그래프(Graph)
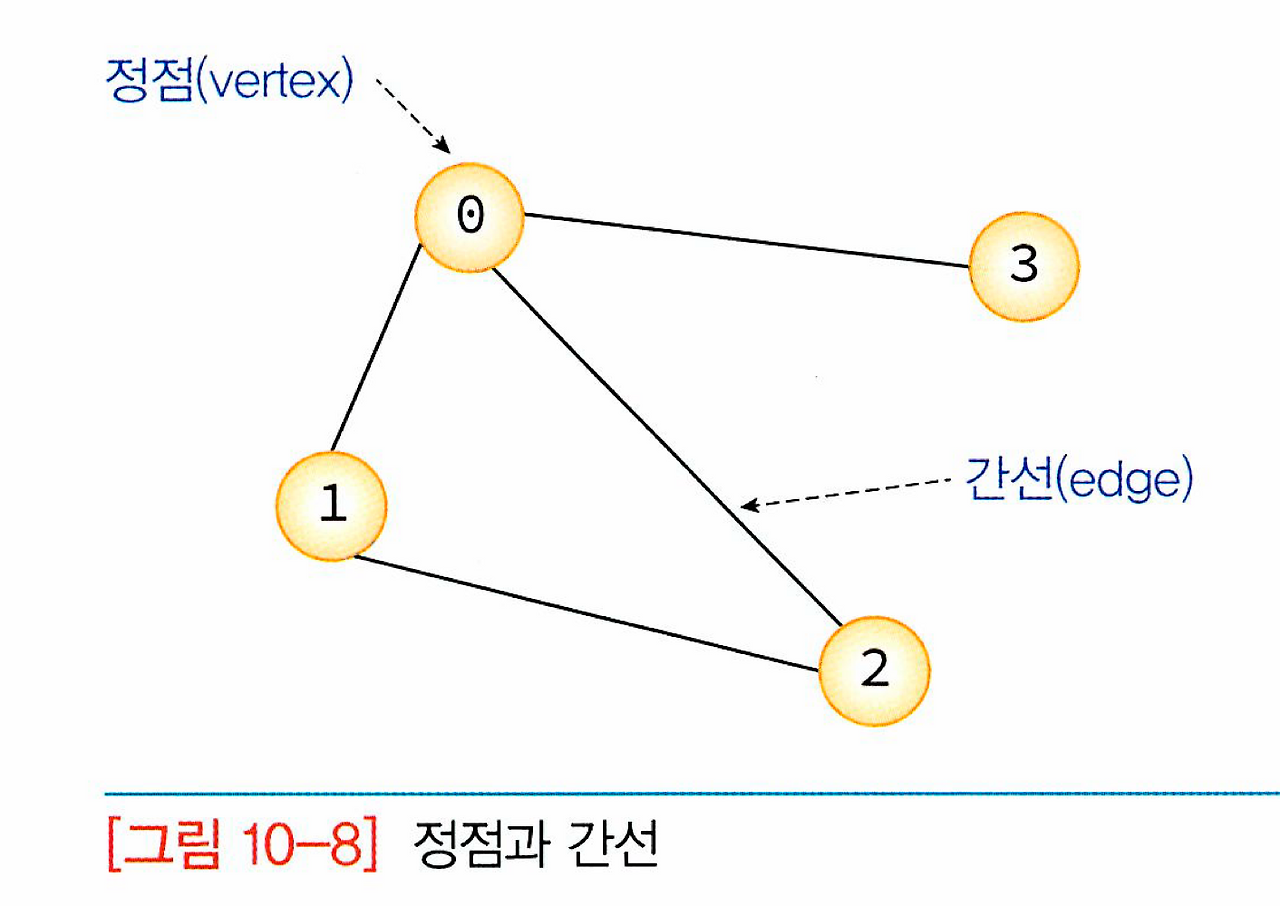
그래프는 정점(vertex)와 간선(edge)들의 유한 집합이라 할 수 있다.
(정점은 '노드'라고 할 수 있고 간선은 '링크'라고도 할 수 있다.)
그래프에는 여러 종류가 있는데 그 중 사이클이 없는 것을 '트리'라고 한다.
V(G1) = {0, 1, 2, 3}
E(G1) = {(0,1), (0,2), (0,3), (1,2)}
그래프는 위와 같이 집합으로 표현할 수 있다.
여기서 V(G)는 그래프 G의 정점들의 집합을, E(G)의 간선들의 집합을 의미한다.
무방향 그래프와 방향 그래프
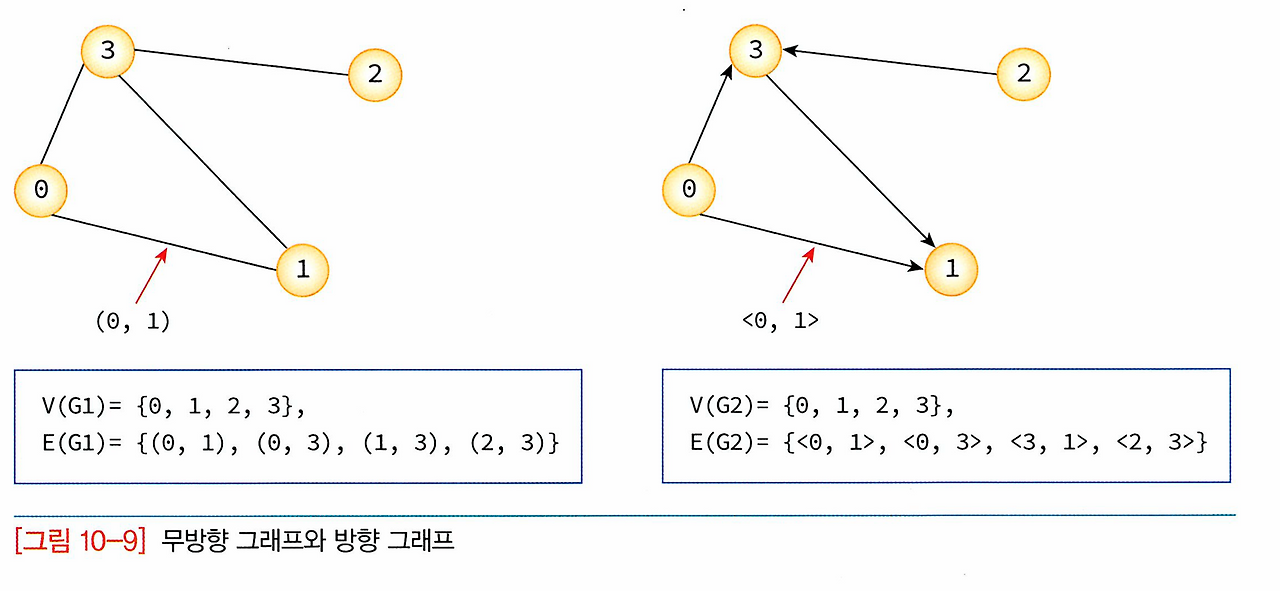
간선의 종류에 따라 그래프는 무방향 그래프(undirected graph)와 방향 그래프(directed graph)로 구분된다.
