2023년 6월 인용수 9회
CAV-MAE paper
Github
Introduction
- 효과적인 self-supervised 두 기법 contrastive multi modality + MDM(Masking data model)를 결합한 모델을 제시
- 두 방법이 서로 보완함
- 대조와 재구성(masking)
- 대조(Constrastive)는 가까운건 가깝게 먼건 멀게, 여기선 가까운건 가깝게(multimodal)
- 재구성의 단점은 데이터가 부족함
- 둘다 대상에 대해 representation을 잘 하는 것 , 상관관계를 잘 학습하는 것이 목표!
- 상관관계란 하나의 modality , 여러개의 modality 둘다 의미
- 대조와 재구성(masking)
Audio & Image pre-processing and tokenization
-
모델의 기본적인 구조는 AST와 ViT와 비슷함.
- patch -> embedding(+positional) + Encoder ~
-
학습데이터는 Audioset과 VGGsound 둘다 10초짜리 영상(video=image+audio)
-
audio
- 128-D melspectrogram / 25ms hanning window / every 10ms
- 10초 -> 1024 x 128 (padding?) -> 16x16 patch 512개
- 특이점이라면 AST는 가로방향이라면 CAV-MAE는 세로방향(이게 맞는 것 같긴함)
-
Image : 모든 image를 사용할 수 없음 -> 연산량이 길이에 따라 Quadratic하게 증가
- 이전의 sota multi modal MBT는 큰 모델 사이즈와 많은 연산량이 필요
- Frame Aggregation strategy : 프레임으로 나눠서 랜덤하게 선택하여 학습
- 하나의 오디오는 하나의 이미지와 매핑하여 학습
- 1 FPS (1초당 이미지 1개로 나눔)
- Training중 랜덤으로 1개 선택
- Resize and centor crop : 224x224 -> 16x16 patch 196개
-
Inference시 average the model prediction of each RGB frame as the video prediction -> 10개의 이미지를 사용한 결과를 평균낸다는 뜻인듯?
- video의 길이가 길어져도 audio만 선형적으로 증가
- Quadratic -> linear complexity
TRANSFORMER ARCHITECTURE
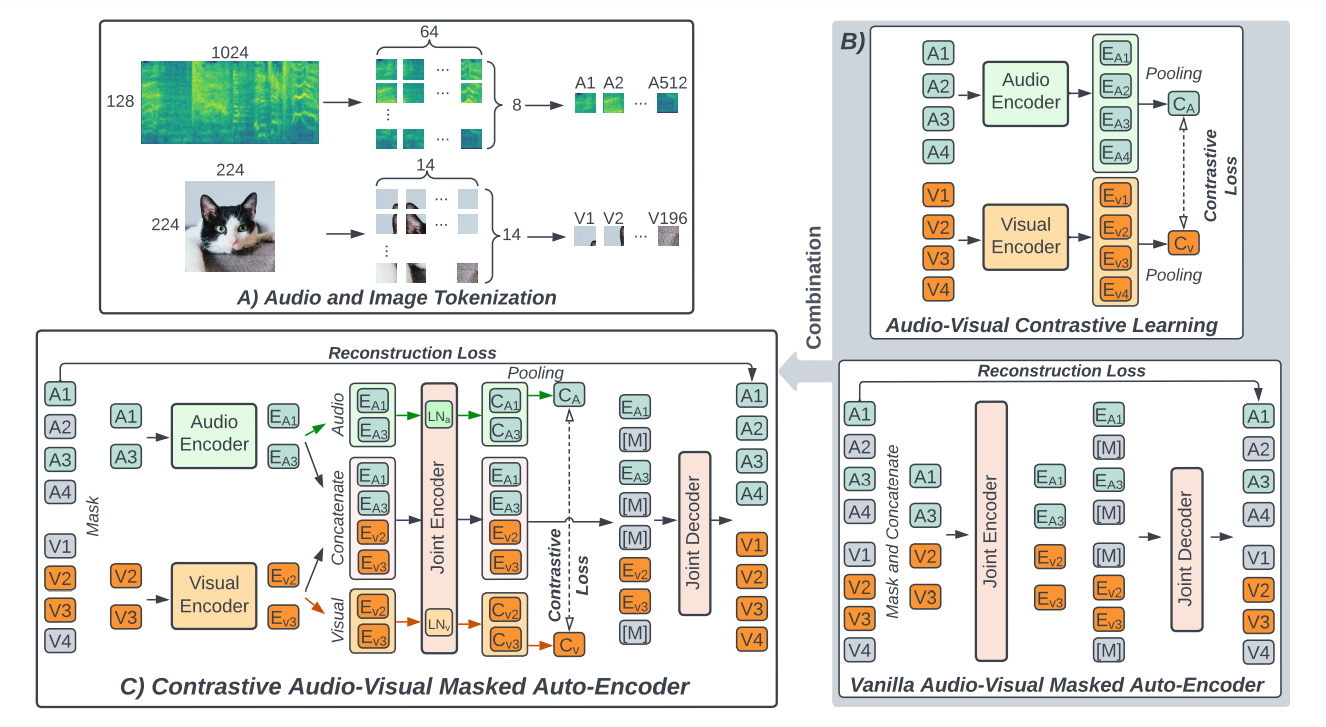
A. Tokenize audio and image
B. 위는 일반적인 방법의 Contrastive learning modal / 아래는 masked auto-encoder를 활용
