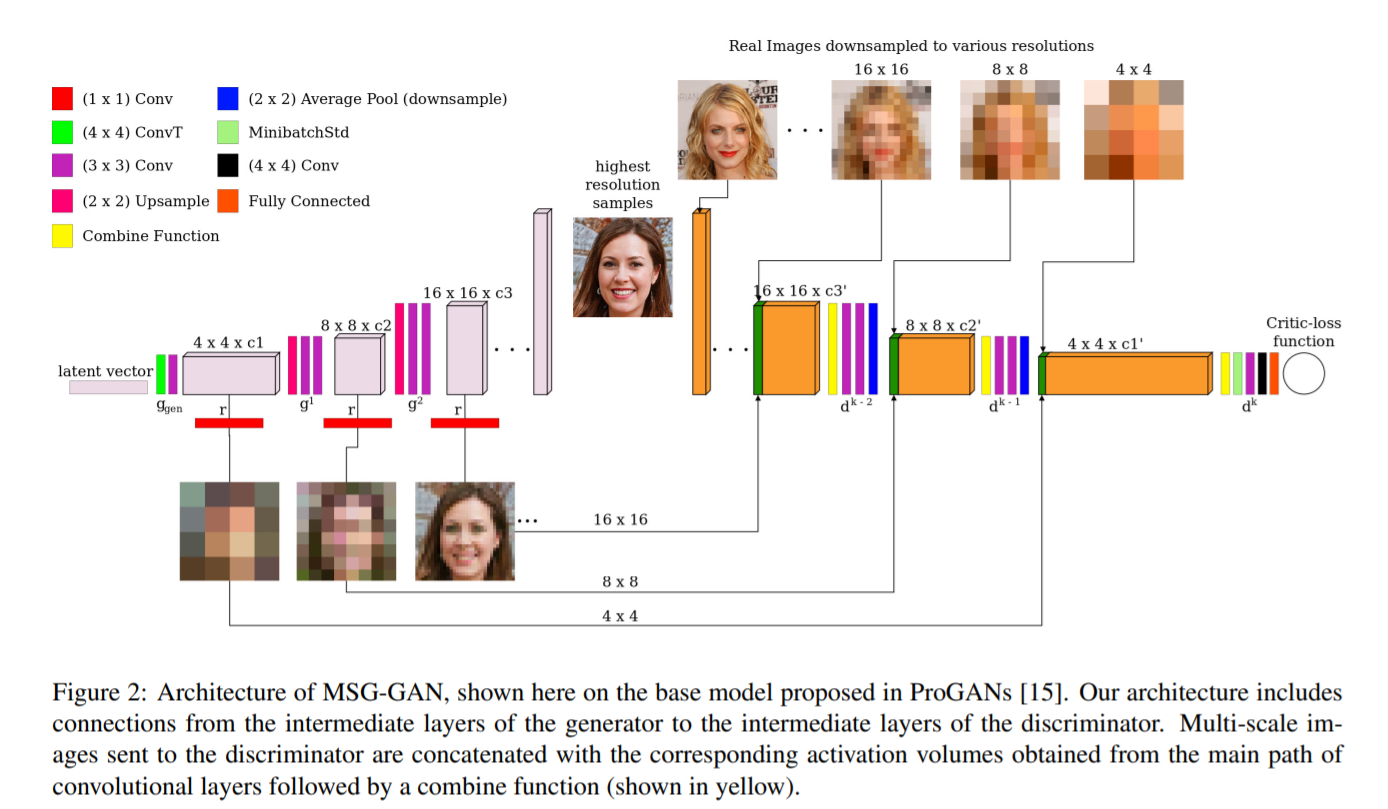
- MSG-GAN : generator와 discriminator의 resolution을 맞춰서 skip connection
- Input/output skips : 다른 resolution의 RGB output을 upsampling/downsampling해서 sum하는 구조. 각 resolution의 영향을 주는 구조
- Residual nets : residual block
Figure7에서 나오는 구조는 generator가 첫 번째 저해상도 이미지가 고해상도 레이어에 영향을 받지 않고 출력할 수 있게 만들고, 학습이 진행되면서 나중엔 고해상도에 집중하게 한다.
Projection of image to latent space
-
최적화 과정에서 latent code에 ramped-down noise를 더했다. 더 복잡한 latent space를 탐색하게 하려고.
-
generator에 입력되는 stochastic noise 값도 정규화(regularize)시켜서 신호 간의 간섭을 막도록, 최적화했다.
마지막으로, 이는 잠재 공간으로 투영하는 방법으로 분석한 결과이다. 히스토그램은 LPIPS 거리 분포를 보여주는데, 이는 실제 이미지와 잠재 공간으로 투영한 후 생성자(Generator)에 한번 다시 통과한 이미지 사이의 거리이다. 히스토그램은 실제 이미지와 StyleGAN, StyleGAN2의 결과를 보여주고 시각화한다. (실제 이미지 또한 인공적으로 잠재 공간으로 떨어졌다.)
StyleGAN2가 StyleGAN과 실제 이미지보다 잠재 공간에서 더 잘 투영됨을 볼 수 있다. 이는 아마도 PPL을 위한 regularization term을 통한 잠재 공간의 매끄러움(smoothing) 때문일 것이다. 아래 그림은 다음 과정을 거친 실제 이미지와 재구성된 이미지(reconstruction images)를 보여준다. 실제 이미지 -> 잠재 공간에 투영 -> 생성자(Generator). StyleGAN에선, 재구성된 이미지(reconstruction images)가 몇몇 장소에서 실제 이미지와 다른 특징 몇 가지를 지녔지만 StyleGAN2에선 꽤 잘 재구성된 것을 볼 수 있다.
