GAN Loss
1. standard GAN

- : 실제 데이터 분포에서 샘플링한 데이터
- : (주로) Gaussian 분포의 임의의 noise에서 샘플링한 데이터
- ≈ 1(진짜) & ≈ 0(가짜)
- ≈ 1(진짜)
- 구현시 binary cross-entropy loss function 사용
참고) https://medium.com/humanscape-tech/paper-review-gan-f304af11a5fb
2. CycleGAN
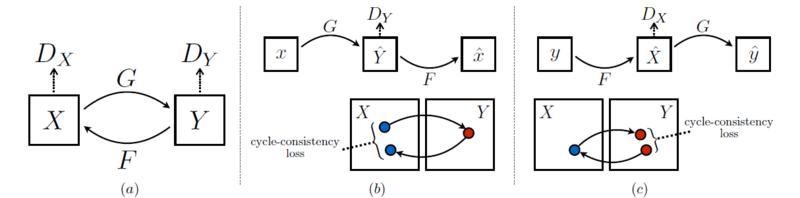
(1) Adversarial loss of CycleGAN
* X → Y인 경우
: 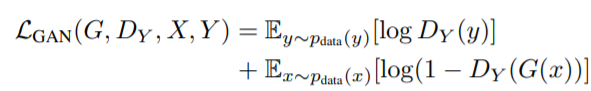
* 반대로 Y → X인 경우
:
- X 도메인에서 Y 도메인으로 매핑하고 역매핑도 해야 하므로 2개의 generator를 사용했고 도메인이 2개니까 2개의 discriminator 사용 (도메인의 수만큼 G, D 수 정해짐)
(2) Cycle-consistency loss of CycleGAN
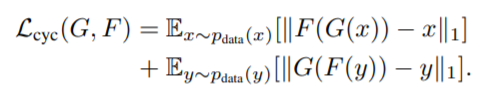
- x → G(x) → F(G(x)) ≈ x / y → F(y) → G(F(y)) ≈ y
- 한 도메인이 다른 도메인으로 갔다가(생성) 원래 도메인으로 잘 복원하도록 함.
- 즉, 이미지의 도메인(스타일)을 바꾸되, 다시 원본으로 복원 가능한 정도로만 바꾸는 것
(3) Full loss of CycleGAN
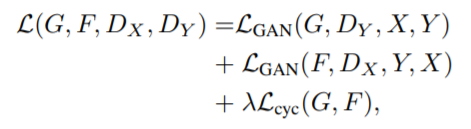
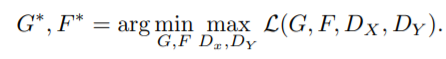
+ (4) Identity loss of CycleGAN
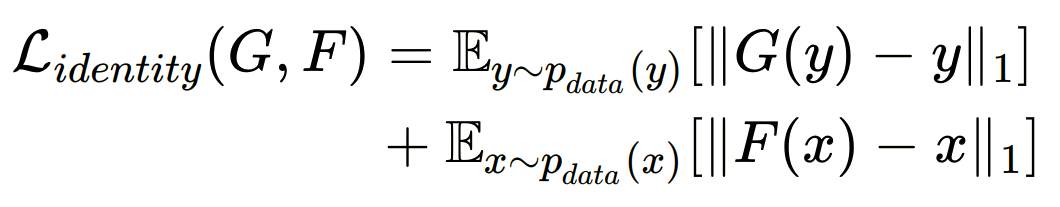
- input과 output의 색감 유지를 위해 도입
- target 도메인 Y가 input으로 들어왔을 때, 동일한 Y 도메인으로 매핑하는 경우 차이가 적도록해 도메인 Y의 색감을 유지할 수 있도록 한다.
논문) Unpaired
image-to-image translation using cycle-consistent adversarial networks
3. RelGAN
: loss functoin이 G 1개와 D 3개 {} 로 구성됨.
사전 지식
- n차원 속성 벡터 =
- 각 특징 는 의미있는 특성 (ex> 얼굴 이미지의 나이, 성별, 머리색 등)
- RelGAN의 목적 : input 이미지 x를 target 특징을 가지면서 real같아 보이는 output 이미지 y로 출력 (몇 개의 user가 지정한 특성은 원래 이미지와 다르게, 그 외는 특성이 유지되도록 출력)
- mapping function 를 학습할 것을 제안
- : 속성의 변화를 원하는 상대 속성 벡터
상대 속성?
-
이미지 x의
특징 벡터 = 원래 도메인,
target 특징 벡터 = target 도메인 -
, 는 둘 다 n차원 벡터임.
-
와 사이의 상대 속성 벡터
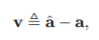

