Gradient descent
gradient descent(경사하강법)은 딥러닝, 머신러닝 모델을 학습할 때 매개변수(hyper parameter)를 갱신하여 손실함수의 오차를 최대한 줄이려는 알고리즘이다.
자세히는 손실함수의 기울기를 구해 기울기를 가장 최소화되는 부분을 구하는 것이다.
Gradient descent의 목적과 사용이유
- 우리가 주로 실제 분석에서 맞딱드리게 되는 함수들은 닫힌 형태가 아니거나 함수의 형태가 복잡해 (가령, 비선형함수) 미분계수와 그 근을 계산하기 어려운 경우가 많고,
- 실제 미분계수를 계산하는 과정을 컴퓨터로 구현하는 것에 비해 gradient descent는 컴퓨터로 비교적 쉽게 구현할 수 있기 때문이다.
- 데이터 양이 매우 큰 경우 gradient descent와 같은 반복적인 방법을 통해 해를 구하면 계산량 측면에서 더 효율적으로 해를 구할 수 있다.
Gradient descent의 수식 유도
gradient descent는 함수의 기울기를 이용해 의 값을 어디로 옮겼을 때 함수가 최솟값이 되는지 알아보는 방법이라 할 수 있다.
기울기가 양수라는 것은 가 커질 수록 함수의 값이 커진다는 것이고 음수라면 가 커질 수록 함수의 값이 작아진다는 것을 의미한다
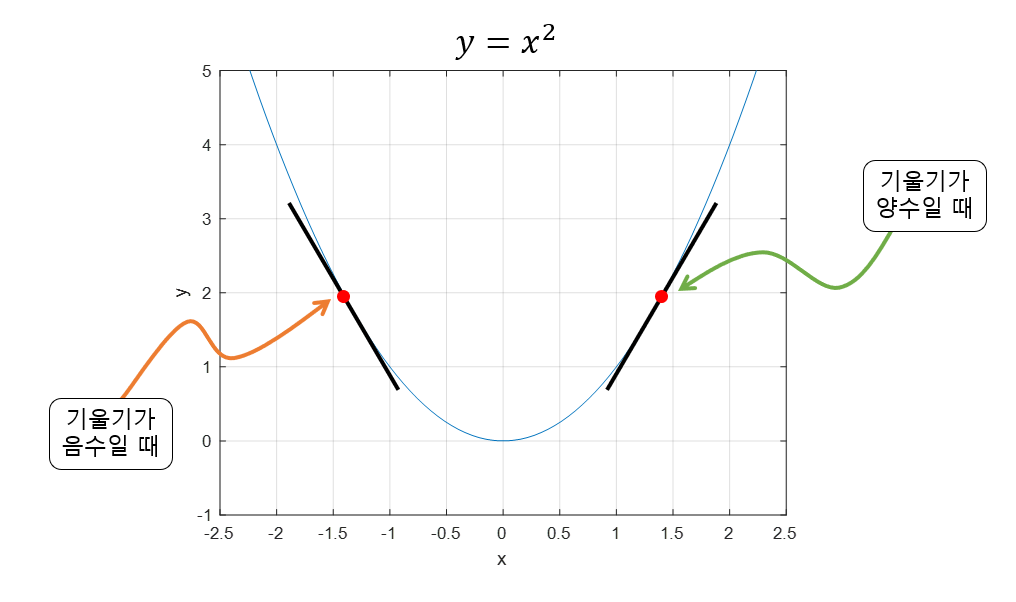
그렇다면 기울기를 알면 어디로 옮겨야 할지 알 수 있다.
이 때 이동거리를 조절할 수 있게 step size 조절 인자를 넣기도 한다.
는 learning late(step size)
최종 수식은 다음과 같다.