무방향 그래프의 간선은 간선을 통해서 어느 방향으로도 갈 수 있음을 나타내며 정점 A와 B를 연결하는 간선은 (A, B)와 같이 정점의 쌍으로 표현한다.
(A, B)와 (B, A)는 동일한 간선이 된다.
방향 그래프는 간선에 방향성이 존재하는 그래프로서 간선을 통하여 한쪽 방향으로만 갈 수 있음을 나타낸다.
정점 A에서 정점 B로만 갈 수 있는 간선은 <A, B>로 표시한다.
방향 그래프에서 <A, B>와 <B, A>는 서로 다른 간선이다.
네트워크
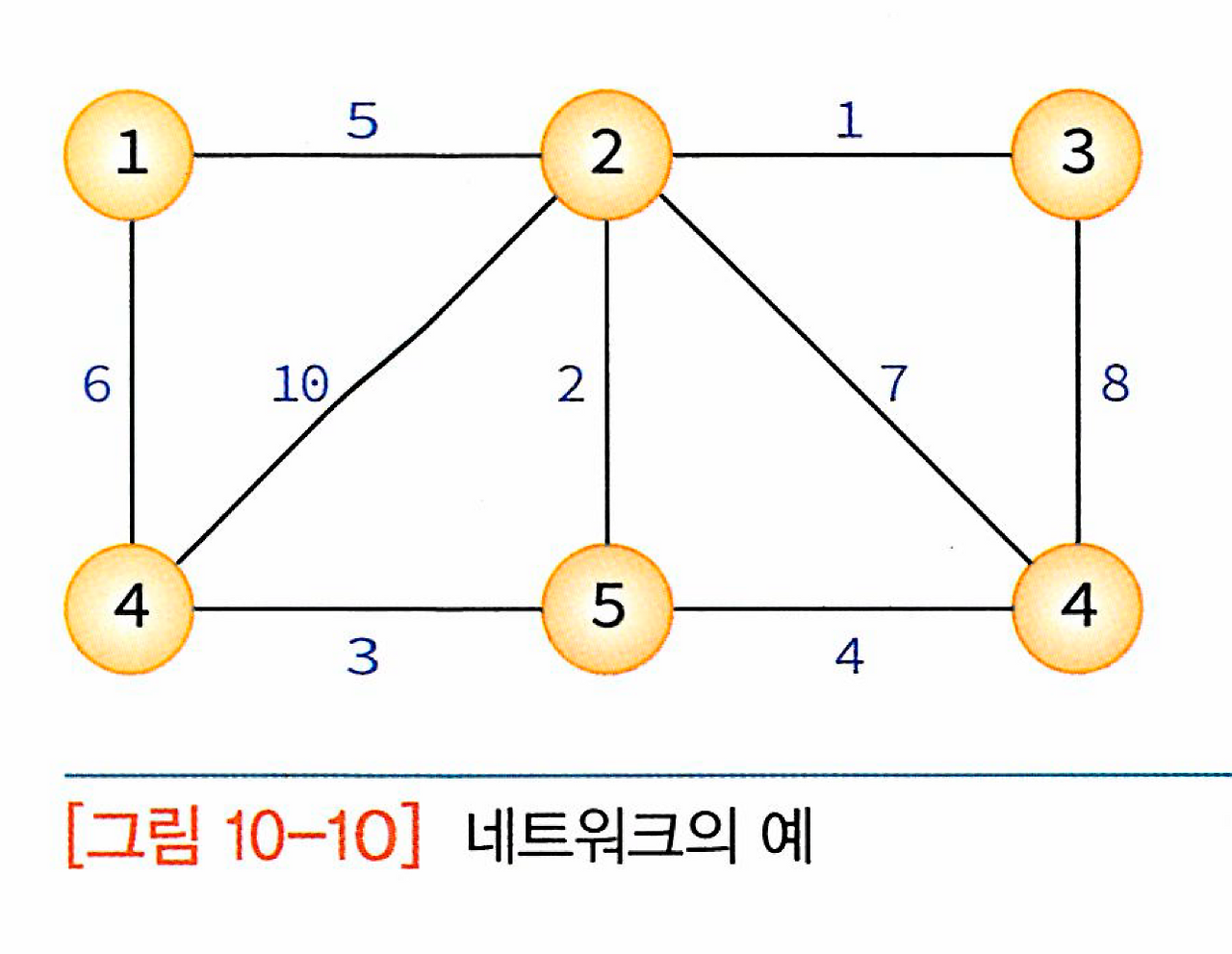
간선에 비용이나 가중치가 할당된 그래프를 가중치 그래프(weighted graph) 또는 네트워크(network)라 하며 다음과 같이 나타낸다.
네트워크는 도시와 도시를 연결하는 도로의 길이, 회로 소자의 용량, 통신망의 사용료 등을 추가로 표현할 수 있으므로 그 응용 분야가 보다 광범위하다.
