https://st-lab.tistory.com/267
해당 블로그를 참고하여 작성된 포스팅 입니다.
❄️풀이1 - Binary Search
해당 문제는 이진탐색을 두번 하여 정답을 구하는 문제이다.
즉 x가 처음으로 등장하는 index(lowerBound)와 x가 마지막으로 등장하는 index(upperBound)를 구해준다.
- lower Bound : 찾고자 하는 값 (이상의)값이 처음으로 나타나는 위치

public static int lowerBound(long arr[], long x, int start, int end) {
while(start < end) {
int mid = (start + end) / 2;
if(arr[mid] >= x)
end = mid;
else
start = mid+1;
}
return end;
}- upper Bound: 즉 찾고자 하는 값보다 큰 값의 위치를 반환

public static int upperBound(long arr[], long x, int start, int end) {
while(start < end) {
int mid = (start + end) / 2;
if(arr[mid] > x) {
end = mid;
} else {
start = mid + 1;
}
}
return end;
}
- 그럼 찾고자 하는 값이 없을경우?
upperBound와 lowerBound의 위치가 같다!
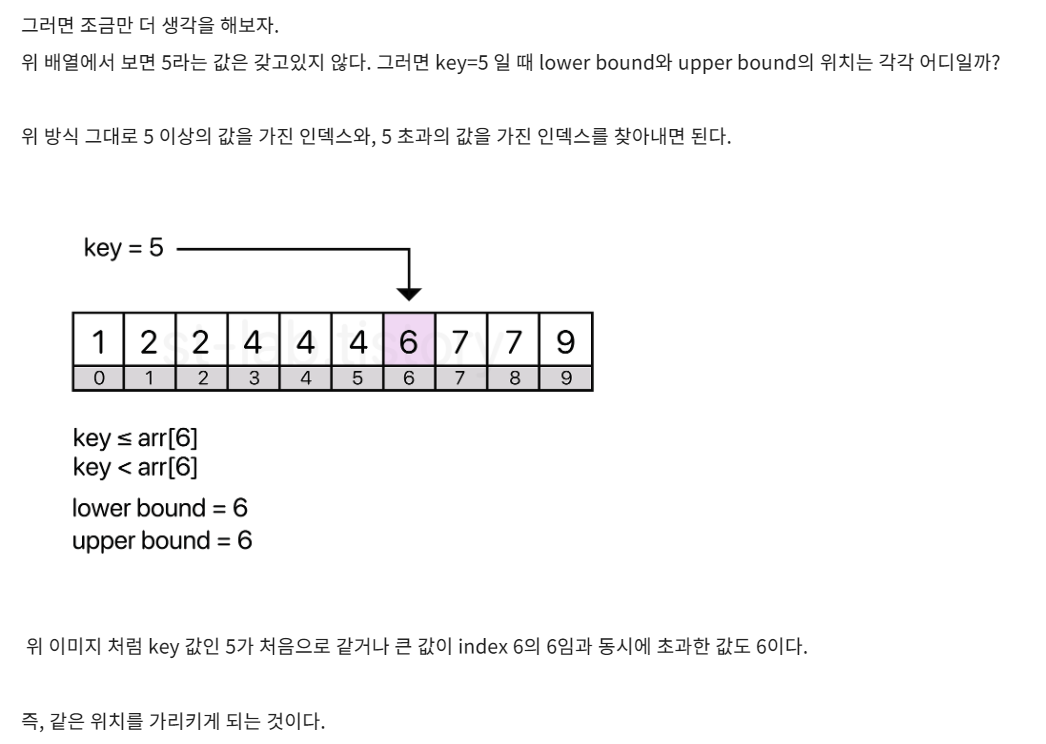
따라서 두 위치의 값을 빼면 해당 값이 몇개인지 출력되는 것이다.
int rightIndex = upperBound(arr, X, 0, N);
int leftIndex = lowerBound(arr, X, 0, N);
if(rightIndex - leftIndex == 0) // 찾고자 하는 값이 없을경우
System.out.println(-1);
else
System.out.println(rightIndex - leftIndex);🤨궁금 1 왜 초기 start = 0이고 end = N일까? 다른 이진탐색에서는 end = N-1이였는데
이유는 rightIndex - leftIndex값을 하기 때문이다!
만약 N = 5, arr = 12333이라면
3의 start위치는 2이고 end는 N인 5가 되어 개수가 (5-2)인 3이 되는 것이다.