--Contrastive한 방법은 multi modal 즉, 다른 형태의 input을 같은 representation으로 나타내는 것이 목적 (coordinate representation) - CAV
--MAE는 말그대로 Auto-encoder로 데이터를 다시 재구성하는 것이 목적 (joint representation) - AV-MAE
C. 위의 두 방법을 결합한 형태 CAV-MAE
다른 Task에도 잘 작동함 -> 모델의 끝 부분을 조정하면 됨
<방법론 소개>
-
Contrastive audio-visual learning(CAV)
- B의 위쪽
- {Audio,Visual} 쌍(Token)이 들어오면 각각 인코더(TF)로 들어가고 mean pooling을 통해 평균 representation {,}가 나옴
- 두 representation은 768-d array 둘의 차이가 작아져야함 -> Contrastive loss(KL)
-
SINGLE MODALITY MASKED AUTOENCODER (MAE)
- Token을 Mask함(75%)
- mask하지 않은 token을 인코더(TF)에 넣고 디코더(TF)로 원래 데이터를 수복(Recontruct)
- 이 과정에서 모델은 잘 presentation하도록 학습
- 인코더에는 unmasked token만 넣으므로 연산량이 적음
- Reconstruct와 원본으로 MSE loss구함
-
VANILLA AUDIO-VISUAL MASKED AUTOENCODER
- 위의 MAE를 audio-visual로 실행
- Audio와 image pair를 각각의 linear projection(Embedding)함
- positional Embedding도 각각 진행함
- 512x768 / 196x768 ebedded token 생성
- audio와 image를 모두 입력으로 받는 인코더를 joint encoder라 함
- 두 embedding된 vector를 concat후 75%로 masking
- Decoder에 들어가는 masking token은 위치를 포함한 학습가능한 token
- Decoder에 들어가는 masking token은 위치를 포함한 학습가능한 token
- AV-MAE는 하나의 modality를 통해 다른 modality를 Reconstruct하며 상호간의 상관관계를 학습함
- AV-MAE는 서로다른 modality를 하나의 가중치로 처리함(joint encoder) 이는 각각의 서로다른 modality를 잘 표현 못할 수 있음,
- 하지만 이 방법은 서로다른 modality가 서로 이해할 수 있게 해줌
- 즉, 각각의 modality는 잘 이해 못하더라도 서로의 modalty를 이해할 수 있음
-
CONSTRASTIVE AUDIO-VISUAL MASKED AUTOENCODER (CAV-MAE)
- CAV와 MAE의 장점을 가져오자!