정점의 차수
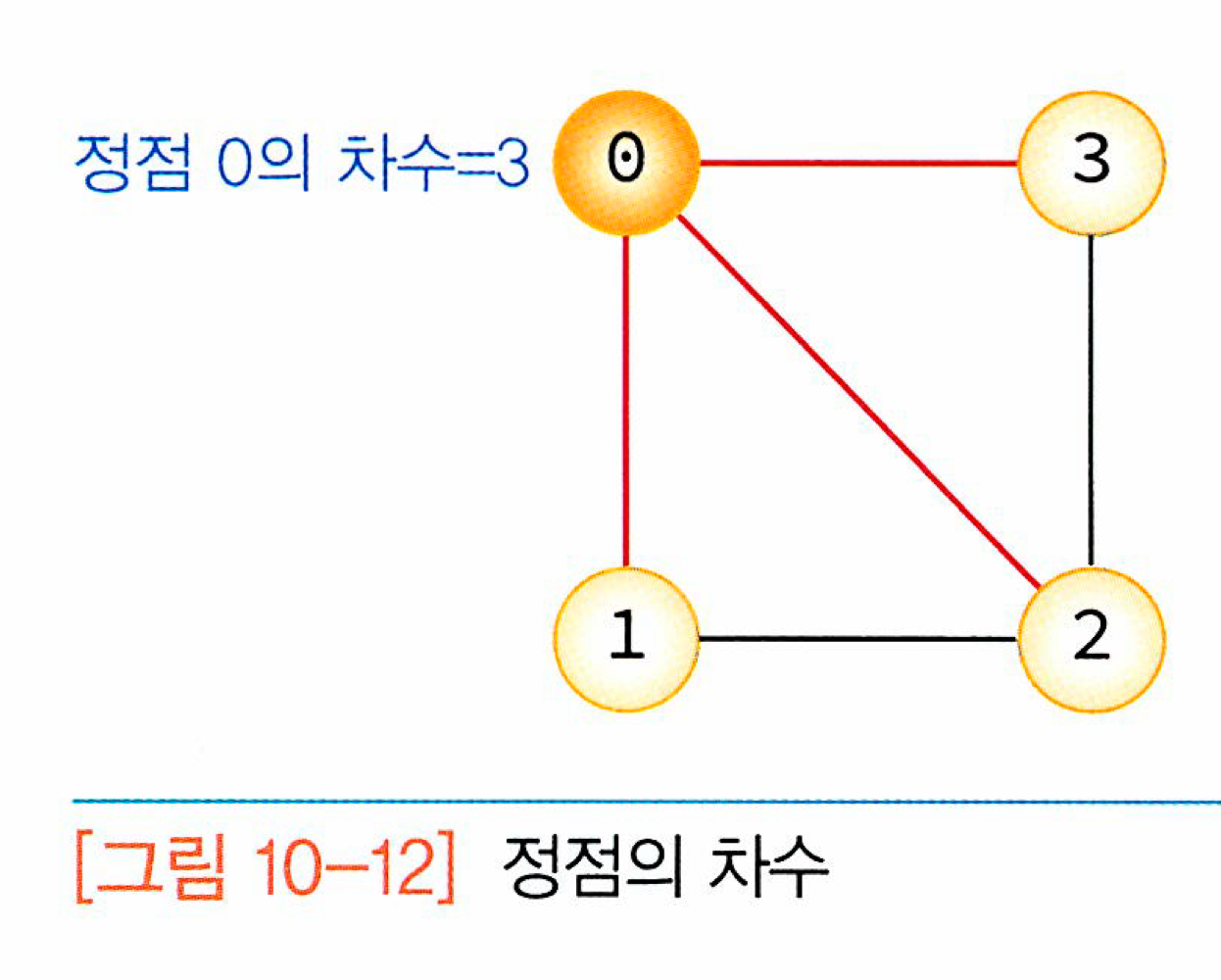
그래프에서 인접 정점(adjacent vertex)란 간선에 의해 직접 연결된 정점을 뜻한다. 다음의 그래프에서 정점 0의 인접 정점은 정점 1, 정점 2, 정점 3이다.
무방향 그래프에서 정점의 차수(degree)는 그 정점에 인접한 정점의 수를 말한다. 다음에서 정점 0의 차수는 3이다.
어떠한 그래프의 차수는 그래프의 속한 정점의 차수 중 가장 큰 차수가 된다.
무방향 그래프에서 모든 정점의 차수를 합하면 간선 수의 2배가 된다.
이것은 하나의 간선이 두개의 정점에 인접하기 때문이다.
방향 그래프에서는 외부에서 오는 간선의 개수를 진입 차수(in-degre)라 하고 외부로 향하는 간선의 개수를 진출 차수(out-degree)라 한다.
경로
무방향 그래프에서 정점 s로부터 정점 e까지의 경로는 정점의 나열 (s,v1,v2,...,vk,e)로서, 나열된 정점들 간에는 반드시 간선 (s,v1),(v1,v2),...,(vk,e)가 존재해야 한다.
만약 방향 그래프라면 <s,v1>,<v1,v2>,...,<vk,e>가 있어야 한다.