-
input 이미지 x를 output 이미지 y로 매핑할 때 user가 원하는 속성 변경을 나타냄.
ex> 이미지 특성이 이진값 (0 or 1)이면 상대 속성은 (−1, 0, 1) 3개의 값으로 표현됨.
: 각 값은 이진 속성에 대한 user의 action에 해당
| turn on | +1 |
| turn off | -1 |
| unchanged | 0 |
- 즉, 상대 속성은 user의 요구사항을 인코딩 하는 것으로 해석 가능.
- 상대 속성을 통한 얼굴 속성 보간
: 와 사이의 보간을 수행하려면 를 적용하기만하면 됨. (은 보간 계수)

(1) Adversarial Loss of RelGAN
- 생성된 이미지를 real 이미지와 구별할 수 없도록 standard GAN의 adversarial loss 적용.
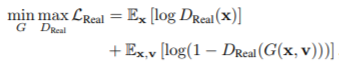
- x : real 이미지
- v : 상대 속성
- : 실제 이미지와 생성된 이미지 구분, unconditional discriminator
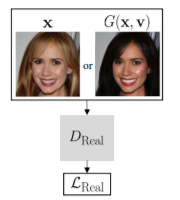
(2) Conditional Adversarial Loss of RelGAN
- output 이미지 가 realistic해 보이길 원함
- 와 의 차이가 상대 속성 와 match 되어야 함.
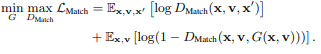
-
: cGAN의 컨셉을 도입한 discriminator (conditional discriminator)
: real triplet 과 fake triplet 을 input으로 함.
-
real triplet
: 2개의 real 이미지 와 상대 속성 벡터 로 구성 -
와
: 각각 x와 의 속성 벡터 -
x와
: 다른 속성을 가진 unpaired한 training data (real 이미지)
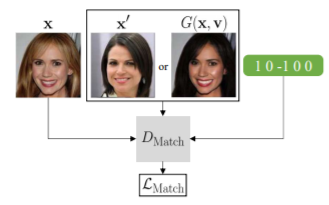
(참고)
- conditional GAN loss
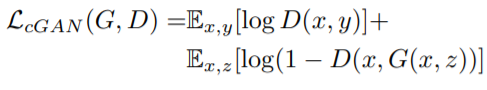
$ G^* = arg minG max_D L{cGAN} (G, D) $
(출처 : Image-to-Image Translation with Conditional Adversarial Networks)
- real triplet
: real 이미지 2개 & 잘 matched 상대 속성
- fake triplet
: real 이미지 1개 & fake 이미지 1개 & 잘 matched 상대 속성
- 와 mismatched 로 구성되는 wrong triplet을 추가
(input-output 쌍이 상대 속성과 일치하는지 여부를 결정하는 matching aware discriminator에 영감 받음)
+ wrong triplet
: real 이미지 2개 & 잘못 matched 상대 속성
: wrong triplet을 추가함으로써 는 아래처럼 분류하려고 함.
| triplet | 분류 |
|---|---|
| real triplet | +1 |
| fake triplet | -1 |
| wrong triplet | -1 |
로 표현되는 real triplet이 주어지면,wrong triplet 작동 방식
4개의 변수 중 하나를 wrong triplet에 의해 생성되는 것으로 대체함으로써
4개의 wrong triplet을 얻는다.