단점
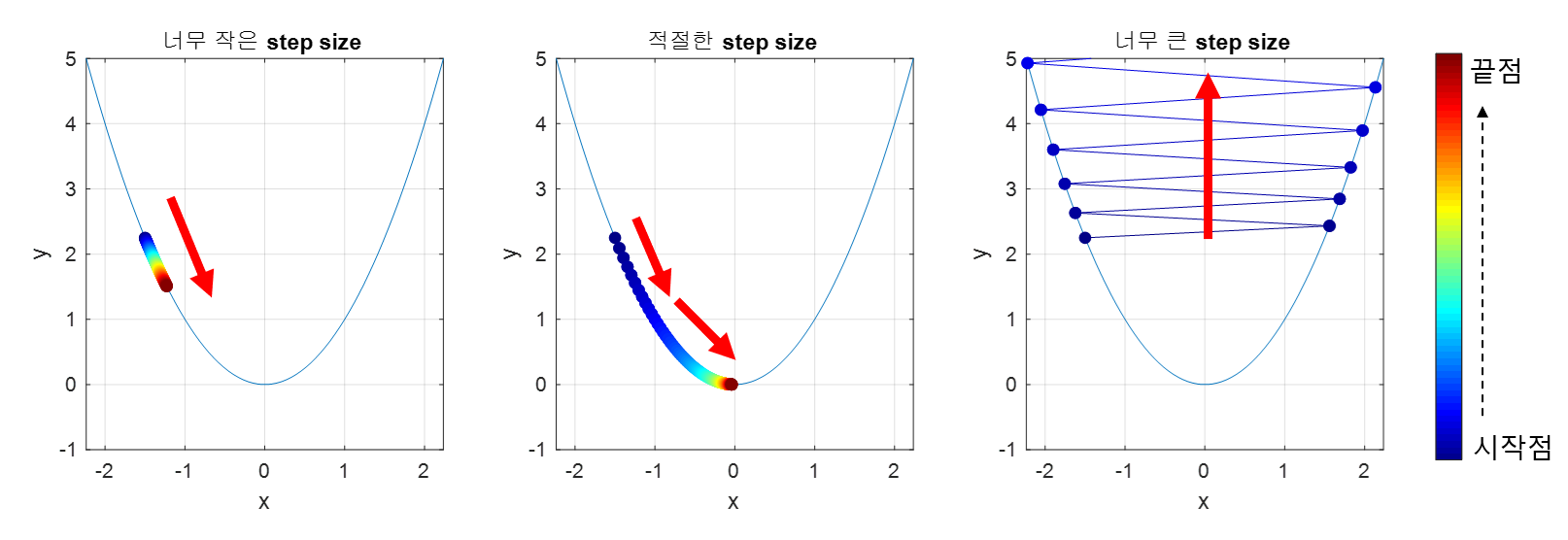
적절한 크기의 step size
step size가 큰 경우 한 번 이동하는 거리가 커지므로 빠르게 수렴할 수 있다는 장점이 있다. 하지만, step size를 너무 크게 설정해버리면 최소값을 계산하도록 수렴하지 못하고 함수 값이 계속 커지는 방향으로 최적화가 진행될 수 있다.
또, 한편 step size가 너무 작은 경우 발산하지는 않을 수 있지만 최적의 를 구하는데 소요되는 시간이 오래 걸린다는 단점이 있다.
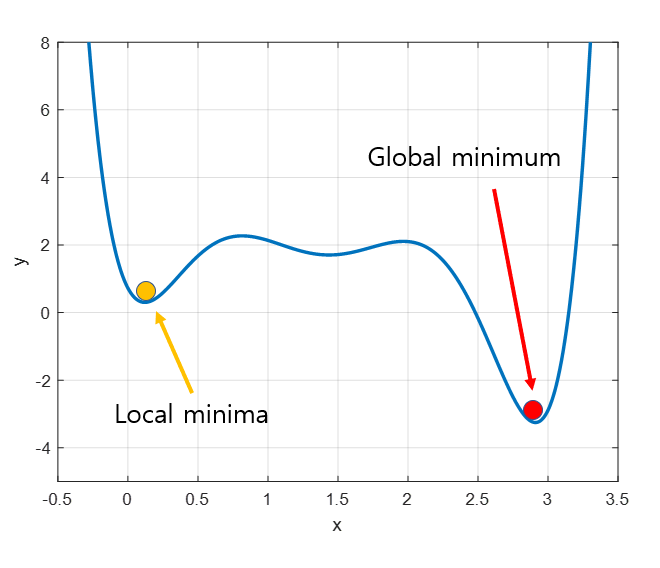
local minima 문제
Gradient descent의 또 다른 문제는 local minima 문제이다. 실제로 우리가 찾고 싶은 것은 아래의 그림에서 볼 수 있는 빨간점이 표시하는 global minimum이지만,gradient descent 알고리즘을 시작하는 위치는 매번 랜덤하기 때문에 어떤 경우에는 local minima에 빠져 계속 헤어나오지 못하는 경우도 생긴다.