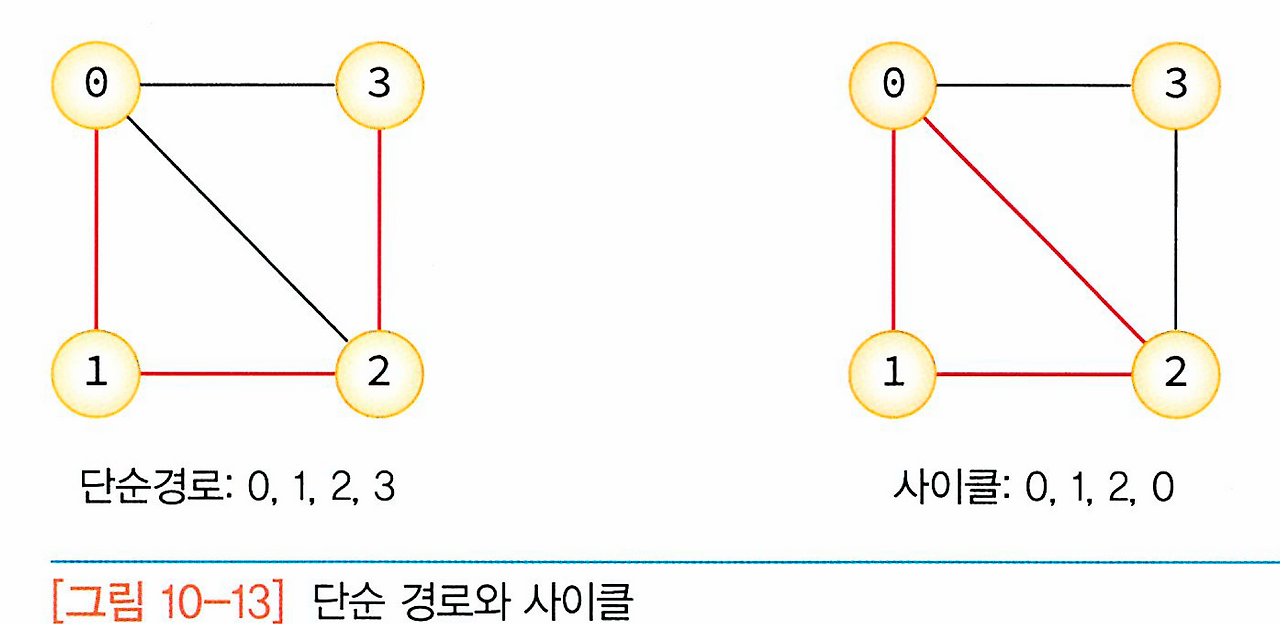
경로 중에서 반복되는 간선이 없을 경우 이러한 경로를 단순 경로(simple path)라 한다.
단순 경로의 시작 정점과 종료 정점이 동일하다면 이러한 경로를 사이클(cycle)이라 한다.
연결 그래프
무방향 그래프 G에 잇는 모든 정점쌍에 대하여 항상 경로가 존재한다면 G는 연결되었다고 하며, 이러한 무방향 그래프 G를 연결 그래프(connected graph)라 부른다.
그렇지 않은 그래프는 비연결 그래프(unconnected graph)라고 한다.
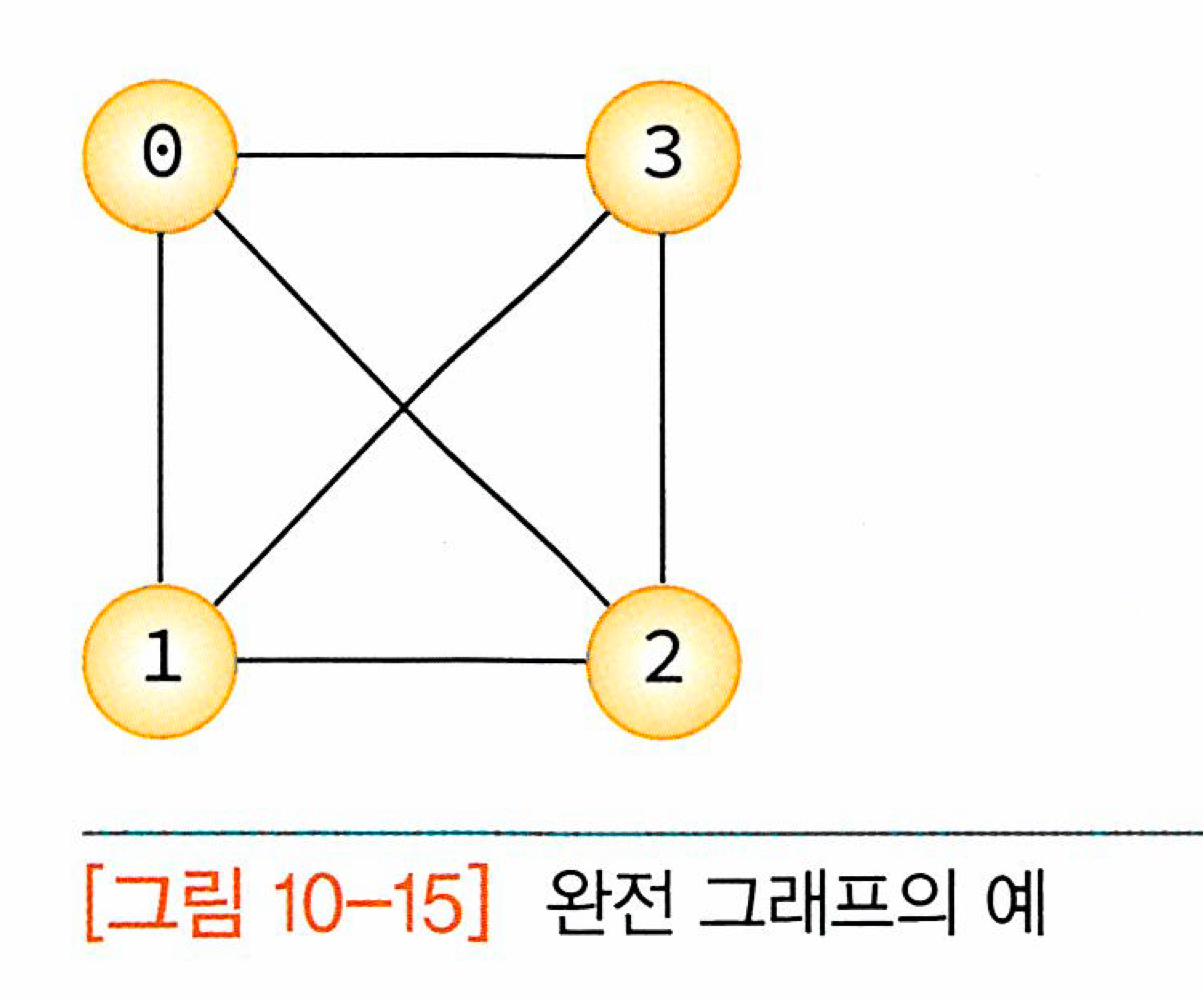
완전 그래프
그래프에 속해있는 모든 정점이 서로 연결되어 있는 그래프를 완전 그래프(complete graph)라고 한다.