🤨궁금 2 왜 end = mid일까? 같은 값 찾는 이진탐색에서는 end = mid - 1이였는데
이유는 mid값 자체가 찾는 값 일수도 있기 때문에end를 mid로 설정하여 현재 위치를 포함한 왼쪽 부분에서 탐색을 이어 나가야 한다.
🤨궁금 3 왜 while(start < end)일까? 같은 값 찾는 이진탐색에서는 while(start <= end) 이였는데
이유는 start가 end와 같아질때까지 범위를 줄이는 것이다.end를 mid로 설정하여 현재 위치를 포함한 왼쪽 부분에서 탐색을 이어 나가야 한다.
사진에서 보는 것 처럼 둘이 같을때 멈추는 것이기 때문에 이때 start, end 둘중에 아무것이나 출력해도 되는 것이다.
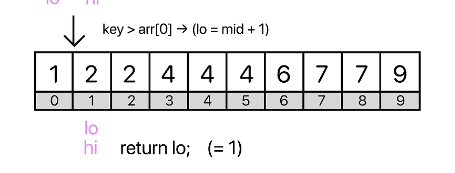
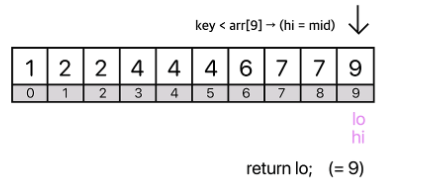
❄️풀이2 - HashMap
HashMap의 getOrDefault()
for(int i = 0; i < N; i++) { int key = Integer.parseInt(st.nextToken()); //만약 value가 없을 경우 defaultValue값을 반환한다. map.put(key, map.getOrDefault(key, 0) + 1); }for(int i = 0; i < M; i++) { int key = Integer.parseInt(st.nextToken()); sb.append(map.getOrDefault(key, 0)).append(' '); }
1. 정렬된 배열에서 특정 수의 개수 구하기
1-1. 문제
N개의 원소를 포함학고 있는 수열이 오름차순으로 정렬되어 있습니다. 이때 이 수열에서 x가 등장하는 횟수를 계산하세요.
예를들어 수열 {1, 1, 2, 2, 2, 2, 3}이 있을때 x = 2라면, 현재 수열에서 값이 2인 원소가 4개이므로 4를 출력합니다.
- 첫째 줄에 N과 x가 정수 형태로 공백으로 구분되어 입력됩니다.
(1 <= N <= 1,000,000), (-10^9 <= x <= 10^9) - 둘째 줄에 N개의 원소가 정수 형태로 공백으로 구분되어 입력됩니다.
(-10^9 <= 각 원소의 값 <= 10^9)
1-2. 풀이
두 문제의 풀이는 같다. 다만 각 lowerBound, upperBound의 return 값이 end거나 start인데 결론적으로는 같다.
백준에서는 return start로 하는 것이 시간이 덜 걸린다.
1-3. (정렬된 배열에서 특정 수의 개수 구하기) 코드
import java.util.*;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
int N = Integer.parseInt(st.nextToken());
long X = Long.parseLong(st.nextToken());
long arr[] = new long[N];
st = new StringTokenizer(br.readLine(), " ");
for(int n = 0; n < N; n++) {
arr[n] = Long.parseLong(st.nextToken());
}
int rightIndex = upperBound(arr, X, 0, N);
int leftIndex = lowerBound(arr, X, 0, N);
if(rightIndex - leftIndex == 0)