- 각각의 Linear projection으로 Embedding / 각각 75% masking / 각각의 Encoder 통과
- multi stream : 각각 세개의 LN통과 , Encoder의 weight는 공유함
- 각각의 modality stream vector로 대조 loss 구할 수 있음 KL loss
- 재구성은 위와 마찬가지로 학습가능한 위치 masked token 사용 , loss는 MSE loss
- 최종 Loss = + *
활용
- 학습 후
- 디코더는 버림 , 인코더만 Keep하고 downstream task에 사용
- single modal stream 혹은 multi modal stream을 사용할 수 있음
- multi stream
- multi stream을 사용하여 하나의 modality와 멀티 modality에 대해 유동적으로 사용가능
- 서로 다른 LN
- 오디오와 이미지는 너무 특성이 다름 -> 서로 다른 encoder를 통과 후 각각 다른 LN 사용
- 같은 encoder를 사용하면 낮은 성능
- 두개의 encoder는 model size는 커지지만 연산량은 작아짐
- a^2 + b^2 < (a+b)^2
- 대조 학습과 MASKING
- masking은 과적합방지 효과가 있음
- 학습이 쉽지는 않음
- masking 75% batch 48 or (27*4개 gpu사용이므로 108)일 때 72% acc(아마 제일 잘나온듯)
실험 환경
-
model_dimension : 768
-
multi head : 12
-
encoder layer : 12 (11+1)
- audio & visual encoder layer : 11
- joint encoder layer : 1
-
audio & visual model_dimension : 768
-
Decoder layer : 8
-
Decoder model_dimension : 512
-
Decoder multi head : 16
-
Loss_c lamda : 0.01
-
model total size : 164M , 27M parameter
-
ImageNet pretrained MAE weight사용(AST와 비슷)
-
supervised learning보단 성능은 안좋지만(다른 모델과 비교) self-supervised learning 사용 가능
평가

- SSL로 학습데이터 구하기 쉬움!
- Contrastive와 masking의 결합
- CAV-MAE는 CAV와 AV-MAE보다 좋은 성능
- multimodal의 관점
- multimodal인데 unimodal보다 좋은 성능
- Audio-MAE와 visual-MAE보다 좋음
- 적은 연산량, 뛰어난 성능
- 기존의 sota MBT(multi modal)는 64GPU 여기는 4GPU
Retreival
- audio-visual classification down stream
- 재구성을 recall metric으로 평가 (코사인유사도)
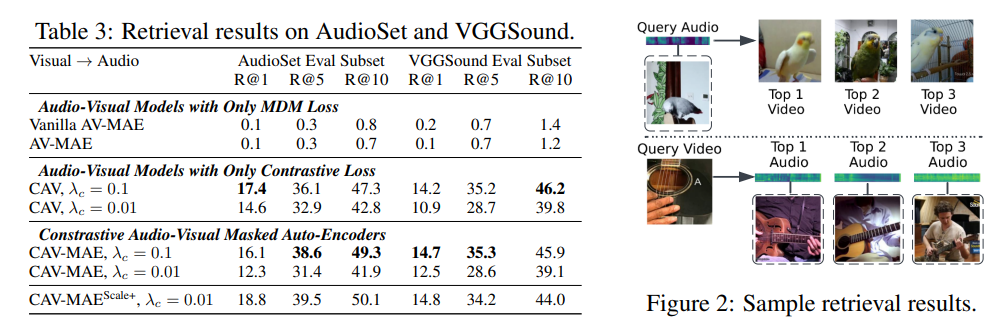
- visual -> audio
- 이미지에서오디오 혹은 오디오에서이미지로 retreival task에선 multimodal학습이 필수적임
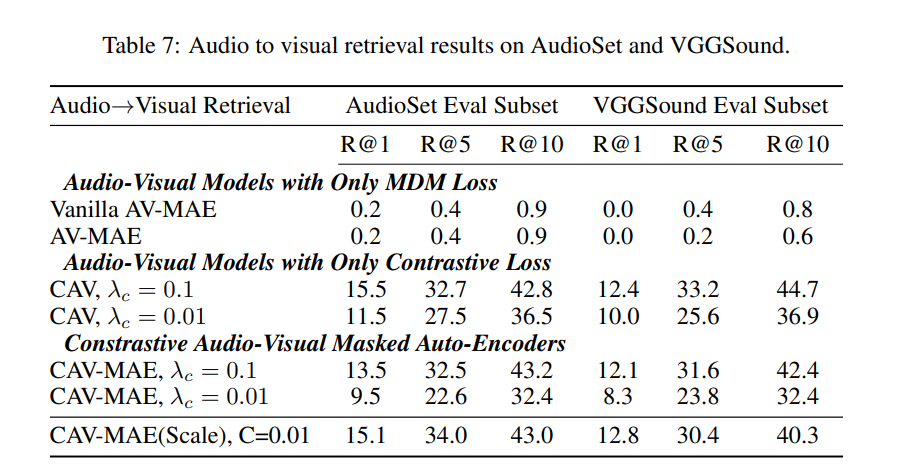
- 이미지에서오디오 혹은 오디오에서이미지로 retreival task에선 multimodal학습이 필수적임
Ablation study
-
model size
- Encoder-Decoder Full model : 190M parameters
- Encoder model : 160M parameters
- Encoder(single modal) : 85M parameters
-
pretraing & Finetuning에 사용된 정확한 파라미터는 Appendix B에서 확인가능!