무방향 완전 그래프의 정점 수를 n이라고 하면, 하나의 정점은 n-1개의 다른 정점으로 연결되므로 간선의 수는 가 된다.
만약 완전 그래프에서 n=4라면 간선의 수는 이다.
방향 완전 그래프의 정점 수를 n이라고 하면, 하나의 정점은 n-1개의 다른 정점으로 연결되고 각 각 정점마다 간선이 필요하므로 간선의 수는 가 된다.
만약 완전 그래프에서 n=4라면 간선의 수는 이다.
그래프의 표현 방법
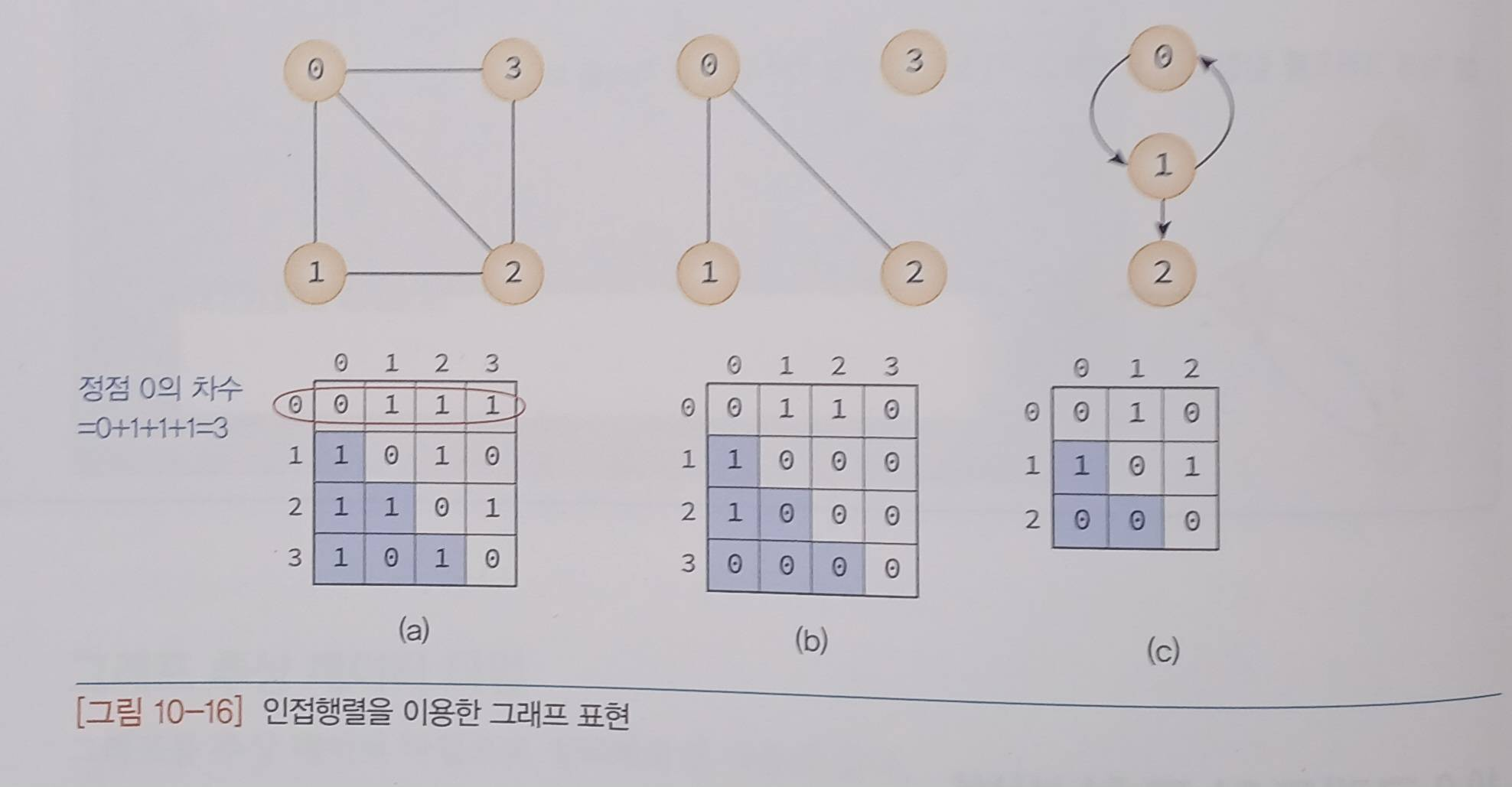
인접 행렬
인접 행렬은 2차원 배열을 사용하여 그래프를 표현한다.
그래프의 정점 수가 n이라면 의 2차원 배열인 인접 행렬(adjacency matrix) M이 생성되었을 때 만약 i, j를 연결하는 간선이 존재 할 때 M[i][j]가 1로 바뀐다.
우리가 다루고 있는 그래프에서는 자체 간선을 허용하지 않으므로 인접 행렬의 대각선 성분은 모두 0으로 표시된다.
만약 i, j를 연결하는 간선이 추가 되면 무방향 그래프에서는 i에서 j로 j에서 i로 갈 수 있기 때문에 M[i][j], M[j][i]으로 대칭 추가된다.
허나 방향 그래프에서는 i에서 j로만 갈 수 있기 때문에 M[i][j]만이 추가되어 일반적으로 대칭이 아니다.
