Vanishing Gradient
말 그대로 기울기가 소실 되는 것이다.
해결하는 방법이 여러가지 있다.
activation function
기울기 소실은 미분값이 0보다 크고 1보다 작을 때 계속 곱해지면 점점 0에 가까워져 결국 0에 수렴되는 것이다. 그러므로 backpropagation을 할 때 점점 뒤로 갈 수록 paramiter가 갱신되지 않을 수 있다.
이러한 문제는 sigmoid함수에서 일어나는 것을 볼 수 있는데 sigmoid함수는 미분의 최댓값이 1/4이므로 결국 0에 수렴한다.
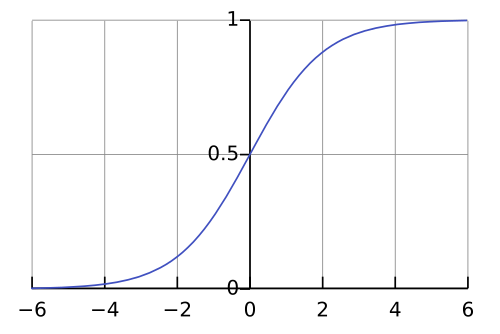
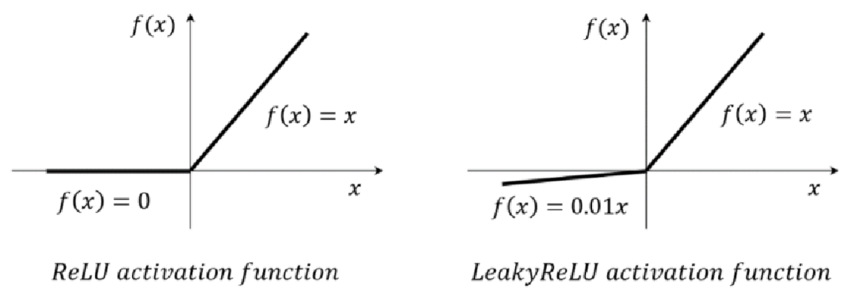
이렇나 sigmoid의 단점 때문에 대신 Relu나 Leaky Relu 등을 사용한다.
가중치 초기화
Hyper parmiter를 맨 처음 설정할 때 적절한 숫자로 설정한다.
기법으로는 Xavier, He 등이 있다.
Batch Normalization(배치 정규화)
데이터의 분포를 줄여 안정적으로 값들이 너무 커지거나 작아지는 것을 막아줌.
batch data{}
: 배치 안의 입력 값
: 배치 크기
: 0으로 나누기 방지용 아주 작은 수
: 학습 가능한 스케일 & 이동 파라미터
1.batch mean
2.batch variance
3.Normalization
4.scale & bias
다시 조사히기 전체적으로 그 담에 RESNET도 조사하자

AI 어렵다