(3) Reconstruction Loss of RelGAN
- unconditional loss와 condtional loss를 최소화하면서 G는 output 이미지 를 real 이미지처럼 생성하는 것을 학습함.
- 그리고 와 의 차이는 상대 속성 에 match됨
- 그러나, G가 low level (ex> 배경 표현) -> high level (ex> 얼굴 이미지의 identity) 과정에서
다른 모든 부분을 유지하면서 속성과 관련된 contents만 수정한다는 보장이 없다. - 이 문제를 보완하기 위해 G를 규제하는 cycle-reconstruction loss와 self-reconstruction loss를 도입함. (둘 다 L1 norm 사용)
1) Cycle-reconstruction loss
- cycleGAN의 cycle consistency 개념을 적용
- L1 norm 사용
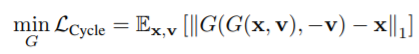
: , 는 서로의 역이 됨.
(참고)
- cycleGAN의 cycle consistency
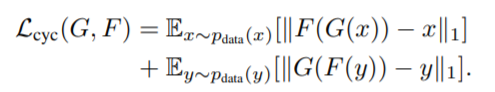
출처) Unpaired
image-to-image translation using cycle-consistent adversarial networks
2) Self-reconstruction loss
- 상대 속성 벡터가 벡터인 경우, 아무 속성도 변하지 않았음을 의미
- output 이미지 은 가능한 한 에 가깝게 돼야 함.
- 아래의 loss를 통해 구현 가능
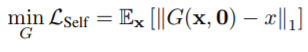
- G는 auto-encoder로 다시 돌아가서(degenerate) 를 재구성함.
- L1 norm 사용
(4) Interpolation Loss of RelGAN
- G는 (은 보간 계수) 를 통해
이미지 와 변환된 이미지 사이를 보간함. - 보간의 high-quality를 위해 보간된 이미지 를 realistic하게 보이기를 원함.
-> ""를 보간되지 않은 output 이미지인 " 및 "와 구별할 수 없도록 만드는 규제를 제안
= interpolation discriminator - 의 목적
: 생성된 이미지를 input으로 받아 보간 정도 를 예측 ()
: 를 예측함으로써 와 사이의 모호성을 해결
+ = 0 : 보간 x
+ = 0.5 : 최대 보간
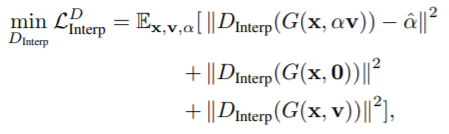
- 첫번째 term
: 로부터 를 복구 - 두번째, 세번째 term
: 이 보간되지 않은 이미지에 대해 0을 출력
- 그런데, 실험적으로 아래의 수정된 loss가 학습을 더 안정화 시키는 것을 발견했음.
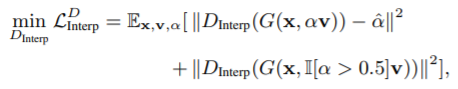
(Ⅱ['] : argument가 참이면 1, 아니면 0인 indicator function)
- G는 아래의 loss 추가
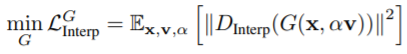
- G는 가 보간되지 않았다고 생각하도록 를 속임.
- 와 과정

(5) Full Loss of RelGAN
- 훈련을 안정화하기 위해 loss function에 orthogonal regularization ()을 추가했음.
- D = {} 와 G에 대한 각각의 full loss function
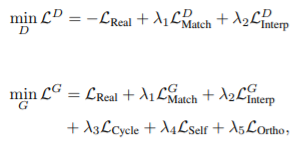
(, , , , 는 hyper-parameters)
| Loss | Generator L | Discriminator L |
|---|---|---|
| Adversarial Loss | ||
| Conditional Adversarial Loss | ||
| Interpolation Loss | ||
| Reconstruction Loss | ||
| Reconstruction Loss | ||
| orthogonal regularization |
논문) RelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes
4. WGAN
추가예정
5. WGAN-CP
추가예정