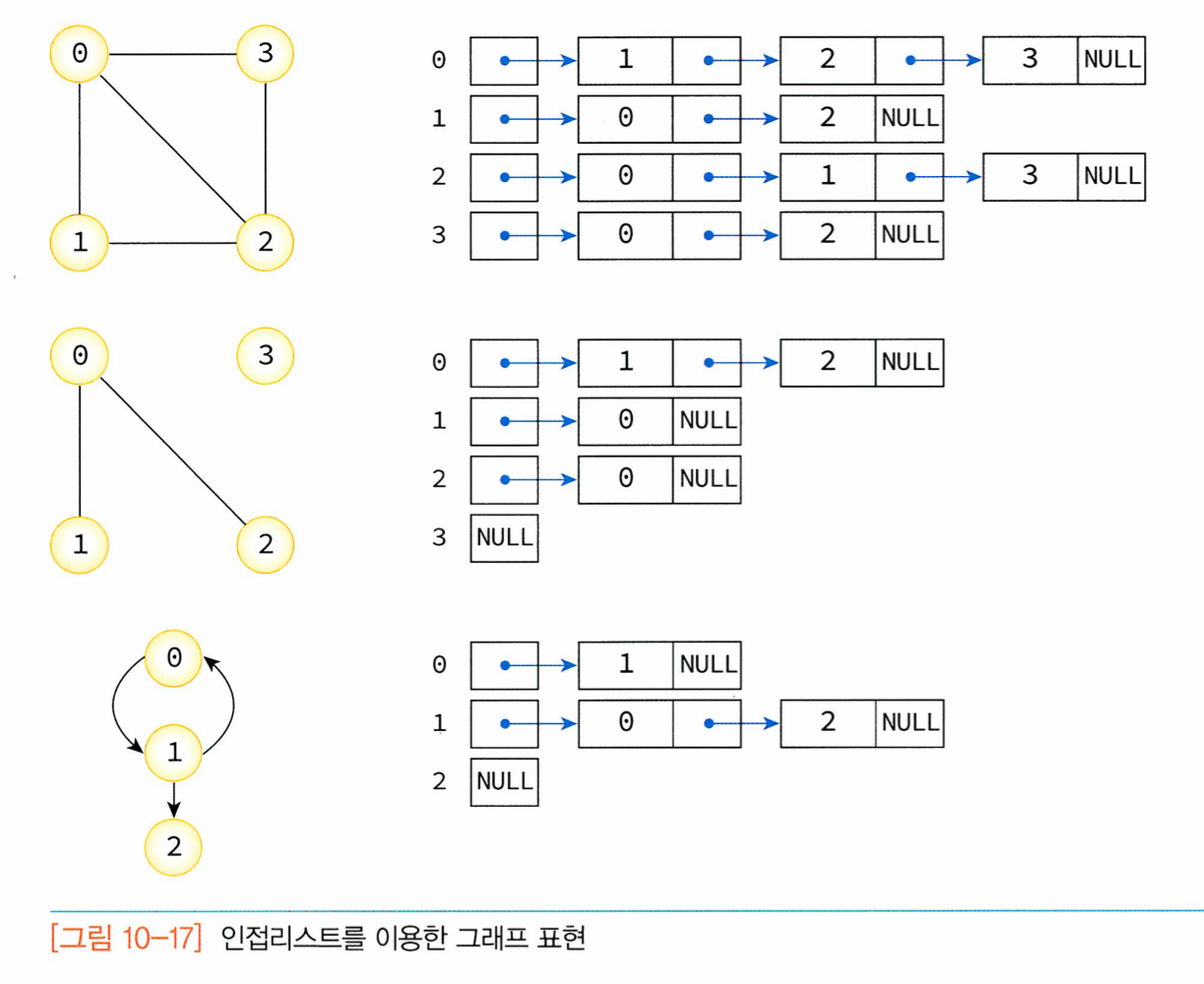
인접 리스트
인접리스트은 연결리스트를 사용하는 그래프를 표현한다.
인접 리스트(adjacency list)는 그래프를 표현함에 있어 각가의 정점에 인접한 정점들을 연결 리스트로 표시한 것이다.
각 연결 리스트의 노드들은 인접 정점을 저장하게 된다.
각 연결 리스트들은 헤더 노드를 가지고 있고 이 헤더 노드들은 하나의 배열로 구성되어 있다.
따라서 정점의 번호만 알면 이 번호를 배열의 인덱스로 하여 각 정점의 연결 리스트에 쉽게 접근할 수 있다.
무방향 그래프의 경우 정점i와 정점 j를 연결하는 간선(i,j)는 정점 i의 연결 리스트에 인접 정점 j로서 한번 표현되고, 정점 j의 연결 리스트에 인접 정점 i로 다시 한번 표현된다.
인접 리스트의 각각의 연결 리스트에 정점들이 입력되는 순서에 따라 연결 리스트 내에서 정점들이 순서가 달라질 수 있다.
그래프의 탐색
하나의 정점으로부터 시작하여 차례대로 모든 정점 한번씩 방문하는 것이다.
그래프의 탐색 방법은 DFS(깊이 우선 탐색)과 BFS(너비 우선 탐색)의 두 가지가 있다.
DFS(깊이 우선 탐색)
그래프의 시작 정점에서 출발하여 시작 정점 v을 방문하였다고 표시한다. 이어서 v에 인접한 정점들 중에서 아직 방문하지 않은 정점 u를 선택한다. 만약 그러한 정점이 없다면 탐색은 종료한다. 만약 아직 방문하지 않은 정점 u가 있다면 u를 시작 정점으로 하여 깊이 우선 탐색을 다시 시작한다. 이 탐색이 끝나게 되면 다시 v에 인접한 정점들 중에서 아직 방문이 안 된 정점을 찾는다. 만약 없으면 종료하고 있다면 다시 그 정점을 시작 정점으로 하여 깊이 우선 rlvdl dn탐색을 다시 시작한다.
깊이 우선 탐색을 구현하는 방법에는 두 가지가 있다. 첫 번째는 순환 호출을 이용하는 것이고 두 번째는 명시적인 스택을 사용하는 것이다.