System.out.println(-1);
else
System.out.println(rightIndex - leftIndex);
}
public static int lowerBound(long arr[], long x, int start, int end) {
while(start < end) {
int mid = (start + end) / 2;
if(arr[mid] >= x)
end = mid;
else
start = mid+1;
}
return end;
}
public static int upperBound(long arr[], long x, int start, int end) {
while(start < end) {
int mid = (start + end) / 2;
if(arr[mid] > x) {
end = mid;
} else {
start = mid + 1;
}
}
return end;
}
}
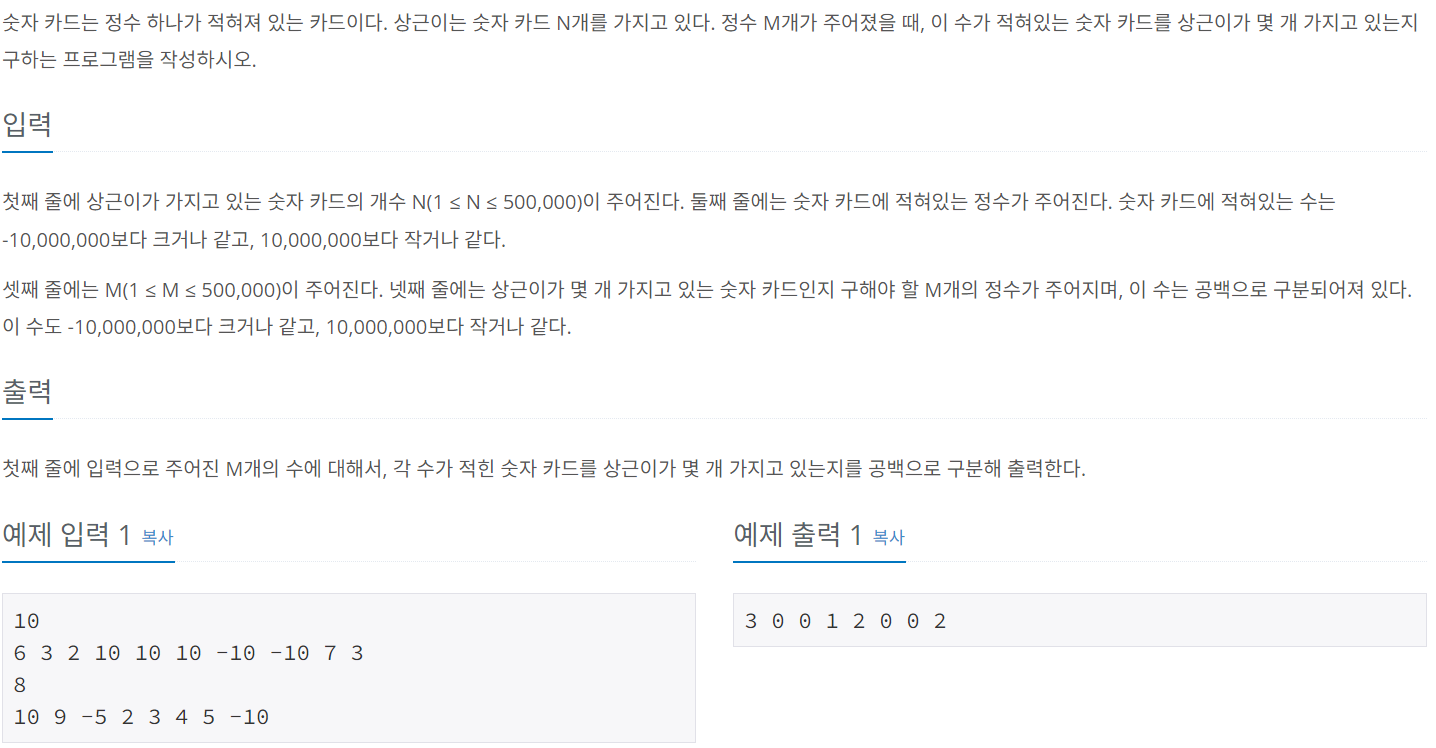
2. 숫자카드2
2-1. 문제
https://www.acmicpc.net/problem/10816
2-2. 풀이
두 문제의 풀이는 같다. 다만 각 lowerBound, upperBound의 return 값이 end거나 start인데 결론적으로는 같다.
백준에서는 return start로 하는 것이 시간이 덜 걸린다.
🚨🚨 문자열을 더할때 StringBuilder를 이용해야한다.
그래야 시간초과가 발생하지 않는다.
2-3. (숫자카드2) 코드
import java.util.*;
public class Main {
public static void main(String args[]) {
Scanner input = new Scanner(System.in);
int N = input.nextInt();
int map[] = new int[N];
for(int n = 0; n < N ; n++)
map[n] = input.nextInt();
Arrays.sort(map);
int M = input.nextInt();
StringBuilder sb = new StringBuilder();
for(int m = 0; m < M; m++) {
int K = input.nextInt();
int hi = upperBound(0, map.length, map, K);
int lo = lowerBound(0, map.length, map, K);
sb.append(hi - lo).append(' ');
}
System.out.println(sb);
}
private static int upperBound(int start, int end, int[] map, int target) {
while(start < end) {
int mid = (start + end) / 2;
if(map[mid] > target)
end = mid;
else
start = mid + 1;
}
return start;
}
private static int lowerBound(int start, int end, int[] map, int target) {
while(start < end) {
int mid = (start + end) / 2;
if(map[mid] >= target)
end = mid;
else
start = mid + 1;
}
return start;
}
}