이러한 gradient descent의 종류에는 여러가지가 있는데 몇 가지를 소개해보자면
Batch Gradient Descent(배치 경사하강법)
전체 데이터를 사용해 매개변수를 갱신한다.
특징:
- 항상 같은 데이터 (전체 데이터)에 대해 경사를 구하기 때문에, 수렴이 안정적이다. (아래 그림 참고)
- 계산시간이 오래걸림.
- 메모리 사용량이 많음.
Stochastic Gradient Descent(확률적 경사 하강법)
하나의 데이터를 사용해 매개변수를 갱신한다.
특징:
- 한번의 하나의 데이터만 처리하기 때문에 GPU의 병렬처리를 이용하지 못한다.
- 1회 학습할 때 계산량이 줄어든다.
- Global Minimum에 수렴하기 어렵다.
- 노이즈가 심하다.
Mini-Batch Stochastic Gradient Descent(미니 배치 확률적 경사 하강법)
전체 데이터를 batch_size개씩(사용자 지정) 나눠 배치로 사용해 매개변수를 갱신한다.
BGD와 SGD를 합친 방법이다.
특징:
- BGD보다 계산량이 적다. (Batch Size에 따라 계산량 조절 가능)
- Shooting이 적당히 발생한다. (Local Minima를 어느정도 회피할 수 있다.)
이 때 batch_size를 지정할 때 GPU의 VRAM 용량에 따라 Out of memory가 발생하지 않도록 정해줘야 한다.
또한 학습데이터 갯수가 나누어떨어지면 좋은데 예를 들어, 530 개의 데이터를 100개의 배치로 나누면, 각 배치 속 데이터는 1/100 만큼의 영향력을 갖게 된다. 그러나 마지막 배치(30개)의 데이터는 1/30의 영향력을 갖게 되어 과평가되는 경향이 있다. 그렇기 때문에 보통 마지막 배치의 사이즈가 다를 경우 이는 버리는 방법을 사용한다.
Momentum(모멘텀법)
가중치를 업데이트 할때 이전 가중치의 업데이트값의 일정 비율을 더하는것으로, 가중치가 local minimum에 빠지지 않고 학습하는 방향대로 가도록 하는 방법이다.
사용 이유:
-
확률적 경사하강법의 단점은 비등방성함수에서 즉, 방향에 따라 자주 기울기가 달라지는 함수에서 탐색경로가 지그재그로 되어 비효율적이다
-
모멘텀 알고리즘은 이런 단점을 보안하기 위하여 제안된 알고리즘이다. 즉 기존 탐색방향을 고려하여 매개변수를 갱신함으로써 진동하는 것을 방지할 수 있다.
여기서 는 모멘트 효과에 대한 가중치이다. 는 0으로 초기화되어 있고 반복이 될 때마다 현재의 그래디언트 가 다음번 모멘트 에 누적된다.
특징:
-
일 때는, 경사가 가파른 곳에서 빠르게 이동하고 안장점 혹은 지역적 최소 지점을 벗어나기에 유리하다.
-
일 때는, 경사 하강법과 동일하다.
단점:
- 오버슈팅 (Overshooting) 최소 지점 주변의 경사가 가파른 경우, 관성에 의해 최소 지점을 지나칠 우려가 있을 수 있다.
출처:
https://twojun-space.tistory.com/124
https://www.dbpia.co.kr/pdf/pdfView.do?nodeId=NODE09310459
https://velog.io/@nayoong/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EC%B5%9C%EC%A0%81%ED%99%94-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
https://angeloyeo.github.io/2020/08/16/gradient_descent.html
https://mangkyu.tistory.com/34
https://skyil.tistory.com/68