재귀함수를 이용한 방식
// 인접 행렬로 표현된 그래프에 대한 깊이 우선 탐색
void dfs_mat(GraphType* g, int v)
{
int w;
visited[v] = TRUE; // 정점 v의 방문 표시
printf("정점 %d -> ", v); // 방문한 정점 출력
for (w = 0; w < g->n; w++) { // 인접 정점 탐색
if (g->adj_mat[v][w] && !visited[w])
dfs_mat(g, w); // 정점 w에서 DFS 새로 시작
}
}
명시적인 스택을 이용한 방식
// DFS 함수
void dfs_mat(GraphType* g, int start) {
Stack stack;
init(&stack);
push(&stack, start);
visited[start] = 1;
printf("DFS 순서: ");
printf("%d ", start);
while (!isEmpty(&stack)) {
int current = pop(&stack);
for (int i = 0; i < g->n; i++) {
if (g->adj_mat[current][i] == 1 && visited[i] == 0) {
printf("%d ", i);
push(&stack, i);
visited[i] = 1;
}
}
}
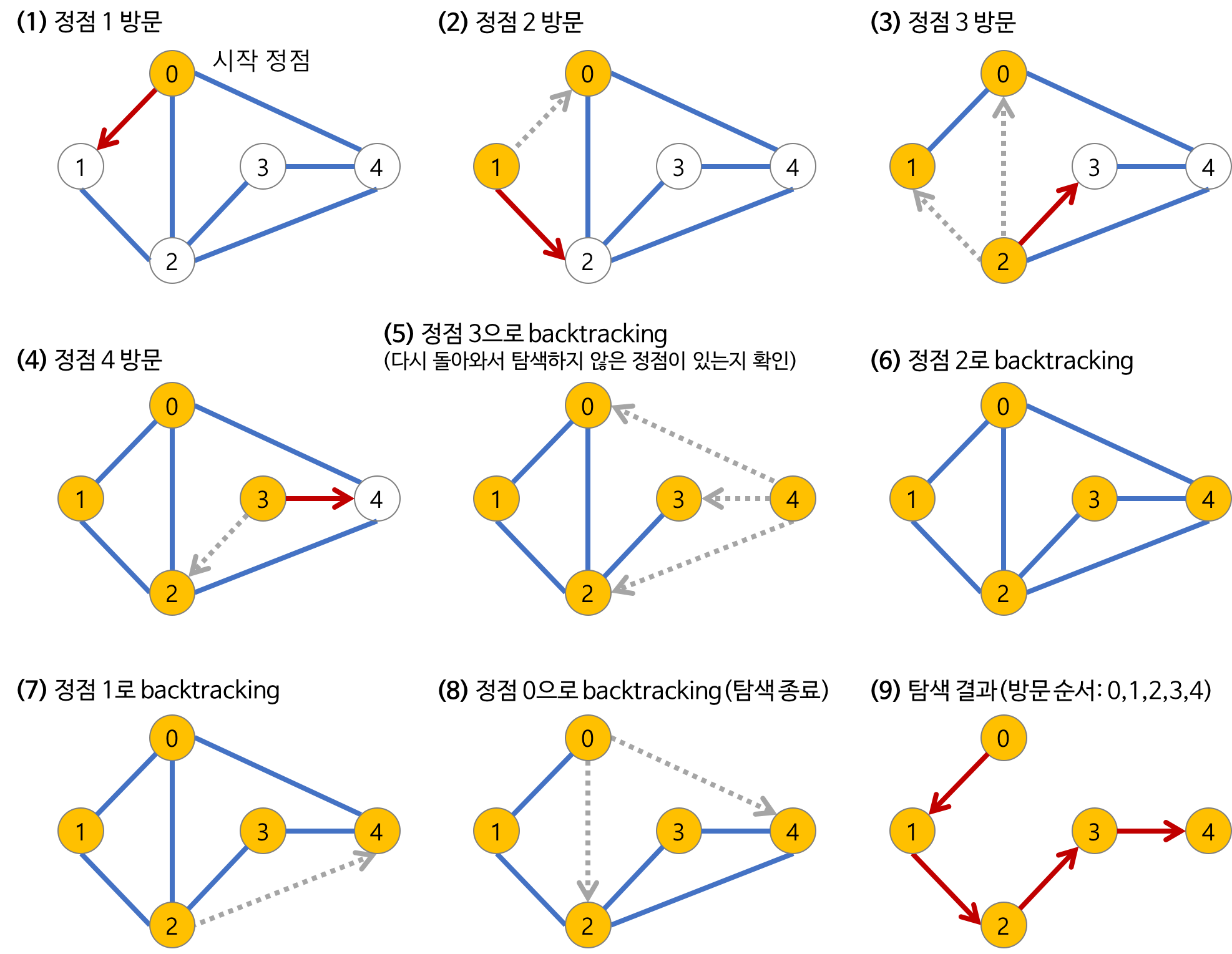
}위의 코드를 실행하면 아래의 그림과 같이 실행된다.