-
Kinetics-sounds : 움직임이 많은 영상 (ex 살사춤)
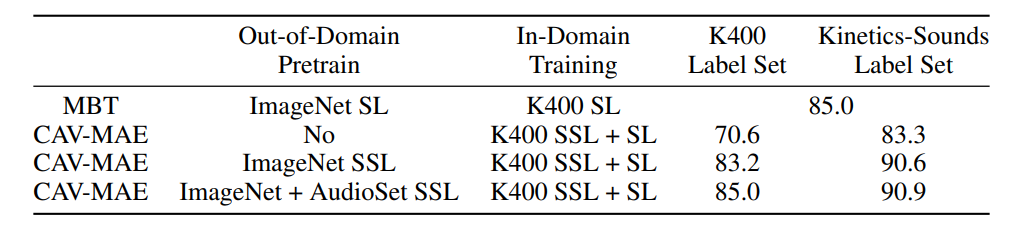
-
Model initialization효과
- ImageNet 과 AudioSet을 모두 사용한 인코더를 Transfer한게 성능이 가장 좋았음
- Appendix E
-
Masking strategy
- Appendix F
- Reconstruct에는 Uniform masking이 성능이 제일 좋음
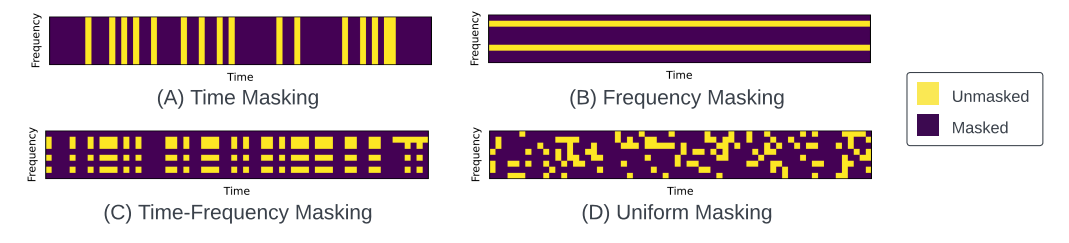
-
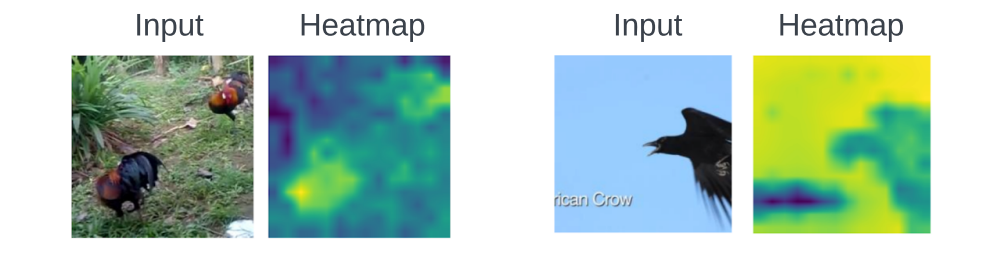
Visual sound source localization (Appendix I)
- mean pool한 clip-level representation와 patch-level image representation으로 코사인유사도 계산
- 왼쪽 good case / 오른쪽 bad case
- 대상대신 배경에 localization함
- 저자 가설 : audio에 hard masking되면 image의 context 정보를 학습(배경이 많으므로 더 집중??)
후기
MIT-IBM에서 발표한 논문
모델이 너무 가벼움 - scale++가 800MB가 안됨
모델 코드와 pretrained weight가 공개되있음
멀티 모달이라 납득하기 쉬움
시각화도 할 수 있음