(시작 정점은 0, 현재 방문 노드의 왼쪽부터 검사)
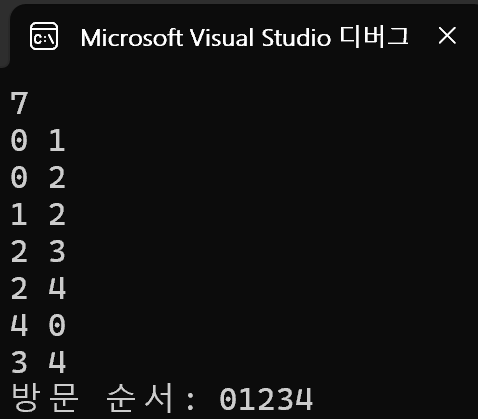
int graph[5][5];
int visited[5];
int dfs(int node) {
visited[node] = 1;
printf("%d", node);
for (int i = 0; i < 5; i++) {
if (graph[node][i] && !visited[i]) {
dfs(i);
}
}
}
int main()
{
int n;
scanf("%d", &n);
int x, y;
for (int i = 0; i < n; i++) {
scanf("%d %d", &y, &x);
graph[y][x] = 1;
graph[x][y] = 1;
}
printf("방문 순서: ");
dfs(0);
}
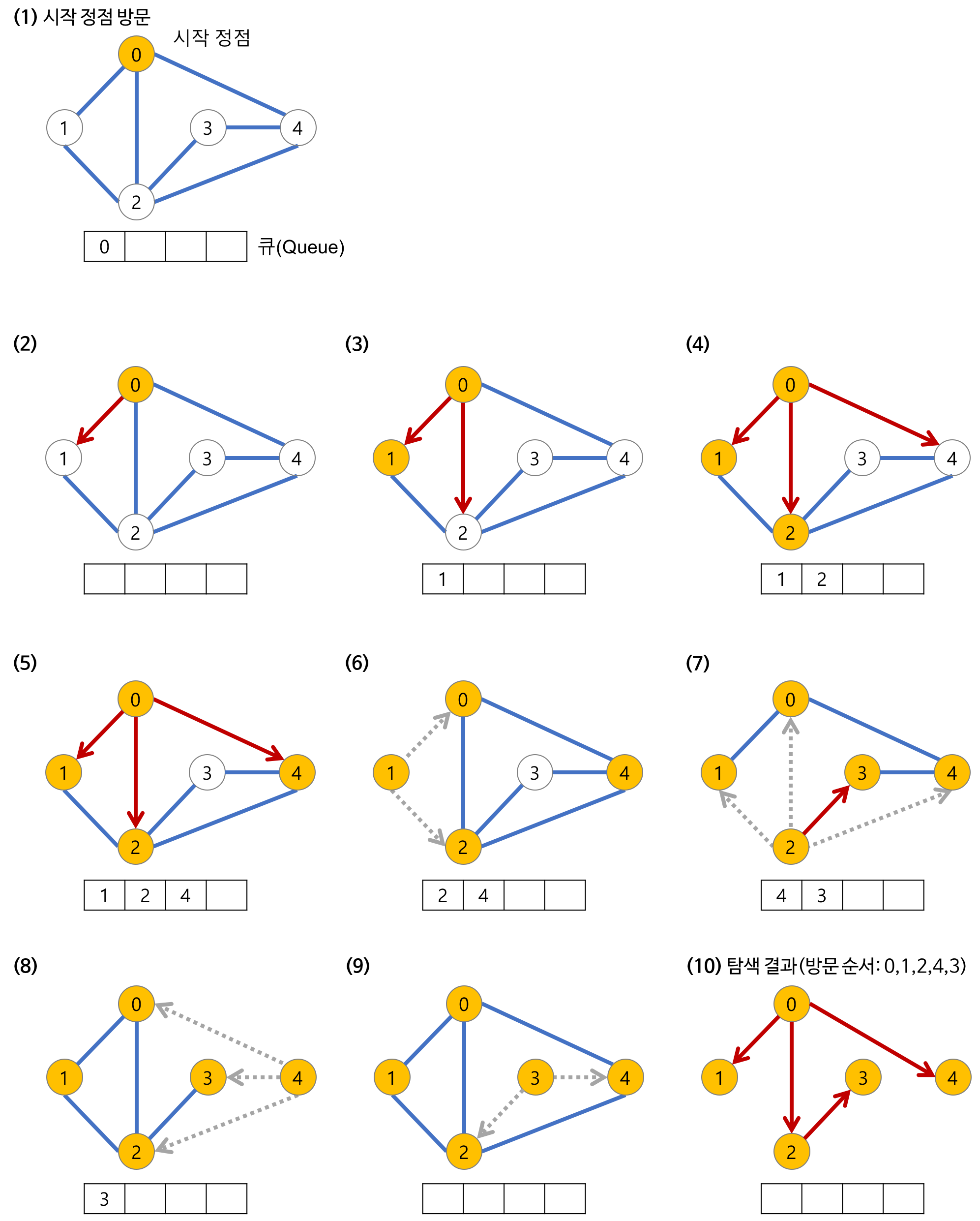
BFS(너비 우선 탐색)
시작 정점으로부터 인접한 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법이다.
정점을 큐에 넣고 큐에서 꺼낸 노드의 인접한 노드를 큐에 넣는다.
큐가 다 빌 때 까지 반복한다.
큐를 이용한 반복문 형식
void bfs_mat(GraphType* g,int v){
int w;
QueueType q;
queue_init(&q);
visited[v]=TRUE;
printf("visited %d->",v);
enqueue(&q,v);
while(!is_empty(&q)){
v=dequeue(&q);
for(w=0;w<g->n;w++)
if(g->adj_mat[v][w]&&!visited[w]){
visited[w]=TRUE;
printf("visited %d->",v);
enqueue(&q,w);
}
}
}
#include <stdio.h>
#define MAX 50
int adj[MAX][MAX];
int visited[MAX];
int queue[MAX], front = 0, rear = 0;
void enqueue(int v) { queue[rear++] = v; }
int dequeue() { return queue[front++]; }
int empty() { return front == rear; }
void bfs(int n, int start) {
visited[start] = 1;
printf("%d ", start);
enqueue(start);
while (!empty()) {
int v = dequeue();
for (int w = 0; w < n; w++) {
if (adj[v][w] && !visited[w]) {
visited[w] = 1;
printf("%d ", w);
enqueue(w);
}
}
}
}
int main() {
int n = 5;
int edges[][2] = { {0,1},{0,2},{0,4},{1,2},{2,3},{3,4}, {2,4} };
for (int i = 0; i < 7; i++) {
int a = edges[i][0], b = edges[i][1];
adj[a][b] = adj[b][a] = 1;
}
printf("BFS: ");
bfs(n, 0);
printf("\n");
}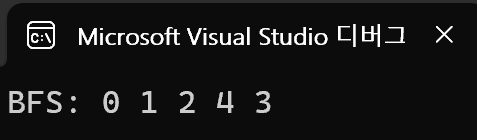
출처:
c언어로 쉽게 풀어쓴 자료구조
https://1107dew.tistory.com/26
https://songsite123.tistory.com/29#google_vignette
https://gmlwjd9405.github.io/2018/08/15/algorithm-bfs.html#google_vignette
